鉴于基础模型的出现和成功,许多企业对使用云原生方法进行大型模型训练的兴趣日益增长。一些人工智能从业者可能认为,要实现分布式训练作业的高 GPU 利用率,唯一的方法是在 HPC 系统(例如通过 Infiniband 互连的系统)上运行它们,并且可能不考虑以太网连接的系统。我们演示了 PyTorch 最新的分布式训练技术——完全分片数据并行 (FSDP) 如何在 IBM Cloud 中使用商用以太网成功扩展到参数超过 100 亿的模型。
PyTorch FSDP 扩展
随着模型变得越来越大,标准的数据并行训练技术仅在 GPU 能够容纳模型的完整副本及其训练状态(优化器、激活等)时才有效。然而,GPU 内存的增加未能跟上模型大小的增加,因此出现了训练此类模型的新技术(例如,完全分片数据并行、DeepSpeed),这使我们能够在训练期间有效地将模型和数据分布到多个 GPU 上。在这篇博文中,我们展示了一种方法,可以使用 PyTorch 原生 FSDP API 将模型训练显着扩展到 64 个节点(512 个 GPU),同时将模型大小增加到 110 亿。
什么是完全分片数据并行?
FSDP 通过将模型参数、梯度和优化器状态分片到 K 个 FSDP 单元(由包装策略决定)来扩展分布式数据并行训练 (DDP) 方法。FSDP 通过显著减少每个 GPU 上的内存占用并重叠计算和通信,在资源和性能方面实现了大型模型训练效率。
通过让所有 GPU 拥有每个 FSDP 单元的一部分来减少内存占用,从而实现资源效率。为了处理给定的 FSDP 单元,所有 GPU 通过 all_gather 通信调用共享其本地拥有的部分。
通过将即将到来的 FSDP 单元的 all_gather 通信调用与当前 FSDP 单元的计算重叠,实现性能效率。一旦当前 FSDP 单元处理完毕,非本地拥有的参数将被丢弃,从而为即将到来的 FSDP 单元释放内存。此过程通过计算和通信的重叠实现训练效率,同时还减少了每个 GPU 所需的峰值内存。
接下来,我们将演示 FSDP 如何使我们能够在分布式训练作业中保持数百个 GPU 的高利用率,同时在标准以太网网络上运行(系统描述在博客末尾)。我们选择 T5 架构进行实验,并利用了FSDP 研讨会的代码。在我们的每个实验中,我们都从单个节点实验开始创建基线,并报告按批大小归一化的每迭代秒数指标,并根据Megatron-LM 论文计算 teraflops(有关 T5 的 teraflop 计算详情,请参见附录)。我们的实验旨在最大化批大小(同时避免 cudaMalloc 重试),以充分利用计算和通信中的重叠,如下所述。扩展被定义为 N 个节点的每迭代秒数(按批大小归一化)与单个节点的比率,表示随着添加更多节点,我们能多好地利用额外的 GPU。
实验结果
我们使用 T5-3B 配置(BF16 混合精度、激活检查点和 Transformer 包装策略)进行的第一组实验表明,随着我们将 GPU 数量从 8 个增加到 512 个(分别对应 1 到 64 个节点),扩展效率达到 95%。我们无需对现有 FSDP API 进行任何修改就取得了这些结果。我们观察到,在这种规模下,基于以太网的网络有足够的带宽来实现通信和计算的持续重叠。
然而,当我们将 T5 模型大小增加到 110 亿时,扩展效率大幅下降至 20%。PyTorch 分析器显示,通信和计算的重叠非常有限。进一步调查网络带宽使用情况表明,重叠不佳是由单个数据包通信中的延迟引起的,而不是所需的带宽(事实上,我们的峰值带宽利用率仅为可用带宽的 1/4)。这使我们推测,如果通过增加批大小来增加计算时间,我们可以更好地重叠通信和计算。然而,鉴于我们已经达到最大 GPU 内存分配,我们必须寻找重新平衡内存分配的机会,以允许增加批大小。我们发现模型状态分配的内存比实际需要的多得多。这些预留的主要功能是预留内存,以便在通信期间积极发送/接收张量,而缓冲区过少会导致等待时间增加,而缓冲区过多会导致批大小减小。
为了实现更高的效率,PyTorch 分布式团队引入了一个新的控制旋钮,即 `rate_limiter`,它控制为张量发送/接收分配的内存量,从而缓解内存压力并为更高的批次大小提供空间。在我们的案例中,`rate_limiter` 可以将批次大小从 20 增加到 50,从而将计算时间增加 2.5 倍,并允许通信和计算之间有更大的重叠。通过此修复,我们将扩展效率提高到 >75%(在 32 个节点上)!
对限制扩展效率的因素的持续调查发现,速率限制器正在创建 GPU 空闲时间的重复流水线气泡。这是由于速率限制器对每组内存缓冲区的分配和释放采用了阻塞和刷新方法。通过等待整个块完成才启动新的 all_gather,GPU 在每个块开始时都处于空闲状态,等待新的 all_gather 参数集到达。通过采用滑动窗口方法缓解了这种气泡。在单个 all_gather 步骤及其计算完成(而不是一整块)后,内存被释放,并且下一个 all_gather 以更均匀的方式立即发出。这一改进消除了流水线气泡,并将扩展效率提高到 >90%(在 32 个节点上)。
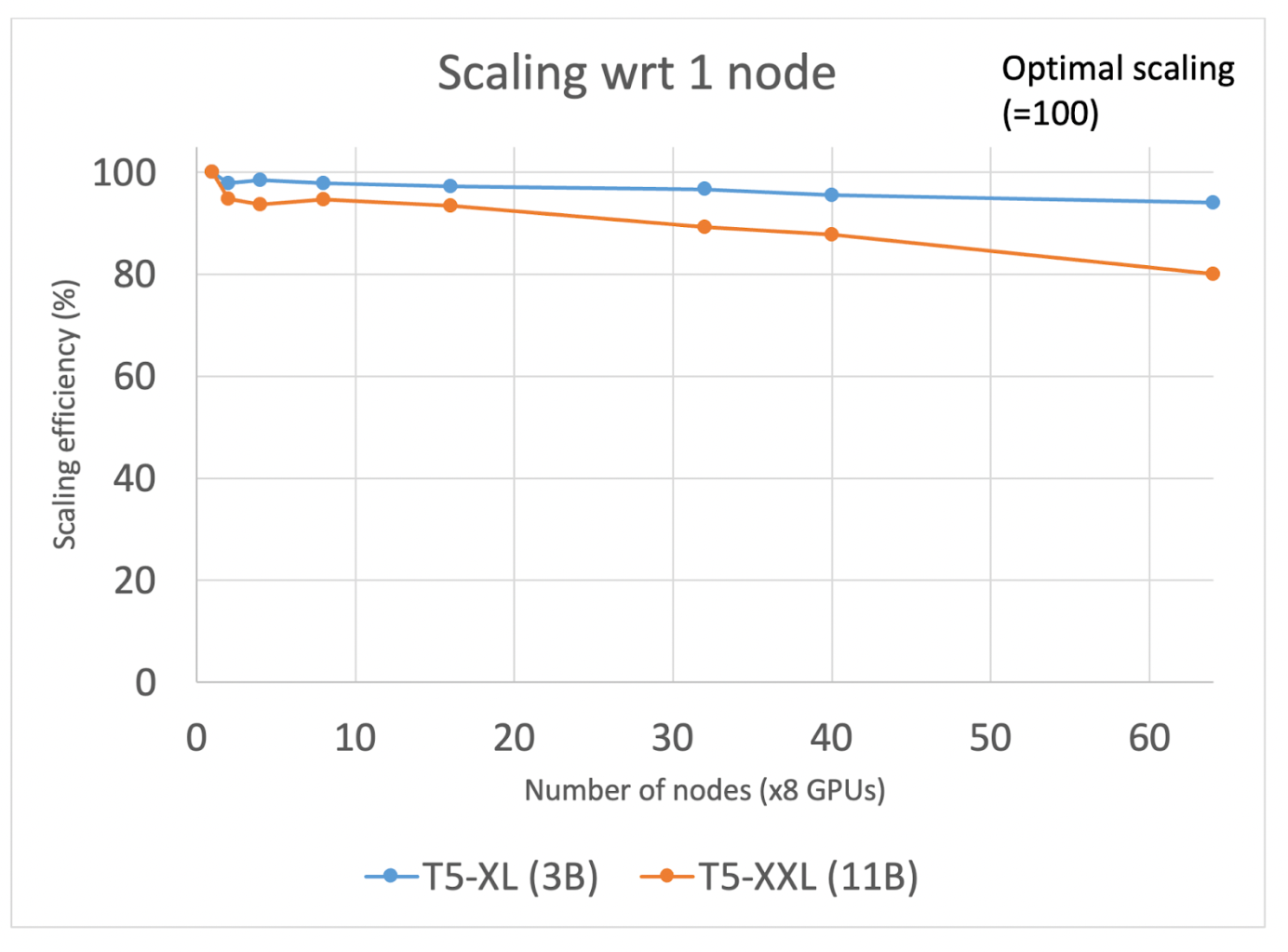
图 1:T5-XL (3B) 和 T5-XXL (11B) 从 1 个节点扩展到 64 个节点
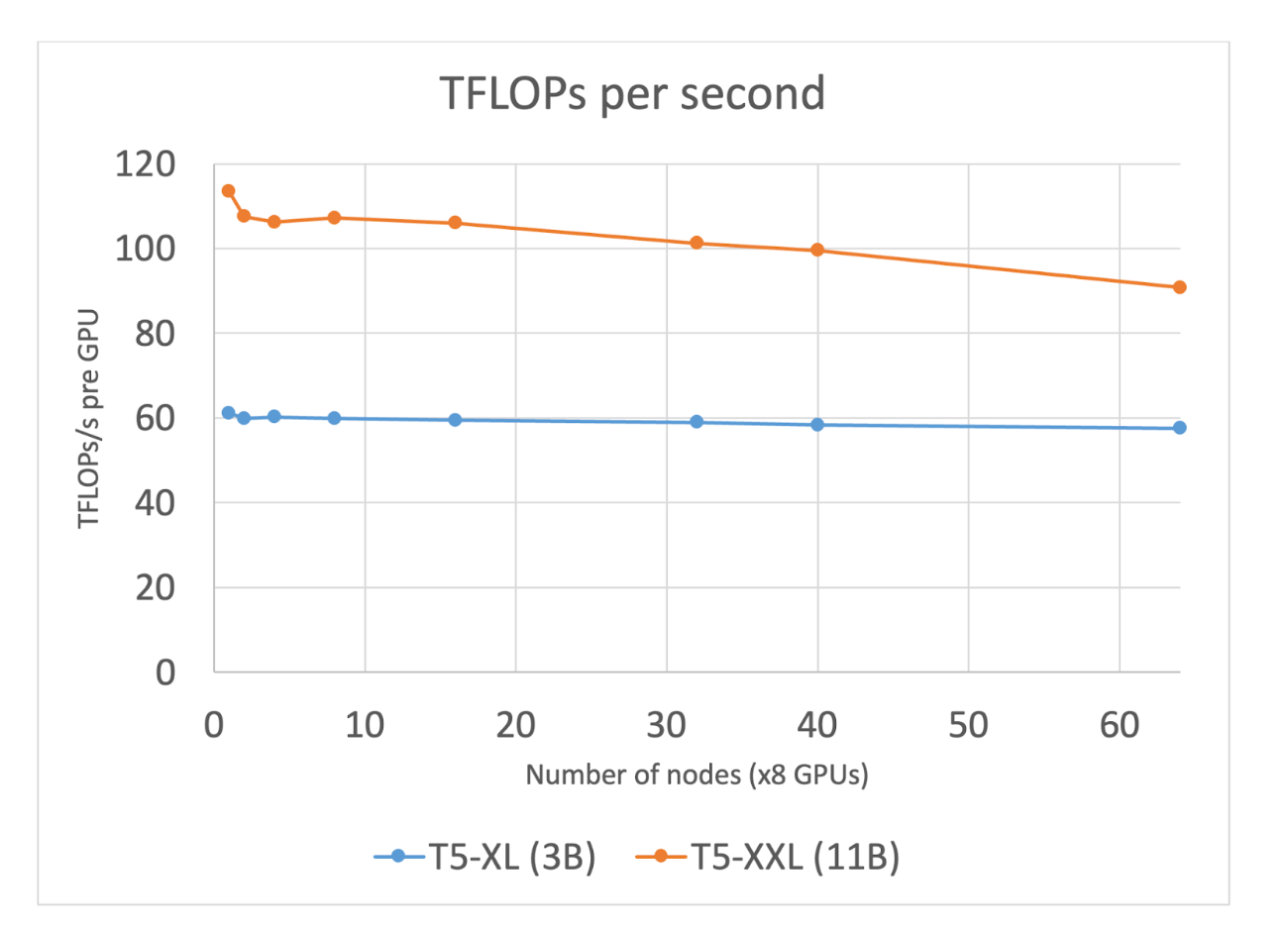
图 2:随着节点数量的增加,T5-XL(3B) 和 T5-XXL (11B) 的 TFLOPs/sec 使用量
IBM Cloud AI 系统和中间件
用于此工作的 AI 基础设施是 IBM Cloud 上的一个大规模 AI 系统,由近 200 个节点组成,每个节点都配备 8 块 NVIDIA A100 80GB 显卡、96 个 vCPU 和 1.2TB CPU RAM。节点内的 GPU 显卡通过 NVLink 连接,卡间带宽为 600GBps。节点通过 2 条 100Gbps 以太网链路连接,采用基于 SRIOV 的 TCP/IP 堆栈,提供 120Gbps 的可用带宽。
IBM Cloud AI 系统自 2022 年 5 月起已准备好投入生产,并配置了 OpenShift 容器平台以运行 AI 工作负载。我们还构建了一个用于生产 AI 工作负载的软件堆栈,提供端到端工具用于训练工作负载。该中间件利用 Ray 进行预处理和后处理工作负载,并利用 PyTorch 进行模型训练。我们还集成了 Kubernetes 原生调度器 MCAD,它通过作业排队、组调度、优先级和配额管理来管理多个作业。多 NIC CNI 发现所有可用的网络接口,并将其作为一个单一的 NIC 池进行处理,从而优化 Kubernetes 中网络接口的使用。最后,CodeFlare CLI 支持使用桌面 CLI(例如,GPU 利用率、损失、梯度范数等应用程序指标)对整个堆栈进行单一面板的可观察性。
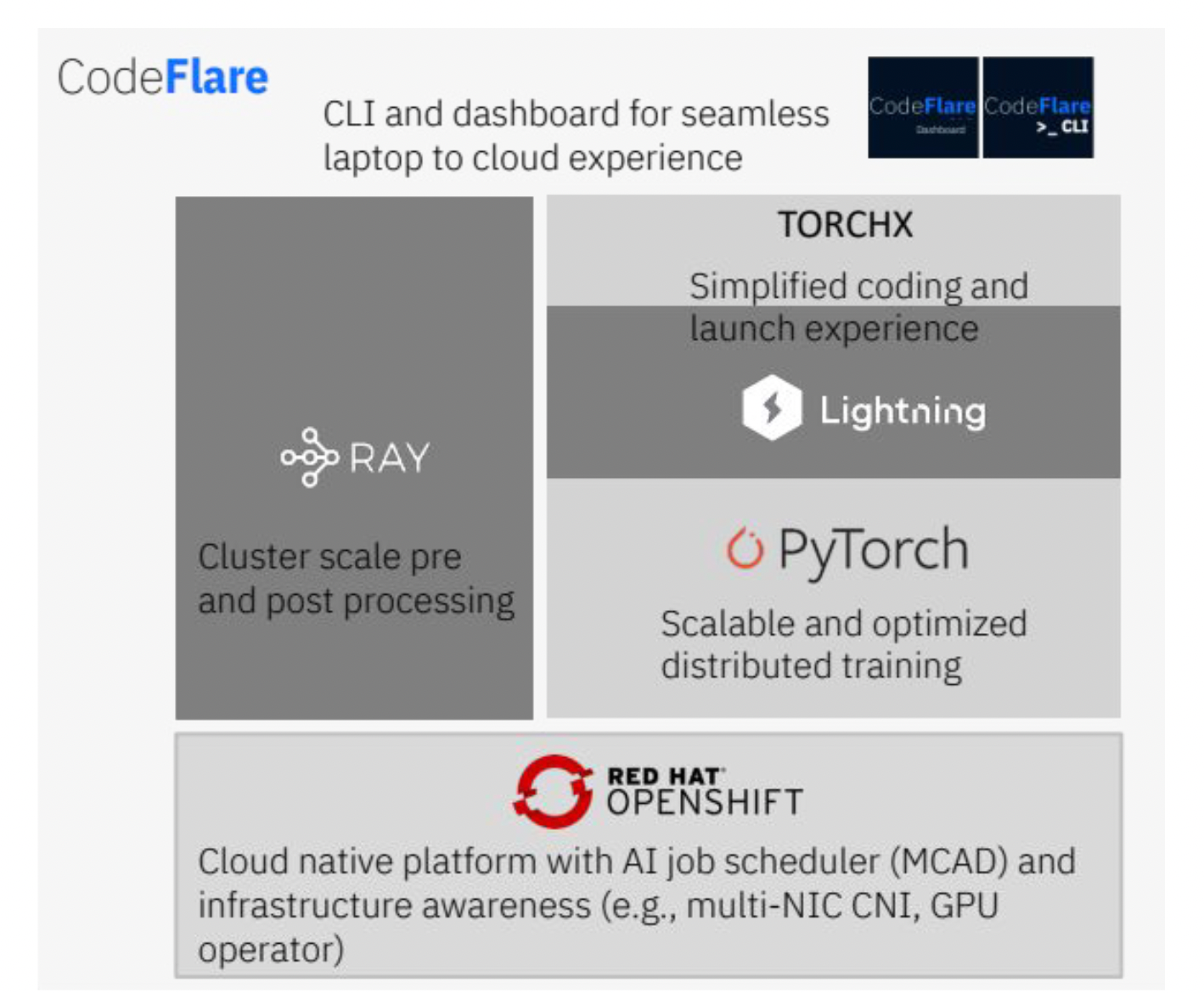
图 3:基础模型中间件堆栈
结论和未来工作
总之,我们演示了如何在非 InfiniBand 网络上实现 FSDP API 的卓越扩展。我们确定了限制 110 亿参数模型训练效率低于 20% 的瓶颈。在识别问题后,我们通过新的速率限制器控制解决了这个问题,以确保预留内存和通信重叠相对于计算时间达到更优化的平衡。通过这一改进,我们成功地将 110 亿参数模型的训练效率提高到 90%(提高了 4.5 倍,在 256 个 GPU 上)和 80%(在 512 个 GPU 上)。此外,即使我们将 GPU 数量增加到 512 个,30 亿参数模型的扩展效率也极高,达到 95%。
这是业界首次使用 Kubernetes、标准以太网和 PyTorch 原生 FSDP API,实现高达 110 亿参数模型的如此高的扩展效率。这一改进使用户能够以经济高效和可持续的方式在混合云平台上训练大型模型。
我们计划继续研究仅解码器模型的扩展,并将这些模型的规模扩大到 1000 亿个参数以上。从系统设计的角度来看,我们正在探索 RoCE 和 GDR 等功能,这些功能可以改善以太网网络上的通信延迟。
致谢
本博客的实现得益于 PyTorch 分布式团队和 IBM 研究团队的贡献。
我们衷心感谢 PyTorch 分布式团队的 Less Wright、Hamid Shojanazeri、Geeta Chauhan、Shen Li、Rohan Varma、Yanli Zhao、Andrew Gu、Anjali Sridhar、Chien-Chin Huang 和 Bernard Nguyen。
我们衷心感谢 IBM 研究团队的 Linsong Chu、Sophia Wen、Lixiang (Eric) Luo、Marquita Ellis、Davis Wertheimer、Supriyo Chakraborty、Raghu Ganti、Mudhakar Srivatsa、Seetharami Seelam、Carlos Costa、Abhishek Malvankar、Diana Arroyo、Alaa Youssef 和 Nick Mitchell。
附录
浮点运算次数计算
T5-XXL(110 亿)架构有两种类型的 T5 块,一种是编码器,另一种是解码器。遵循 Megatron-LM 的方法,其中每个矩阵乘法需要 2m×k×n 次浮点运算,第一个矩阵的大小为 m×k,第二个矩阵的大小为 k×n。编码器块由自注意力层和前馈层组成,而解码器块由自注意力层、交叉注意力层和前馈层组成。
注意力块(自注意力和交叉注意力)包括 QKV 投影,需要 6Bsh2 次操作;注意力矩阵计算,需要 2Bs2h 次操作;对值的注意力,需要 2Bs2h 次计算;以及注意力后线性投影,需要 2Bsh2 次操作。最后,前馈层需要 15Bsh2 次操作。
编码器块的总数为 23Bsh2+4Bs2h,而解码器块的总数为 31Bsh2+8Bs2h。总共有 24 个编码器和 24 个解码器块,以及 2 个前向传播(因为我们丢弃了激活)和 1 个后向传播(相当于 2 个前向传播),最终的 FLOPs 计算结果为 96×(54Bsh2+ 12Bs2h) + 6BshV。其中,B 是每个 GPU 的批大小,s 是序列长度,h 是隐藏状态大小,V 是词汇大小。我们对略有不同的 T5-XL(30 亿)架构重复了类似的计算。