在这篇博文中,我们将介绍最近提出的随机权重平均 (SWA) 技术 [1, 2],及其在 torchcontrib 中的新实现。SWA 是一种简单的方法,可以在不增加额外成本的情况下,比随机梯度下降 (SGD) 更好地提高深度学习的泛化能力,并且可以作为 PyTorch 中任何其他优化器的直接替代品。SWA 具有广泛的应用和功能:
- SWA 已被证明能显著提高计算机视觉任务的泛化能力,包括 ImageNet 和 CIFAR 基准上的 VGG、ResNets、Wide ResNets 和 DenseNets [1, 2]。
- SWA 在半监督学习和域适应的关键基准上提供了最先进的性能 [2]。
- SWA 被证明能提高深度强化学习中策略梯度方法的训练稳定性以及最终平均奖励 [3]。
- SWA 的扩展可以获得高效的贝叶斯模型平均,以及深度学习中的高质量不确定性估计和校准 [4]。
- 用于低精度训练的 SWA,即 SWALP,即使所有数字都量化到 8 位,包括梯度累加器,也能达到全精度 SGD 的性能 [5]。
简而言之,SWA 对 SGD 遍历的权重进行等权平均,并采用修改后的学习率调度(见图 1 的左图)。SWA 解决方案最终位于损失的宽平坦区域的中心,而 SGD 倾向于收敛到低损失区域的边界,这使得它容易受到训练和测试误差表面之间偏移的影响(见图 1 的中图和右图)。
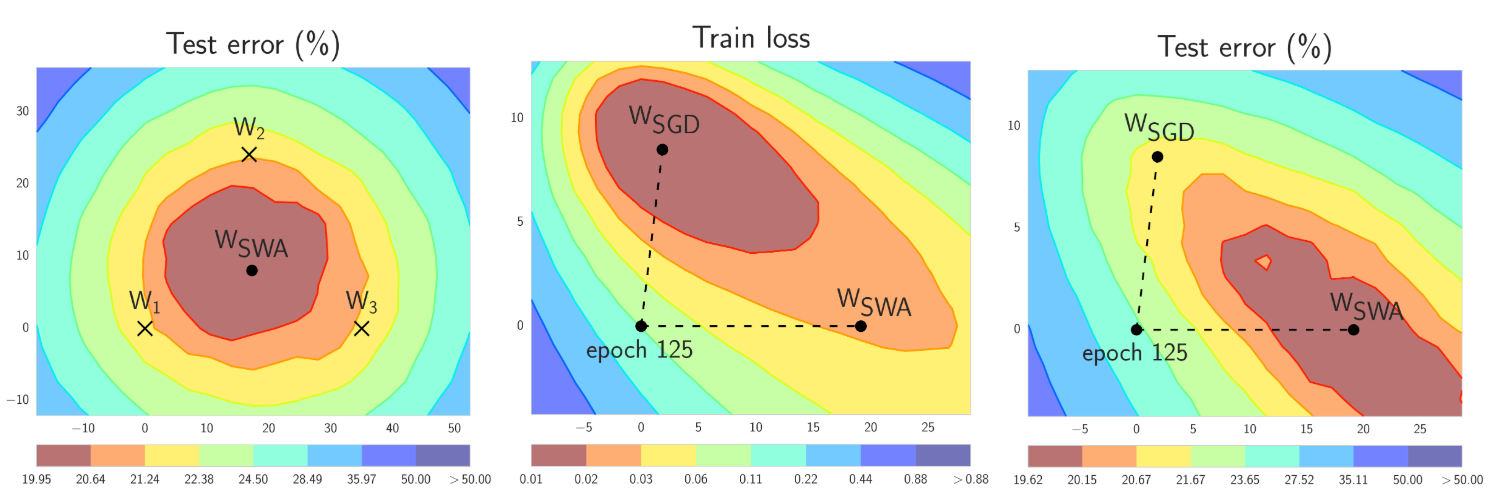
图 1. CIFAR-100 上使用 Preactivation ResNet-164 的 SWA 和 SGD 示例 [1]。左图:三个 FGE 样本和相应的 SWA 解决方案的测试误差表面(权重空间中的平均)。中图和右图:测试误差和训练损失表面,显示从 SGD 训练 125 个 epoch 后的相同初始化开始,SGD(收敛时)和 SWA 提出的权重。有关这些图的构建细节,请参见 [1]。
通过我们 torchcontrib 中的新实现,使用 SWA 就像使用 PyTorch 中的任何其他优化器一样简单。
from torchcontrib.optim import SWA
...
...
# training loop
base_opt = torch.optim.SGD(model.parameters(), lr=0.1)
opt = torchcontrib.optim.SWA(base_opt, swa_start=10, swa_freq=5, swa_lr=0.05)
for _ in range(100):
opt.zero_grad()
loss_fn(model(input), target).backward()
opt.step()
opt.swap_swa_sgd()
您可以使用 SWA 类包装 torch.optim 中的任何优化器,然后像往常一样训练您的模型。训练完成后,您只需调用 swap_swa_sgd() 将模型的权重设置为其 SWA 平均值。下面我们将详细解释 SWA 过程和 SWA 类的参数。我们强调,SWA 可以与任何优化过程(例如 Adam)以与与 SGD 结合的相同方式结合使用。
这仅仅是平均 SGD 吗?
从宏观角度来看,平均 SGD 迭代可以追溯到几十年前的凸优化 [6, 7],有时被称为 Polyak-Ruppert 平均,或平均 SGD。但细节很重要。平均 SGD 通常与衰减学习率和指数移动平均结合使用,通常用于凸优化。在凸优化中,重点在于提高收敛速度。在深度学习中,这种形式的平均 SGD 平滑了 SGD 迭代的轨迹,但表现并没有太大差异。
相比之下,SWA 侧重于 SGD 迭代的等权平均,并采用修改后的循环或高常数学习率,利用深度学习特有的训练目标平坦性 [8],以提高泛化能力。
随机权重平均
SWA 之所以有效,有两个重要因素。首先,SWA 采用修改后的学习率调度,使 SGD 继续探索高性能网络集合,而不是简单地收敛到一个单一解决方案。例如,我们可以在训练时间的最初 75% 使用标准的衰减学习率策略,然后将学习率设置为一个合理的高常数,用于剩余的 25% 时间(参见下面的图 2)。第二个因素是平均 SGD 遍历的网络权重。例如,我们可以在训练时间的最后 25% 期间,在每个 epoch 结束时保持一个权重运行平均值(参见图 2)。
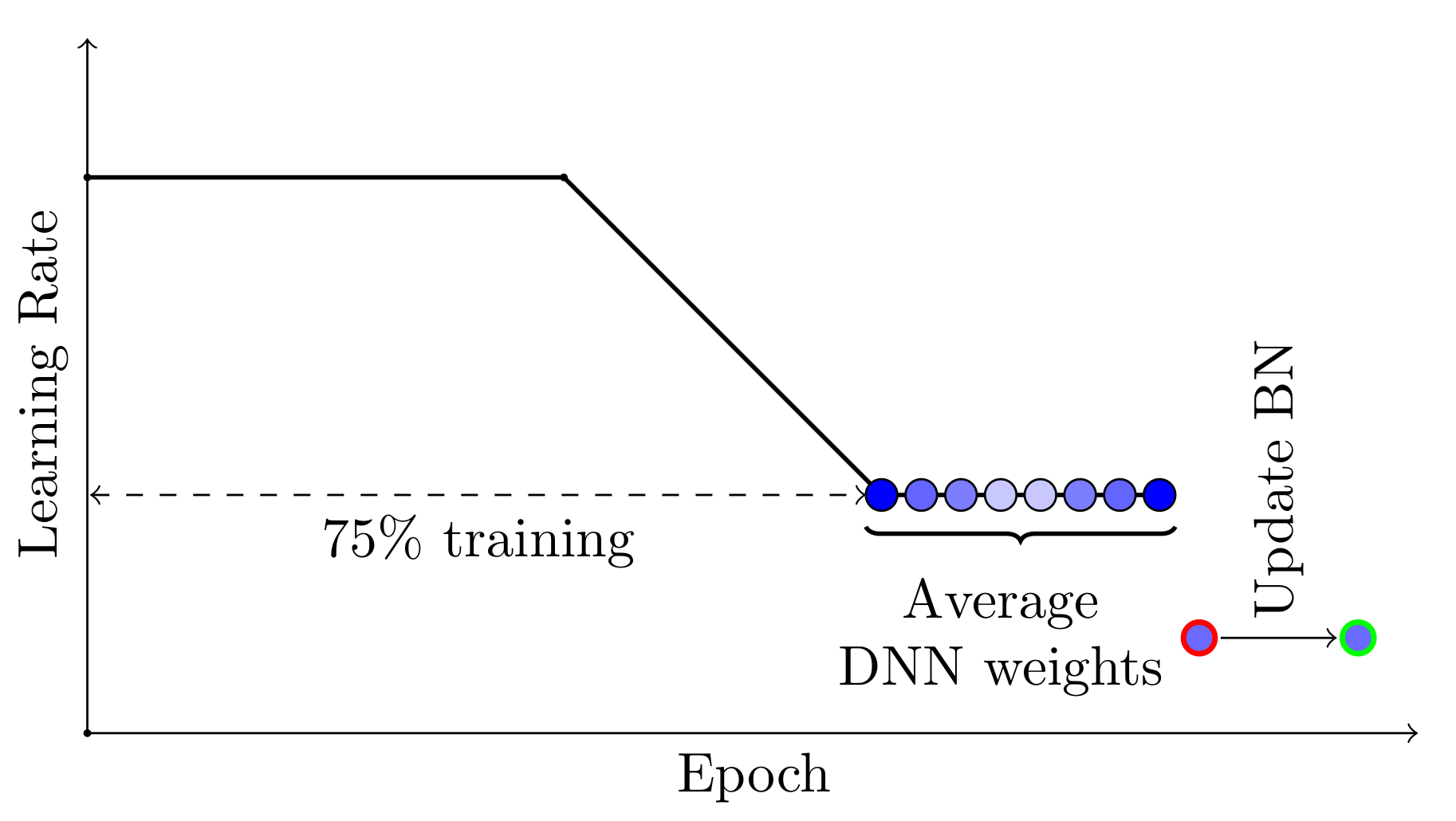
图 2. SWA 采用的学习率调度图示。前 75% 的训练使用标准衰减调度,然后剩余 25% 的训练使用高常数值。SWA 平均值在训练的最后 25% 期间形成。
在我们的实现中,SWA 优化器的自动模式允许我们运行上述过程。要在自动模式下运行 SWA,您只需使用 SWA(base_opt, swa_start, swa_freq, swa_lr) 包装您选择的优化器 base_opt(可以是 SGD、Adam 或任何其他 torch.optim.Optimizer)。在 swa_start 优化步骤之后,学习率将切换到一个常数值 swa_lr,并且在每 swa_freq 优化步骤结束时,权重的快照将被添加到 SWA 运行平均值中。一旦您运行 opt.swap_swa_sgd(),模型的权重将被其 SWA 运行平均值替换。
批归一化
一个需要记住的重要细节是批归一化。批归一化层在训练期间计算激活的运行统计量。请注意,SWA 的权重平均值在训练期间从不用于进行预测,因此在您使用 opt.swap_swa_sgd() 重置模型权重后,批归一化层没有计算激活统计量。要计算激活统计量,您可以在训练完成后,使用 SWA 模型对训练数据进行一次前向传播。在 SWA 类中,我们提供了一个辅助函数 opt.bn_update(train_loader, model)。它通过对 train_loader 数据加载器进行前向传播,更新模型中每个批归一化层的激活统计量。您只需在训练结束时调用此函数一次。
高级学习率调度
SWA 可以与任何鼓励探索解决方案平坦区域的学习率调度一起使用。例如,您可以在训练时间的最后 25% 使用循环学习率而不是常数值,并平均每个周期内学习率最低值对应的网络权重(见图 3)。
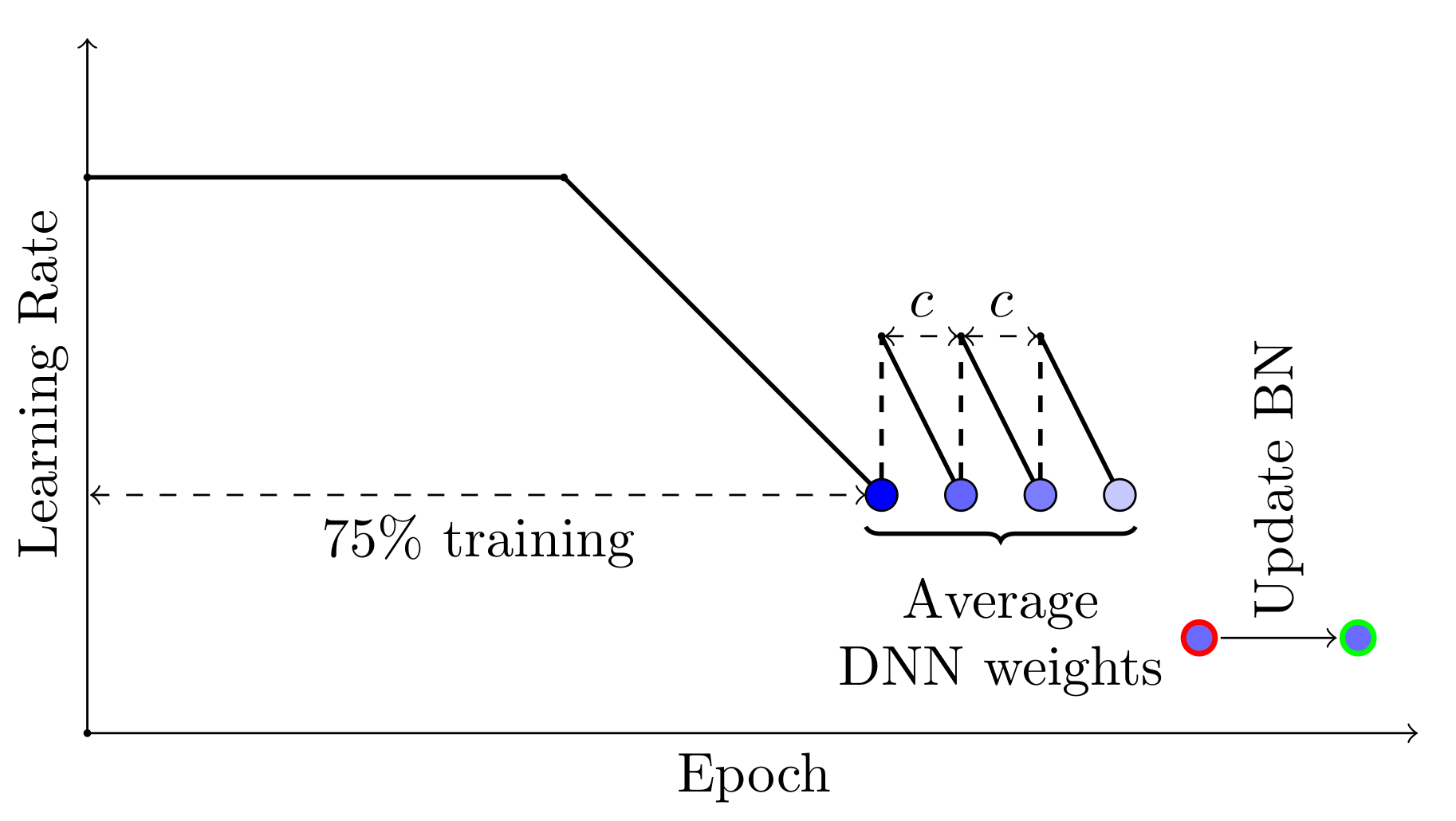
图 3. 采用替代学习率调度的 SWA 示例。训练的最后 25% 采用循环学习率,并在每个周期结束时收集模型进行平均。
在我们的实现中,您可以通过在手动模式下使用 SWA 来实现自定义学习率和权重平均策略。以下代码与本博文开头介绍的自动模式代码等效。
opt = torchcontrib.optim.SWA(base_opt)
for i in range(100):
opt.zero_grad()
loss_fn(model(input), target).backward()
opt.step()
if i > 10 and i % 5 == 0:
opt.update_swa()
opt.swap_swa_sgd()
在手动模式下,您无需指定 swa_start、swa_lr 和 swa_freq,只需在您希望更新 SWA 运行平均值时(例如在每个学习率周期结束时)调用 opt.update_swa()。在手动模式下,SWA 不会改变学习率,因此您可以像使用任何其他 torch.optim.Optimizer 一样,使用任何您想要的调度。
为什么它有效?
SGD 在损失的宽平坦区域内收敛到解决方案。权重空间是极其高维的,平坦区域的大部分体积集中在边界附近,因此 SGD 解决方案将始终在损失的平坦区域边界附近找到。另一方面,SWA 平均多个 SGD 解决方案,这使其能够向平坦区域的中心移动。
我们期望位于损失平坦区域中心的解决方案比那些位于边界附近的解决方案具有更好的泛化能力。实际上,训练和测试误差表面在权重空间中并不完全对齐。位于平坦区域中心的解决方案不像那些位于边界附近的解决方案那样容易受到训练和测试误差表面之间偏移的影响。在下面的图 4 中,我们展示了连接 SWA 和 SGD 解决方案方向上的训练损失和测试误差表面。正如您所看到的,虽然 SWA 解决方案的训练损失高于 SGD 解决方案,但它位于低损失区域的中心,并且具有明显更好的测试误差。
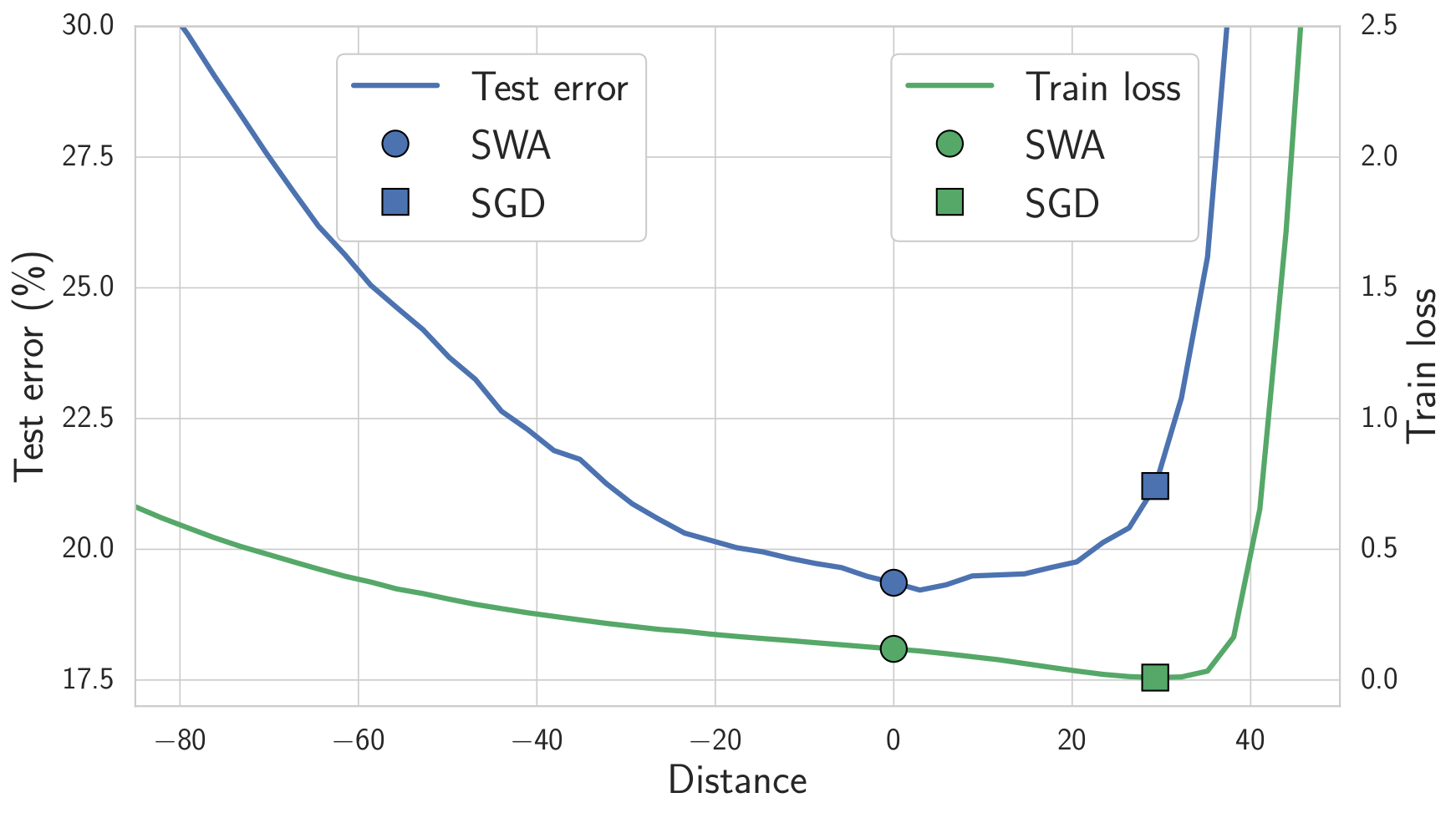
图 4. 连接 SWA 解决方案(圆圈)和 SGD 解决方案(正方形)的直线上的训练损失和测试误差。SWA 解决方案位于低训练损失的宽阔区域的中心,而 SGD 解决方案位于边界附近。由于训练损失和测试误差表面之间的偏移,SWA 解决方案可以带来更好的泛化能力。
示例和结果
我们在这里发布了一个 GitHub 仓库 here,其中包含使用 torchcontrib 实现 SWA 训练 DNN 的示例。例如,这些示例可用于在 CIFAR-100 上取得以下结果:
| DNN (预算) | SGD | SWA 1 预算 | SWA 1.25 预算 | SWA 1.5 预算 |
|---|---|---|---|---|
| VGG16 (200) | 72.55 ± 0.10 | 73.91 ± 0.12 | 74.17 ± 0.15 | 74.27 ± 0.25 |
| PreResNet110 (150) | 76.77 ± 0.38 | 78.75 ± 0.16 | 78.91 ± 0.29 | 79.10 ± 0.21 |
| PreResNet164 (150) | 78.49 ± 0.36 | 79.77 ± 0.17 | 80.18 ± 0.23 | 80.35 ± 0.16 |
| WideResNet28x10 (200) | 80.82 ± 0.23 | 81.46 ± 0.23 | 81.91 ± 0.27 | 82.15 ± 0.27 |
半监督学习
在后续的 论文 中,SWA 被应用于半监督学习,其中它在多种设置下都展示了超越最佳报告结果的改进。例如,如果只有 4k 训练数据点的训练标签,使用 SWA 可以在 CIFAR-10 上获得 95% 的准确率(此问题之前的最佳报告结果是 93.7%)。这篇论文还探讨了在 epoch 内多次平均,这可以在给定时间内加速收敛并找到更平坦的解决方案。
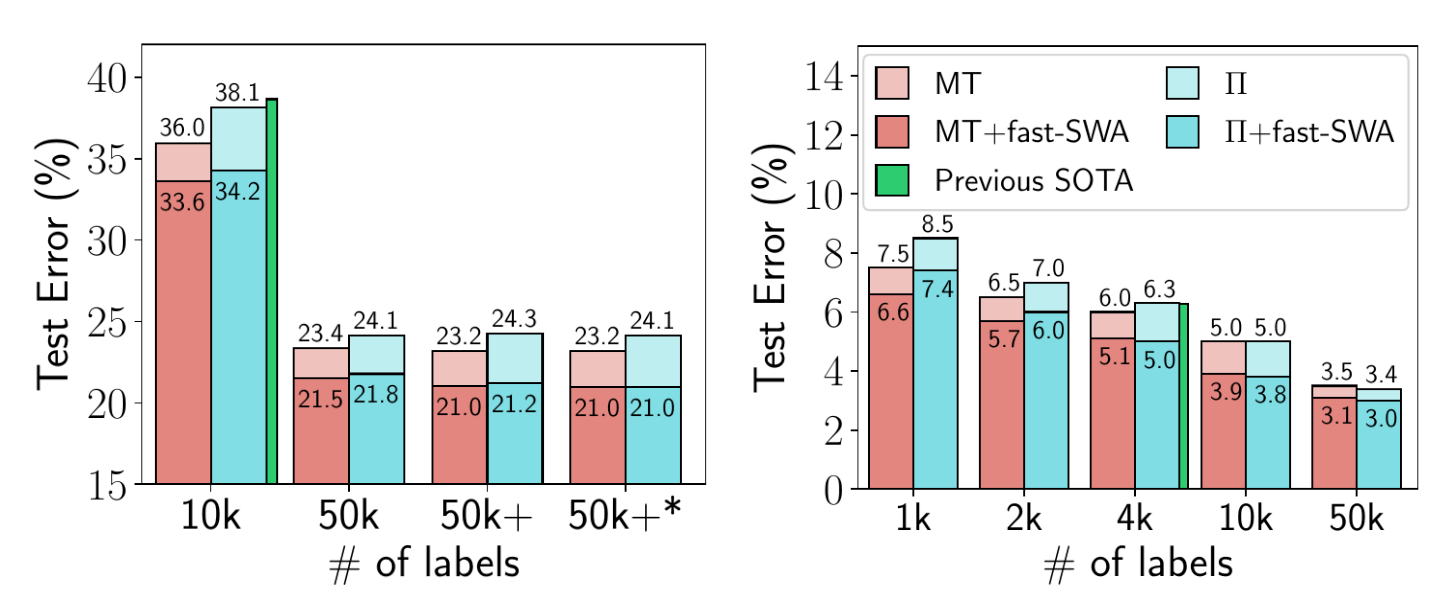
图 5. CIFAR-10 半监督学习中 fast-SWA 的性能。fast-SWA 在考虑的每种设置中都取得了创纪录的结果。
校准和不确定性估计
SWA-高斯 (SWAG) 是一种简单、可扩展且方便的贝叶斯深度学习中不确定性估计和校准方法。与 SWA 保持 SGD 迭代的运行平均值类似,SWAG 估计迭代的一阶和二阶矩,以构建权重的正态分布。SWAG 分布近似真实后验的形状:下面的图 6 展示了 CIFAR-100 上 PreResNet-164 的后验对数密度上的 SWAG 分布。
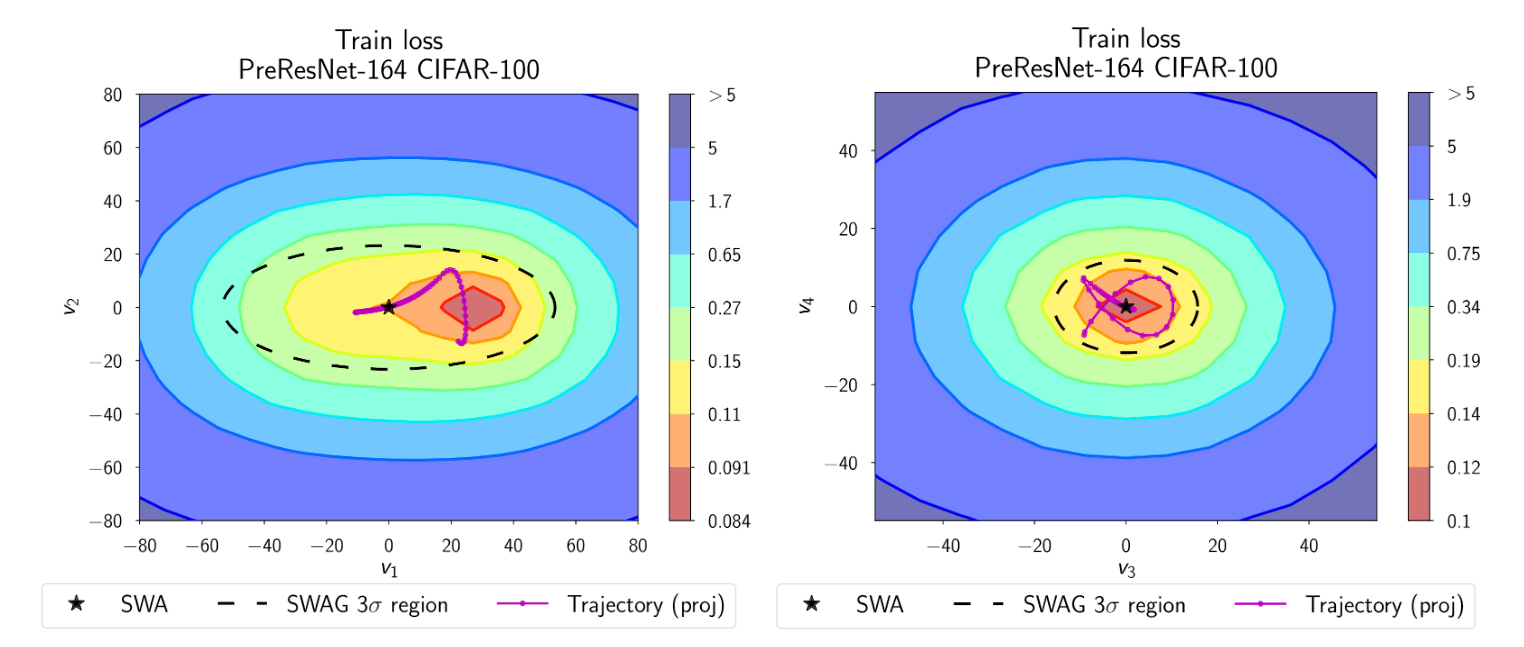
图 6. CIFAR-100 上 PreResNet-164 后验对数密度上的 SWAG 分布。SWAG 分布的形状与后验对齐。
从经验来看,SWAG 在计算机视觉任务中的不确定性量化、分布外检测、校准和迁移学习方面,表现与包括 MC Dropout、KFAC Laplace 和温度缩放等流行替代方法相当或更好。SWAG 的代码可在此处获取:https://github.com/wjmaddox/swa_gaussian。
强化学习
在另一篇后续 论文 中,SWA 被证明可以提高策略梯度方法 A2C 和 DDPG 在多个 Atari 游戏和 MuJoCo 环境中的性能。
| 环境 | A2C | A2C + SWA |
|---|---|---|
| 突破 | 522 ± 34 | 703 ± 60 |
| Qbert | 18777 ± 778 | 21272 ± 655 |
| 太空入侵者 | 7727 ± 1121 | 21676 ± 8897 |
| 海中救援 | 1779 ± 4 | 1795 ± 4 |
| 疯狂攀爬者 | 147030 ± 10239 | 139752 ± 11618 |
| 光束骑士 | 9999 ± 402 | 11321 ± 1065 |
低精度训练
我们可以通过结合向下取整的权重和向上取整的权重来过滤量化噪声。此外,通过平均权重找到损失表面的平坦区域,权重的较大扰动不会影响解决方案的质量(图 7 和 8)。最近的工作表明,通过将 SWA 适应到低精度设置,即一种称为 SWALP 的方法,即使所有训练都采用 8 位,也可以达到全精度 SGD 的性能 [5]。这是一个非常重要的实际结果,因为 (1) 8 位 SGD 训练的性能明显低于全精度 SGD,以及 (2) 低精度训练比训练后低精度预测(通常设置)更难。例如,在 CIFAR-100 上使用浮点 (16 位) SGD 训练的 ResNet-164 达到 22.2% 的误差,而 8 位 SGD 达到 24.0% 的误差。相比之下,使用 8 位训练的 SWALP 达到 21.8% 的误差。
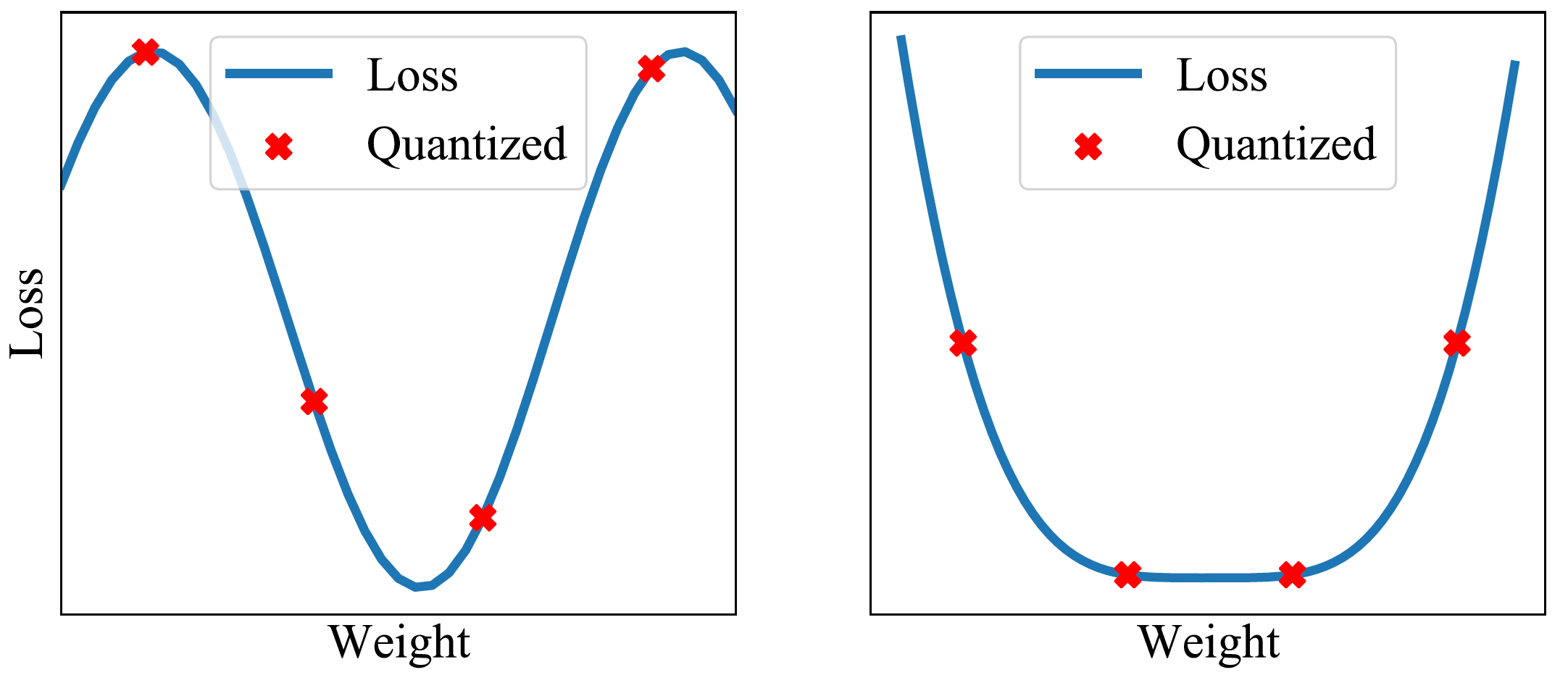
图 7. 在平坦区域进行量化仍然可以提供低损失的解决方案。

图 8. 低精度 SGD 训练(采用修改后的学习率调度)和 SWALP。
结论
深度学习中最大的开放性问题之一是,为什么 SGD 能够找到好的解决方案,因为训练目标是高度多模态的,原则上存在许多参数设置可以实现零训练损失但泛化能力差。通过理解几何特征(例如与泛化相关的平坦性),我们可以开始解决这些问题并构建提供更好泛化能力和许多其他有用功能(例如不确定性表示)的优化器。我们介绍了 SWA,它是一种标准的 SGD 的简单替代品,原则上可以使任何训练深度神经网络的人受益。SWA 已被证明在许多领域具有强大的性能,包括计算机视觉、半监督学习、强化学习、不确定性表示、校准、贝叶斯模型平均和低精度训练。
我们鼓励您尝试 SWA!现在使用 SWA 就像使用 PyTorch 中的任何其他优化器一样简单。即使您已经使用 SGD(或任何其他优化器)训练了模型,也很容易通过从预训练模型开始,运行少量 epoch 的 SWA 来实现 SWA 的好处。
[1] Averaging Weights Leads to Wider Optima and Better Generalization; Pavel Izmailov, Dmitry Podoprikhin, Timur Garipov, Dmitry Vetrov, Andrew Gordon Wilson; 人工智能中的不确定性 (UAI), 2018
[2] There Are Many Consistent Explanations of Unlabeled Data: Why You Should Average; Ben Athiwaratkun, Marc Finzi, Pavel Izmailov, Andrew Gordon Wilson; 国际学习表征会议 (ICLR), 2019
[3] Improving Stability in Deep Reinforcement Learning with Weight Averaging; Evgenii Nikishin, Pavel Izmailov, Ben Athiwaratkun, Dmitrii Podoprikhin, Timur Garipov, Pavel Shvechikov, Dmitry Vetrov, Andrew Gordon Wilson, UAI 2018 研讨会:深度学习中的不确定性, 2018
[4] A Simple Baseline for Bayesian Uncertainty in Deep Learning, Wesley Maddox, Timur Garipov, Pavel Izmailov, Andrew Gordon Wilson, arXiv 预印本, 2019: https://arxiv.org/abs/1902.02476
[5] SWALP : Stochastic Weight Averaging in Low Precision Training, Guandao Yang, Tianyi Zhang, Polina Kirichenko, Junwen Bai, Andrew Gordon Wilson, Christopher De Sa, 将发表于国际机器学习会议 (ICML), 2019。
[6] David Ruppert. Efficient estimations from a slowly convergent Robbins-Monro process. 技术报告,康奈尔大学运筹学与工业工程,1988 年。
[7] Acceleration of stochastic approximation by averaging. Boris T Polyak 和 Anatoli B Juditsky. SIAM Control and Optimization 期刊,30(4):838–855,1992 年。
[8] Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs, Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, Andrew Gordon Wilson. 神经信息处理系统 (NeurIPS), 2018