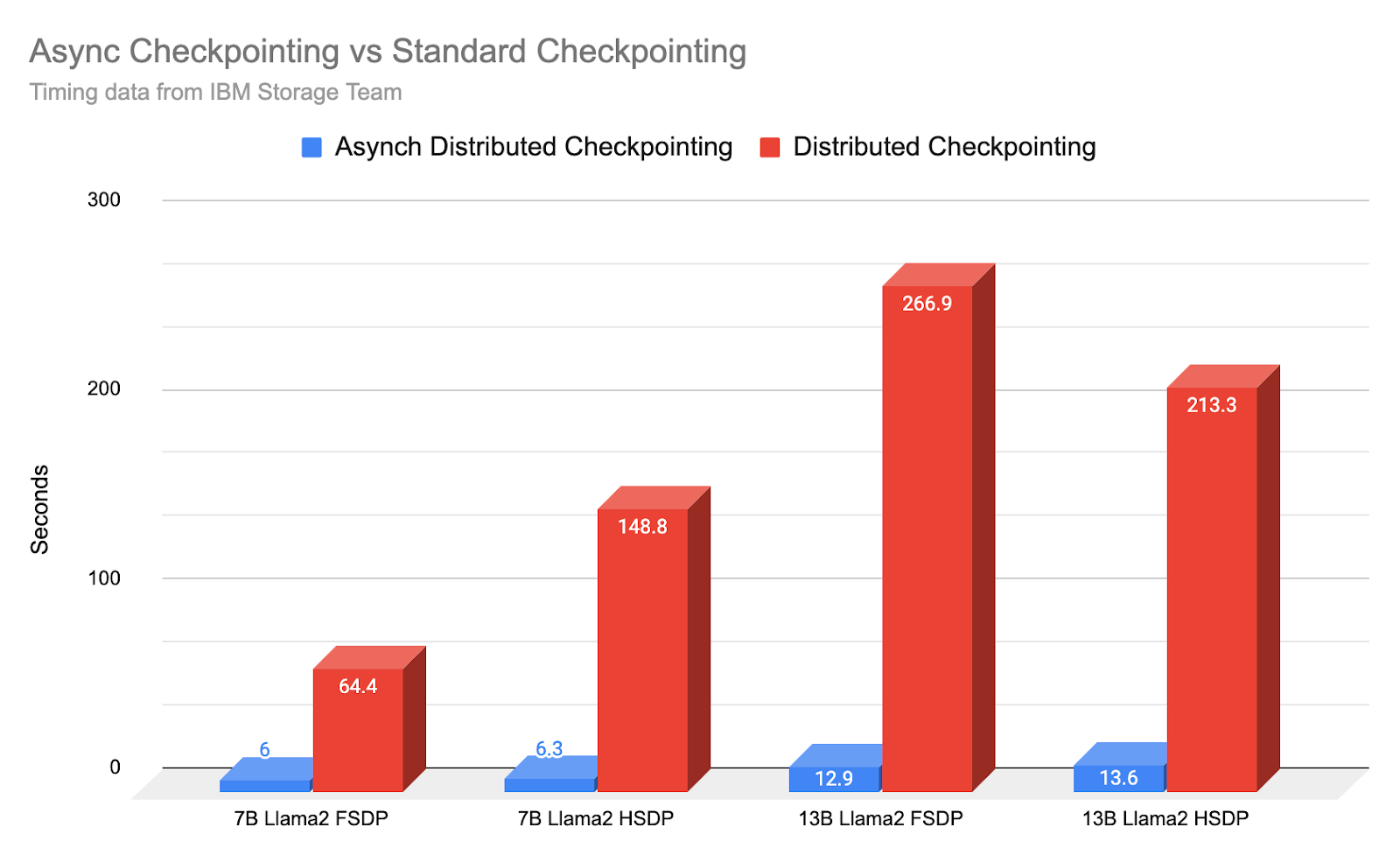
摘要: PyTorch 分布式新的异步检查点功能是在 IBM 的反馈下开发的,我们展示了 IBM 研究团队如何实现并将有效检查点时间缩短 10-20 倍。示例:7B 模型的检查点“停机时间”从平均 148.8 秒缩短到 6.3 秒,速度提高了 23.62 倍。
这直接意味着在每个 24 小时周期内获得更多的净训练进展,同时继续稳健地进行检查点,或者更频繁地进行检查点以缩短恢复窗口/时间。
在本说明中,我们展示了使异步检查点成为可能的使用代码和架构,以及经 IBM 研究团队验证的计时结果。
模型检查点是大型模型训练的重要组成部分,但检查点是一个昂贵的过程,因为每个检查点过程都涉及阻塞训练进程以保存最新的模型权重。然而,不进行检查点或减少检查点频率可能会导致训练进展的显著损失。例如,死锁、落后者和 GPU 错误等故障需要重新启动训练过程。为了从故障中重新启动,所有(训练)工作器都必须停止其训练过程并从上次保存的检查点重新启动。
因此,对故障的鲁棒性与训练进展之间的内在张力表现为一种权衡,但现在有了异步检查点,PyTorch Distributed 能够显著减少这种张力,并以对整体训练时间的最小影响实现频繁检查点。
作为背景,大约一年前,我们展示了分布式检查点如何大大加快了检查点时间,与原始的 torch.save() 功能相比。正如 IBM 研究院所指出的,torch.save 可能需要长达 30 分钟才能检查点单个 11B 模型(PyTorch 1.13)。
随着分布式检查点的进步,对于高达 30B 模型尺寸,检查点可以在 4 分钟内完成。
通过异步检查点,由于检查点而损失的训练时间现在缩短到 30 秒以内,通常甚至短至 6 秒。
需要明确的是,异步检查点并没有像之前的更新所展示的那样压缩实际的序列化检查点时间。相反,它将最终的检查点过程移出了关键路径(移到 CPU 线程),以允许 GPU 训练继续进行,同时在单独的线程下完成检查点。
然而,对于用户而言,效果几乎相同,因为由于检查点造成的训练停机时间大幅减少,在许多情况下甚至减少了 10 倍或 20 倍。
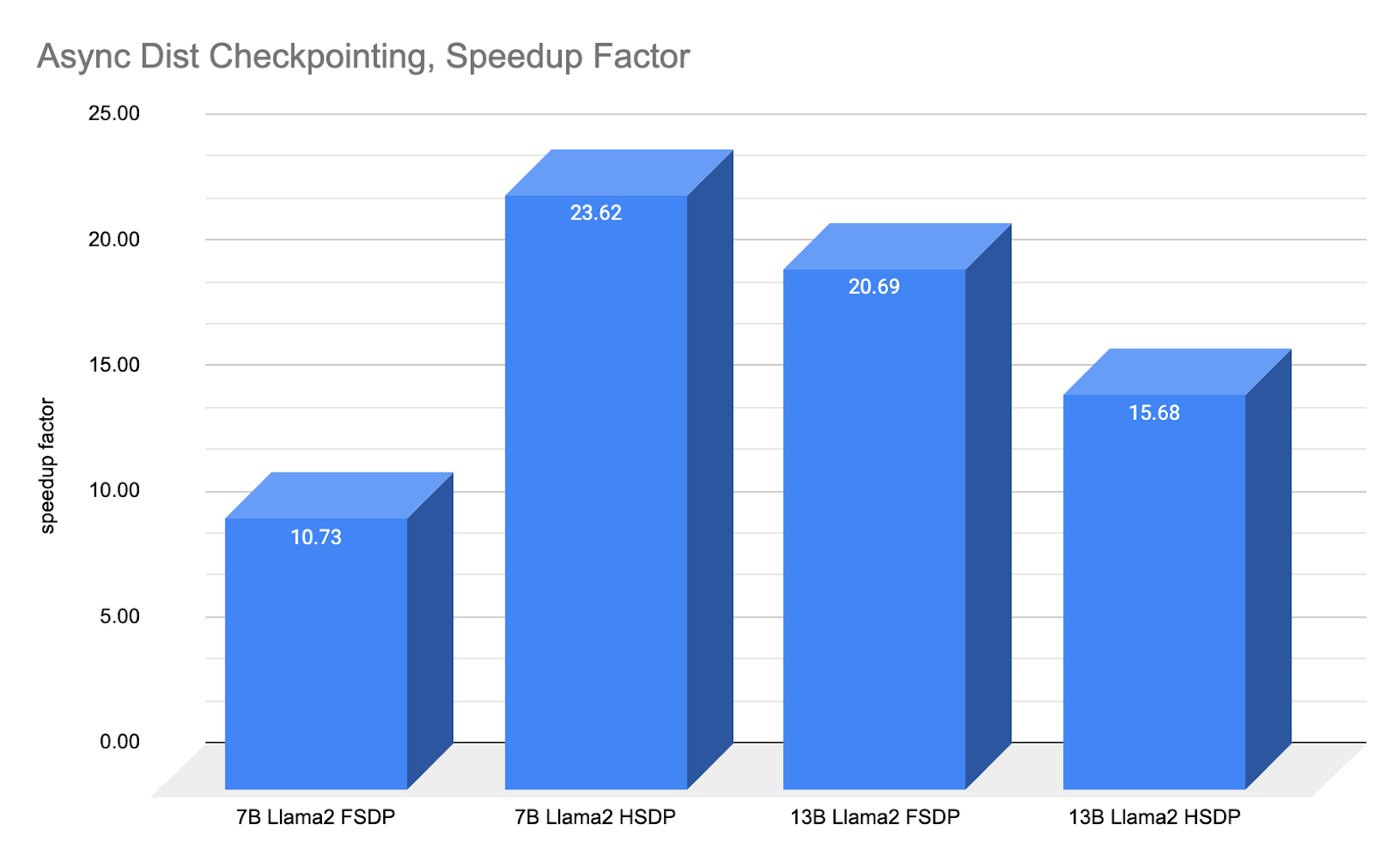
如上图所示,异步检查点在去年已取得的巨大改进基础上,进一步提高了 10 到 23 倍。
异步检查点如何工作?
异步检查点将检查点过程模块化为两个部分,而不是一个单一的整体过程。第一阶段将数据从每个 GPU/rank 从 GPU 复制到 CPU。这是用户可见的停机时间,对于 7B-13B 模型尺寸,可能需要 6-14 秒。第二阶段异步地将数据从 CPU 内存复制到磁盘以持久化检查点。
一旦数据在第一阶段复制到 CPU,GPU 就可以立即恢复训练。因此,使用异步检查点时,检查点的停机时间就是将最新模型状态复制到 CPU 所需的时间。
在训练恢复的同时,非阻塞 CPU 线程使用内存中新到达的数据完成完整的检查点/序列化过程到磁盘(即持久保存)。

请注意,PyTorch 的分布式检查点器依赖于用于优化保存所需的每个 rank 元数据的集体通信调用,以及一个最终同步,该同步标记检查点已完成并使操作原子化。如果检查点线程使用与训练相同的进程组,这可能会干扰分布式训练(因为分布式训练也依赖于类似的调用来跨多个 GPU 同步训练)。
具体来说,这些调用之间的竞争条件可能会导致训练和异步检查点保存线程同时等待集体调用,从而导致真正的集体挂起。
我们通过为异步检查点初始化一个单独的进程组来避免这种情况。这将检查点集合操作分离到它们自己的逻辑进程组中,从而确保它不会干扰主训练线程中的集合调用。
如何在我的训练中使用异步检查点?
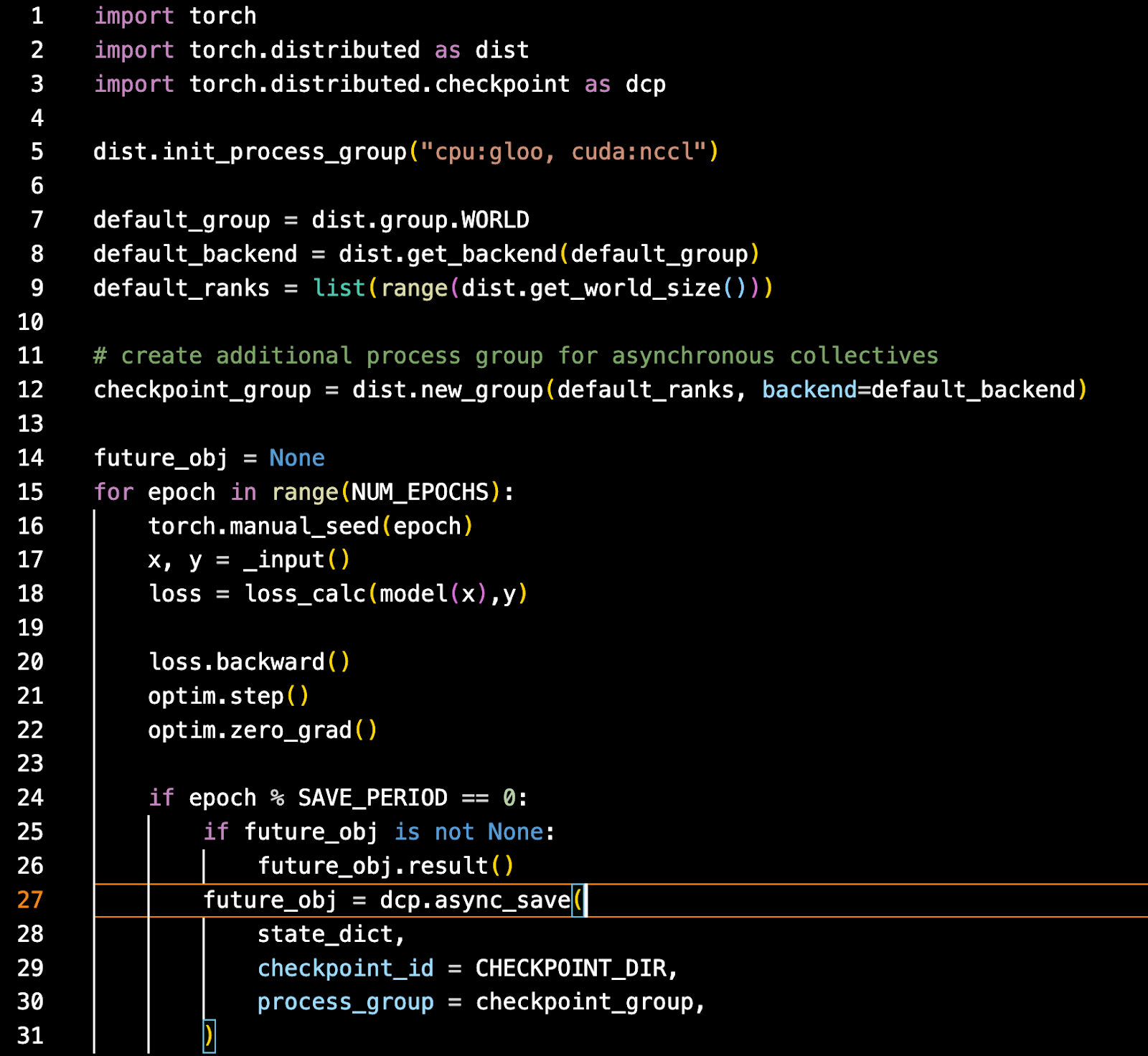
异步检查点的使用相对简单。使用 PyTorch 的最新每夜版本,您需要使用 nccl 和 gloo 初始化您的进程组。Gloo 是 CPU 线程部分所必需的。
从那里,创建一个异步检查点将使用的重复进程组。然后像往常一样训练,但在您想要进行检查点时,使用异步保存 API,传入要保存的状态、检查点 ID 和检查点进程组。
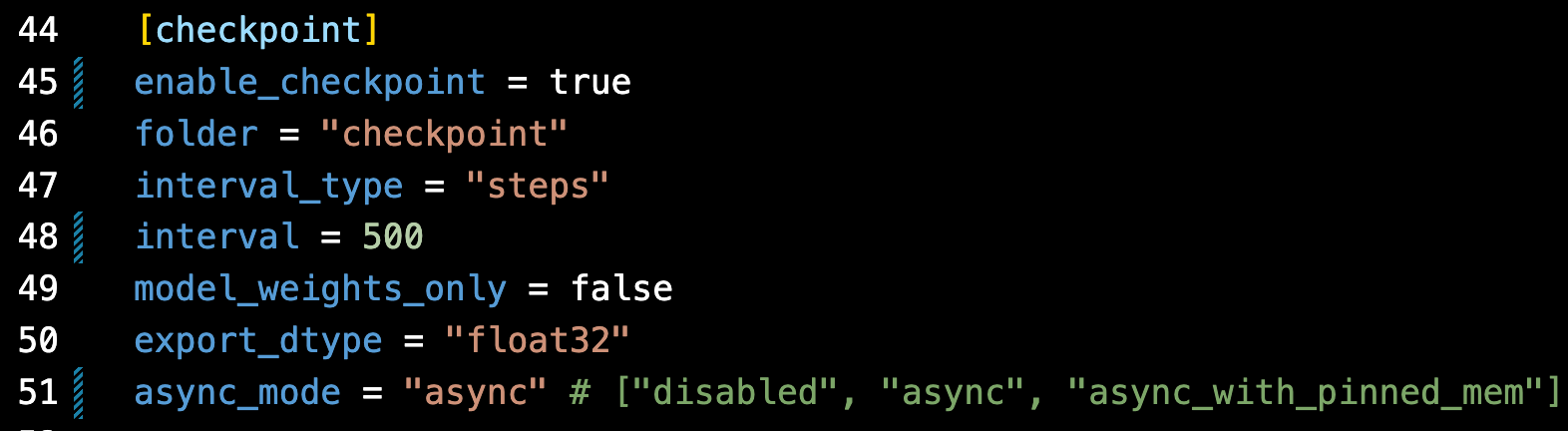
异步检查点也已在 torchtitan 中完全实现。在此,它用于预训练您自己的 Llama2 或 Llama3 模型。使用它就像更新 toml 配置文件一样简单
未来工作
检查点在过去一年取得了巨大进展。从几乎半小时的检查点,到分布式检查点的不到 5 分钟,再到现在的异步检查点的不到 30 秒。
最后的障碍——零开销检查点,即使是少于 30 秒的开销也通过在反向传播期间流式传输更新的权重来消除,这样在异步检查点启动时检查点数据已经位于 CPU 上。
这将有效地使大型模型训练达到检查点没有中断或停机时间的地步,从而既能提高鲁棒性(因为可以更频繁地进行检查点)又能加快训练进度,因为检查点没有停机时间。
源代码链接:https://github.com/pytorch/pytorch/blob/main/torch/distributed/checkpoint/state_dict_saver.py