引言
随着对各种硬件加速器需求的增长,对健壮且适应性强的深度学习框架的需求变得越来越重要。在进行此集成时,PyTorch 生态系统中出现了一些挑战,可能会影响各种硬件供应商。本博客旨在突出这些问题并提出解决方案,以增强 PyTorch 在不同硬件平台上的适应性、可移植性和弹性。
通过加速器自动加载提高用户代码的可移植性
目前,用户在不同加速器上运行代码时面临额外的工作。其中一项任务是手动导入非核心设备的模块。这要求用户不仅要理解加速器之间不同的使用模式,还要使他们的代码了解这些差异。如果您有最初在 GPU/CPU 上运行并希望迁移到其他加速器的项目,这可能会导致大量工作和潜在的挫败感。
额外导入的示例
# Case 1: Use HPU
import torch
import torchvision.models as models
import habana_frameworks.torch # <-- extra import
model = models.resnet50().eval().to("hpu")
input = torch.rand(128, 3, 224, 224).to("hpu")
output = model(input)
# Case 2: Use torch_npu
import torch
import torch_npu # <-- extra import
print(torch.ones(1, 2, device='npu'))
作为一个高级机器学习框架,PyTorch 能够屏蔽用户与设备之间的差异,这是一个竞争优势。加速器自动加载允许用户继续使用熟悉的 PyTorch 设备编程模型,而无需显式加载或导入特定于设备的扩展。
它是如何工作的?
利用 Python 的插件架构,通过 PyTorch 包中的入口点实现设备扩展的自动加载。
Python 入口点为 Python 包提供了一种标准化的方式,用于在应用程序中公开和发现组件或插件。通过在加速器包的setup.py中定义,PyTorch 可以在调用import torch时自动初始化加速器模块,这为用户在不同后端设备之间提供了 consistent 的体验。
从设备角度来看,只需要在setup.py中声明以下设置(以torch_npu为例):
// setup.py
entry_points={
'torch.backends': ['torch_npu = torch_npu:_autoload', ],
}
当调用import torch时,加速器模块将自动加载。这为用户提供了跨非核心设备的一致编程体验,消除了了解 CUDA、HPU 和 NPU 之间差异的必要性。
# Case 1: Use HPU
import torch
import torchvision.models as models
model = models.resnet50().eval().to("hpu")
input = torch.rand(128, 3, 224, 224).to("hpu")
output = model(input)
# Case 2: Use torch_npu
import torch
print(torch.ones(1, 2, device='npu'))
设备集成优化
什么是 PrivateUse1?
在 PyTorch 中,调度器是框架后端的一个关键组件,它管理操作如何路由到适当的设备特定实现。调度键是该系统不可或缺的一部分,用作表示各种执行上下文(例如设备(CPU、CUDA、XPU)、布局(密集、稀疏)和自动梯度功能)的标识符。这些键确保操作被定向到正确的实现。
PrivateUse1 是一个可定制的设备调度键,类似于 CUDA/CPU/XPU 等),保留用于非核心设备。它为开发人员提供了一种在不修改核心框架的情况下扩展 PyTorch 功能的方法,从而可以集成新设备、硬件加速器或其他专用计算环境。
为什么我们需要 PrivateUse1?
在内部,调度键表示为位掩码,每个位表示某个键是否处于活动状态。这种位掩码表示形式对于快速查找和组合键非常有效,但它本质上限制了不同键的数量(通常为 64 或更少)。
PyTorch 中 BackendComponent 调度键的当前实现遇到了一个关键瓶颈,这限制了新后端的添加,从而限制了 PyTorch 生态系统的扩展。
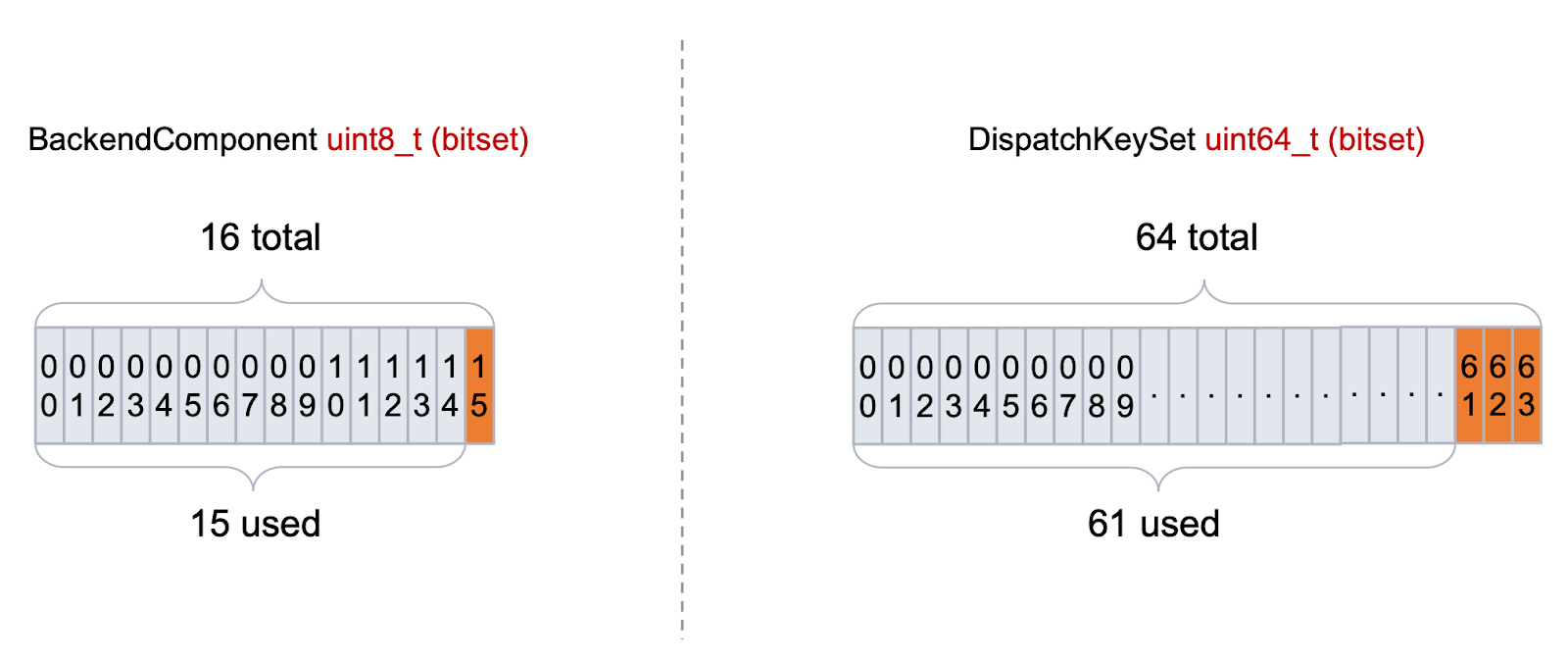
为了应对这一挑战,对 PrivateUse1 机制进行了一系列优化,以增强其容量。
- PrivateUse1 集成机制 最初作为备用选项保留,PrivateUse1,以及 PrivateUse2 和 PrivateUse3,被设计为仅在现有键资源稀缺时激活。PrivateUse1 现在正在开发中,以匹配 CUDA 和 CPU 等现有键的健壮性和多功能性。实现这一点需要在关键的 PyTorch 模块中进行深度集成。这种集成不仅仅是简单的切换——它涉及对 AMP(自动混合精度)、Autograd、分布式训练、检查点、DataLoader、优化和量化等核心组件的重大更新。
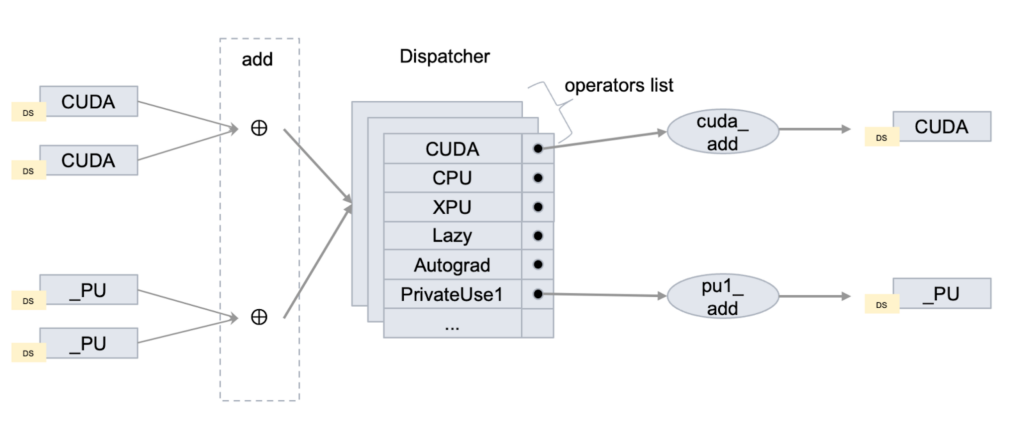
PrivateUse1 的激活是一项巨大的协作努力,最终完成了 100 多个拉取请求,旨在使其从占位符发展成为一个完全可操作的调度键。
- PrivateUse1 UT/CI 质量保证 单元测试对于确保 PrivateUse1 机制开发过程中的质量至关重要,但它们本身不足以防止新的拉取请求无意中影响现有功能或非核心设备的兼容性。为了减轻这种风险,社区已将
pytorch_openreg模块添加到测试套件中。该模块利用 CPU 后端模拟与加速器的交互,为严格测试创建受控环境。实施后,这将能够在相关代码更新时自动执行设备通用测试用例,从而使我们能够快速检测和解决影响 PrivateUse1 集成机制的任何潜在问题。 - 综合文档 通过提供全面易懂的文档,我们旨在降低开发人员的入门门槛,并鼓励 PrivateUse1 机制在 PyTorch 生态系统中的更广泛采用。此文档包括:
- 使用 PrivateUse1 集成新后端的逐步指南
- 清晰解释 PrivateUse1 的功能和优势
- 高效实现的示例代码和最佳实践
这些增强功能旨在提高 PrivateUse1 机制的鲁棒性和可靠性,促进新后端的更好集成并扩展 PyTorch 的功能。
上游与下游之间的兼容性
设备通用单元测试
PyTorch 中的大多数单元测试都集中在 CPU 和 CUDA 设备上,这限制了其他硬件用户的参与。为了解决这个问题,我们计划修改 PyTorch 的单元测试框架,以更好地支持非 CUDA 设备。该计划包括移除现有的设备限制、实现动态数据类型加载以及泛化装饰器以适应更广泛的设备。此外,我们旨在强制使用通用设备代码并扩展分布式测试以支持非 NCCL 后端。
通过这些改进,我们希望显著提高非 CUDA 设备的测试覆盖率和通过率,并将它们集成到 PyTorch 的持续集成流程中。初步更改已经实施,为新硬件支持铺平了道路,并为其他设备创建了参考模板。
通过自动化测试确保健壮的设备集成
为了维护 PyTorch 高标准的质量保证,我们建立了独立的构建仓库和每日持续集成 (CI) 工作流,重点关注冒烟测试和集成测试。
pytorch-integration-tests 仓库自动化 PyTorch 设备特定功能的测试,确保它们在各种硬件平台(NPU 和其他专用设备)上正确高效地运行。在该仓库中,我们正在尝试构建一个完全自动化的系统,持续验证 PyTorch 与不同硬件后端的兼容性。
- 自动化集成测试:使用 GitHub Actions 在不同设备上运行自动化测试。这种自动化确保代码库中的每次更改都在多个硬件平台上经过彻底测试,从而在开发过程的早期捕获潜在问题。
- 可重用工作流:此仓库中的工作流是模块化且可重用的,这简化了测试过程。开发人员可以轻松地将这些工作流适应新设备或测试场景,使系统在 PyTorch 发展过程中既灵活又可扩展。
- 非核心设备的感知:该仓库显示所有非核心设备的存在和行为,使社区知情。这种方法最大限度地降低了意外破坏下游功能的风险,并提供了对更改的快速反馈。
增强多设备集成的努力对于其在不断发展的深度学习领域中的适应性至关重要。这些举措不仅有利于现有用户,还降低了新硬件供应商和开发人员的进入门槛,促进了 AI 和机器学习领域的创新。随着 PyTorch 的不断发展,其对灵活性、健壮性和包容性的承诺使其成为一个能够满足深度学习社区多样化需求的领先框架。