引言
TL;DR: 在移动设备、SBCs(单板计算机)和IOT设备上运行 PyTorch 可能具有挑战性。PyTorch 库编译后非常庞大,并包含可能在设备使用场景下不需要的依赖项。
要在设备上运行特定模型集,我们实际上只需要 PyTorch 库中的一小部分功能。我们发现,使用通过选择性构建生成的 PyTorch 运行时可以使二进制文件大小减少高达 90%(对于 Linux 上 x86-64 构建的 CPU 和 QuantizedCPU 后端)。在本博客中,我们分享了使用选择性构建生成模型专用最小运行时的经验,并向您展示如何做到这一点。
为什么这对于应用程序开发者很重要?
使用通过选择性构建生成的 PyTorch 运行时可以将 AI 驱动的应用程序大小减少 30+ MB——对于典型的移动应用程序来说,这是一个显著的缩减!使移动应用程序更轻量化具有诸多益处——它们可以在更广泛的设备上运行,消耗更少的蜂窝数据,并且可以在用户设备上更快地下载和更新。
开发者体验如何?
此方法可以与任何现有的 PyTorch Mobile 部署工作流程无缝协作。您所需要做的就是将通用的 PyTorch 运行时库替换为针对您希望在应用程序中使用的特定模型定制的运行时。此过程的一般步骤是:
- 以检测模式构建 PyTorch 运行时(这称为 PyTorch 的检测构建)。这将记录所使用的运算符、内核和功能。
- 使用提供的 model_tracer 二进制文件,通过此检测构建运行您的模型。这将生成一个 YAML 文件,其中存储了您的模型使用的所有功能。这些功能将保留在最小运行时中。
- 以此 YAML 文件作为输入构建 PyTorch。这就是选择性构建技术,它大大减小了最终 PyTorch 二进制文件的大小。
- 使用此选择性构建的 PyTorch 库来减小您的移动应用程序的大小!
以特殊的“检测”模式(通过传递 TRACING_BASED=1 构建选项)构建 PyTorch 运行时会生成 PyTorch 的检测构建运行时,以及一个 model_tracer 二进制文件。使用此构建运行模型可以跟踪模型使用的 PyTorch 部分。
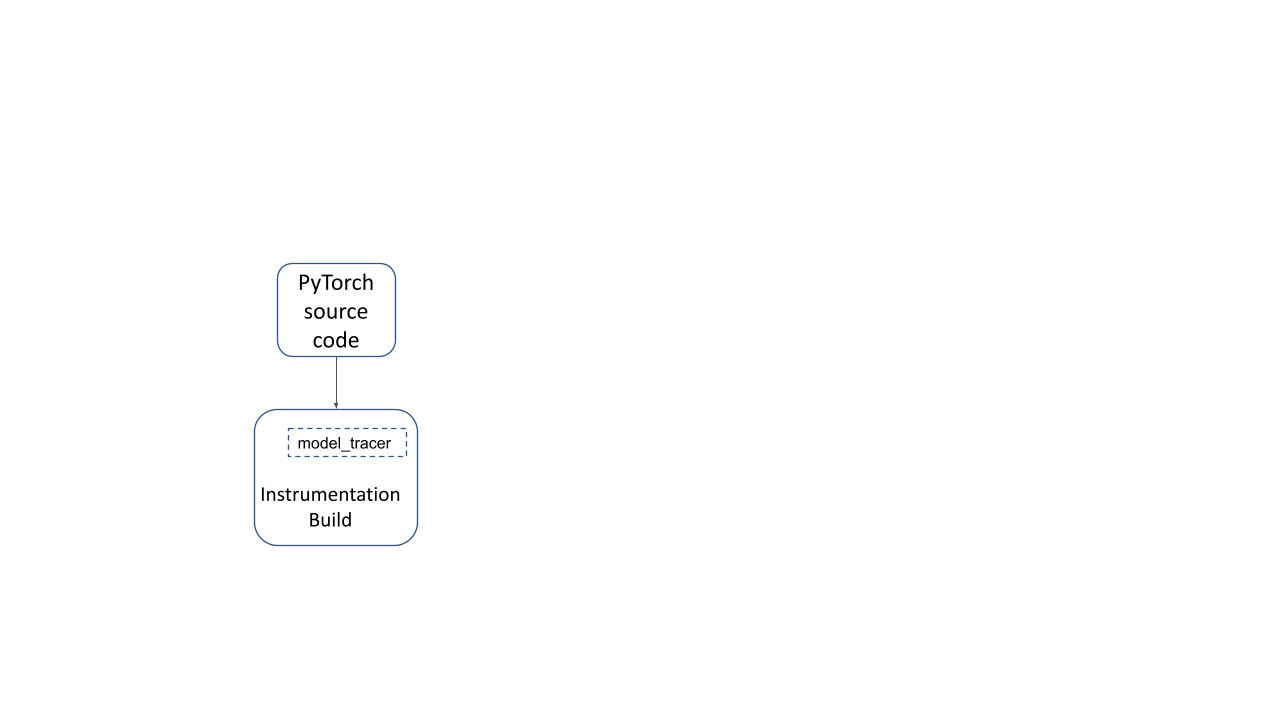
图 1:PyTorch 的检测构建
# Clone the PyTorch repo
git clone https://github.com/pytorch/pytorch.git
cd pytorch
# Build the model_tracer
USE_NUMPY=0 USE_DISTRIBUTED=0 USE_CUDA=0 TRACING_BASED=1 \
python setup.py develop
现在,此检测构建用于使用代表性输入运行模型推理。 model_tracer 二进制文件观察在推理运行期间激活的检测构建部分,并将其转储到 YAML 文件中。
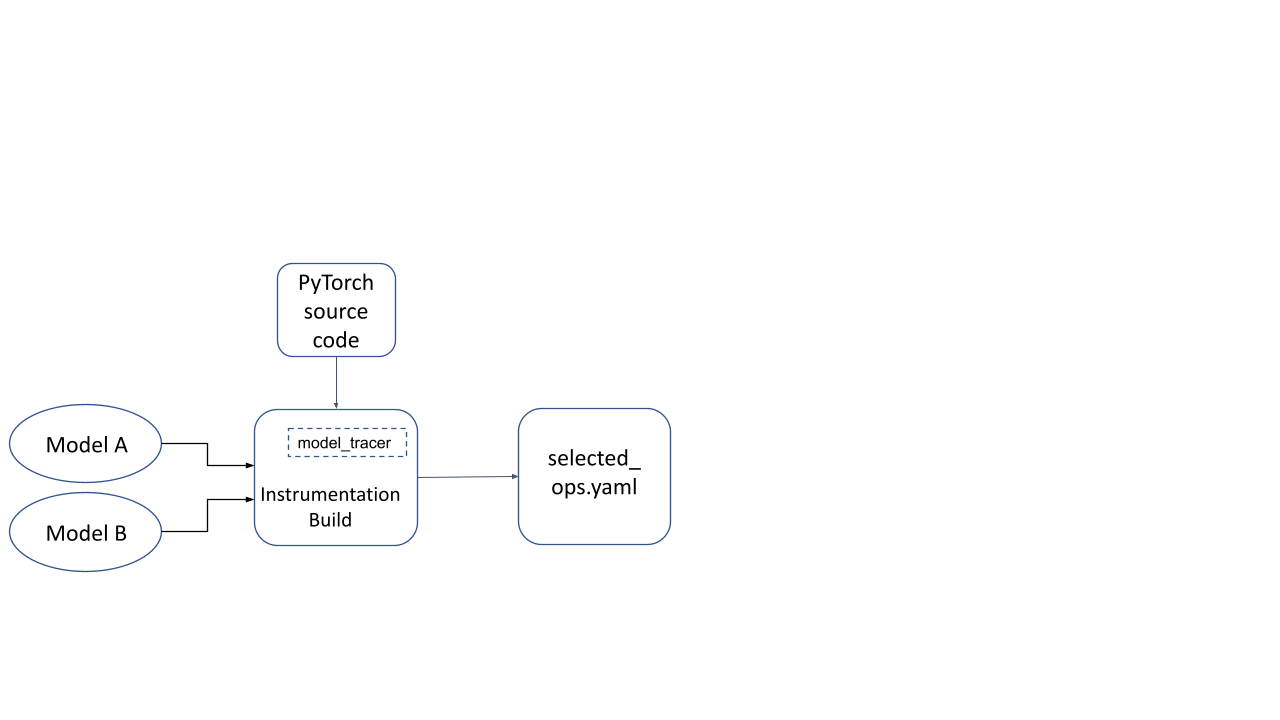
图 2:在检测构建上运行模型生成的 YAML 文件
# Generate YAML file
./build/bin/model_tracer \
--model_input_path /tmp/path_to_model.ptl \
--build_yaml_path /tmp/selected_ops.yaml
现在我们再次构建 PyTorch 运行时,但这次使用由跟踪器生成的 YAML 文件。运行时现在只包含此模型所需的部分。这在下图中称为“选择性构建的 PyTorch 运行时”。
# Clean out cached configuration
make clean
# Build PyTorch using Selected Operators (from the YAML file)
# using the host toolchain, and use this generated library
BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN=1 \
USE_LIGHTWEIGHT_DISPATCH=0 \
BUILD_LITE_INTERPRETER=1 \
SELECTED_OP_LIST=/tmp/selected_ops.yaml \
TRACING_BASED=1 \
./scripts/build_mobile.sh
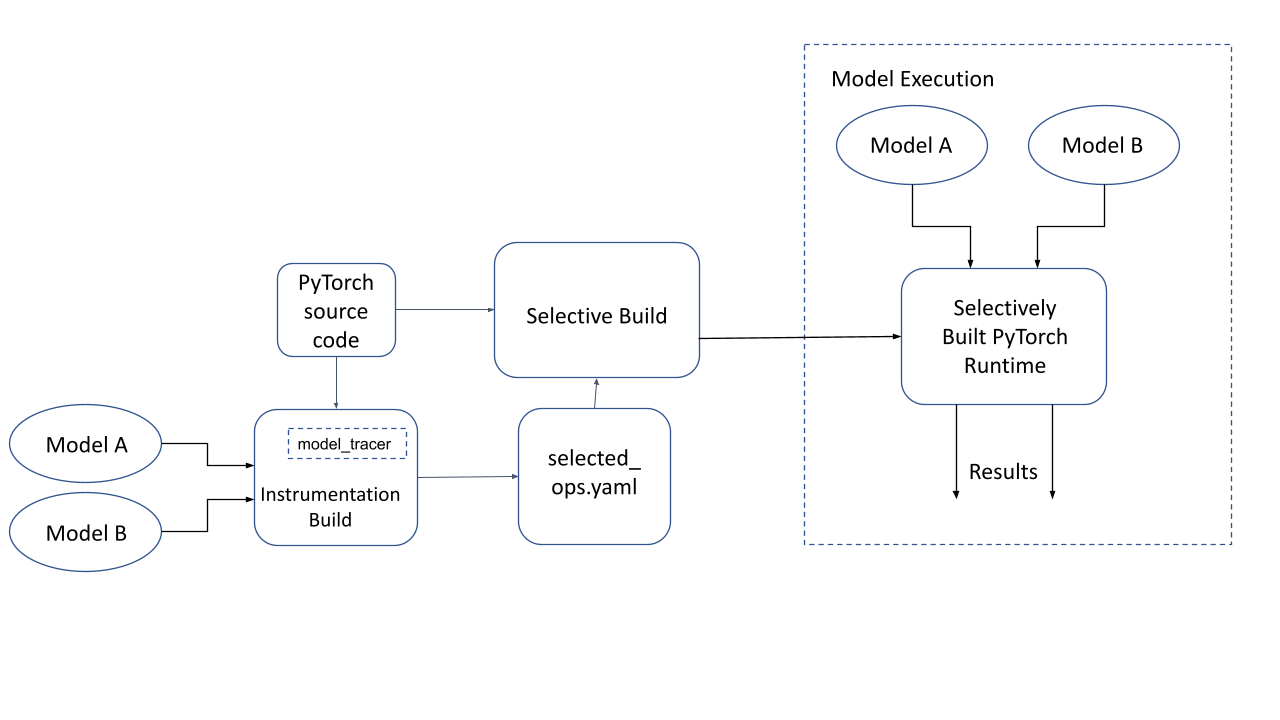
图 3:PyTorch 的选择性构建以及在选择性构建的 PyTorch 运行时上执行模型
给我看代码!
我们整理了一个笔记本,以使用一个简单的 PyTorch 模型来演示上述过程在代码中的样子。
有关如何在 Android/iOS 上部署此功能的更实际教程,此教程应该会有所帮助。
技术常见问题解答
为什么 PyTorch 的选择性构建需要跟踪?
在 PyTorch 中,CPU 内核可以通过PyTorch Dispatcher调用其他操作符。仅仅包含模型直接调用的根操作符集是不够的,因为在底层可能通过传递调用了更多操作符。在代表性输入上运行模型并观察实际调用的操作符列表(即“跟踪”)是确定 PyTorch 哪些部分被使用的最准确方法。
此外,诸如内核应处理哪些 dtypes 等因素也是运行时特性,取决于提供给模型的实际输入。因此,跟踪机制非常适合此目的。
通过基于跟踪的选择性构建可以选择(或排除)哪些功能?
在基于跟踪的选择性构建过程中,可以选择以下功能用于 PyTorch 运行时:
- CPU/量化 CPU 内核用于PyTorch 的 ATen 运算符:如果一个目标为选择性构建运行时的模型不需要某个 PyTorch 运算符,那么该 CPU 内核的注册将在运行时中省略。这通过Torchgen 代码生成控制。
- 主要运算符:这由一个名为TORCH_SELECTIVE_SCHEMA的宏控制(通过模板化选择性构建),它根据生成头文件中的信息选择或取消选择主要运算符。
- 在 CPU 内核中处理特定 dtypes 的代码:这通过在宏AT_PRIVATE_CHECK_SELECTIVE_BUILD生成的 switch case 中特定 case 语句中生成异常抛出实现。
- 注册扩展 PyTorch 的自定义 C++ 类:这由宏TORCH_SELECTIVE_CLASS控制,可在注册自定义 C++ 类时使用。torch::selective_class_<> 辅助函数应与宏TORCH_SELECTIVE_CLASS结合使用。
构建过程中使用的 YAML 文件的结构是什么?
跟踪后生成的 YAML 文件如下例所示。它编码了上述指定的所有“可选择”构建功能元素。
include_all_non_op_selectives: false
build_features: []
operators:
aten::add.Tensor:
is_used_for_training: false
is_root_operator: true
include_all_overloads: false
aten::len.t:
is_used_for_training: false
is_root_operator: true
include_all_overloads: false
kernel_metadata:
_local_scalar_dense_cpu:
- Float
add_stub:
- Float
copy_:
- Bool
- Byte
mul_cpu:
- Float
custom_classes: []
代码究竟是如何从生成的二进制文件中消除的?
根据具体情况,有两种主要技术用于向编译器和链接器提示未使用的和不可达的代码。然后,这些代码会被编译器或链接器作为不可达代码进行清理。
[1] 链接器移除未引用的函数
当被链接在一起的编译对象文件中存在一个未被任何可见函数传递引用的函数时,链接器会将其移除(如果提供了正确的构建标志)。选择性构建系统在两种场景中利用了这一点。
调度器中的内核注册
如果不需要某个操作符的内核,那么它就不会在调度器中注册。未注册的内核意味着该函数是不可达的,它将被链接器移除。
模板化选择性构建
这里的核心思想是,使用类模板特化来选择一个类,该类要么捕获对函数的引用,要么不捕获(取决于是否使用),然后链接器可以清理未引用的函数。
例如,在下面的代码中,没有对函数“fn2”的引用,因此它将被链接器清理,因为它没有在任何地方被引用。
#include <vector>
#include <cstdio>
template <typename T, bool>
struct FunctionSelector {
T fn_;
FunctionSelector(T fn): fn_(fn) {}
T get() { return this->fn_; }
};
// The "false" specialization of this class does NOT retain the argument passed
// to the class constructor, which means that the function pointer passed in
// is considered to be unreferenced in the program (unless it is referenced
// elsewhere).
template <typename T>
struct FunctionSelector<T, false> {
FunctionSelector(T) {}
};
template <typename T>
FunctionSelector<T, true> make_function_selector_true(T fn) {
return FunctionSelector<T, true>(fn);
}
template <typename T>
FunctionSelector<T, false> make_function_selector_false(T fn) {
return FunctionSelector<T, false>(fn);
}
typedef void(*fn_ptr_type)();
std::vector<fn_ptr_type> fns;
template <typename T>
void add_fn(FunctionSelector<T, true> fs) {
fns.push_back(fs.get());
}
template <typename T>
void add_fn(FunctionSelector<T, false>) {
// Do nothing.
}
// fn1 will be kept by the linker since it is added to the vector "fns" at
// runtime.
void fn1() {
printf("fn1\n");
}
// fn2 will be removed by the linker since it isn't referenced at all.
void fn2() {
printf("fn2\n");
}
int main() {
add_fn(make_function_selector_true(fn1));
add_fn(make_function_selector_false(fn2));
}
[2] 编译器消除的死代码
C++ 编译器可以通过静态分析代码的控制流来检测死代码(不可达代码)。例如,如果有一条代码路径位于无条件异常抛出之后,那么它之后的所有代码都将被标记为死代码,并且不会被编译器转换为目标代码。通常,编译器需要使用 -fdce 标志来消除死代码。
在下面的示例中,您可以看到左侧(红色框中)的 C++ 代码没有任何相应的右侧生成的对象代码。
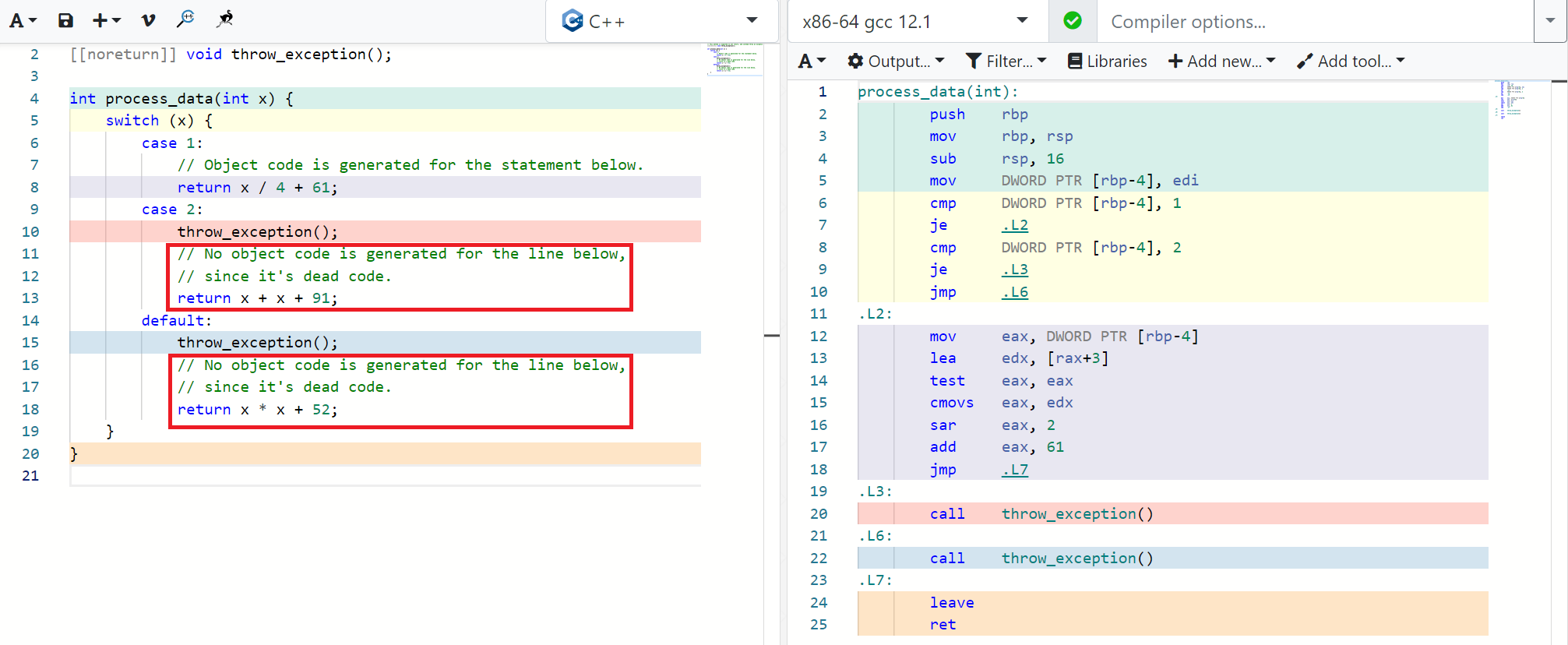
图 4:C++ 编译器消除死代码
此属性在 PyTorch 内核实现的函数体中得到利用,这些函数体包含大量重复代码以处理张量的多种 dtypes。一个dtype是张量存储元素的基础数据类型。它可以是 float、double、int64、bool、int8 等。
几乎每个 PyTorch CPU 内核都使用形式为 AT_DISPATCH_ALL_TYPES* 的宏,用于替换为内核需要处理的每个 dtype 专门编写的代码。例如:
AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND3(
kBool, kHalf, kBFloat16, dtype, "copy_kernel", [&] {
cpu_kernel_vec(
iter,
[=](scalar_t a) -> scalar_t { return a; },
[=](Vectorized<scalar_t> a) -> Vectorized<scalar_t> { return a; });
});
宏 AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND3 内部有一个 switch-case 语句,看起来像上面图 4 中的代码。跟踪过程记录了针对“copy_kernel”内核标签触发的 dtypes,构建过程处理这些标签并在处理不需要此内核标签的 dtype 的每个 case 语句中插入 throw 语句。
这就是 PyTorch 基于跟踪的选择性构建中 dtype 选择性的实现方式。
结论
基于跟踪的选择性构建是一种实用且可扩展的方法,用于仅选择应用程序中使用的部分以保留静态分析无法检测到的代码。此类代码本质上通常高度依赖于数据/输入。
本文详细阐述了基于跟踪的选择性构建的工作原理以及与其实施相关的技术细节。这些技术也可以应用于其他可以从减小二进制文件大小中受益的应用程序和场景。