在 Meta,推荐系统是向全球数十亿用户提供相关和个性化广告的基石。通过 PyTorch 的 TorchRec 等技术,我们成功开发了能够在数百个 GPU 上进行模型训练的解决方案。尽管这些系统运行良好,但最近关于扩展定律的研究揭示了一个引人注目的机会:通过训练更大规模的神经网络,我们可以实现显著更好的模型性能。
然而,这一洞察给我们带来了新的挑战。我们当前的训练基础设施虽然针对数百个 GPU 进行了高度优化,但无法有效地扩展到训练这些更大模型所需的数千个 GPU。从数百个到数千个 GPU 的飞跃带来了复杂的技术挑战,特别是在处理推荐模型中的稀疏操作方面。这些挑战需要根本性的分布式训练新方法,我们通过一种新颖的并行化策略来解决这些问题。
为了解决这些问题,我们引入了二维嵌入并行,这是一种新颖的并行化策略,克服了在数千个 GPU 上训练大型推荐模型固有的稀疏扩展挑战。现在,通过 TorchRec 中的 DMPCollection API,该功能已可用。 这种方法结合了两种互补的并行化技术:针对模型的稀疏组件的数据并行和针对嵌入表的模型并行,利用了 TorchRec 强大的分片能力。通过策略性地整合这些技术,我们创建了一个可以扩展到数千个 GPU 的解决方案,现在为 Meta 最大的推荐模型训练运行提供支持。
什么是稀疏扩展挑战?
我们确定了三个关键挑战,它们阻碍了我们将模型天真地扩展到数千个 GPU:
- 不平衡和慢节点问题: 随着 GPU 数量的增加,实现平衡分片变得更加困难,一些节点可能承担更重的嵌入计算工作负载,这会减慢整个训练过程。
- 跨节点通信: 随着训练作业使用的 GPU 数量增加,在某些网络拓扑下,all-to-all 通信带宽可能会下降,这会显著增加通信延迟。
- 内存开销: 输入特征使用的内存通常可以忽略不计,但是,当我们使用数千个 GPU 时,我们可以引入更大的输入特征,并且内存需求可能会变得非常大。
通过二维嵌入并行,我们可以像这样描述我们的新并行方案,在这个例子中,我们有 2 个模型副本(副本 1:GPU1/GPU3,副本 2:GPU2/GPU4)。
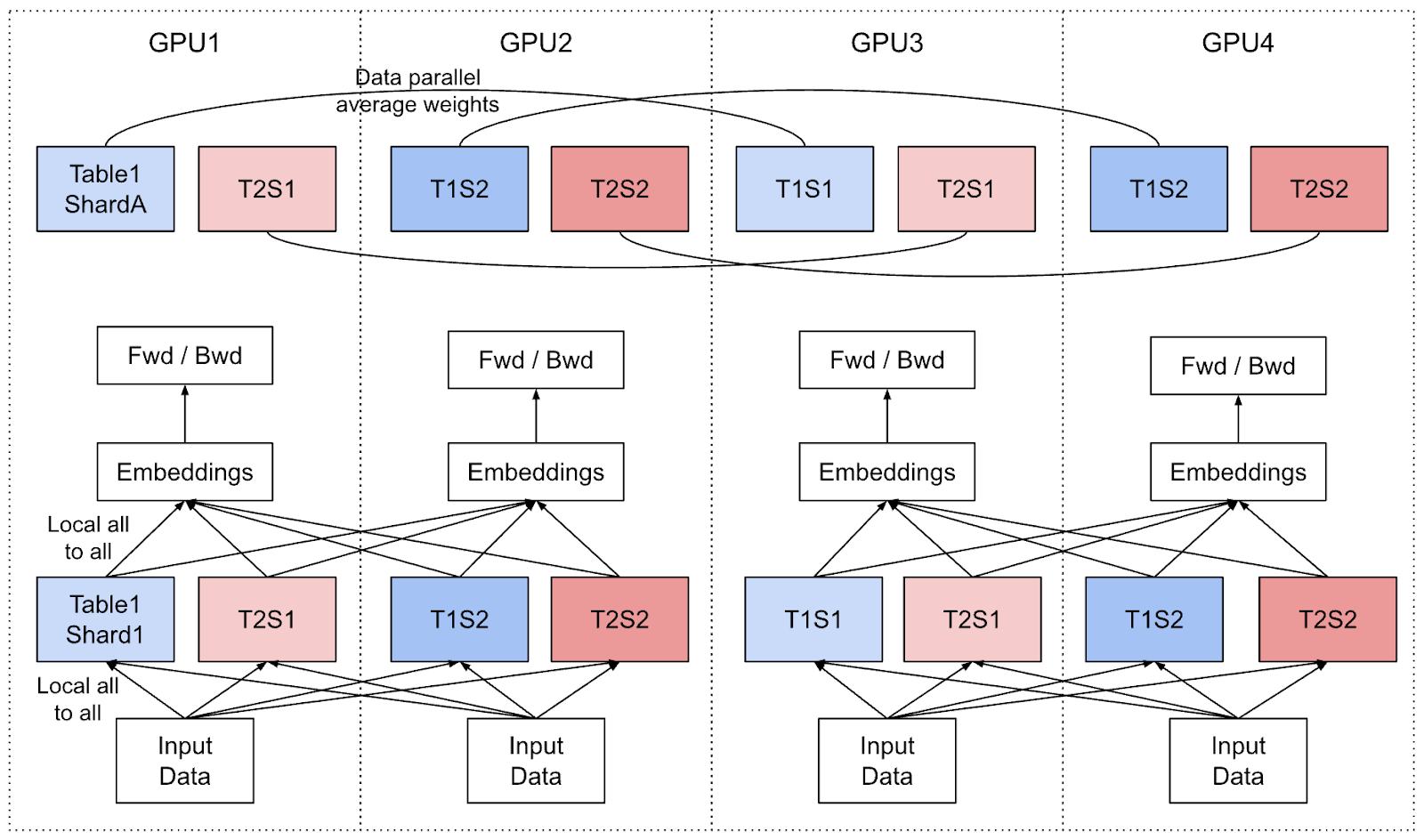
图 1:二维稀疏并行的布局图
通过二维稀疏并行,我们解决了这些挑战,我们不再将表分片到所有节点,而是首先将所有节点平均分成几个并行组。
- 在每个组内,我们对嵌入表使用模型并行,例如列式/行式分片。在大规模部署中,对于我们最大的表,我们还开发了网格分片,它在行和列维度上对嵌入表进行分片。
- 在组间,我们进行数据并行,使得每个组中的每个节点在其他组中都有其对应的副本节点(副本节点意味着存储相同的嵌入表分片)。
- 每个组完成其自己的反向传播后,我们对所有副本的嵌入表权重进行 All-Reduce 操作以保持它们同步。
我们的生产解决方案
TorchRec 是我们在原生 PyTorch 中构建推荐模型稀疏部分的库。传统的 API 是 DistributedModelParallel,它将模型并行应用于嵌入表。我们引入了一个新的 API,称为 DMPCollection,它作为在 TorchRec 模型上启用二维并行化的主要入口点。我们设计它使其像应用 FSDP/DDP 一样简单易行。
要理解 DMPCollection 的作用,我们首先需要理解 DistributedModelParallel (DMP) 的作用:
- 创建嵌入表,称为 EmbeddingBagCollection 和 EmbeddingCollections。
- 根据 GPU 拓扑、嵌入表、可用内存、输入数据等生成分片计划。
- 使用 DMP 和传入的相关分片计划包装模型。
- DMP 根据分片计划初始化和分片嵌入表。
- 在训练步骤中,DMP 接收一个输入批次,将其通信到包含感兴趣的嵌入表分片的适当 GPU,查找值,然后将其返回给请求它的 GPU。这都是在全局进程组上完成的,特殊分片(例如表行式分片)除外。
DistributedModelParallel 是为模型并行而构建的,许多部分都假设分片并围绕全局世界大小工作。我们需要以一种我们可以引入额外并行维度而又不失去 TorchRec 优化和功能集的方式来改变这些部分。
DMPCollection 改变了几个关键部分,以可扩展的方式启用二维并行:
- 为较小的分片组生成一次分片计划,一旦传入,我们将其通信到全局组中适当的节点,并重新映射节点以适应新的分片组节点。
- 创建两个新的 NCCL 进程组,称为分片进程组和副本进程组。分片进程组被传递给 TorchRec 的分片和训练步骤组件。副本进程组用于权重和优化器状态同步,All-Reduce 调用在此进程组上发生。
- 子 NCCL 进程组允许我们只在与特定通信相关的节点之间高效通信。每个节点将有两个关联的进程组。
对用户来说,更改非常简单,同时消除了将并行策略应用于模型的所有复杂性。
我们如何创建这些分片组和复制组?
这些进程组是 DMPCollection 高性能实现的关键之一。从我们之前的图中,我们展示了一个简单的 2×2 GPU 设置,但是,在大规模部署中,我们如何分配哪些节点属于给定的分片组,以及它们在分片组中的副本节点是什么?
考虑以下设置:2 个节点,每个节点有 4 个 GPU。二维并行下的分片组和复制组将是:
| 分片组 | 分片节点 0 | 0, 2, 4, 6 1 | 1, 3, 5, 7 |
复制组 | 复制节点 0 | 0, 1 1 | 2, 3 2 | 4, 5 3 | 6, 7 |
我们使用以下公式:
- 将所有训练器分成 G 个分片组,每个组有 L 个训练器。
- 组 G 由 G = T / L 确定,其中 T 是训练器总数。
- 对于每个组 G,我们根据其所在的组分配非连续的训练器节点,如下:
- [i, G+i, 2G+i, ..., (L – 1) G+i],其中 *i = 0 到 G-1*
- 从组 G 中,我们可以创建复制组,即每 G 个连续的节点。
- (0 到 G-1, G 到 2*G – 1) 每个连续集合存储重复的嵌入表分片。
这意味着我们的分片组 G 的大小为 L,可以认为是应用模型并行的节点数量。这反过来又给我们带来了复制组,每个组的大小为 G,这些是我们进行数据并行的节点。
在 DMPCollection 中,我们能够利用 DeviceMesh 高效地创建这些进程组,我们将整个 GPU 拓扑创建为一个 2×2 矩阵,其中每行代表分片节点组,每列代表相应的副本节点:
create peer matrix
num_groups = global_world_size // sharding_group_size
for each group_rank in num_groups:
peers = [num_groups * rank + group_rank for rank in range(sharding_group_size)]
add peer to peer matrix
initalize DeviceMesh with two dimensions (shard, replicate)
slice DeviceMesh on shard for sharding process group
slide DeviceMesh on replicate for replica process group
通过我们的 DeviceMesh 方法,如果未来我们想改变拓扑结构或提供更大的灵活性,我们可以轻松地将我们的创建逻辑扩展到任何形式的拓扑结构,甚至在需要时扩展到更多的并行维度。
二维并行性能
我们的节点分区策略通过战略性地将每个分片的模型副本节点放置在同一计算节点内来优化通信模式。这种架构为权重同步操作提供了显著的性能优势。在反向传播之后,我们执行 All-Reduce 操作以同步模型权重——考虑到我们必须通信和同步的大量参数,这是一个昂贵的过程——通过我们将在同一节点上放置副本的设置,我们利用了节点内的高带宽,而不是过度依赖较慢的节点间带宽。
这种设计选择对其他通信集合的影响通常会缩短延迟。这种改进源于两个因素。
- 通过将嵌入表分片到更少的节点,并在较小的组内进行模型的通信,我们实现了更低的 all-to-all 延迟。
- 通过二维并行中的复制,我们的节点上的嵌入查找延迟降低了,我们可以将局部批次大小减小到等效全局批次大小的 1/N,其中 N 是模型副本的数量。
一个生产模型跟踪示例了这两个因素,这里我们在 1024 个 GPU 上运行二维并行作业,分片组大小为 256 个 GPU。

图 2:比较非二维并行和二维并行工作负载之间的延迟
用户有两个关键杠杆可以调整,以最大化其工作负载的性能:
- 模型分片组相对于全局世界大小的大小。全局世界大小除以分片组大小表示我们将拥有的模型副本数量。
- 为了最大化性能,用户可以尝试将模型扩展到 8 倍,此扩展因子可维持主机内 All-Reduce。
- 为了进一步扩展,All-Reduce 必须在主机间进行。根据我们的实验,我们没有看到明显的性能下降,实际上注意到了主机间 All-Reduce 的优势。我们可以将我们的分片和副本拓扑更改为主机间 All-Reduce,这有助于我们在特定主机发生故障时引入容错策略。
- 为了最大化性能,用户可以尝试将模型扩展到 8 倍,此扩展因子可维持主机内 All-Reduce。
- All-Reduce 同步的频率,DMPCollection 带有一个 sync() 调用,可以调整为每 N 个训练步骤调用一次,执行一种局部 SGD 训练。随着规模的扩大,降低同步频率可以显著提高性能。
未来工作
读者应注意,二维稀疏并行训练与非并行训练不同,因为我们同步的是嵌入表权重而不是梯度。这种方法之所以可行,得益于 TorchRec 使用了 FBGEMM,它在底层提供了优化的核。FBGEMM 的一个关键优化是在反向传播中融合了优化器。它不是完全实例化嵌入表梯度(这会消耗大量内存),而是将它们直接传递给优化器更新。尝试实例化和同步这些梯度会产生巨大的开销,使得这种方法不切实际。
我们的探索发现,为了获得与基线相当的训练结果,我们以延迟的调度方式同步优化器状态,其时间取决于分片/复制组的数量(例如:对于 Adagrad,我们将动量更新延迟一个同步步骤)。这种方法还允许用户实现局部 SGD 或半同步训练策略,这可以实现收敛并可能产生比基线更好的损失曲线。
感谢您阅读我们的文章!这是一个我们遇到的令人兴奋的方向,我们希望进一步发展它,以最大限度地提高推荐系统的性能并推动最先进技术的发展。