![]()
我们很高兴地宣布,Kubeflow Trainer 项目已集成到 PyTorch 生态系统中!此次集成确保 Kubeflow Trainer 符合 PyTorch 的标准和实践,为开发人员提供了一个可靠、可扩展且由社区支持的解决方案,以便在 Kubernetes 上运行 PyTorch。
要查看 PyTorch 生态系统,请参阅 PyTorch Landscape。了解更多关于项目如何 加入 PyTorch 生态系统的信息。
关于 Kubeflow Trainer
Kubeflow Trainer 是一个 Kubernetes 原生项目,支持可扩展的分布式 AI 模型训练,并专为大型语言模型 (LLM) 的微调而构建。它简化了跨多个节点的训练工作负载的扩展,高效管理大型数据集并确保容错性。

其核心功能包括:
- 简化 Kubernetes 复杂性:Kubeflow Trainer API 专为两种主要用户角色设计——AI 从业者——使用 Kubeflow Python SDK 和 TrainJob API 开发 AI 模型的机器学习工程师和数据科学家,平台管理员——负责管理 Kubernetes 集群和 Kubeflow Trainer 运行时 API 的管理员和 DevOps 工程师。AI 从业者可以专注于 PyTorch 中的应用程序代码,而无需担心基础设施细节。同时,平台管理员可以灵活地调度工作负载资源,以实现最大的集群利用率和成本效率。为了支持这些角色,Kubeflow Trainer 指定了专门构建的 Kubernetes 自定义资源定义 (CRD),以简化模型训练和基础设施管理。
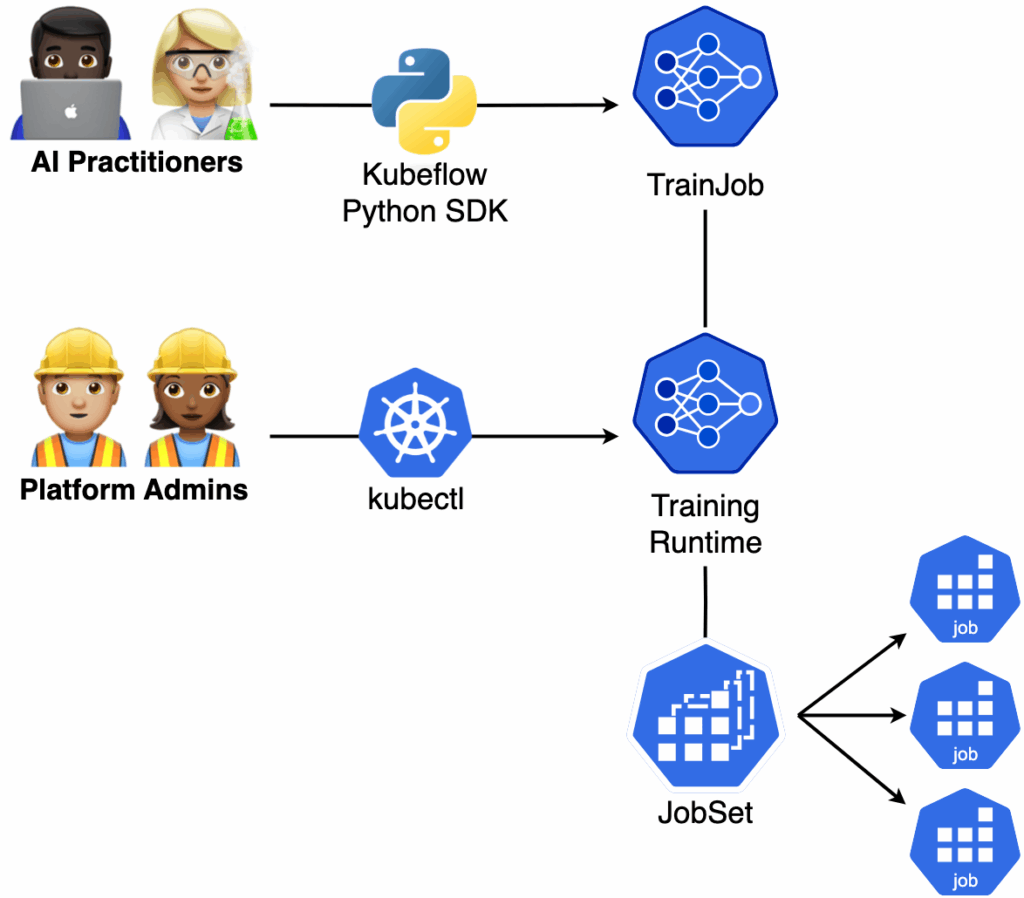
- Python SDK:一个专为 AI 从业者设计的 Pythonic 接口,抽象了直接与 Kubernetes API 交互的细节。它使用户能够专注于开发 PyTorch 模型,而无需担心 Kubernetes YAML 配置。
- 在 Kubernetes 上进行 LLM 微调的蓝图:借助内置的 Trainer,Kubeflow Trainer 使 AI 从业者能够使用所需的数据集、LoRA 参数、学习率等配置无缝微调他们喜欢的 LLM。在第一个版本中,它实现了支持各种微调策略的配方,包括监督微调 (SFT)、知识蒸馏、DPO、PPO、GRPO 和量化感知训练。社区正在努力添加更多由 LLaMA-Factory、Unsloth、HuggingFace TRL 提供支持的内置 Trainer,以实现高效的 LLM 微调。
- 优化 GPU 利用率:Kubeflow Trainer 通过使用由 Apache Arrow 和 Apache DataFusion 提供支持的内存分布式数据缓存,将大规模数据直接传输到分布式 GPU,从而最大限度地提高 GPU 效率。
- 高级调度功能:Kubeflow Trainer 通过 PodGroupPolicy API 支持组调度,实现跨节点的 Pod 协调调度。它还与 Kubernetes 调度器集成,例如 Kueue、Coscheduling、Volcano 和 KAI Scheduler,以确保在训练作业开始前分配所有必需的资源。
- 加速 Kubernetes 上的 MPI 工作负载:Kubeflow Trainer 支持基于 MPI 的运行时,例如 DeepSpeed 和 MLX。它通过基于 SSH 的优化处理所有必要的 MPI 工作负载编排,以提高 MPI 性能。
- 提高弹性和容错性:通过利用 Kubernetes 原生 API,如 Jobs 和 JobSets,Kubeflow Trainer 提高了 AI 工作负载的可靠性和效率。通过支持 PodFailurePolicy API,用户可以通过避免不必要的重启来降低成本。此外,SuccessPolicy API 允许训练作业在达到目标后提前完成。
背景和演变
该项目最初是作为 TensorFlow 的分布式训练操作符(例如 TFJob)启动的,后来我们合并了来自其他 Kubeflow 训练操作符(例如 PyTorchJob、MPIJob)的努力,为用户和开发人员提供统一和简化的体验。我们非常感谢所有提出问题或帮助解决问题、提问和回答问题以及参与启发性讨论的人。我们还要感谢所有为原始操作符做出贡献和维护的人。
通过加入 PyTorch 生态系统,我们力求在 Kubernetes 上部署分布式 PyTorch 应用程序时应用最佳实践,并在 Kubeflow Trainer 中带来一流的 PyTorch 支持。
与 PyTorch 生态系统的集成
Kubeflow Trainer 与 PyTorch 生态系统深度集成,支持广泛的工具和库——包括 torch、DeepSpeed、HuggingFace、Horovod 等。
它使 PyTorch 用户能够实施高级分布式训练策略,例如分布式数据并行 (DDP)、完全分片数据并行 (FSDP & FSDP2) 和张量并行,从而在 Kubernetes 上实现高效的大规模模型训练。
此外,Kubeflow Trainer 支持使用 PyTorch IterableDatasets 进行数据并行,直接从分布式内存数据缓存节点流式传输数据。这使得即使数据集规模庞大,超出本地内存容量,也能实现可扩展的训练。
快速入门
按照以下步骤快速部署 Kubeflow Trainer 并运行您的第一个训练作业。
先决条件
安装 Kubeflow Trainer
在您的本地 kind 集群上部署 Kubeflow Trainer 控制平面:
$ kind create cluster
$ kubectl apply --server-side -k "https://github.com/kubeflow/trainer.git/manifests/overlays/manager?ref=v2.0.0"
# Ensure that JobSet and Trainer controller manager are running.
$ kubectl get pods -n kubeflow-system
NAME READY STATUS RESTARTS AGE
jobset-controller-manager-54968bd57b-88dk4 2/2 Running 0 65s
kubeflow-trainer-controller-manager-cc6468559-dblnw 1/1 Running 0 65s
# Deploy the Kubeflow Trainer runtimes.
$ kubectl apply --server-side -k "https://github.com/kubeflow/trainer.git/manifests/overlays/runtimes?ref=v2.0.0"
# Install Kubeflow SDK
$ pip install git+https://github.com/kubeflow/sdk.git@64d74db2b6c9a0854e39450d8d1c0201e1e9b3f7#subdirectory=python定义 PyTorch 训练函数
安装 Kubeflow Trainer 后,定义您的 PyTorch 训练函数,其中包含端到端训练脚本
def train_pytorch():
import os
import torch
import torch.distributed as dist
from torch.utils.data import DataLoader, DistributedSampler
from torchvision import datasets, transforms, models
# [1] Configure CPU/GPU device and distributed backend.
device, backend = ("cuda", "nccl") if torch.cuda.is_available() else ("cpu", "gloo")
dist.init_process_group(backend=backend)
local_rank = int(os.getenv("LOCAL_RANK", 0))
device = torch.device(f"{device}:{local_rank}")
# [2] Get the pre-defined model.
model = models.shufflenet_v2_x0_5(num_classes=10)
model.conv1 = torch.nn.Conv2d(1, 24, kernel_size=3, stride=2, padding=1, bias=False)
model = torch.nn.parallel.DistributedDataParallel(model.to(device))
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
# [3] Get the FashionMNIST dataset and distribute it across all available devices.
if local_rank == 0: # Download dataset only on local_rank=0 process.
dataset = datasets.FashionMNIST("./data", train=True, download=True, transform=transforms.Compose([transforms.ToTensor()]))
dist.barrier()
dataset = datasets.FashionMNIST("./data", train=True, download=False, transform=transforms.Compose([transforms.ToTensor()]))
train_loader = DataLoader(dataset, batch_size=100, sampler=DistributedSampler(dataset))
# [4] Define the PyTorch training loop.
for epoch in range(3):
for batch_idx, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
# Forward and Backward pass
outputs = model(inputs)
loss = torch.nn.functional.cross_entropy(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 10 == 0 and dist.get_rank() == 0:
print(f"Epoch {epoch} [{batch_idx * len(inputs)}/{len(train_loader.dataset)}] "
f"Loss: {loss.item():.4f}"
)
使用 TrainJob 在 Kubernetes 上运行 PyTorch
定义训练函数后,使用 Kubeflow SDK 创建 TrainJob
from kubeflow.trainer import TrainerClient, CustomTrainer
job_id = TrainerClient().train(
trainer=CustomTrainer(
func=train_pytorch,
num_nodes=2,
resources_per_node={
"cpu": 3,
"memory": "3Gi",
# "gpu": 2, # Uncomment this line if you have GPUs.
},
),
runtime=TrainerClient().get_runtime("torch-distributed"),
)
获取 TrainJob 结果
创建 TrainJob 后,您应该能够列出它:
for job in TrainerClient().list_jobs():
print(f"TrainJob: {job.name}, Status: {job.status}")
TrainJob: q33a18f65635, Status: Created TrainJob 第一次拉取 PyTorch 镜像可能需要几分钟。一旦镜像被拉取,TrainJob 的步骤应该转换为 运行中 状态。每个步骤代表一个训练节点,每个步骤的设备数量对应于该节点上的设备数量。
for s in TrainerClient().get_job(name=job_id).steps:
print(f"Step: {s.name}, Status: {s.status}, Devices: {s.device} x {s.device_count}")
Step: node-0, Status: Running, Devices: cpu x 3
Step: node-1, Status: Running, Devices: cpu x 3 步骤运行后,您可以检查 TrainJob 日志。60,000 个样本的数据集已均匀分布在 6 个 CPU 上,每个设备处理 10,000 个样本:60,000 / 6 = 10,000
print(TrainerClient().get_job_logs(name=job_id)["node-0"])
...
Epoch 0 [8000/60000] Loss: 0.4476
Epoch 0 [9000/60000] Loss: 0.4784
Epoch 1 [0/60000] Loss: 0.3909
Epoch 1 [1000/60000] Loss: 0.4888
Epoch 1 [2000/60000] Loss: 0.4100
... 恭喜您,您已使用 PyTorch 和 Kubeflow Trainer 创建了您的第一个分布式训练作业!
下一步
Kubeflow Trainer 具有令人兴奋的路线图,包括以下项目
- 本地 TrainJob 执行 – 在没有 Kubernetes 的情况下本地运行 Kubeflow Trainer 作业。
- 分布式数据缓存 – 通过 Apache Arrow 和 Apache DataFusion 提供支持的内存分布式数据流。
- 高级调度功能 – 通过与 Kueue、KAI Scheduler、Volcano 集成,改进资源管理和组调度功能。
- 支持 JAX 运行时。
- 为 GPU 加速工作负载自动化 Checkpointing。
行动号召
我们很高兴地欢迎 Kubeflow Trainer 加入 PyTorch 生态系统!Kubeflow Trainer 使 AI 模型训练在 Kubernetes 上普及化,并显著改善了 AI 从业者的开发体验。我们邀请您探索以下资源,以了解有关该项目的更多信息
- 阅读 Kubeflow Trainer v2 公告博客文章和 发布说明。
- 探索 官方 Kubeflow Trainer 文档。
- 加入 #kubeflow-trainer Slack 频道中的对话。
- 参加我们每周三举行的双周 Kubeflow Trainer 社区会议。
- 通过在 GitHub 仓库上提出问题来分享您的用例或功能提案。
- 通过撰写 Kubeflow 博客文章或在即将到来的 Kubeflow 活动中发表演讲来讲述您的故事。
- 探索 面向 AI 从业者的 Kubeflow Python SDK。
我们迫不及待地想看到您将使用 Kubeflow Trainer 构建什么!