今天,我们很高兴宣布推出 PyTorch/XLA SPMD:将 GSPMD 集成到 PyTorch 中,并提供易于使用的 API。寻求卓越性能和扩展性的 PyTorch 开发者现在可以训练和部署最大的神经网络,同时最大限度地利用 AI 加速器,例如 Google Cloud TPU。
介绍
GSPMD 是用于机器学习工作负载的自动并行化系统。XLA 编译器根据用户提供的分片提示,将单设备程序转换为带有适当集合操作的分区程序。这使得开发者可以像在单个大型设备上一样编写 PyTorch 程序,无需任何自定义分片计算和/或集合通信操作来扩展模型。
PyTorch/XLA SPMD 允许 PyTorch 用户以更少的精力、更好的性能并行化其机器学习工作负载。以下是一些主要亮点:
- 更好的开发者体验。一切都通过用户提供的少量分片注解完成,PyTorch/XLA SPMD 实现了与最有效的 PyTorch 分片实现相当的性能(参见下面的“示例和结果”部分)。PyTorch/XLA SPMD 将机器学习模型的编程任务与并行化挑战分离。其自动化的模型分片方法使开发者无需实现带有适当集合操作的分片版本操作。
- 一个 API 即可支持各种并行算法(包括数据并行、完全分片数据并行、空间分区张量和流水线并行,以及这些算法的组合),适用于不同的机器学习工作负载和模型架构。
- 大型模型训练中行业领先的性能。PyTorch/XLA SPMD 将强大的 XLA GSPMD 引入 PyTorch,使用户能够充分利用 Google Cloud TPU 的强大功能。
- 使 PyTorch 和 JAX 开发者能够利用相同的底层 XLA API 来扩展模型。
关键概念
分片注解 API 背后的关键概念是:1) Mesh,2) Partition Spec,以及 3) 使用 Mesh 和 Partition Spec 表达分片意图的 mark_sharding API。更详细的设计概述可在此处找到用户指南 这里。
Mesh
对于给定的设备集群,物理网格是互连拓扑的表示。
我们根据此拓扑推导出逻辑网格,以创建设备子组,这些子组可用于模型中张量不同轴的分区。我们应用分片注解将程序映射到逻辑网格;这会自动在程序图中插入通信集合,以支持功能正确性(参见下图)。
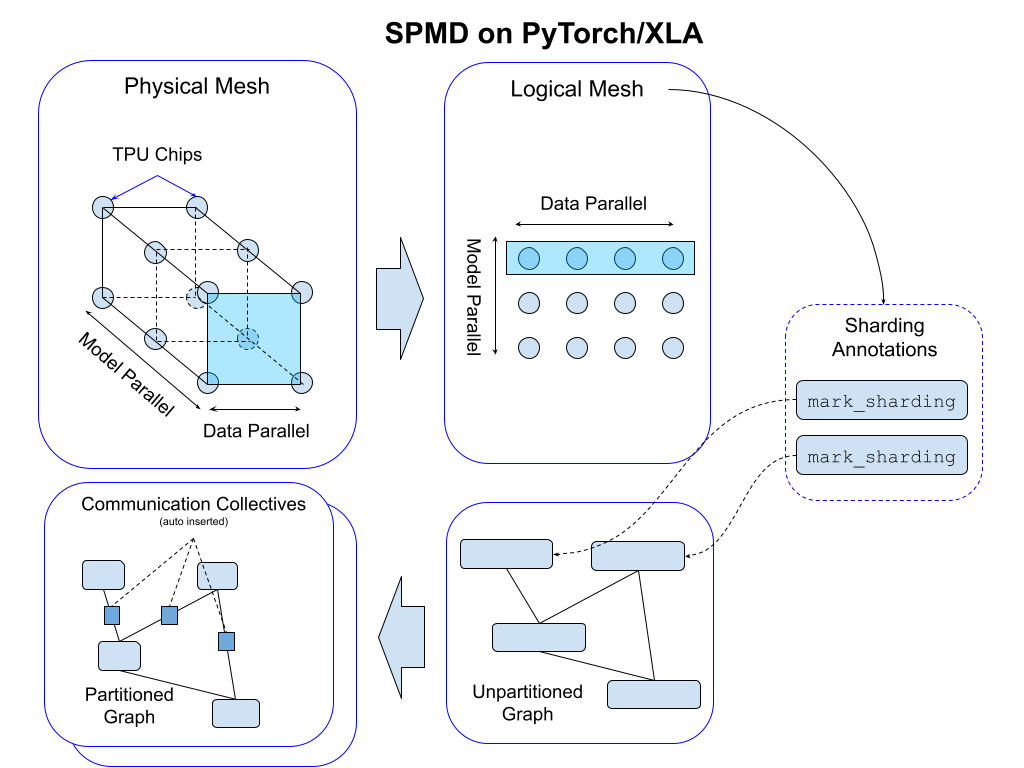
我们使用 Mesh API 抽象逻辑网格。逻辑网格的轴可以命名。这是一个例子:
import numpy as np
import torch_xla.runtime as xr
import torch_xla.experimental.xla_sharding as xs
from torch_xla.experimental.xla_sharding import Mesh
# Enable XLA SPMD execution mode.
xr.use_spmd()
# Assuming you are running on a TPU host that has 8 devices attached
num_devices = xr.global_runtime_device_count()
# mesh shape will be (4,2) in this example
mesh_shape = (num_devices // 2, 2)
device_ids = np.array(range(num_devices))
# axis_names 'x' nad 'y' are optional
mesh = Mesh(device_ids, mesh_shape, ('x', 'y'))
mesh.get_logical_mesh()
>> array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])
mesh.shape()
>> OrderedDict([('x', 4), ('y', 2)])
分区规范
partition_spec 与输入张量具有相同的秩。每个维度描述相应的输入张量维度如何在设备网格(由 mesh_shape 逻辑定义)中进行分片。partition_spec 是一个元组,由 device_mesh 维度 index、None 或网格维度索引的元组组成。如果相应的网格维度已命名,则 index 可以是 int 或 str。这指定了每个输入秩如何分片(mesh_shape 的 index)或复制(None)。
# Provide optional mesh axis names and use them in the partition spec
mesh = Mesh(device_ids, (4, 2), ('data', 'model'))
partition_spec = ('model', 'data')
xs.mark_sharding(input_tensor, mesh, partition_spec)
我们支持原始 GSPMD 论文中描述的所有三种分片类型。例如,可以这样指定部分复制:
# Provide optional mesh axis names and use them in the partition spec
mesh = Mesh(device_ids, (2, 2, 2), ('x', 'y', 'z'))
# evenly shard across x and z and replicate among y
partition_spec = ('x', 'z') # equivalent to ('x', None, 'z')
xs.mark_sharding(input_tensor, mesh, partition_spec)
带有分片注解的简单示例
用户可以使用 mark_sharding API (src) 注解原生 PyTorch 张量。它将 torch.Tensor 作为输入,并返回 XLAShardedTensor 作为输出。
def mark_sharding(t: Union[torch.Tensor, XLAShardedTensor], mesh: Mesh, partition_spec: Tuple[Union[int, None]]) -> XLAShardedTensor
调用 mark_sharding API 接受用户定义的逻辑 mesh 和 partition_spec,并为 XLA 编译器生成分片注解。分片规范附加到 XLATensor 以及原始输入张量。这是一个来自 [RFC] 的简单使用示例,用于说明分片注解 API 的工作原理:
import numpy as np
import torch
import torch_xla.core.xla_model as xm
import torch_xla.runtime as xr
import torch_xla.experimental.xla_sharding as xs
from torch_xla.experimental.xla_sharded_tensor import XLAShardedTensor
from torch_xla.experimental.xla_sharding import Mesh
# Enable XLA SPMD execution mode.
xr.use_spmd()
# Device mesh, this and partition spec as well as the input tensor shape define the individual shard shape.
num_devices = xr.global_runtime_device_count()
mesh_shape = (2, num_devicese // 2) # 2x4 on v3-8, 2x2 on v4-8
device_ids = np.array(range(num_devices))
mesh = Mesh(device_ids, mesh_shape, ('x', 'y'))
t = torch.randn(8, 4).to(xm.xla_device())
# Mesh partitioning, each device holds 1/8-th of the input
partition_spec = (0, 1)
m1_sharded = xs.mark_sharding(t, mesh, partition_spec)
assert isinstance(m1_sharded, XLAShardedTensor) == True
# Note that the sharding annotation is also in-placed updated to t
我们可以在 PyTorch 程序中注解不同的张量,以启用不同的并行技术,如下面评论所述:
# Sharding annotate the linear layer weights. SimpleLinear() is a nn.Module.
model = SimpleLinear().to(xm.xla_device())
xs.mark_sharding(model.fc1.weight, mesh, partition_spec)
# Training loop
model.train()
for step, (data, target) in enumerate(loader):
# Assumes `loader` returns data, target on XLA device
optimizer.zero_grad()
# Sharding annotate input data, we can shard any input
# dimensions. Sharding the batch dimension enables
# data parallelism, sharding the feature dimension enables
# spatial partitioning.
xs.mark_sharding(data, mesh, partition_spec)
ouput = model(data)
loss = loss_fn(output, target)
optimizer.step()
xm.mark_step()
更完整的单元测试用例和集成测试示例可在 PyTorch/XLA 仓库中找到。
结果
性能
我们使用 GPT-2 模型 (src) 测量了 PyTorch/XLA SPMD 的性能,并将其与 用户模式 FSDP 进行了比较。
在此,SPMD 应用了与 FSDP 图相同的分片方案(即 1D 分片)。用户有望通过探索更高级的 SPMD 分片方案获得更好的 MFU 结果。
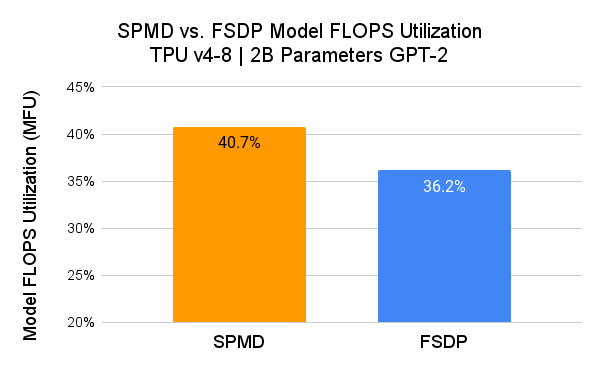
我们使用模型 FLOPS 利用率 (MFU) 作为比较指标。MFU 是“观察到的吞吐量与系统在峰值 FLOPs 下运行的理论最大吞吐量之比”(PaLM 论文)。
flops_per_step = 6 * global_batch_size * seq_len * num_params
model_flops_utilization = flops_per_step / step_time(s) / chip_count / flops_per_chip
此估计假设输入维度远大于输入序列长度 (d_model » seq_len)。如果此假设不成立,则自注意力 FLOPs 开始变得足够显著,并且此表达式将低估真实的 MFU。
可扩展性
SPMD 的核心优势之一是灵活的分区,可用于节省加速器内存 (HBM) 使用并提高可扩展性。对于可扩展性分析,我们提出了两项研究:1) 我们使用 Hugging Face transformers (GPT-2) 作为基础实现,检查了 4 种模型大小的峰值 HBM;2) 我们检查了 空间分区 的峰值 HBM 使用情况。
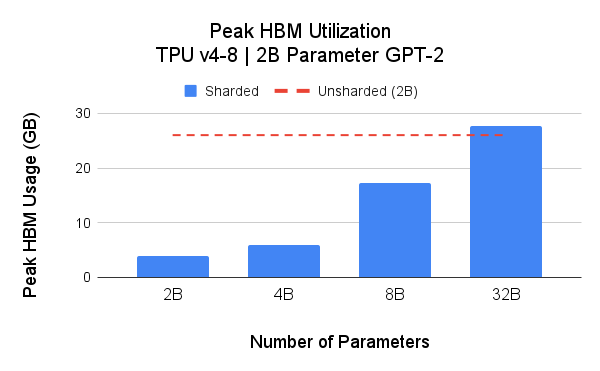
上图显示,未分片的 2B 参数模型峰值内存占用为 26GB(红色虚线)。对模型权重进行分片(模型并行)可减少峰值内存占用,从而在给定的 TPU Pod 切片上训练更大的模型。在这些实验中,我们在 Google Cloud TPU v4-16 上,针对 4B 参数模型实现了高达 39.75% 的 MFU。
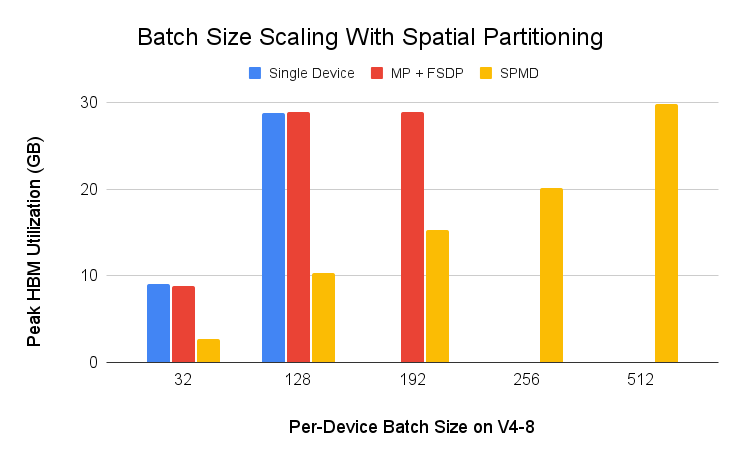
我们还在 Cloud TPU v4-8 上使用 空间分区 和一个简单的 ResNet50 示例 (src) 运行了输入批次可扩展性测试。输入批次通常在批次维度上进行分片以实现数据并行 (DDP, FSDP),但 PyTorch/XLA SPMD 允许输入在输入特征维度上进行分片以实现空间分片。如下图所示,通过空间分区,可以将每个设备的批次大小推至 512,这在其他数据并行技术中是不可能实现的。
PyTorch/XLA SPMD 的未来发展
我们对 PyTorch/XLA 的未来发展感到非常兴奋,并邀请社区加入我们。SPMD 仍处于实验阶段,我们将不断为其添加新功能。在未来的版本中,我们计划解决异步数据加载、部分复制分片以及其他改进。我们很乐意听取您的意见,回答您关于 PyTorch/XLA SPMD 的问题,并了解您如何使用 SPMD。
干杯!
Google 的 PyTorch/XLA 团队