主要收获
- PyTorch 和 vLLM 对人工智能生态系统都至关重要,并且越来越多地被一起用于前沿的生成式人工智能应用,包括推理、后训练和大规模智能体系统。
- 随着 PyTorch 基金会转变为伞形基金会,我们很高兴看到项目被从超大规模企业到初创公司等各种客户使用和支持。
- vLLM 正在利用更广泛的 PyTorch 生态系统加速创新,受益于 torch.compile、TorchAO、FlexAttention 等项目,并合作支持异构硬件和复杂的并行化。
- 这些团队(以及其他团队)正在合作,为大规模推理和后训练构建 PyTorch 原生支持和集成。
甚至在 vLLM 加入 PyTorch 基金会之前,我们已经看到 PyTorch 和 vLLM 在全球一些部署大规模 LLM 的顶尖公司中获得了有机和广泛的 共同采用。有趣的是,这些项目有许多共同点,包括:强大的有远见的领导者;广泛的、有机获得的多边治理结构,其提交者来自多个实体,包括工业界和学术界;以及对开发者体验的压倒性关注。
此外,在过去一年多的时间里,我们看到这两个项目支撑了许多最流行的开源 LLM,包括各种 Llama 和 DeepSeek 模型。鉴于这些项目的相似性和互补性,看到所有不同的集成点确实令人兴奋。
PyTorch → vLLM 集成
在各个点进行集成的总体目标是释放性能并为用户带来新功能。这包括对 Llama 模型以及更广泛的开放模型的优化和支持。
torch.compile: torch.compile 是一个编译器,可以优化 PyTorch 代码,以最少的用户工作量提供快速性能。虽然手动调整模型的性能可能需要几天、几周甚至几个月,但这种方法对于大量模型来说是不切实际的。相反,torch.compile 提供了一个方便的解决方案来优化模型性能。vLLM 默认使用 torch.compile 为其大多数模型生成优化的内核。最近的基准测试显示,torch.compile 在 CUDA 上对 Llama4、Qwen3 和 Gemma3 等流行模型带来了显著的速度提升,范围从 1.05 倍到 1.9 倍。
TorchAO: 我们很高兴地宣布,TorchAO 现在作为 vLLM 中的量化解决方案获得官方支持。此次集成带来了使用 Int4、Int8 和 FP8 数据类型的高性能推理能力,并即将支持专门为 B200 GPU 设计的 MXFP8、MXFP4 和 NVFP4 优化。此外,我们正在努力计划对 AMD GPU 的 FP8 推理支持,从而扩展高性能量化推理的硬件兼容性。
TorchAO 的量化 API 由强大的高性能内核集合提供支持,包括来自 PyTorch Core、FBGEMM 和 gemlite 的内核。TorchAO 技术旨在与 torch.compile 组合。这意味着更简单的实现和 PT2 带来的自动性能提升。编写更少的代码,获得更好的性能。
此次集成最令人兴奋的方面之一是它实现了无缝的工作流程:vLLM 用户现在可以使用 TorchTitan 进行 float8 训练,使用 TorchTune 进行量化感知训练 (QAT),然后通过 vLLM 直接加载和部署其量化模型进行生产推理。这种端到端管道显著简化了从模型训练和微调到部署的路径,使高级量化技术更容易被开发者使用。
FlexAttention: vLLM 现在包含 FlexAttention – 一种专为灵活性设计的新型注意力后端。FlexAttention 提供了一个可编程的注意力框架,允许开发者定义自定义注意力模式,从而更容易支持新型模型设计,而无需进行大量后端修改。
这个由 torch.compile 启用的后端,生成 JIT 融合内核。这在保持非标准注意力模式性能的同时提供了灵活性。FlexAttention 目前在 vLLM 中处于早期开发阶段,尚未准备好投入生产使用。我们将继续投入到此集成中,并计划使其成为 vLLM 建模工具包的强大组成部分。目标是简化对新兴注意力模式和模型架构的支持,从而更容易弥合研究创新与部署就绪推理之间的差距。
异构硬件: PyTorch 团队与不同的硬件供应商合作,为不同类型的 硬件后端(包括 NVIDIA GPU、AMD GPU、Intel GPU、Google TPU 等)提供了坚实的支持。vLLM 推理引擎利用 PyTorch 作为与不同硬件对话的代理,这大大简化了对异构硬件的支持。
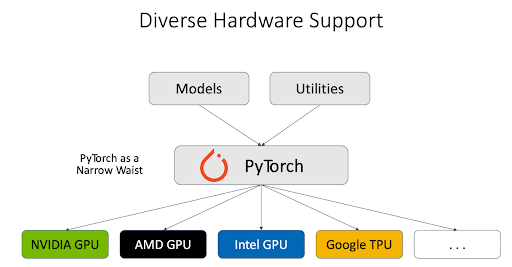
此外,PyTorch 工程师与 vLLM 其他贡献者密切合作,支持下一代 NVIDIA GPU。例如,我们已经彻底测试了 vLLM 在 Blackwell 上的 FlashInfer 支持,进行了性能比较,并调试了精度问题。
PyTorch 团队还与 AMD 合作,增强了对 vLLM + Llama4 的支持,例如 AMD 上的 Llama 4 零日支持以及 MI300x 上的 Llama4 性能优化。
并行化: 在 Meta,我们利用不同类型的并行化及其组合进行生产。流水线并行 (PP) 是其中一种重要的类型。vLLM 中的原始 PP 硬性依赖于 Ray。然而,并非所有用户都利用 Ray 来管理他们的服务和协调不同的主机。PyTorch 团队开发了 支持纯 torchrun 的 PP,并进一步 优化了其方法以重叠微批次之间的计算。此外,PyTorch 工程师还开发了 视觉编码器的数据并行化,这对多模态模型的性能至关重要。
持续集成 (CI): 鉴于 vLLM 对 PyTorch 生态系统至关重要,我们正在合作确保项目之间的 CI 具有良好的测试覆盖率,资金充足,并且整个社区可以依赖所有这些集成。仅仅集成 API 是不够的;重要的是要建立 CI,以确保随着 vLLM 和 PyTorch 都发布新版本和功能,随着时间的推移不会出现任何问题。更具体地说,我们正在测试 vLLM main 和 PyTorch nightly 的组合,我们相信这将为我们和社区提供监控两个项目之间集成状态所需的信号。在 Meta,我们开始将一些开发工作转移到 vLLM main 上,以对 vLLM 的各种正确性和性能方面进行压力测试。此外,vLLM v1 的性能仪表板现已在 hud.pytorch.org 上提供。
下一步…
这仅仅是个开始。我们正在共同努力构建以下高级功能:
1. 大规模模型推理:主要目标是确保 vLLM 在云产品上高效运行,展示关键功能(预填充-解码解耦、多节点并行、高性能内核和通信、上下文感知路由和容错)以扩展到数千个节点,并成为企业构建的稳定基础。在第二季度,Meta 工程师已经在 vLLM 引擎和 KV 连接器 API 的基础上原型化了解耦集成。团队正在与社区合作尝试新策略,并计划将最成功的策略上游,以进一步推动 vLLM 的可能性。
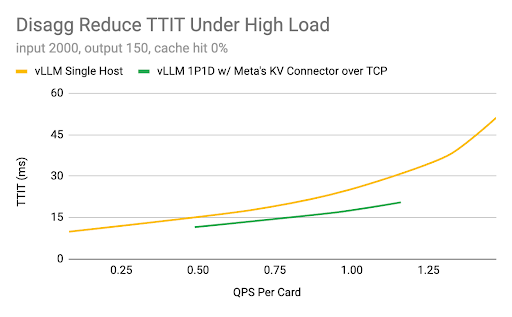
硬件:H100 GPU、96 GB HBM2e、AMD Genoa CPU、CUDA 12.4
2. 强化学习后训练:推理时间计算正迅速成为 LLM 和智能体系统的关键。我们正在开发端到端原生后训练,该训练将强化学习大规模整合,以 vLLM 作为系统的推理骨干。
干杯!
- PyTorch 团队(Meta)和 vLLM 团队