Intel 宣布 PyTorch 2.8 在分布式训练方面取得了重大进展:为 Intel® GPU(Intel® XPU 设备)原生集成了 XCCL 后端。这直接将 Intel® oneAPI Collective Communications Library (oneCCL) 支持引入 PyTorch,为开发人员提供了无缝、开箱即用的体验,可在 Intel 硬件上扩展 AI 工作负载。
在 Intel® GPU 上实现无缝分布式训练
在此版本之前,PyTorch 缺乏在 Intel GPU 上进行分布式训练的内置方法,这使得用户无法充分利用高级功能。PyTorch 2.8 中原生 XCCL 后端的引入弥补了这一空白。XCCL 的集成遵循了由 公开 RFC 指导的透明、社区驱动的流程,以确保设计符合 PyTorch 的可用性和可靠性核心原则。
这种集成对于以下方面至关重要:
- 提供无缝用户体验: 对于大多数开发人员来说,在 Intel GPU 上进行分布式训练现在可以正常工作,与在其他硬件上的简单体验保持一致。这消除了以前的进入障碍并简化了工作流程。
- 保证功能对等: 确保最先进的 PyTorch 功能,例如完全分片数据并行性 v2 (FSDP2),在 Intel 硬件上无缝工作。
- 生态系统的未来保障: 允许 Intel 硬件立即受益于 PyTorch 中所有未来的分布式增强。
如何使用 XCCL 后端
此功能的主要目标是为 XPU 设备上的用户提供一个简单且与现有后端(如 NCCL 和 Gloo)一致的分布式 API。为了确保可靠性,我们付出了巨大的努力来重构测试,使其与后端无关,从而使 XCCL 的单元测试通过率很高。
使用新后端非常简单。要使用 XCCL 显式初始化进程组,您可以将其指定为后端。
# No extra imports needed! import torch import torch.distributed as dist # Check if the XPU device and XCCL are available if torch.xpu.is_available() and dist.is_xccl_available(): # Initialize with the native 'xccl' backend dist.init_process_group(backend='xccl', ...)
为了获得更流畅的体验,PyTorch 2.8 在 Intel XPU 设备上运行时会自动选择 XCCL 作为默认后端。
# On XPU devices, PyTorch 2.8 will automatically activate the XCCL backend dist.init_process_group(...)
XCCL 的成功经验
原生 XCCL 支持对 PyTorch 的影响是立竿见影且意义重大的。
无缝生态系统集成:TorchTitan
现在,基于 PyTorch 构建的框架只需少量修改(如果有的话)即可在 Intel GPU 上运行。例如,用于生成式 AI 模型大规模训练的平台 TorchTitan 可以与 XCCL 后端无缝、开箱即用地运行。使用 TorchTitan,我们成功地使用先进的多维并行性(FSDP2 和张量并行性)在 XPU 设备上预训练了 Llama3 模型。这些模型表现出卓越的收敛性,并扩展到 2K 级别,与竞争对手旗鼓相当。
Argonne 国家实验室:使用 Aurora 超级计算机进行科学 AI 研究
截至 2025 年 6 月,美国能源部 (DOE) Argonne 国家实验室的 Aurora 百亿亿次超级计算机在 HPL-MxP AI 性能基准测试中排名第二 [1,2]。它拥有 10,624 个计算节点,每个节点承载六个 Intel GPU。
作为我们与 Argonne 持续合作的一部分,我们利用 PyTorch 原生的大规模分布式训练功能,使科学家能够使用 Aurora 解决当今最具挑战性的问题,从气候建模和药物发现到宇宙学和基础物理学。
案例研究 1:CosmicTagger 模型
我们为 CosmicTagger 模型(一个用于分析中微子数据的基于 U-Net 的分割模型)启用了 XCCL 后端。结果非常出色:
- 该模型在使用分布式数据并行 (DDP) 进行扩展(单个节点内的多个设备)分布式训练时实现了 99% 的扩展效率。
- 使用 Float32 和 BFloat16 精度测试数据集,它平均达到了约 78% 的准确率。
- 在 FP32 精度弱扩展运行中,该模型在扩展(跨多个节点的多个设备)分布式训练中,扩展到 2,048 个 Aurora 节点(24,576 个级别) 时,实现了近 92% 的扩展效率(见图 1)。
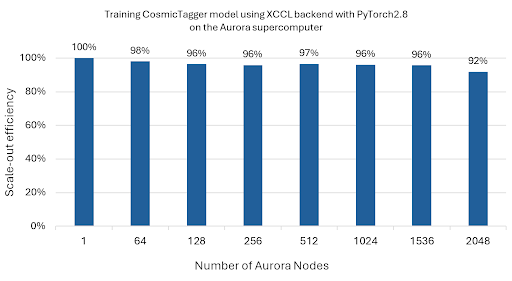
图 1:CosmicTagger 模型扩展到 2,048 个 Aurora 节点(24,576 个级别)的扩展效率结果。
* 扩展效率衡量分布式训练中性能扩展的程度。扩展配置的扩展效率计算为使用多个级别在节点内训练时的每个级别的吞吐量,并相对于使用相同数量但独立并行执行的最低吞吐量级别进行归一化。多节点扩展训练的扩展效率计算为使用多个节点时的每个级别的吞吐量,并相对于使用单个节点时的每个级别的吞吐量进行归一化。
案例研究 2:LQCD-su3-4d 模型
LQCD-su3-4d 模型用于高保真物理模拟,以求解夸克和胶子的量子色动力学 (QCD) 理论。我们为该模型启用了 XCCL 后端,并使用 PyTorch 的 DDP 成功地在多达 2,048 个 Aurora 节点(24,576 个级别) 上进行 FP64 精度训练,在弱扩展运行中实现了超过 89% 的扩展效率(见图 2)。
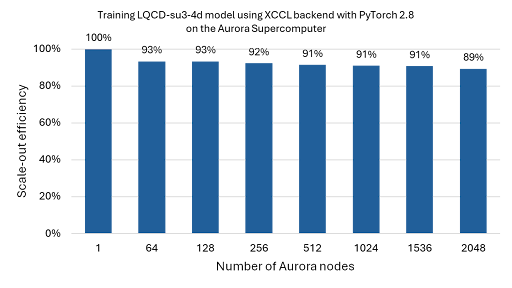
图 2:LQCD-su3-4d 模型扩展到 2,048 个 Aurora 节点(24,576 个级别)的扩展效率结果。
案例研究 3:Llama3 模型预训练
为了支持 Argonne 雄心勃勃的 AuroraGPT 项目 [3],我们已开始使用 TorchTitan 在 Aurora 上预训练大型语言模型。图 3 展示了使用 FSDP2 和 XCCL 后端在单个 Aurora 节点(12 个级别)上运行的 Llama3-8B 模型的收敛性研究,展示了稳定的训练和成功的检查点。
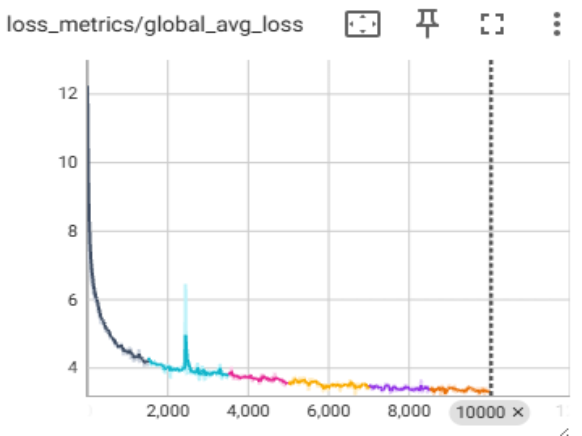
图 3:单个 Aurora 节点上的 Llama3-8b 收敛性研究。
案例研究 4:将 Llama3 8B 预训练扩展到 2K 级别
Llama 3 8B 模型预训练已使用 TorchTitan 中提供的多维并行性(见图 4)在 C4 数据集上扩展到 2K 级别。TorchTitan 中可用的超参数和模型未经任何更改就被使用。节点内使用 TP,节点间使用 FSDP。
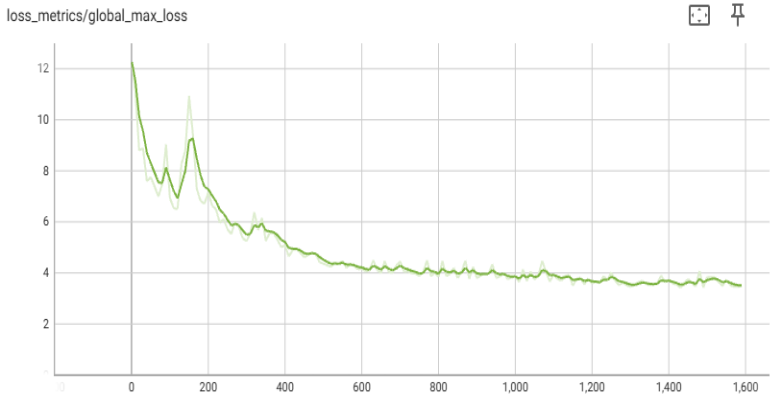
图 4:Aurora 上 2K 级别的 Llama3-8b 收敛性研究。
立即开始!
原生 XCCL 支持现已在 PyTorch 2.8 中提供。更新您的环境,将您在 Intel 硬件上的分布式训练提升到一个新的水平。
请注意:在 PyTorch 2.8 中,原生 XCCL 支持适用于 Linux 系统上的 Intel® 数据中心 GPU。
有关更多详细信息,请查看官方文档:
- PyTorch 分布式概述: https://pytorch.ac.cn/docs/stable/distributed.html
- is_xccl_available 检查: https://pytorch.ac.cn/docs/stable/distributed.html#torch.distributed.distributed_c10d.is_xccl_available
参考文献:
[1] Argonne 国家实验室的 Aurora 超级计算机: https://www.anl.gov/aurora
[2] HPL-MxP 基准测试结果: https://hpl-mxp.org/results.md
[3] Argonne 国家实验室的 AuroraGPT 项目: https://auroragpt.anl.gov/
性能因使用、配置和其他因素而异。Intel、Intel 徽标和其他 Intel 标记是 Intel Corporation 或其子公司的商标。其他名称和品牌可能属于其他公司的财产。