我们很高兴正式推出 torchao,这是一个 PyTorch 原生库,它通过利用低位数据类型、量化和稀疏性来使模型更快、更小。torchao 是一个易于访问的技术工具包,(大部分)用易于阅读的 PyTorch 代码编写,涵盖推理和训练。这篇博客将帮助您选择适合您工作负载的技术。
我们对 Llama 3 和扩散模型等流行的生成式人工智能模型进行了技术基准测试,并发现准确性下降极小。除非另有说明,基线是在 A100 80GB GPU 上运行的 bf16。
Llama 3 的核心指标如下:
- 使用 int4 仅权重(weight only)量化和 HQQ 的 autoquant,Llama 3 8B 推理速度提升 97%
- Llama 3.1 8B 在 128K 上下文长度推理时,通过量化 KV 缓存,峰值显存(VRAM)减少 73%
- Llama 3 70B 在 H100 上使用 float8 训练,预训练速度提升 50%
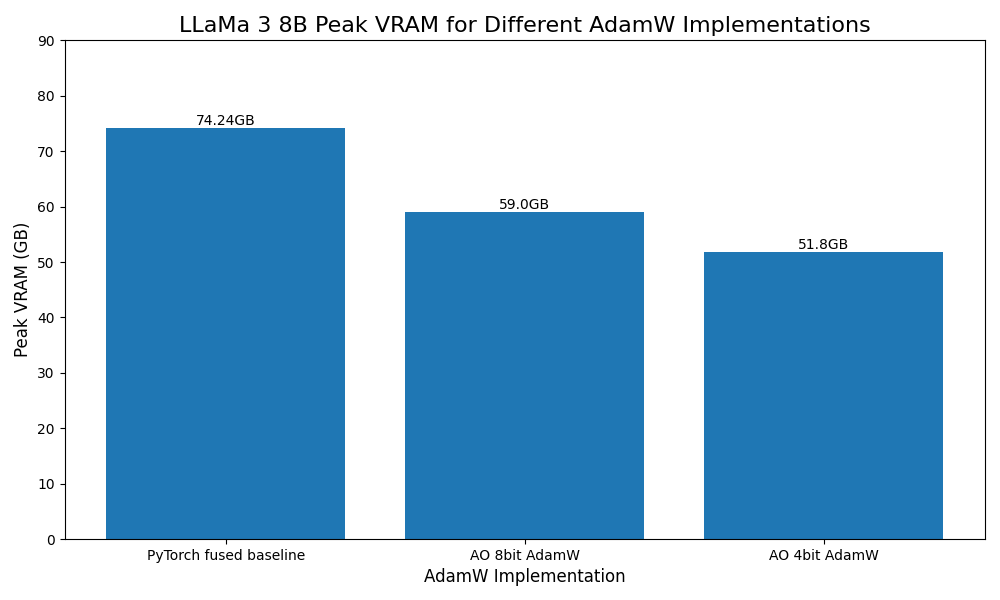
- Llama 3 8B 使用 4 位量化优化器,峰值显存(VRAM)减少 30%。
扩散模型推理的核心指标如下:
- 在 H100 上的 flux1.dev 上,使用 float8 动态量化推理和 float8 行式(row-wise)缩放,速度提升 53%
- CogVideoX 使用 int8 动态量化,模型显存(VRAM)减少 50%
下面我们将介绍 torchao 中可用于推理和训练模型的一些技术。
推理
我们的推理量化算法 适用于包含 nn.Linear 层的任意 PyTorch 模型。可以使用我们的顶级 quantize_ API 选择针对各种数据类型和稀疏布局的仅权重(weight only)和动态激活量化。
from torchao.quantization import (
quantize_,
int4_weight_only,
)
quantize_(model, int4_weight_only())
有时,由于开销,量化层可能会使其变慢,因此如果您希望我们为您选择模型中每个层的量化方式,您可以运行:
model = torchao.autoquant(torch.compile(model, mode='max-autotune'))
quantize_ API 有几种不同的选项,具体取决于您的模型是计算密集型(compute bound)还是内存密集型(memory bound)。
from torchao.quantization import (
# Memory bound models
int4_weight_only,
int8_weight_only,
# Compute bound models
int8_dynamic_activation_int8_semi_sparse_weight,
int8_dynamic_activation_int8_weight,
# Device capability 8.9+
float8_weight_only,
float8_dynamic_activation_float8_weight,
)
我们还与 HuggingFace diffusers 团队合作,在 diffusers-torchao 中对扩散模型进行了广泛的基准测试,其中我们展示了 Flux.1-Dev 上 53.88% 的速度提升和 CogVideoX-5b 上 27.33% 的速度提升。
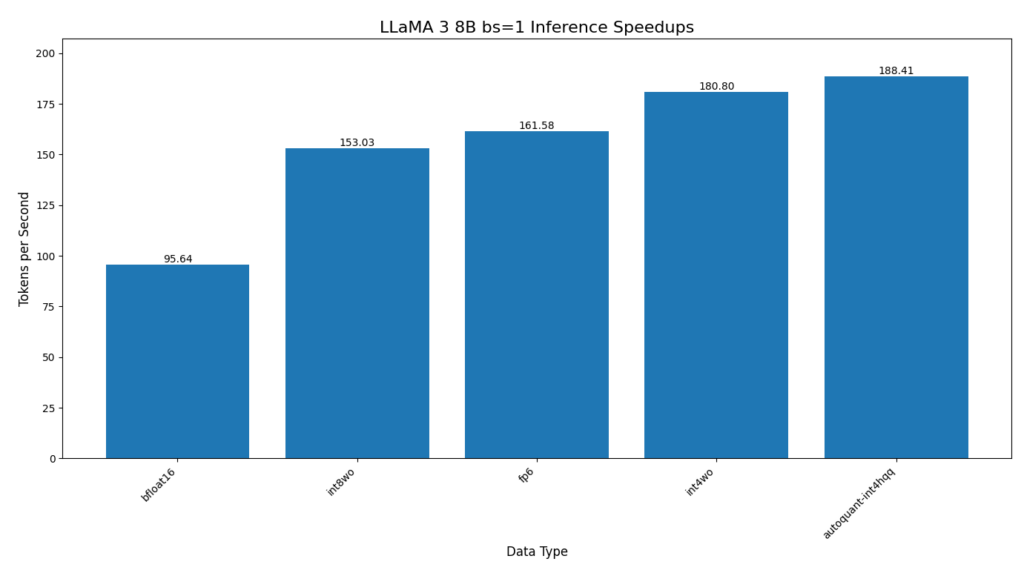
我们的 API 是可组合的,例如,我们已经组合了稀疏性和量化,为 ViT-H 推理带来了 5% 的速度提升。
但也可以做一些事情,例如将权重量化为 int4,将 KV 缓存量化为 int8,以支持 Llama 3.1 8B 在不到 18.9GB 的 VRAM 中以完整的 128K 上下文长度运行。
QAT
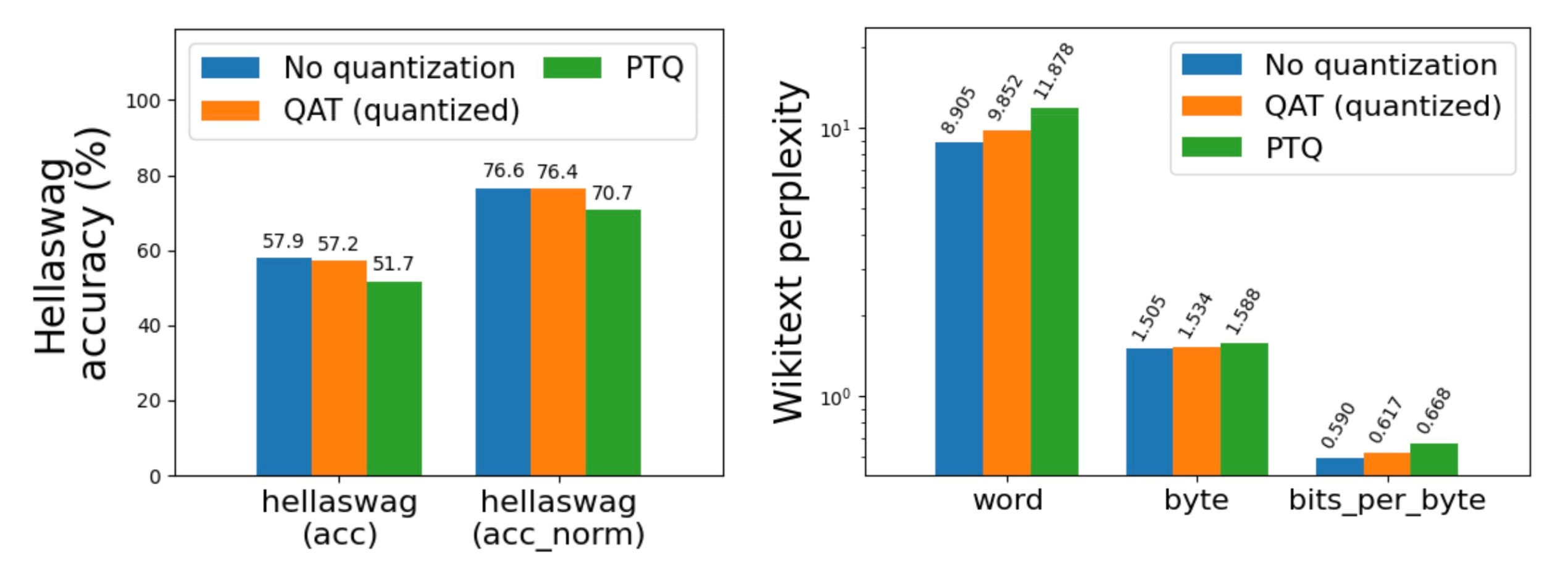
训练后量化,尤其是低于 4 位的量化,可能会导致严重的精度下降。通过使用 量化感知训练 (QAT),我们成功地在 hellaswag 上恢复了高达 96% 的精度下降。我们已将其作为 torchtune 中的端到端配方集成,并提供了最少的 教程。
训练
低精度计算和通信
torchao 提供了易于使用的端到端工作流程,用于降低训练计算和分布式通信的精度,从 `torch.nn.Linear` 层的 float8 开始。这是一个将您的训练运行的计算 gemms 转换为 float8 的单行代码:
from torchao.float8 import convert_to_float8_training
convert_to_float8_training(model)
有关如何使用 float8 将 LLaMa 3 70B 预训练加速高达 1.5 倍 的端到端示例,请参阅我们的 README,以及 torchtitan 的 博客 和 float8 配方。
LLaMa 3 70B float8 预训练与 bfloat16 的性能和准确性
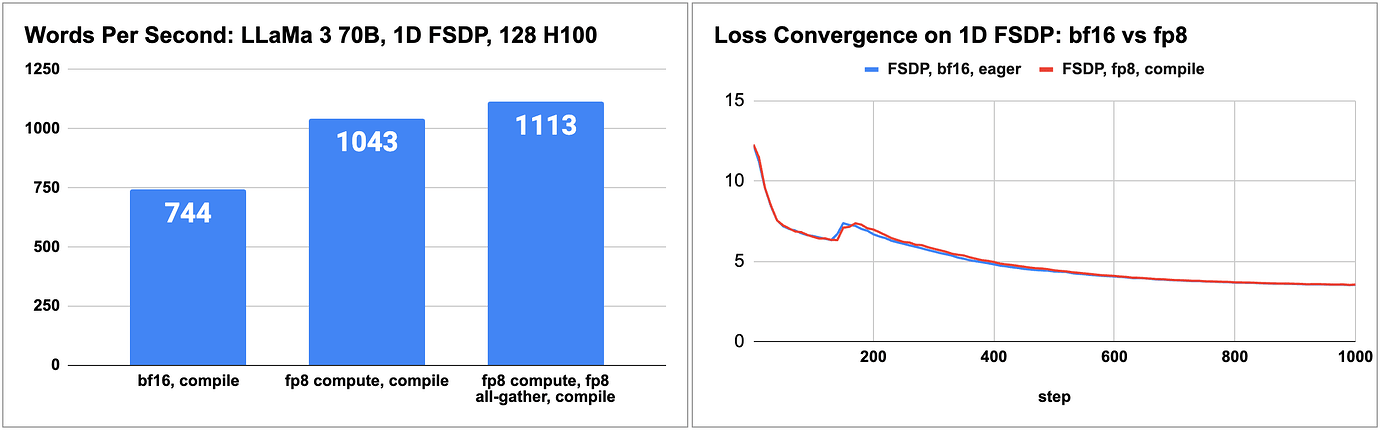 (来源:https://dev-discuss.pytorch.org/t/enabling-float8-all-gather-in-fsdp2/2359)
(来源:https://dev-discuss.pytorch.org/t/enabling-float8-all-gather-in-fsdp2/2359)
我们正在将训练工作流程扩展到更多数据类型和布局
低位优化器
受 Bits and Bytes 的启发,我们还添加了 8 位和 4 位优化器的原型支持,可作为 AdamW 的直接替代。
from torchao.prototype.low_bit_optim import AdamW8bit, AdamW4bit
optim = AdamW8bit(model.parameters())
集成
我们一直积极致力于确保 torchao 在一些最重要的开源项目中良好运行。
- Huggingface transformers 作为 推理后端
- 在 diffusers-torchao 中 作为加速扩散模型的参考实现
- 在 HQQ 中用于 快速 4 位推理
- 在 torchtune 中 用于 PyTorch 原生 QLoRA 和 QAT 配方
- 在 torchchat 中 用于训练后量化
- 在 SGLang 中用于 int4 和 int8 训练后量化
结论
如果您有兴趣让您的模型在训练或推理时更快、更小,我们希望您会发现 torchao 有用且易于集成。
pip install torchao
我们对接下来有很多兴奋的事情,包括低于 4 位、用于高吞吐量推理的高性能内核、扩展到更多层、缩放类型或粒度、MX 硬件支持以及支持更多硬件后端。如果以上任何一项听起来令人兴奋,您可以在这里关注我们的进展:https://github.com/pytorch/ao
如果您有兴趣参与 torchao 的工作,我们创建了 贡献者指南,如果您有任何问题,我们会在 discord.gg/gpumode 的 #torchao 频道上与您交流。
致谢
我们很幸运能站在巨人的肩膀上,并与一些最优秀的开源人士合作。谢谢!
- Bits and Bytes 在低位优化器和 QLoRA 方面的开创性工作
- Answer.ai 在使 FSDP 和 QLoRA 兼容方面的工程工作
- Mobius Labs 在量化算法和低位内核方面的精彩交流
- HuggingFace transformers 在实战测试和集成我们工作方面的帮助
- HuggingFace diffusers 在广泛基准测试和最佳实践方面的合作
- torch.compile 使我们能够用纯 PyTorch 编写算法
- GPU MODE 的大部分早期贡献者