我们很高兴地宣布 PyTorch® 1.13 版本发布(发行说明)!其中包括 BetterTransformer 的稳定版本。我们已弃用 CUDA 10.2 和 11.3,并完成了 CUDA 11.6 和 11.7 的迁移。测试版包括对 Apple M1 芯片和 functorch 的改进支持,functorch 是一个提供可组合的 vmap(向量化)和 autodiff 转换的库,已随 PyTorch 版本一起包含在内。自 1.12.1 版本以来,此版本包含超过 3,749 次提交和 467 名贡献者。我们衷心感谢我们敬业的社区所做出的贡献。
总结
- BetterTransformer 功能集支持在推理过程中为常见的 Transformer 模型提供开箱即用的快速路径执行,而无需修改模型。其他改进包括加速 add+matmul 线性代数内核,适用于 Transformer 模型中常用的尺寸,并且嵌套张量现在默认启用。
- 及时弃用旧版 CUDA 允许我们继续引入 Nvidia® 发布的最新的 CUDA 版本,从而支持 PyTorch 中的 C++17 和新的 NVIDIA Open GPU Kernel 模块。
- 此前,functorch 是作为单独的包在外部发布的。安装 PyTorch 后,用户将能够 `import functorch` 并使用 functorch,而无需安装其他包。
- PyTorch 正在为使用 Apple 新的 M1 芯片的 Apple® Silicon 机器提供原生构建,作为测试版功能,为 PyTorch 的 API 提供改进的支持。
除了 1.13 版本,我们还在发布 PyTorch 库的重大更新,更多详细信息请参见此 博客。
稳定功能
(稳定)BetterTransformer API
BetterTransformer 功能集(最初在 PyTorch 1.12 中发布)现已稳定。PyTorch BetterTransformer 支持在推理过程中为常见的 Transformer 模型提供开箱即用的快速路径执行,而无需修改模型。为了补充 Better Transformer 的改进,我们还加速了 add+matmul 线性代数内核,适用于 Transformer 模型中常用的尺寸。
为了反映对许多 NLP 用户的性能优势,Better Transformer 使用嵌套张量现在默认启用。为了确保兼容性,会执行一个掩码检查以确保提供连续掩码。在 Transformer 编码器中,可以通过设置 mask_check=False 来抑制 src_key_padding_mask 的掩码检查。这加速了那些能够保证只提供对齐掩码的用户的处理。最后,提供了更好的错误消息来诊断不正确的输入,以及改进了为什么不能使用快速路径执行的诊断。
Better Transformer 直接集成到 PyTorch TorchText 库中,使 TorchText 用户能够透明地自动利用 BetterTransformer 的速度和效率性能。(教程)
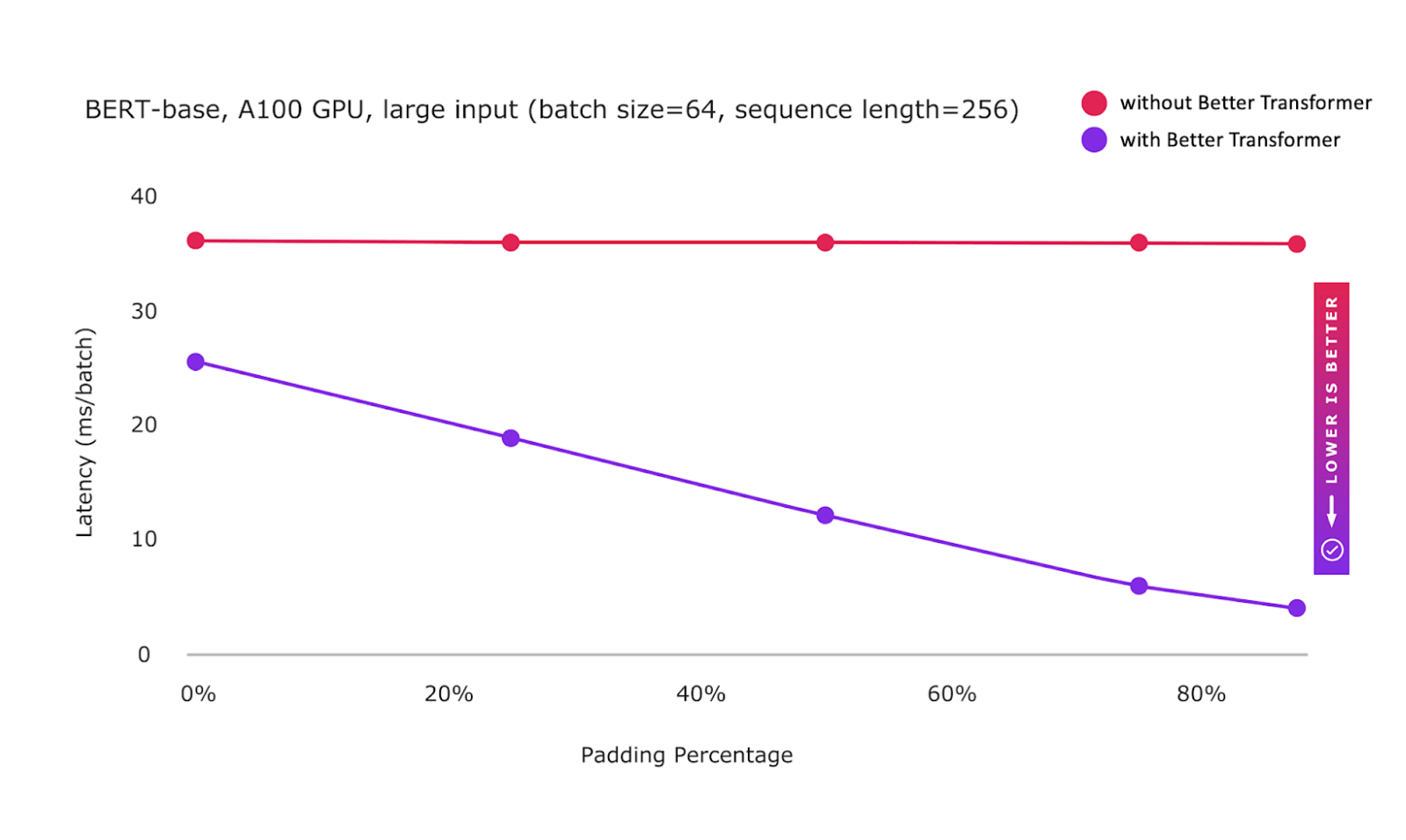
图: BetterTransformer 快速路径执行现已稳定,并默认启用使用嵌套张量表示的稀疏性优化
引入 CUDA 11.6 和 11.7 并弃用 CUDA 10.2 和 11.3
及时弃用旧版 CUDA 允许我们继续引入 Nvidia® 发布的最新的 CUDA 版本,从而允许开发者使用 CUDA 的最新功能并受益于最新版本提供的正确性修复。
CUDA 10.2 退役。CUDA 11 是第一个支持 C++17 的 CUDA 版本。因此,退役旧版 CUDA 10.2 是在 PyTorch 中添加 C++17 支持的重要一步。它还有助于通过消除旧版 CUDA 10.2 特定的指令来改进 PyTorch 代码。
CUDA 11.3 的退役和 CUDA 11.7 的引入带来了对新的 NVIDIA Open GPU Kernel 模块的兼容性支持,另一个重要的亮点是延迟加载支持。CUDA 11.7 随附 cuDNN 8.5.0,其中包含多项优化,可加速基于 Transformer 的模型,将库大小减少 30%,并改进了运行时融合引擎。通过我们的 发行说明 了解有关 CUDA 11.7 的更多信息。
测试版功能
(测试版)functorch
受 Google® JAX 启发,functorch 是一个提供可组合的 vmap(向量化)和 autodiff 转换的库。它支持在 PyTorch 中难以表达的高级 autodiff 用例。例如:
我们很高兴地宣布,作为与 PyTorch 更紧密集成的重要一步,functorch 已移至 PyTorch 库内部,不再需要安装单独的 functorch 包。通过 conda 或 pip 安装 PyTorch 后,您将能够在程序中 `import functorch`。通过我们的 详细说明、夜间构建 和 发行说明 了解更多信息。
(测试版)Intel® VTune™ Profiler 的 Instrumentation and Tracing Technology API (ITT) 集成
PyTorch 用户能够在 Intel® VTune™ Profiler 中可视化 PyTorch 脚本执行的操作级时间线,当他们需要在 Intel 平台上使用低级性能指标分析每个操作的性能时。
with torch.autograd.profiler.emit_itt():
for i in range(10):
torch.itt.range_push('step_{}'.format(i))
model(input)
torch.itt.range_pop()
通过我们的 教程 了解更多信息。
(测试版)NNC:添加 BF16 和 Channels last 支持
通过向 NNC 添加 channels last 和 BF16 支持,TorchScript 图模式在 x86 CPU 上的推理性能得到了提升。PyTorch 用户可以在最流行的 x86 CPU 上受益于 channels last 优化,并在 Intel Cooper Lake 处理器和 Sapphire Rapids 处理器上受益于 BF16 优化。在 Intel Cooper Lake 处理器上,通过这两种优化,在广泛的视觉模型上观察到几何平均性能提升 >2 倍。
可以通过现有的 TorchScript、channels last 和 BF16 Autocast API 获得性能优势。请参阅下面的代码片段。我们将把 NNC 中的优化迁移到新的 PyTorch DL 编译器 TorchInductor。
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
# Convert the model to channels-last
model = model.to(memory_format=torch.channels_last)
model.eval()
data = torch.rand(1, 3, 224, 224)
# Convert the data to channels-lastdata = data.to(memory_format=torch.channels_last)
# Enable autocast to run with BF16
with torch.cpu.amp.autocast(), torch.no_grad():
# Trace the model
model = torch.jit.trace(model, torch.rand(1, 3, 224, 224))
model = torch.jit.freeze(model)
# Run the traced model
model(data)
(测试版)对 M1 设备的支持
自 v1.12 以来,PyTorch 一直为使用 Apple 新 M1 芯片的 Apple® Silicon 机器提供原生构建作为原型功能。在此版本中,我们将此功能带到测试版,为 PyTorch 的 API 提供改进的支持。
我们现在在 M1 macOS 12.6 实例上运行所有子模块的测试,除了 `torch.distributed`。通过这种改进的测试,我们能够修复 cpp 扩展和某些输入的卷积正确性等功能。
要开始使用,只需在您的 Apple Silicon Mac 上安装 PyTorch v1.13,该 Mac 运行 macOS 12 或更高版本,并带有原生版本 (arm64) 的 Python。通过我们的 发行说明 了解更多信息。
原型功能
(原型)AWS Graviton 对 Arm® Compute Library (ACL) 后端支持
我们通过 Arm Compute Library (acl) 为 aarch64 cpu 上的 CV 和 NLP 推理实现了显著改进,以支持 pytorch 和 torch-xla 模块的 acl 后端。亮点包括:
- 将 mkldnn + acl 启用为 aarch64 torch wheel 的默认后端。
- 为 aarch64 bf16 设备启用了 mkldnn matmul 运算符。
- 将 TensorFlow xla+acl 功能引入 torch-xla。我们增强了 TensorFlow xla 与 Arm Compute Library 运行时,用于 aarch64 cpu。这些更改已包含在 TensorFlow master 中,然后是即将发布的 TF 2.10。一旦 torch-xla 仓库针对 tensorflow commit 进行更新,它将支持 torch-xla 的编译。与 Graviton3 上的 torch 1.12 wheel 相比,MLPerf Bert 推理观察到约 2.5-3 倍的改进。
(原型)CUDA Sanitizer
启用后,sanitizer 开始分析用户 PyTorch 代码导致的低级 CUDA 操作,以检测由不同 CUDA 流的非同步数据访问引起的数据竞争错误。然后,发现的错误将与错误访问的堆栈跟踪一起打印,就像 Thread Sanitizer 所做的那样。一个简单错误和 sanitizer 产生的输出示例可以在 这里 查看。它将特别适用于机器学习应用程序,其中损坏的数据可能很容易被人忽略,并且错误可能不总是显现出来;sanitizer 将始终能够检测到它们。
(原型)有限的 Python 3.11 支持
支持 Python 3.11 的 Linux 二进制文件可通过 pip 下载。请按照 入门页面 上的说明进行操作。请注意,Python 3.11 支持仅为预览版。特别是,包括分布式、分析器、FX 和 JIT 在内的功能可能尚未完全正常运行。