提要:我们展示了如何使用 PyTorch 和 FairScale 的 FullyShardedDataParallel (FSDP) API 编写大型视觉 Transformer 模型。我们讨论了在 GPU 集群上扩展和优化这些模型的技术。此平台扩展工作的目标是实现大规模研究。本博客不讨论模型准确性、新模型架构或新训练方案。
1. 引言
最新的视觉研究[1, 2] 表明模型扩展是一个有前景的研究方向。在此项目中,我们的目标是使我们的平台能够训练大规模视觉 Transformer (ViT) [3] 模型。我们展示了在 FAIR 视觉平台中将可训练的最大 ViT 从 10 亿参数扩展到 1200 亿参数的工作。我们使用 PyTorch 编写了 ViT,并利用其对 GPU 集群上大规模分布式训练的支持。
在本博客的其余部分,我们将首先讨论主要挑战,即可扩展性、优化和数值稳定性。然后,我们将讨论如何通过数据和模型并行性、自动混合精度、内核融合和bfloat16等技术来解决这些挑战。最后,我们将展示我们的结果并得出结论。
2. 主要挑战
2.1 可扩展性
关键的可扩展性挑战是如何有效地将模型的运算和状态分片到多个 GPU。一个 1000 亿参数的模型,假设采用 fp16 表示,仅参数就需要大约 200GB 的 RAM。因此,模型不可能在一台 GPU 上运行(A100 最多只有 80GB RAM)。因此,我们需要一种有效的方法来将模型的数据(输入、参数、激活和优化器状态)分片到多个 GPU 上。
这个问题的另一个方面是,在不显著改变训练方案的情况下进行扩展。例如,某些表示学习方案使用的全局批大小最高可达 4096,超过这个值就会出现准确性下降。在不使用某种形式的张量或流水线并行的情况下,我们无法扩展到 4096 个以上的 GPU。
2.2 优化
关键的优化挑战在于,即使我们扩展模型参数和浮点运算的数量,也要保持高 GPU 利用率。当我们将模型扩展到每秒万亿次浮点运算及以上时,我们的软件堆栈开始遇到主要的瓶颈,这些瓶颈会超线性地增加训练时间并降低加速器利用率。我们仅运行一个实验就需要数百甚至数千个 GPU。提高加速器利用率可以显著降低成本并提高设备利用率。它使我们能够资助更多的项目并并行运行更多的实验。
2.3 数值稳定性
关键的稳定性挑战是避免在大规模情况下出现数值不稳定和发散。在我们的实验中,我们凭经验观察到,当模型大小、数据、批大小、学习率等扩大时,训练不稳定性会变得严重且难以处理。Vision Transformers 即使在较低的参数阈值下也特别容易出现训练不稳定性。例如,我们发现即使是 ViT-H(仅有 6.3 亿参数)在混合精度模式下,如果不使用强数据增强,也很难训练。我们需要研究模型属性和训练方案,以确保模型训练稳定并收敛。
3. 我们的解决方案
图 1 描绘了我们针对每个挑战的解决方案。
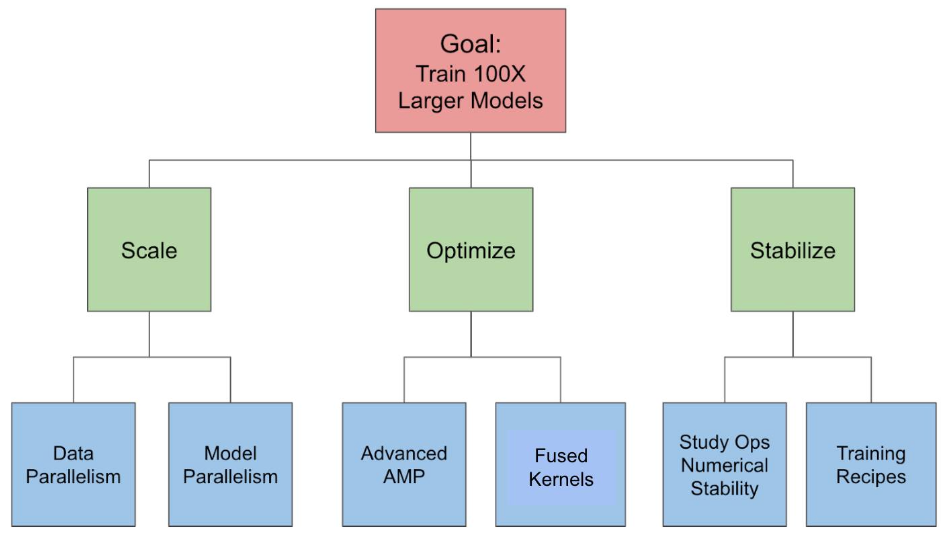
3.1 通过数据并行和模型并行解决扩展挑战
我们采用各种形式的数据和模型并行来使超大型模型适应 GPU 内存。
我们使用基于 PyTorch 的 FairScale 的 FullyShardedDataParallel (FSDP) API [4],将参数、梯度和优化器状态分片到多个 GPU 上,从而减少每个 GPU 的内存占用。此过程包括以下三个步骤:
- 步骤 1:我们将整个模型封装在一个 FSDP 实例中。这会在前向传播结束时分片模型参数,并在前向传播开始时收集参数。这使我们能够将参数从 15 亿扩展到 45 亿,实现了约 3 倍的扩展。
- 步骤 2:我们尝试将单个模型层封装在单独的 FSDP 实例中。这种嵌套封装通过分片和收集单个模型层的参数(而不是整个模型)进一步减少了内存占用。在这种模式下,峰值内存由 GPU 内存中单独封装的 transformer 块决定,而不是整个模型。
- 步骤 3:我们使用激活检查点来减少激活的内存消耗。它保存输入张量,并在前向传播期间丢弃中间激活张量。这些张量在反向传播期间重新计算。
此外,我们还尝试了模型并行技术,例如流水线并行 [5],它允许我们在不增加批处理大小的情况下扩展到更多的 GPU。
3.2 通过高级 AMP 和内核融合解决优化挑战
高级 AMP
自动混合精度(AMP)[6] 训练是指使用低于 FP32 或默认精度的位进行模型训练,同时仍保持准确性。我们尝试了以下三种级别的 AMP:
- AMP O1:这指的是混合精度训练,其中权重采用 FP32,部分操作采用 FP16。使用 AMP O1,可能影响准确性的操作仍保留在 FP32 中,不会自动转换为 FP16。
- AMP O2:这指的是混合精度训练,但与 O1 相比,更多的权重和操作采用 FP16。权重不会隐式保留在 FP32 中,而是转换为 FP16。主权重的一个副本以 FP32 精度保存,供优化器使用。如果需要将归一化层权重保留在 FP32 中,则需要显式使用层封装来确保这一点。
- 完整 FP16:这指的是完全 FP16 训练,其中权重和操作均采用 FP16。由于收敛问题,FP16 训练难以实现。
我们发现 AMP O2 结合 FP32 中的 LayerNorm 封装可以在不牺牲准确性的情况下实现最佳性能。
内核融合
- 为了减少 GPU 内核启动开销并增加 GPU 工作粒度,我们使用 xformers 库 [7] 尝试了内核融合,包括融合 dropout 和融合 layer-norm。
3.3 通过研究操作数值稳定性和训练方案解决稳定性挑战
一般使用 BFloat16,但 LayerNorm 采用 FP32
bfloat16 (BF16) [8] 浮点格式提供与 FP32 相同的动态范围,同时内存占用与 FP16 相同。我们发现,我们可以使用与 FP32 相同的超参数集以 BF16 格式训练模型,而无需进行特殊参数调整。尽管如此,我们发现需要将 LayerNorm 保持在 FP32 模式下才能使训练收敛。
3.4 最终训练方案
最终训练方案总结。
- 将外部模型封装在 FSDP 实例中。在前向传播后启用参数分片。
- 用激活检查点、嵌套 FSDP 封装和参数扁平化来封装单个 ViT 块。
- 启用混合精度模式 (AMP O2),并采用 bfloat16 表示。将优化器状态保持在 FP32 精度以增强数值稳定性。
- 将 LayerNorm 等归一化层封装在 FP32 中以获得更好的数值稳定性。
- 通过将矩阵维度保持为 8 的倍数来最大化 Nvidia TensorCore 利用率。有关更多详细信息,请查看 Nvidia Tensor Core 性能指南。
4. 结果
在本节中,我们展示了 ViT 在三类任务上的扩展结果:(1) 图像分类,(2) 目标检测,(3) 视频理解。我们的关键结果是,在应用了所讨论的扩展和优化技术后,我们能够在这些视觉任务上训练大规模 ViT 主干网络。这使得视觉研究能够以更大的规模进行。我们对模型进行了收敛训练,以验证即使进行了所有优化,我们仍能保持当前的基线。图 2、3、4 的共同趋势是,我们能够在 128 个 A100 GPU 上,在不到 4 小时的 epoch 时间内训练高达 250 亿参数的模型。600 亿和 1200 亿参数的模型训练相对较慢。
图 2 显示了图像分类扩展结果。它绘制了使用 128 个 A100-80GB GPU,针对不同模型大小在 ImageNet 上训练 ViT 的每个 epoch 时间。
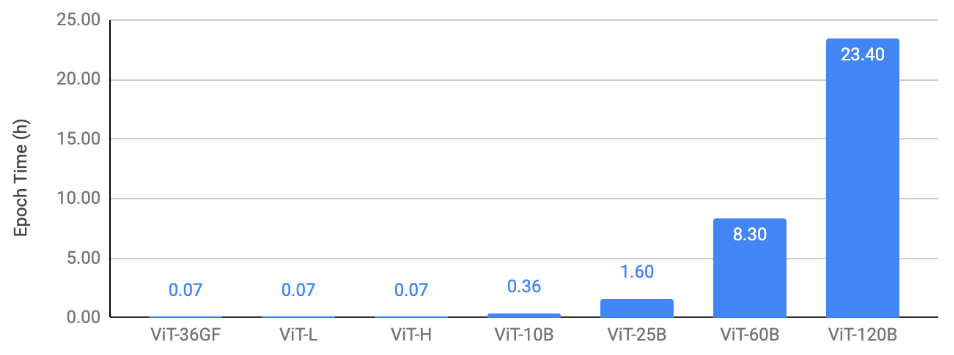
图 2:图像分类扩展结果。
图 3 显示了目标检测扩展结果。它绘制了使用 128 个 A100-80GB GPU,针对不同 ViT 主干在 COCO 上训练 ViTDet [9] 的每个 epoch 时间。
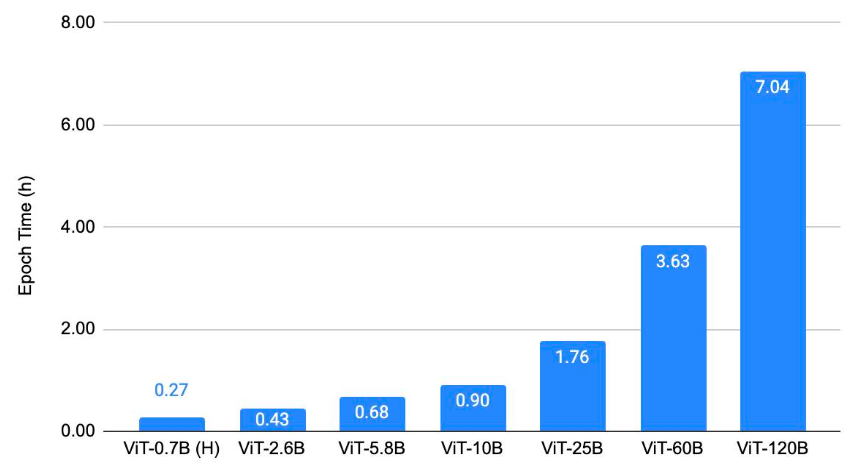
图 3:目标检测扩展结果。
图 4 显示了视频理解的扩展结果。它绘制了使用 128 个 V100(32 GB)GPU 以 FP32 精度,在 Kinetics 400 [11] 上训练 MViTv2 [10] 模型的每个 epoch 时间。
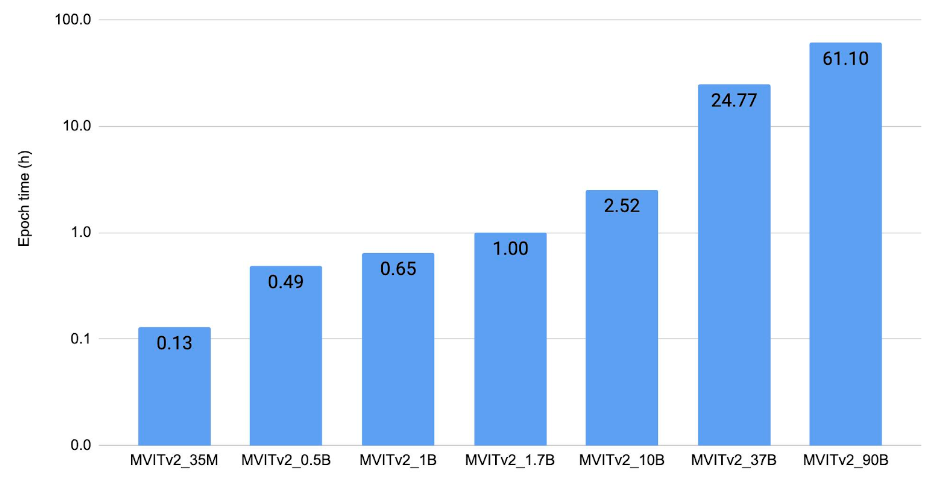
图 4:视频理解扩展结果。
图 5 显示了图 2 中 ViT-H 模型在 8 个 A100-40GB GPU 上的优化结果。使用了三个版本:(1)基线使用 PyTorch 的 DDP [12] 与 AMP O1,(2)FSDP + AMP-O2 + 其他优化,以及(3)FSDP + FP16 + 其他优化。这些优化总共将训练速度提高了 2.2 倍。
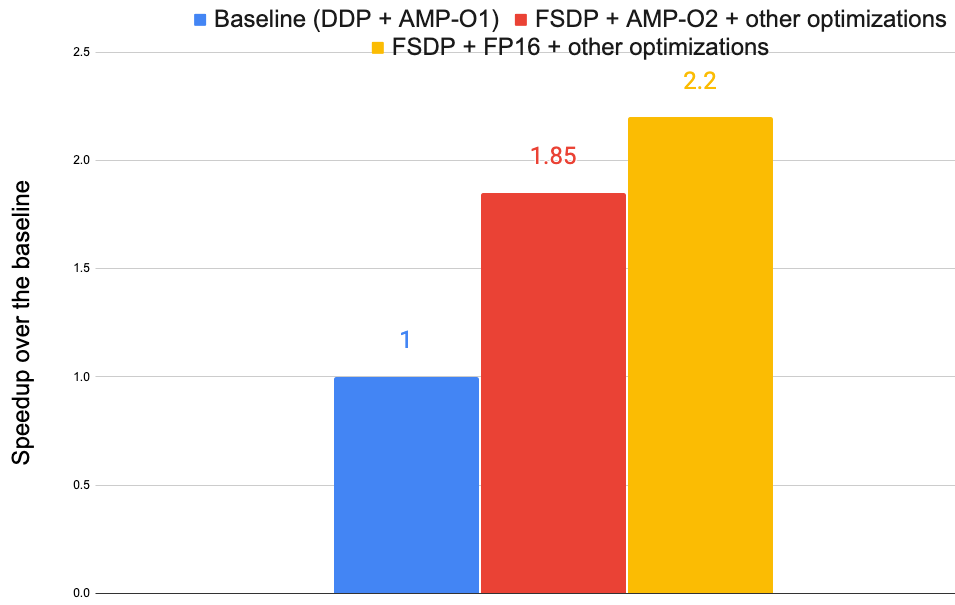
图 5:各种优化带来的训练加速。
5. 总结
我们展示了如何使用 PyTorch 和 FairScale 的 FullyShardedDataParallel (FSDP) API 编写大型视觉 Transformer 模型。我们讨论了在 GPU 集群上扩展和优化这些模型的技术。我们希望本文能激励其他人使用 PyTorch 及其生态系统开发大规模机器学习模型。
参考文献
[1] 掩码自编码器是可扩展的视觉学习器
[3] 一张图片胜过 16x16 个单词:用于大规模图像识别的 Transformer
[4] fairscale.nn.FullyShardedDataParallel
[5] PyTorch 中的流水线并行
[7] xformers
[8] bfloat16 数值格式
[9] 探索用于目标检测的普通视觉 Transformer 主干
[10] MViTv2:改进的多尺度视觉 Transformer 用于分类和检测
[11] https://www.deepmind.com/open-source/kinetics
[12] 分布式数据并行 (DDP) 入门