在这篇博文中,我们讨论了如何使用 PyTorch 原生优化(例如原生快速内核、torch compile 的编译转换和用于分布式推理的张量并行)来改善 Llama 2 系列模型的推理延迟。我们的方法在 70B LLaMa 模型上实现了单个用户请求 29 毫秒/token 的延迟(在 8 块 A100 GPU 上测量)。我们很高兴与社区分享我们的发现,并在此提供我们的代码。
背景
我们正处于生成式 AI 革命之中,拥有数百亿参数的大型语言模型正在商品化并可供使用。然而,社区普遍认为,以经济高效的方式部署这些大型模型仍然是一个关键挑战。人们尝试了许多不同的方法,取得了不同程度的成功并提供了不同的权衡。特定硬件的优化(例如 NVIDIA 的 Faster Transformer)仅限于特定的目标硬件,而依赖于抽象层的方法(例如 ONNX)则支持任意模型,但效率会降低。随着去年 PyTorch Compile 的推出,IBM 和 PyTorch 团队开始探索使用模型编译进行推理优化,目标是降低生成模型的每 token 延迟。
模型选择
鉴于 Llama 2 系列模型的流行性,我们选择对其进行基准测试。我们感兴趣的模型及其与本博文相关的超参数如下表所示。
| 模型大小 | 隐藏维度 | 头数 | 层数 | 注意力类型 |
| 7B | 4096 | 32 | 32 | MHA |
| 13B | 5120 | 40 | 40 | MHA |
| 70B | 8192 | 64 | 80 | GQA |
这些模型仅包含解码器,这意味着 token 是以序列化方式生成的,通常使用 KV 缓存来加速。我们在延迟和吞吐量测量中也采用了类似的方法。
推理方法
我们进行推理的目标是提供一条能够快速实现最佳延迟的路径,以跟上社区中新模型架构涌现的速度。PyTorch 原生方法具有吸引力,因为它在模型的“覆盖范围”方面提供了最大的灵活性。我们注意到有四种正交技术可以加速推理:(a) 使用编译进行内核融合,(b) 更快的内核,(c) 用于大型模型的张量并行,以及 (d) 量化。在我们的方法中,我们使用了这四个杠杆中的前三个——编译原生与 SDPA 的更快内核以及定制的张量并行实现协同工作,以在单个用户使用 8 块 NVIDIA A100 GPU 测量 70B 模型时,实现 29 毫秒/token 的推理延迟。
一路编译!
PyTorch Compile 利用跟踪和图捕获来减少 CPU 开销,在理想情况下,CPU 到 GPU 只需要一次图执行/指令。然而,由于模型架构和编译不支持的操作,编译经常会引入图中断。例如,目前编译不支持 einops 等复杂操作。同样,张量并行推理会在每一层引入图中断,因为编译要求张量并行实现使用可跟踪的通信集合。如果不消除这些图中断,编译工件的性能将受到影响,甚至可能低于 eager 模式执行。要充分利用编译工件的优势,需要消除图中断。
下面,我们描述了如何为 70B Llama 2 模型实现这一点,以及我们为使编译全程顺利运行所必须克服的挑战。
我们的第一次尝试是使用 torch.compile 编译开箱即用的 Llama 2 模型,但由于不支持复杂操作而失败了。通过使用 TORCH_COMPILE_DEBUG = 1,我们发现 RoPE 位置编码使用了复数函数,导致图中断和显著的减速。我们重写了 RoPE 函数,以绕过 torch.einsum(原始实现使用了也与编译冲突的 torch.polar),并改用 torch.cos 和 torch.sin。
self.cached_freqs[dev_idx][alpha] = torch.stack(
[
torch.cos(freqs),
-torch.sin(freqs),
torch.sin(freqs),
torch.cos(freqs),
],
dim=2,
).view(*freqs.shape, 2, 2)
我们实现的频率计算
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
t = t / self.scaling_factor
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
Hugging Face 实现的频率计算
RoPE 修复后,我们能够在单个 A100 GPU 上编译 7B 和 13B 模型,没有任何图中断。
我们使用了 SDPA,PyTorch 原生实现的高效注意力计算,并启用了跟踪(用于编译)。为了避免与使用 Python 上下文强制选择单个算法相关的图中断(这是推荐的方法),我们不得不使用 `torch.backends.cuda.enable_*_sdp` 函数。
attn = torch.nn.functional.scaled_dot_product_attention(
queries,
keys_e,
values_e,
attn_mask=attn_mask,
dropout_p=self.p_dropout if self.training else 0.0,
is_causal=is_causal_mask,
)
使用 SDPA 进行注意力计算
接下来,我们对更大的 70B 模型执行了相同的步骤,发现即使使用半精度,模型也无法适应单个 GPU,需要张量并行推理。对 70B 模型使用 torch.compile 导致了 162 个图中断,原因是每层有两个 all-reduce,一个用于前向嵌入的 all-gather,以及一个用于反向嵌入的 all-gather。因此,我们没有看到推理延迟有显著改善。在撰写本博文时,我们无法使用 PyTorch 的分布式张量实现,因为它不支持编译。我们从头重写了张量并行代码,使其仅依赖可跟踪的集合以使其与编译兼容。在进行这一最终更改后,PyTorch 编译器没有引入任何图中断,并且我们看到推理延迟显著加速。具体来说,当使用 8 个 A100 GPU 时,我们测量 Llama 70B 模型的延迟为 29 毫秒/token,比未优化的推理提高了 2.4 倍。
服务方面
最后,这里需要注意的是,仅仅对模型进行编译不足以在生产环境中服务模型。为了在高吞吐量下实现上述性能,我们需要支持动态批处理、嵌套张量,并且需要一个预热阶段,在此阶段我们为桶化的序列长度进行预编译。我们正在致力于这些方面,以在生产环境中实现此类性能。
实验与测量
我们使用配备 8 块 80G A100 NVIDIA GPU 的节点,在两种不同的环境(IBM Cloud 和 AWS,均运行 OpenShift)中进行所有测量。首先,我们比较了各种技术—— eager 模式、带有 SDPA Flash 内核、带有 Compile,以及带有 Compile 和 SDPA。对于 70B 模型,我们以张量并行模式运行,并使用 Compile 和 SDPA。在本实验中,我们使用 512 个 token 作为输入长度,生成 50 个 token。对于 7B 和 13B 模型,我们使用单个 A100 来测量延迟,而对于 70B 模型,我们使用 8 个 A100。此外,对于 70B 模型,我们使用 PyTorch Compile 中的 reduce-overhead 选项,该选项使用 CudaGraphs 来减少 CPU 到 GPU 内核启动开销;在 7B 和 13B 模型中使用 CudaGraphs 未显示任何好处(因此此处未报告)。从图 1 中我们观察到,Compile 和 SDPA 提供了非常低的延迟,70B Llama 2 模型达到 29 毫秒/token。
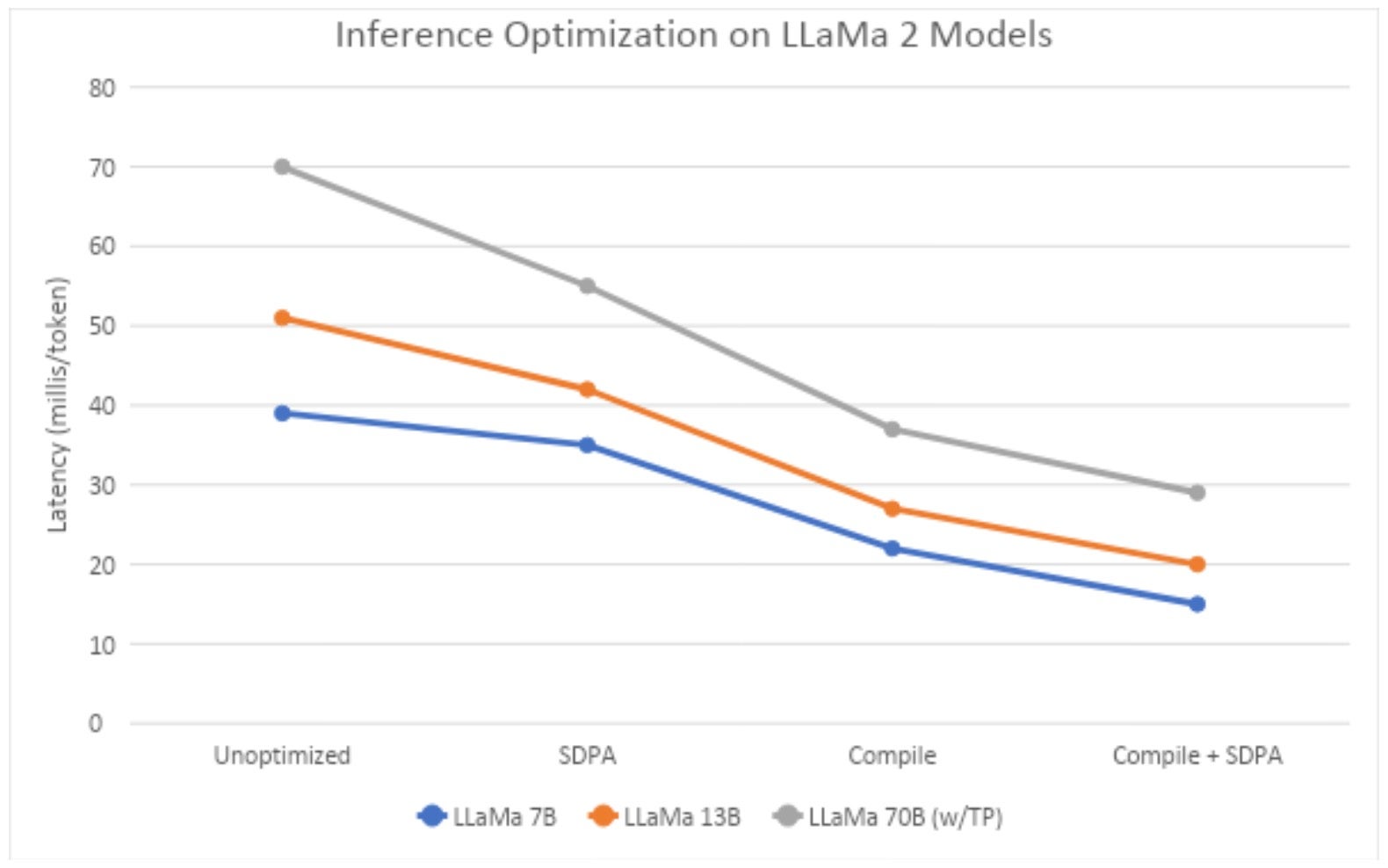
图 1:不同技术在序列长度为 512 时的中位延迟(在 IBM Cloud A100 服务器上测量)
接下来,我们检查序列长度的影响,将其从 1024 增加到 4096,观察到每 token 的中位延迟呈次线性增长,表明当我们增加上下文到大型文档时,我们不会牺牲响应时间。
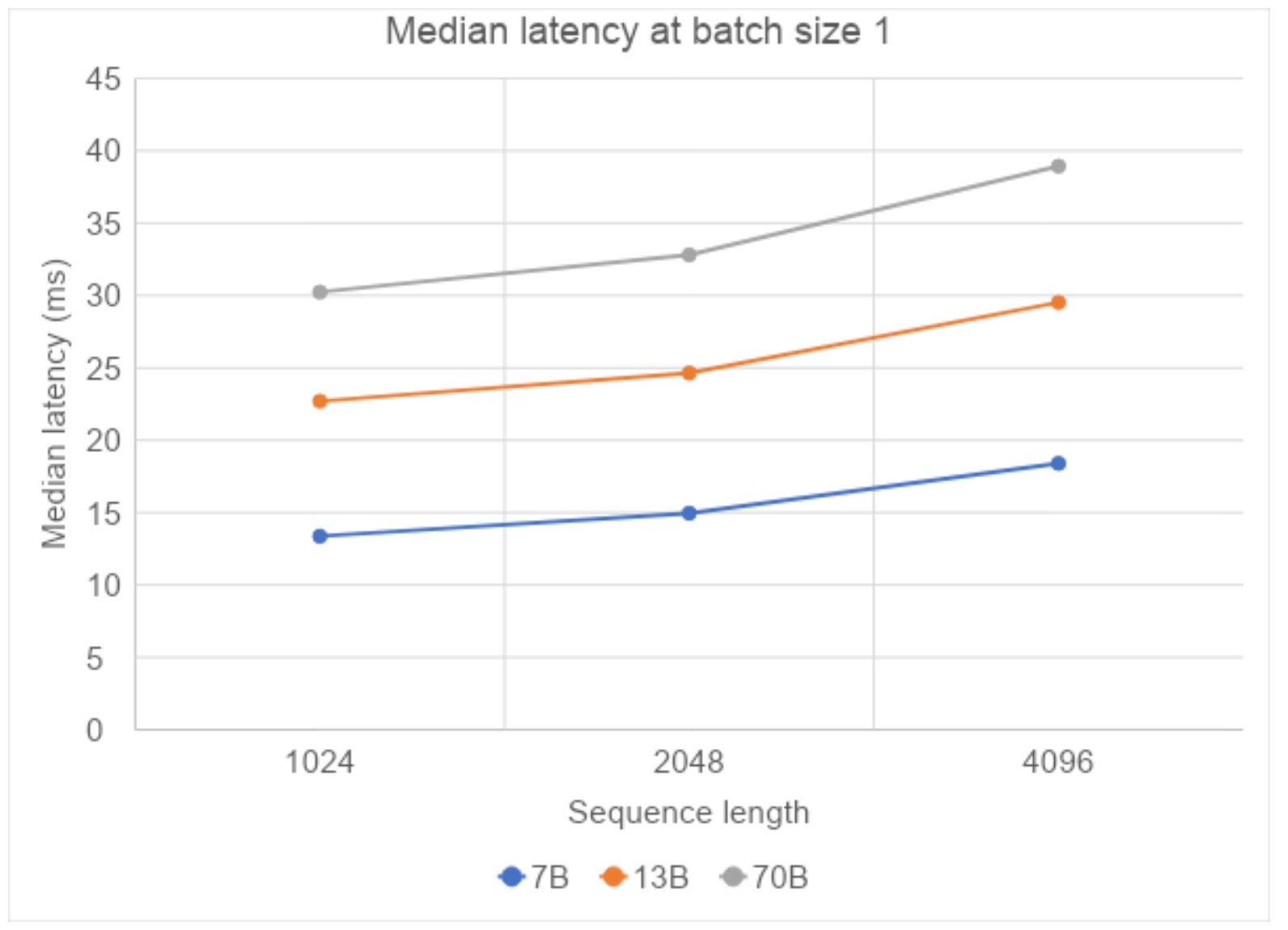
图 2:Compile+SDPA 在不同序列长度下的中位延迟(在 AWS 的 A100 上测量)
最后,随着批处理量的增加,我们观察到响应延迟呈次线性增长。对于 13B 模型,在批处理量为 8 时,我们遇到了 OOM(内存不足)。对于 70B 模型,鉴于它在 8 个 GPU 上以张量并行模式运行,我们没有看到任何此类 OOM 问题。
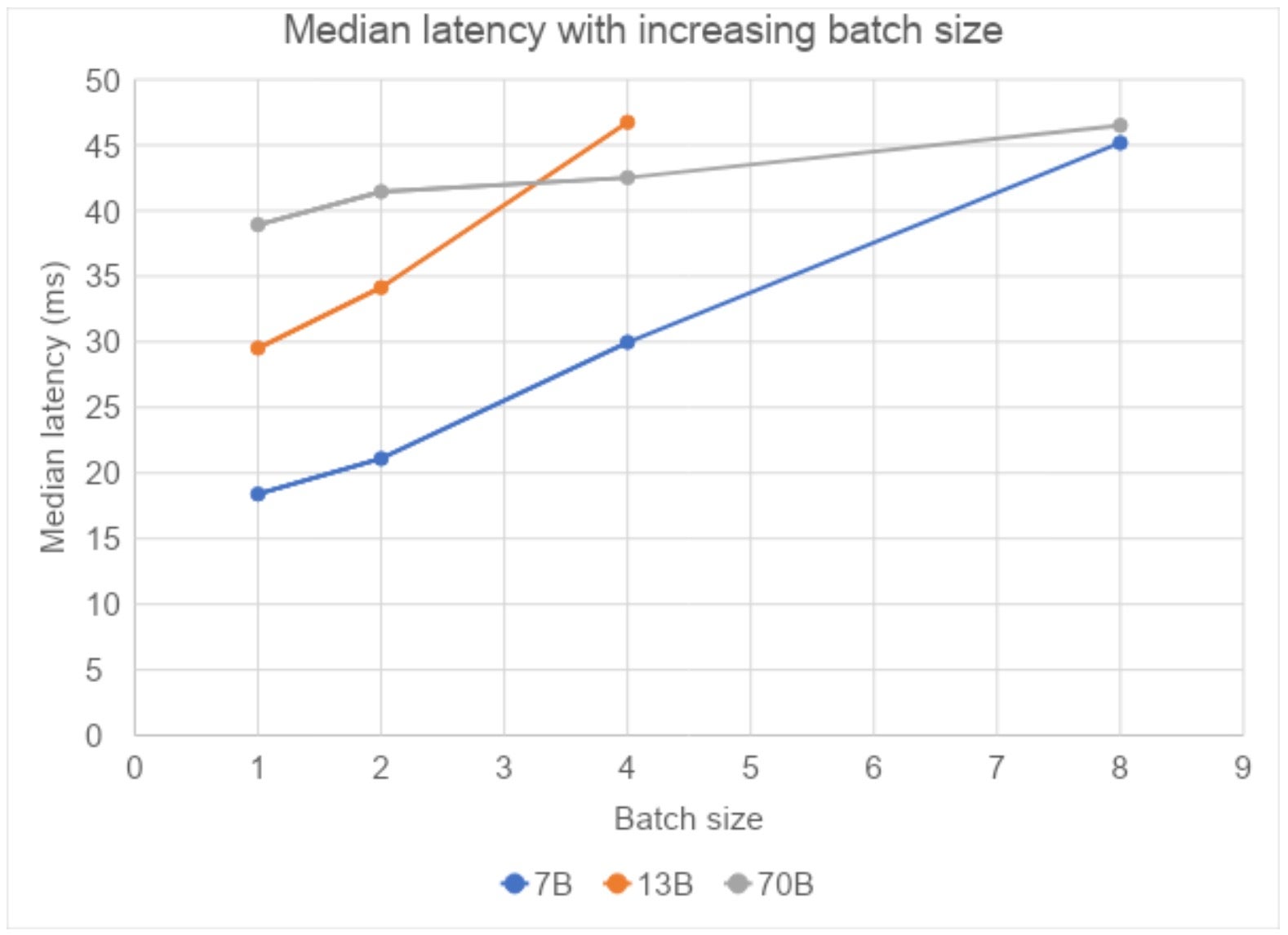
图 3:Compile+SDPA 在不同批处理量和固定序列长度为 4096 时的中位延迟(在 AWS 的 A100 上测量)
总结
我们已经展示了 PyTorch Compile 推理路径如何为 70B 模型推理提供超低延迟。下一步是结合上述杠杆启用动态批处理和嵌套张量。
特别感谢 PyTorch 团队的 Edward Yang、Elias Ellison、Driss Guessous、Will Feng、Will Constable、Horace He、Less Wright 和 Andrew Gu,他们的 PR 审查和代码贡献使我们能够使用 PyTorch 原生方法实现这些低延迟。我们感谢更广大的 PyTorch 团队,他们不知疲倦地努力使 PyTorch 变得更好,特别感谢 SDPA 团队在快速内核上启用跟踪和编译,以及编译团队一直密切指导我们如何解决和修复问题(包括识别和提出 CUDA 图中的 NVIDIA 驱动程序错误)。
推理延迟一直是 LLM 在关键企业工作流中应用的主要障碍之一,但另一个主要障碍是对安全性、可信赖性和治理的需求。IBM 关于 AI 安全和 LLM 风险的指南可在此处找到,Meta 的 LLaMa 负责任使用指南可在此处找到。
参考文献
- GitHub 资源:https://ibm.biz/fm-stack
- 使用 PyTorch/XLA 在 LLaMa 65B 上实现超低推理延迟的路径
- 速度,Python:二者选其一。CUDA 图如何为深度学习启用快速 Python 代码
- IBM 在 AI 伦理与信任方面的资源:https://www.ibm.com/downloads/cas/E5KE5KRZ
- Meta LLaMa 负责任使用指南:https://ai.meta.com/llama/responsible-use-guide/