在这篇博客中,我们介绍了 PyTorch 中大型语言模型的端到端量化感知训练 (QAT) 流程。我们展示了 PyTorch 中的 QAT 如何在 hellaswag 上将 Llama3 的准确率降低程度**恢复高达 96%**,在 wikitext 上将困惑度降低程度**恢复高达 68%**,优于训练后量化 (PTQ)。我们介绍了 torchao 中的 QAT API,并展示了用户如何利用它们在 torchtune 中进行微调。
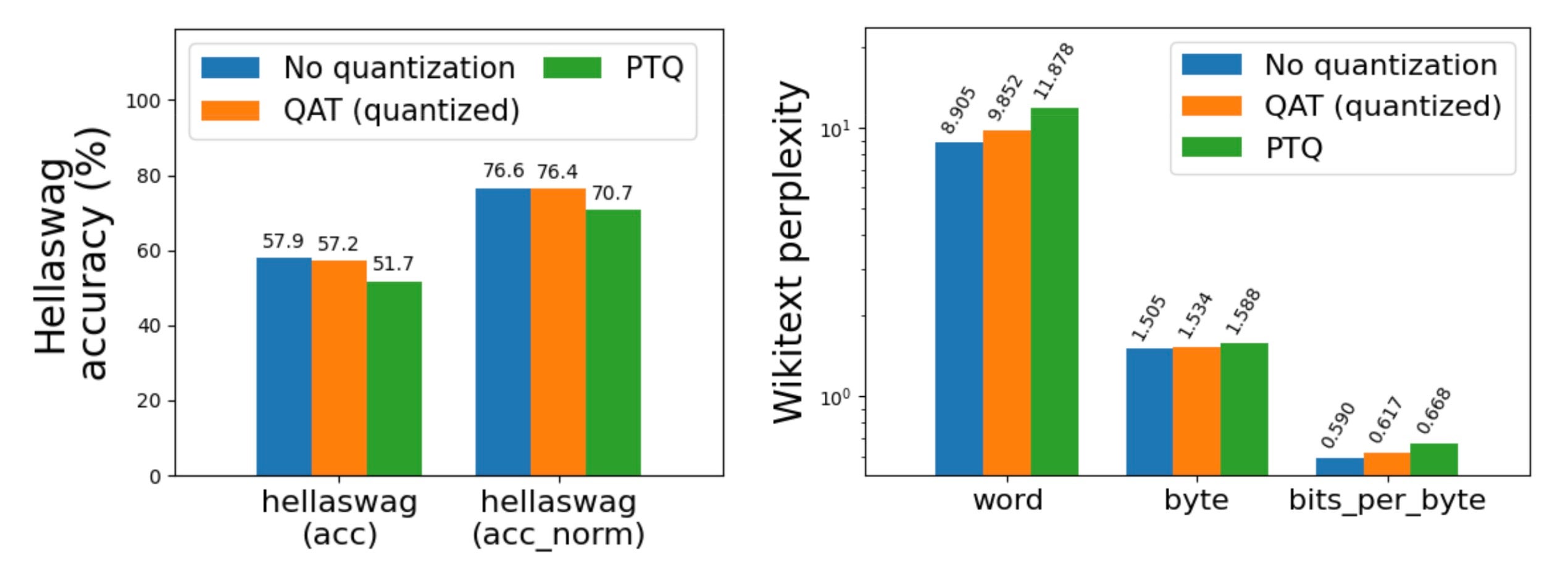
图 1: Llama3-8B 在 C4 数据集(英文子集)上进行微调,使用和不使用 QAT,采用 int8 每 token 动态激活 + int4 分组每通道权重,在 A100 GPU 上对 hellaswag 和 wikitext 进行评估。请注意 wikitext 的对数刻度(越低越好)。
为了证明 QAT 在端到端流程中的有效性,我们通过 executorch 将量化模型进一步降低到 XNNPACK,这是一个针对包括 iOS 和 Android 在内的后端的高度优化的神经网络库。**降低到 XNNPACK 后,QAT 模型的困惑度比 PTQ 模型低 16.8%,同时保持相同的模型大小以及设备上的推理和生成速度。**
| 降低模型指标 | PTQ | QAT |
| Wikitext 单词困惑度 (↓) | 23.316 | 19.403 |
| Wikitext 字节困惑度 (↓) | 1.850 | 1.785 |
| Wikitext 每字节比特数 (↓) | 0.887 | 0.836 |
| 模型大小 | 3.881 GB | 3.881 GB |
| 设备推理速度 | 5.065 token/秒 | 5.265 token/秒 |
| 设备生成速度 | 8.369 token/秒 | 8.701 token/秒 |
表 1: QAT 在降低到 XNNPACK 的 Llama3-8B 模型上实现了 16.8% 的困惑度降低,模型大小和设备上的推理和生成速度保持不变。线性层使用 int8 每 token 动态激活 + int4 分组每通道权重进行量化,嵌入层额外使用 32 的分组大小量化为 int4(QAT 仅应用于线性层)。Wikitext 评估使用 5 个样本和最大序列长度 127 在服务器 CPU 上执行,因为设备上不可用评估(所有 wikitext 结果越低越好)。设备上的推理和生成在三星 Galaxy S22 智能手机上进行基准测试。
QAT API
我们很高兴用户试用 torchao 中的 QAT API,它可以用于训练和微调。此 API 涉及两个步骤:准备 (prepare) 和转换 (convert):准备步骤对模型中的线性层进行转换,以在训练期间模拟量化数值,而转换步骤在训练后实际将这些层量化为较低的位宽。转换后的模型可以与 PTQ 模型完全相同的方式使用。
import torch
from torchtune.models.llama3 import llama3
from torchao.quantization.prototype.qat import Int8DynActInt4WeightQATQuantizer
# Smaller version of llama3 to fit in a single GPU
model = llama3(
vocab_size=4096,
num_layers=16,
num_heads=16,
num_kv_heads=4,
embed_dim=2048,
max_seq_len=2048,
).cuda()
# Quantizer for int8 dynamic per token activations +
# int4 grouped per channel weights, only for linear layers
qat_quantizer = Int8DynActInt4WeightQATQuantizer()
# Insert "fake quantize" operations into linear layers.
# These operations simulate quantization numerics during
# training without performing any dtype casting
model = qat_quantizer.prepare(model)
# Standard training loop
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-5)
loss_fn = torch.nn.CrossEntropyLoss()
for i in range(10):
example = torch.randint(0, 4096, (2, 16)).cuda()
target = torch.randn((2, 16, 4096)).cuda()
output = model(example)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Convert fake quantize to actual quantize operations
# The quantized model has the exact same structure as the
# quantized model produced in the corresponding PTQ flow
# through `Int8DynActInt4WeightQuantizer`
model = qat_quantizer.convert(model)
# inference or generate
使用 torchtune 进行微调
我们还将此 QAT 流程集成到 torchtune 中,并提供了 recipe,以便在分布式设置中运行它,类似于现有的完全微调分布式 recipe。用户还可以通过运行以下命令在 LLM 微调期间应用 QAT。有关更多详细信息,请参阅 此 README。
tune run --nproc_per_node 8 qat_distributed --config llama3/8B_qat_full
什么是量化感知训练?
量化感知训练 (QAT) 是一种常见的量化技术,用于缓解量化引起的模型准确率/困惑度下降。这是通过在训练期间模拟量化数值来实现的,同时将权重和/或激活保持在原始数据类型(通常是浮点),有效地“伪量化”值,而不是实际将它们转换为较低的位宽。
# PTQ: x_q is quantized and cast to int8
# scale and zero point (zp) refer to parameters used to quantize x_float
# qmin and qmax refer to the range of quantized values
x_q = (x_float / scale + zp).round().clamp(qmin, qmax).cast(int8)
# QAT: x_fq is still in float
# Fake quantize simulates the numerics of quantize + dequantize
x_fq = (x_float / scale + zp).round().clamp(qmin, qmax)
x_fq = (x_fq - zp) * scale
由于量化涉及非可微运算,如舍入,QAT 反向传播通常使用 直通估计器 (STE),这是一种估计通过非光滑函数的梯度机制,以确保传递给原始权重的梯度仍然有意义。通过这种方式,在计算梯度时会考虑到权重最终在训练后会被量化,从而有效地允许模型在训练过程中调整量化噪声。请注意,QAT 的替代方案是量化训练,它在训练期间实际将值转换为较低位宽的数据类型,但 先前的努力 仅在高达 8 位的情况下取得了成功,而 QAT 即使在较低位宽下也有效。
PyTorch 中的 QAT
我们最初在 torchao 的原型 这里 添加了 QAT 流程。目前,我们支持线性层的 int8 动态每 token 激活 + int4 分组每通道权重(缩写为 8da4w)。这些设置的动机是 边缘后端上的内核可用性 和 LLM 量化方面的先前研究 的结合,这些研究发现,与其他量化方案相比,每 token 激活和每组权重量化可实现 LLM 的最佳模型质量。
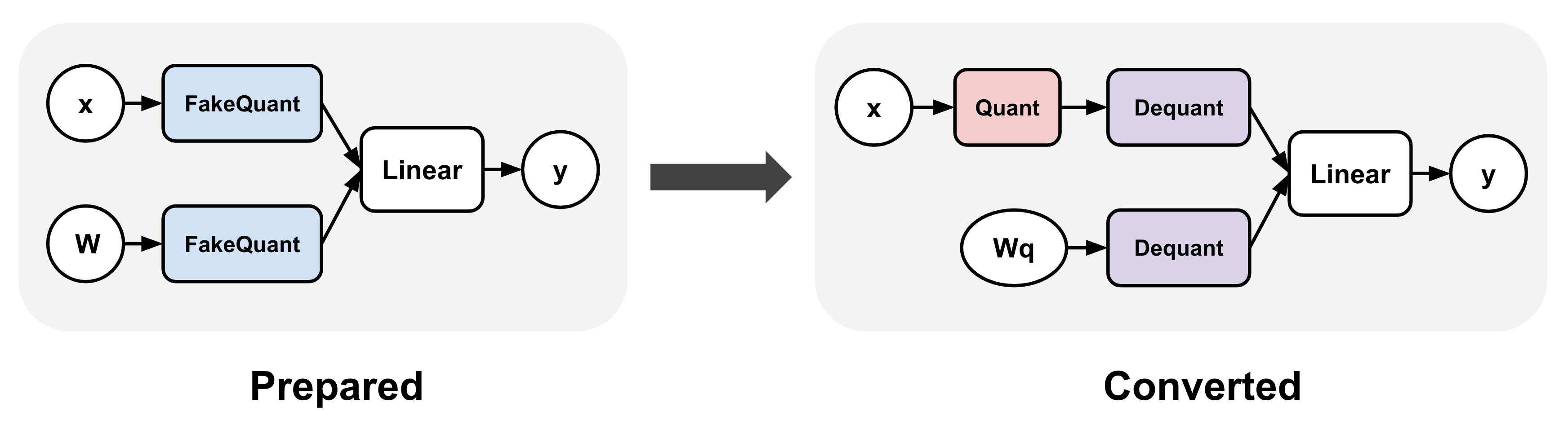
图 2: torchao QAT 流程。此流程涉及两个步骤:(1)准备,它将伪量化操作插入到模型的线性层中,以及(2)转换,它在训练后将这些伪量化操作转换为实际的量化和反量化操作。
此流程使用相同的量化设置(通过 Int8DynActInt4WeightQuantizer)生成与 PTQ 流程完全相同的量化模型,但量化权重实现了卓越的准确率和困惑度。因此,我们可以使用从 QAT 流程转换的模型作为 PTQ 模型的直接替代品,并重用所有后端委托逻辑和底层内核。
实验结果
本博客文章中的所有实验均使用上述 torchtune QAT 集成执行。我们使用 6-8 个配备 80 GB 内存的 A100 GPU,在 C4 数据集(英文子集)上对 Llama2-7B 和 Llama3-8B 进行 5000 步微调。对于所有实验,我们使用批量大小 = 2,学习率 = 2e-5,Llama2 的最大序列长度 = 4096,Llama3 的最大序列长度 = 8192,完全分片数据并行 (FSDP) 作为我们的分布式策略,以及激活检查点以减少内存占用。对于 8da4w 实验,我们对权重使用 256 的分组大小。
由于预训练数据集不易获取,我们选择在微调过程中执行 QAT。经验上,我们发现前 N 步禁用伪量化会带来更好的结果,这可能是因为这样做可以在我们开始向微调过程引入量化噪声之前稳定权重。我们在所有实验的前 1000 步中禁用了伪量化。
我们使用 torchtune 中的 lm-evaluation-harness 集成来评估我们的量化模型。我们报告了各种常用于评估 LLM 的任务的评估结果,包括 hellaswag(一个常识性句子补全任务)、wikitext(一个下一个 token/字节预测任务)以及一些问答任务,例如 arc、openbookqa 和 piqa。对于 wikitext,困惑度是指模型预测下一个单词或字节能力的倒数(越低越好),bits_per_byte 是指预测下一个字节所需的比特数(这里也是越低越好)。对于所有其他任务,acc_norm 是指按目标字符串的字节长度归一化的准确率。
Int8 动态激活 + Int4 权重量化 (8da4w)
从 Llama2 8da4w 量化开始,我们发现 QAT 能够在 hellaswag 上恢复与 PTQ 相比 62% 的归一化准确率下降,并在 wikitext 上恢复 58% 和 57% 的单词和字节困惑度下降(分别)。我们在大多数其他任务中看到了类似的改进。
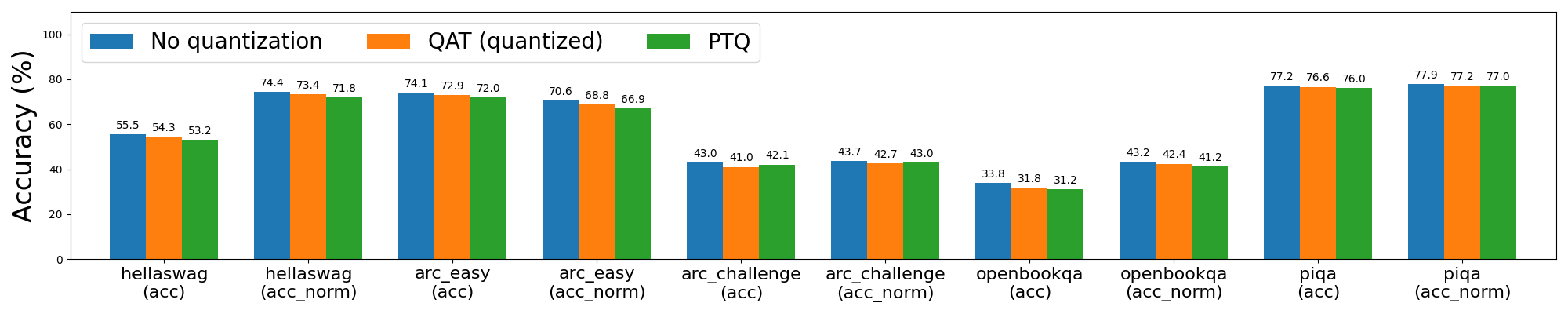
图 3a: Llama2-7B 8da4w 量化,使用和不使用 QAT
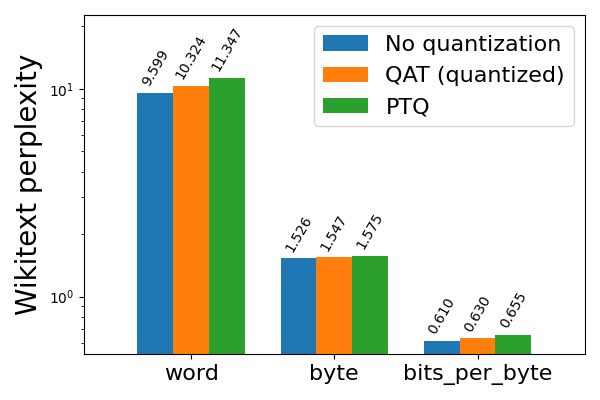
图 3b: Llama2-7B 8da4w 量化,使用和不使用 QAT,在 wikitext 上评估(越低越好)
Llama3 8da4w 量化在使用 QAT 后看到了更显著的改进。在 hellaswag 评估任务中,我们能够恢复与 PTQ 相比 96% 的归一化准确率下降,与未量化准确率相比总体下降极小(<1%)。在 wikitext 评估任务中,QAT 分别恢复了 68% 和 65% 的单词和字节困惑度下降。即使在对 Llama2 QAT 来说很困难的 arc_challenge 上,我们也能够恢复 51% 的归一化准确率下降。
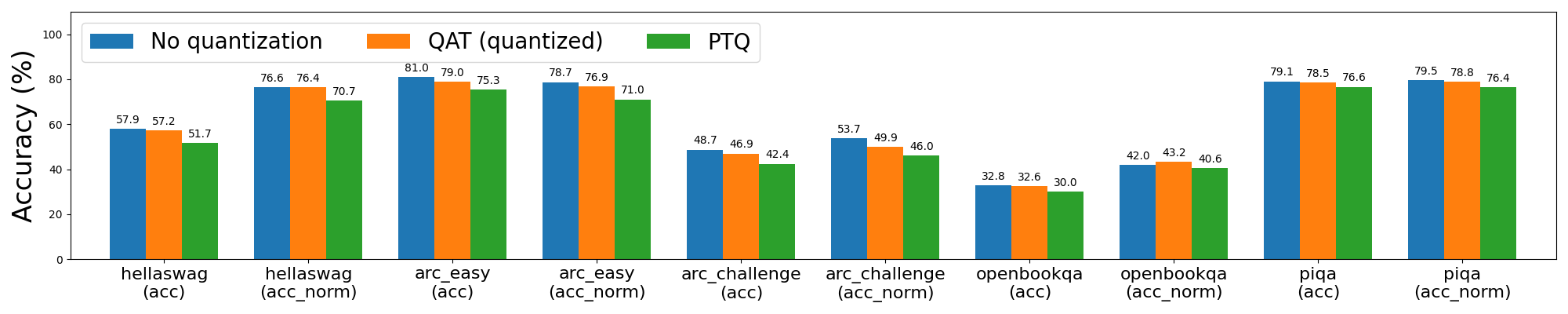
图 4a: Llama3-8B 8da4w 量化,使用和不使用 QAT
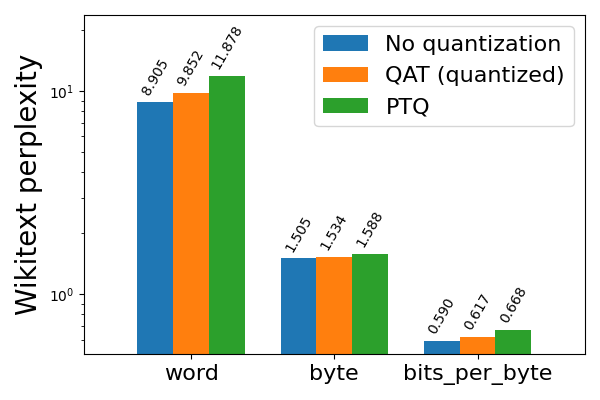
图 4b: Llama3-8B 8da4w 量化,使用和不使用 QAT,在 wikitext 上评估(越低越好)
低位宽纯权重(Weight Only)量化
我们进一步将 torchao QAT 流程扩展到 2 位和 3 位纯权重(weight only)量化,并对 Llama3-8B 重复了相同的实验。在较低位宽下,量化退化更严重,因此我们对所有实验使用 32 的分组大小以进行更精细的量化。
然而,这对于 2 位 PTQ 仍然不够,后者导致 wikitext 困惑度飙升。为了缓解这个问题,我们利用了先前敏感性分析的知识,即 Llama3 模型的前 3 层和后 2 层最敏感,并通过跳过量化这些层来换取量化模型尺寸的适度增加(2 位为 1.78 GB,3 位为 1.65 GB)。这将 wikitext 单词困惑度从 603336 降低到 6766,这很显著但仍然远未达到可接受的水平。为了进一步改进量化模型,我们转向 QAT。
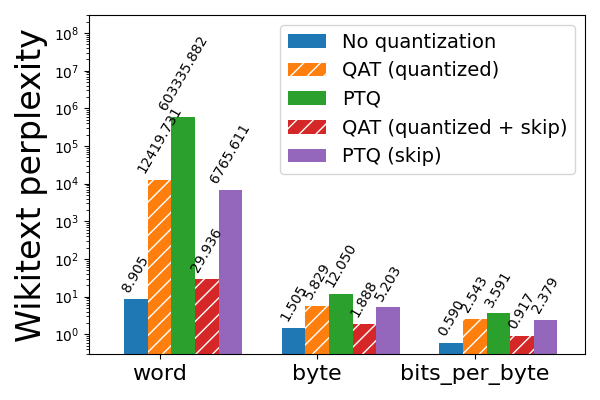
图 5a: Llama3-8B 2 位纯权重(weight only)量化,使用和不使用 QAT,在 wikitext 上评估(越低越好)。带有“skip”的条形表示跳过对模型前 3 层和后 2 层的量化,这些层对量化更敏感。请注意对数刻度。
我们观察到,在跳过对前 3 层和后 2 层的量化的情况下应用 QAT,进一步将单词困惑度降低到一个更合理的 30(从 6766)。更普遍地说,QAT 能够恢复与 PTQ 相比 hellaswag 上 53% 的归一化准确率下降,以及 wikitext 上 99% 和 89% 的单词和字节困惑度下降(分别)。然而,如果不跳过敏感层,QAT 在缓解量化模型质量下降方面的效果要差得多。
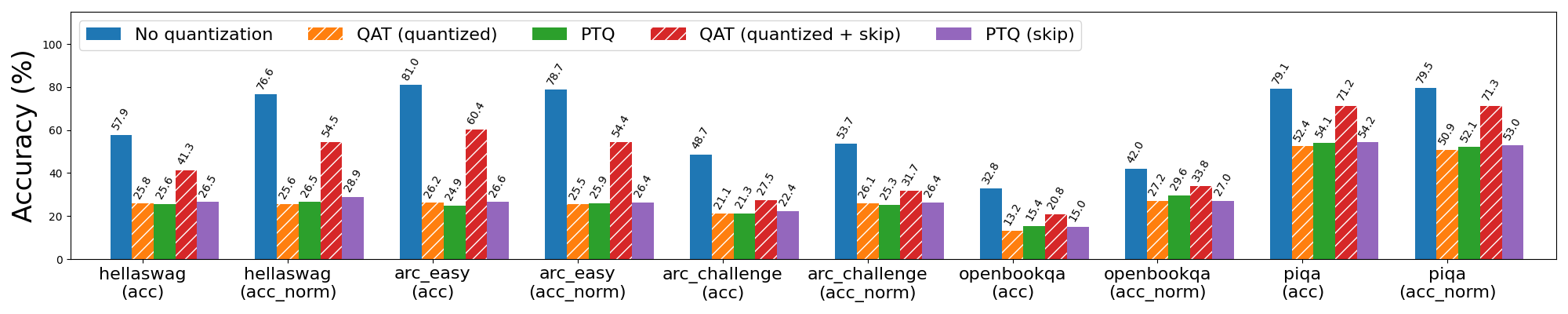
图 5b: Llama3-8B 2 位纯权重(weight only)量化,使用和不使用 QAT。带有“skip”的条形表示跳过对模型前 3 层和后 2 层的量化,这些层对量化更敏感。
对于 3 位纯权重(weight only)量化,QAT 即使不跳过前 3 层和后 2 层也有效,尽管跳过这些层仍然会为 PTQ 和 QAT 带来更好的结果。在跳过的情况下,QAT 能够恢复与 PTQ 相比 hellaswag 上 63% 的归一化准确率下降,以及 wikitext 上 72% 和 65% 的单词和字节困惑度下降(分别)。
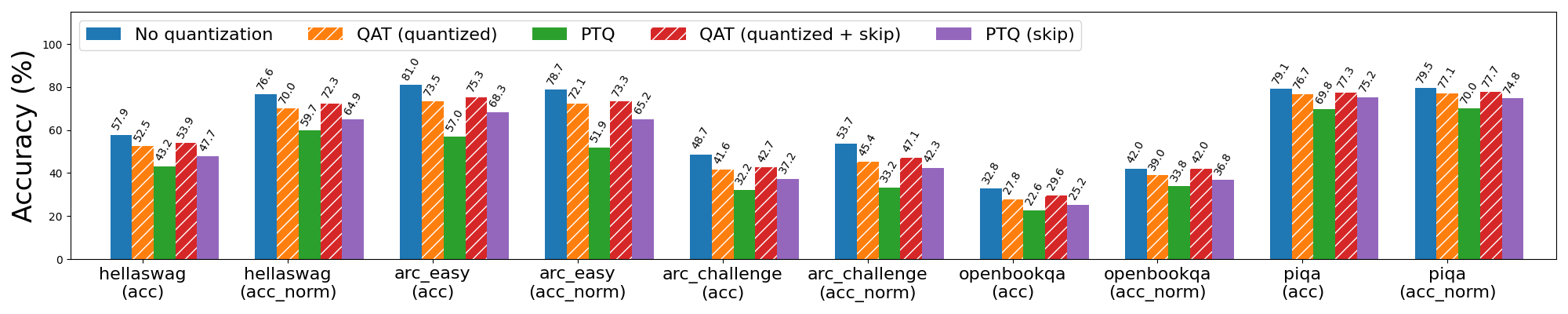
图 6a: Llama3-8B 3 位纯权重(weight only)量化,使用和不使用 QAT。带有“skip”的条形表示跳过对模型前 3 层和后 2 层的量化,这些层对量化更敏感。
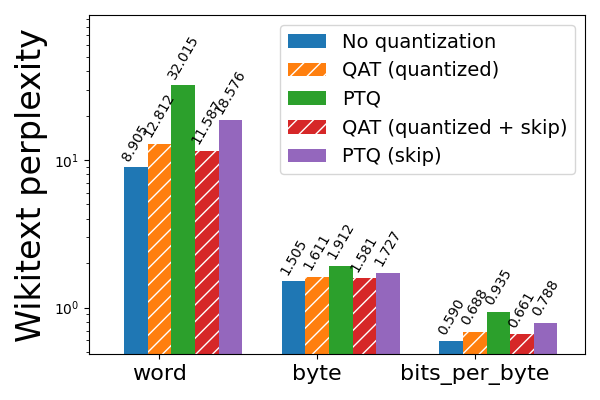
图 6b: Llama3-8B 3 位纯权重(weight only)量化,使用和不使用 QAT,在 wikitext 上评估(越低越好)。带有“skip”的条形表示跳过对模型前 3 层和后 2 层的量化,这些层对量化更敏感。请注意对数刻度。
QAT 开销
QAT 在整个模型中插入了许多伪量化操作,增加了微调速度和内存使用的大量开销。例如,对于 Llama3-8B 这样的模型,我们有 (32 * 7) + 1 = 225 个线性层,每个层至少有 1 个用于权重的伪量化操作,并且可能有一个用于输入激活的伪量化操作。内存占用增加也很大,因为我们不能就地修改权重,因此在应用伪量化之前需要克隆它们,尽管这种开销可以通过启用激活检查点来最大程度地缓解。
在我们的微基准测试中,我们发现 8da4w QAT 微调比常规完全微调慢约 34%。启用激活检查点后,每个 GPU 的内存增加约为 2.35 GB。这些开销大部分是 QAT 工作原理的基础,尽管我们将来可能能够通过 torch.compile 加速计算。
| 每个 GPU 统计数据 | 完全微调 | QAT 微调 |
| 每秒中位 token 数 | 546.314 token/秒 | 359.637 token/秒 |
| 中位峰值内存 | 67.501 GB | 69.850 GB |
表 2: Llama3 QAT 微调开销,用于在 6 个 A100 GPU(每个 80GB 内存)上使用 int8 每 token 动态激活 + int4 分组每通道权重。
展望未来
在本博客中,我们介绍了通过 torchao 实现的 LLM QAT 流程,将其与 torchtune 中的微调 API 集成,并展示了其在恢复大部分量化退化(与 PTQ 相比)和在某些任务上达到未量化性能方面的潜力。未来有许多探索方向:
- 超参数调优。 广泛的超参数调优可能会进一步改善微调和 QAT 的结果。除了学习率、批量大小、数据集大小和微调步数等通用超参数外,我们还应该调整 QAT 特定的超参数,例如何时开始/停止伪量化、伪量化多少步以及伪量化值的正则化参数。
- 异常值减少技术。 在我们的实验中,我们发现 PTQ 和 QAT 都容易受到异常值的影响。除了微调期间的简单钳制和正则化之外,我们还可以探索允许网络学习如何控制这些异常值的技术(例如 学习量化范围、裁剪 softmax 和 门控注意力),或者甚至借鉴训练后设置中的异常值抑制技术(例如 SpinQuant、SmoothQuant),并将其少量应用于微调过程。
- 混合精度和更复杂的数据类型。 特别是在较低位宽下,我们发现跳过对某些敏感层的量化对 PTQ 和 QAT 都有效。我们是否需要完全跳过量化这些层,还是可以仍然量化它们,只是降低位宽?在 QAT 的背景下探索混合精度量化将很有趣。使用 MX4 等更新的数据类型进行训练是另一个有前途的方向,特别是考虑到即将推出的 Blackwell GPU 将 不再支持 int4 Tensor 核心。
- 与 LoRA 和 QLoRA 的可组合性。 我们在 torchtune 中的 QAT 集成目前仅支持完全微调工作流。然而,许多用户希望使用低秩适配器来微调他们的模型,以大幅减少内存占用。将 QAT 与 LoRA / QLoRA 等技术结合,将使用户能够获得这些方法的内存和性能优势,同时生成一个最终将被量化且模型质量下降最小的模型。
- 与 torch.compile 的可组合性。 这是另一种显着加速 QAT 中伪量化计算并减少内存占用的潜在方法。torch.compile 目前与 torchtune 中完全分布式微调 recipe 中使用的分布式策略不兼容(无论是否使用 QAT),但将在不久的将来添加支持。
- 量化其他层。 在这项工作中,我们只探索了量化线性层。然而,在长序列长度的背景下,KV 缓存通常成为吞吐量瓶颈,并且可以达到数十 GB,因此 LLM-QAT 探索了量化 KV 缓存以及激活和权重。先前的工作 也成功地将嵌入层量化到 2 位,用于其他基于 Transformer 的模型。
- 在高性能 CUDA 内核上的端到端评估。 这项工作的自然延伸是提供一个在高性能 CUDA 内核上评估的端到端 QAT 流程,类似于通过 executorch 降低到 XNNPACK 内核的现有 8da4w QAT 流程。对于 int4 纯权重(weight only)量化,我们可以利用高效的 带位打包的 int4 权重 MM 内核 进行量化,并且正在进行为该内核添加 QAT 支持的工作:https://github.com/pytorch/ao/pull/383。对于 8da4w 量化,cutlass 中也正在添加 混合 4 位/8 位 GEMM。这将是构建高效 8da4w CUDA 内核所必需的。
QAT 代码可在 此处 找到。请参阅 此 torchtune 教程 开始。如果您有任何其他问题,请随时在 torchao 的 GitHub 上提出问题或联系 andrewor@meta.com。我们欢迎您的反馈和贡献!