音视频语音识别(AV-ASR 或 AVSR)是一项从音频和视频流中转录文本的任务,由于其对噪声的鲁棒性,最近引起了大量研究关注。迄今为止,绝大多数工作都集中在开发用于非流式识别的 AV-ASR 模型;对流式 AV-ASR 的研究非常有限。
我们开发了一个紧凑的实时语音识别系统,该系统基于 TorchAudio(一个用于音频和信号处理的库,使用 PyTorch)。它可以在笔记本电脑上本地运行,具有高精度,无需访问云端。今天,我们以宽松的开放许可(BSD-2-Clause 许可)发布 实时 AV-ASR 配方,以支持广泛的应用并促进语音识别音视频模型的进一步研究。
这项工作是我们 AV-ASR 研究 方法的一部分。这种方法的一个有前景的方面是它能够自动注释大规模音视频数据集,从而可以训练更准确、更鲁棒的语音识别系统。此外,这项技术有可能在智能设备上运行,因为它实现了此类设备进行推理所需的延迟和内存效率。
未来,语音识别系统有望为众多领域的应用提供支持。AV-ASR 的主要应用之一是增强 ASR 在嘈杂环境中的性能。由于视频流不受声学噪声的影响,将其集成到音视频语音识别模型中可以弥补 ASR 模型性能的下降。我们的 AV-ASR 系统除了语音识别之外,还有潜力用于多种目的,例如文本摘要、翻译甚至文本转语音。此外,在某些场景中,例如不允许说话、会议中以及需要公共对话隐私的情况下,独家使用 VSR 可能会很有用。
AV-ASR
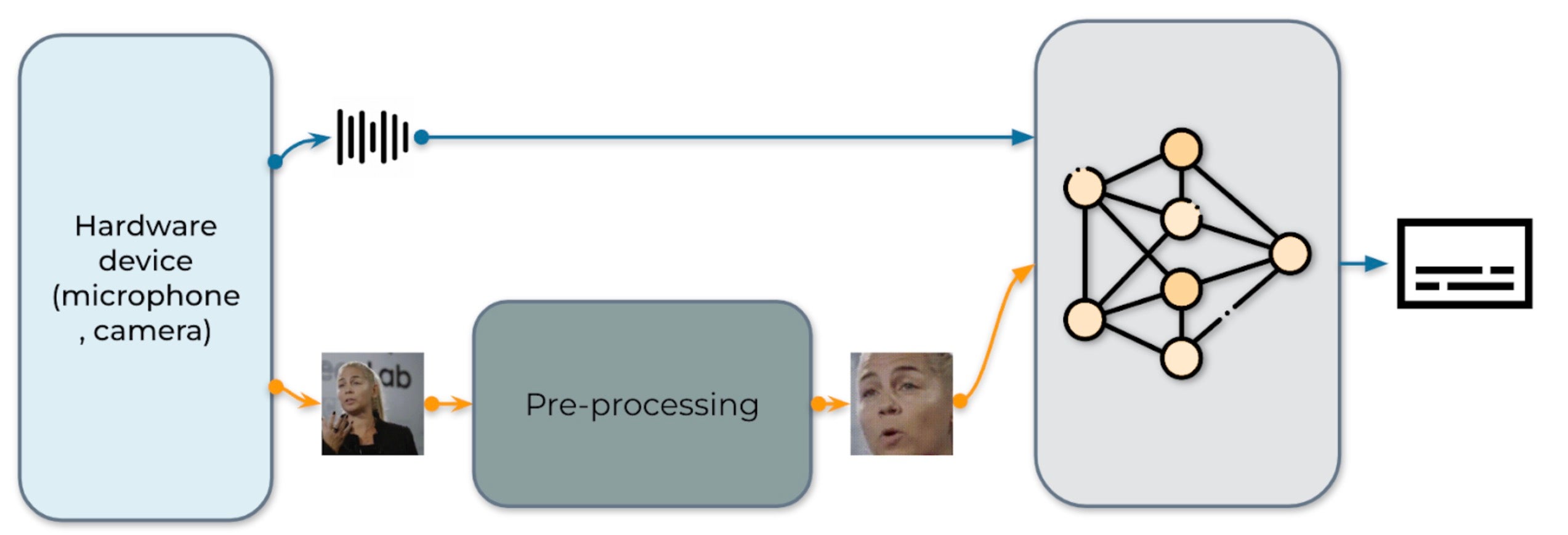
图 1:音视频语音识别系统的工作流程
我们的实时 AV-ASR 系统如图 1 所示。它由三个组件组成:数据收集模块、预处理模块和端到端模型。数据收集模块包含麦克风和摄像头等硬件设备。它的作用是收集真实世界的信息。收集到信息后,预处理模块定位并裁剪人脸。接下来,我们将原始音频流和预处理后的视频流输入到我们的端到端模型中进行推理。
数据收集
我们使用 torchaudio.io.StreamReader 从流式设备输入(例如笔记本电脑上的麦克风和摄像头)捕获音频/视频。一旦收集到原始视频和音频流,预处理模块就会定位并裁剪人脸。需要注意的是,数据在流式处理过程中会立即删除。
预处理
在将原始流输入到我们的模型之前,每个视频序列都必须经过特定的预处理程序。这包括三个关键步骤。第一步是执行人脸检测。之后,每个单独的帧都会与一个参考帧(通常称为平均脸)对齐,以标准化帧之间的旋转和大小差异。预处理模块的最后一步是从对齐的人脸图像中裁剪出人脸区域。我们想明确指出,我们的模型输入的是原始音频波形和人脸像素,没有任何进一步的预处理,例如人脸解析或地标检测。表 1 展示了预处理程序的一个示例。
 |  |  |  |
| 0. 原始图像 | 1. 检测 | 2. 对齐 | 3. 裁剪 |
表 1:预处理流程。
模型
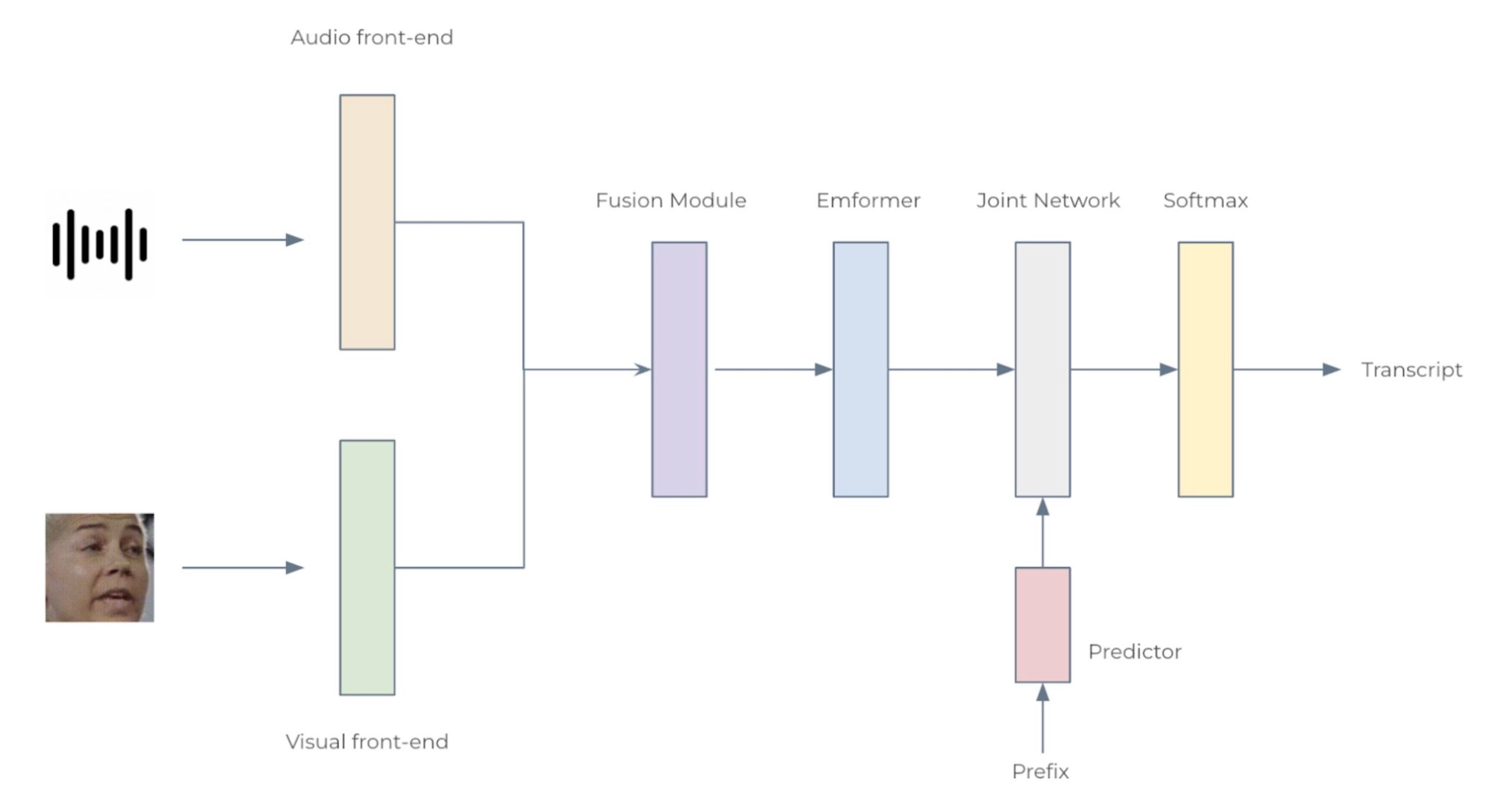
图 2:音视频语音识别系统的架构
我们考虑两种配置:小型模型(12 个 Emformer 块)和大型模型(28 个 Emformer 块),分别具有 34.9M 和 383.3M 参数。每个 AV-ASR 模型都由前端编码器、融合模块、Emformer 编码器和转导器模型组成。具体来说,我们使用卷积前端从原始音频波形和面部图像中提取特征。这些特征被连接起来形成 1024 维特征,然后通过两层多层感知器和一个 Emformer 转导器模型。整个网络使用 RNN-T 损失进行训练。所提出的 AV-ASR 模型的架构如图 2 所示。
分析
数据集。 我们遵循 Auto-AVSR:带自动标签的音视频语音识别,使用公开可用的音视频数据集,包括 LRS3、VoxCeleb2 和 AVSpeech 进行训练。在训练和测试阶段,我们均不使用嘴部 ROI、面部地标或属性。
与最新技术相比。 表 2 列出了 LRS3 上的非流式评估结果。我们的音视频模型具有 800 毫秒的算法延迟(160 毫秒 + 1280 毫秒 x 0.5),产生的 WER 为 1.3%,这与 AV-HuBERT、RAVEn 和 Auto-AVSR 等最先进的离线模型所实现的性能相当。
| 方法 | 总时长 | 词错误率 (%) |
| ViT3D-CM | 90, 000 | 1.6 |
| AV-HuBERT | 1, 759 | 1.4 |
| RAVEn | 1, 759 | 1.4 |
| AutoAVSR | 3, 448 | 0.9 |
| 我们的模型 | 3, 068 | 1.3 |
表 2:LRS3 数据集上音视频模型的非流式评估结果。
噪声实验。 在训练过程中,将 16 种不同类型的噪声随机注入音频波形,其中包括来自 Demand 数据库的 13 种类型:“DLIVING”、“DKITCHEN”、“OMEETING”、“OOFFICE”、“PCAFETER”、“PRESTO”、“PSTATION”、“STRAFFIC”、“SPSQUARE”、“SCAFE”、“TMETRO”、“TBUS”和“TCAR”,来自 语音命令 数据库的两种噪声类型:白噪声和粉噪声,以及来自 NOISEX-92 数据库的另一种噪声类型:嘈杂噪声。信噪比水平在 [干净、7.5dB、2.5dB、-2.5dB、-7.5dB] 范围内以均匀分布选择。表 3 显示了 ASR 和 AV-ASR 模型在嘈杂噪声下测试的结果。随着噪声水平的增加,我们的音视频模型相对于纯音频模型的性能优势增大,这表明结合视觉数据可以提高噪声鲁棒性。
| 类型 | ∞ | 10dB | 5dB | 0dB | -5dB | -10dB |
| A | 1.6 | 1.8 | 3.2 | 10.9 | 27.9 | 55.5 |
| A+V | 1.6 | 1.7 | 2.1 | 6.2 | 11.7 | 27.6 |
表 3:在 LRS3 数据集上,0.80 秒延迟限制下,我们的纯音频 (A) 和音视频 (A+V) 模型在各种信噪比下的流式评估词错误率 (%) 结果。
实时因子。实时因子 (RTF) 是衡量系统高效处理实时任务能力的重要指标。RTF 值小于 1 表示系统满足实时要求。我们使用一台搭载 Intel® Core™ i7-12700 CPU (2.70 GHz) 和 NVIDIA 3070 GeForce RTX 3070 Ti GPU 的笔记本电脑测量 RTF。据我们所知,这是第一个在 LRS3 基准测试中报告 RTF 的 AV-ASR 模型。小型模型在 CPU 上实现了 2.6% 的 WER 和 0.87 的 RTF(表 4),表明其在实时设备端推理应用方面的潜力。
| 模型 | 设备 | 流式词错误率 [%] | 实时因子 |
| 大型 | GPU | 1.6 | 0.35 |
| 小型 | GPU | 2.6 | 0.33 |
| CPU | 0.87 |
表 4:AV-ASR 模型大小和设备对 WER 和 RTF 的影响。请注意,RTF 计算包括预处理步骤,其中使用 Ultra-Lightweight Face Detection Slim 320 模型生成人脸边界框。
从以下已发表的作品中了解更多关于该系统的信息
- Shi, Yangyang, Yongqiang Wang, Chunyang Wu, Ching-Feng Yeh, Julian Chan, Frank Zhang, Duc Le, and Mike Seltzer. “Emformer: Efficient memory transformer based acoustic model for low latency streaming speech recognition.” In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6783-6787. IEEE, 2021.
- Ma, Pingchuan, Alexandros Haliassos, Adriana Fernandez-Lopez, Honglie Chen, Stavros Petridis, and Maja Pantic. “Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels.” In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5. IEEE, 2023.