在本博客文章中,我们描述了第一篇经过同行评审的研究论文,该论文探讨了加速 PyTorch DDP(torch.nn.parallel.DistributedDataParallel)[1] 和流水线(torch.distributed.pipeline)混合训练的方法——PipeTransformer:用于大型模型分布式训练的自动化弹性流水线(如 BERT [2] 和 ViT [3] 等 Transformer),发表于 ICML 2021。
PipeTransformer 利用自动化弹性流水线来高效地进行 Transformer 模型的分布式训练。在 PipeTransformer 中,我们设计了一种自适应的实时冻结算法,该算法可以在训练过程中逐步识别并冻结某些层,以及一个弹性流水线系统,该系统可以动态分配资源来训练剩余的活动层。更具体地说,PipeTransformer 自动将冻结的层从流水线中排除,将活动层打包到更少的 GPU 中,并分叉更多的副本以增加数据并行宽度。我们使用 Vision Transformer (ViT) 在 ImageNet 上以及 BERT 在 SQuAD 和 GLUE 数据集上评估了 PipeTransformer。我们的结果表明,与最先进的基线相比,PipeTransformer 在不损失准确性的情况下实现了高达 2.83 倍的加速。我们还提供了各种性能分析,以更全面地理解我们的算法和系统设计。
接下来,我们将介绍背景、动机、我们的想法、设计以及我们如何使用 PyTorch Distributed API 实现算法和系统。
- 论文:http://proceedings.mlr.press/v139/he21a.html
- 源代码:https://DistML.ai。
- 幻灯片:https://docs.google.com/presentation/d/1t6HWL33KIQo2as0nSHeBpXYtTBcy0nXCoLiKd0EashY/edit?usp=sharing
引言
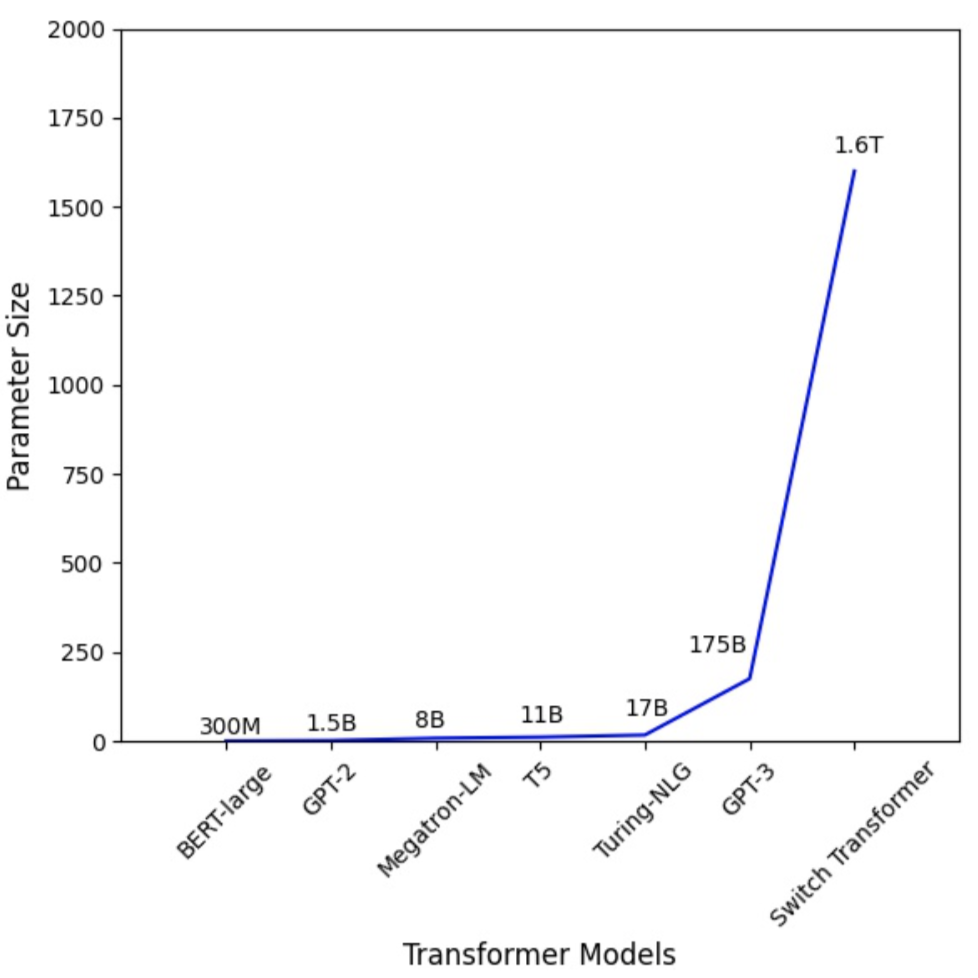
图 1:Transformer 模型参数数量急剧增加。
大型 Transformer 模型[4][5] 在自然语言处理和计算机视觉领域都推动了准确性的突破。GPT-3 [4] 在几乎所有 NLP 任务中都创下了新的最高准确率记录。Vision Transformer (ViT) [3] 也在 ImageNet 上实现了 89% 的 top-1 准确率,超越了最先进的卷积网络 ResNet-152 和 EfficientNet。为了应对模型规模的增长,研究人员提出了各种分布式训练技术,包括参数服务器[6][7][8]、流水线并行[9][10][11][12]、层内并行[13][14][15] 和零冗余数据并行[16]。
然而,现有的分布式训练解决方案仅研究在整个训练过程中都需要优化所有模型权重的情况(即,计算和通信开销在不同迭代中保持相对静态)。最近关于渐进式训练的工作表明,神经网络中的参数可以动态训练。
- 冻结训练:用于深度学习动力学和可解释性的奇异向量典型相关分析。NeurIPS 2017
- 通过渐进式堆叠高效训练 BERT。ICML 2019
- 通过渐进式层丢弃加速基于 Transformer 的语言模型的训练。NeurIPS 2020。
- 关于渐进式 BERT 训练的 Transformer 增长。NACCL 2021
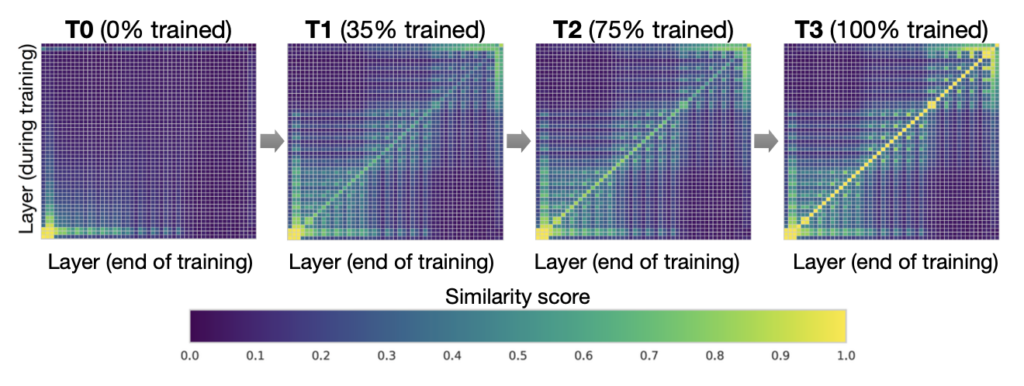
图 2. 可解释的冻结训练:DNNs 自下而上收敛(CIFAR10 上使用 ResNet 的结果)。每个窗格显示使用 SVCCA [17][18] 的逐层相似性。
例如,在冻结训练 [17][18] 中,神经网络通常自下而上收敛(即,并非所有层都需要在整个训练过程中进行训练)。图 2 展示了在此方法中权重在训练过程中如何逐渐稳定下来的一个示例。这一观察结果促使我们利用冻结训练进行 Transformer 模型的分布式训练,通过动态分配资源以专注于一组不断缩小的活动层来加速训练。这种层冻结策略对流水线并行尤为重要,因为将连续的底层从流水线中排除可以减少计算、内存和通信开销。
图 3. PipeTransformer 自动化弹性流水线加速 Transformer 模型分布式训练的过程。
我们提出了 PipeTransformer,一个弹性流水线训练加速框架,它通过动态转换流水线模型的范围和流水线副本的数量来自动响应冻结层。据我们所知,这是第一篇研究在流水线和数据并行训练背景下层冻结的论文。图 3 展示了这种组合的优势。首先,通过将冻结层从流水线中排除,相同的模型可以被打包到更少的 GPU 中,从而减少跨 GPU 通信和更小的流水线气泡。其次,在将模型打包到更少的 GPU 中后,相同的集群可以容纳更多的流水线副本,增加了数据并行的宽度。更重要的是,从这两个优势中获得的加速是乘法而不是加法,进一步加速了训练。
PipeTransformer 的设计面临四个主要挑战。首先,冻结算法必须做出实时的自适应冻结决策;然而,现有工作[17][18]仅提供事后分析工具。其次,流水线重新分区结果的效率受多种因素影响,包括分区粒度、跨分区激活大小以及迷你批次中的分块(微批次数量),这需要在大型解决方案空间中进行推理和搜索。第三,为了动态引入额外的流水线副本,PipeTransformer 必须克服集体通信的静态特性,并避免在引入新进程时(一个流水线由一个进程处理)可能出现的复杂跨进程消息协议。最后,缓存可以节省冻结层重复前向传播的时间,但它必须在现有流水线和新添加的流水线之间共享,因为系统无法为每个副本创建和预热专用缓存。
图 4:展示 PipeTransformer 动态的动画
正如动画(图 4)所示,PipeTransformer 设计了四个核心构建块来解决上述挑战。首先,我们设计了一个可调的自适应算法来生成信号,指导不同迭代中冻结层的选择(冻结算法)。一旦这些信号被触发,我们的弹性流水线模块(AutoPipe)就会将剩余的活动层打包到更少的 GPU 中,同时考虑到激活大小和异构分区(冻结层和活动层)之间工作负载的差异。然后,它根据对不同流水线长度的先验分析结果,将一个迷你批次分成最佳数量的微批次。我们的下一个模块 AutoDP 会生成额外的流水线副本以占用空闲的 GPU,并维护分层通信进程组以实现集体通信的动态成员资格。我们的最后一个模块 AutoCache 有效地在现有和新的数据并行进程之间共享激活,并在转换期间自动替换过时的缓存。
总的来说,PipeTransformer 结合了冻结算法、AutoPipe、AutoDP 和 AutoCache 模块,提供了显著的训练加速。我们使用 Vision Transformer (ViT) 在 ImageNet 上以及 BERT 在 GLUE 和 SQuAD 数据集上评估了 PipeTransformer。我们的结果表明,PipeTransformer 在不损失准确性的情况下实现了高达 2.83 倍的加速。我们还提供了各种性能分析,以更全面地理解我们的算法和系统设计。最后,我们还为 PipeTransformer 开发了开源灵活的 API,它在冻结算法、模型定义和训练加速之间提供了清晰的分离,允许将其转移到需要类似冻结策略的其他算法中。
整体设计
假设我们旨在分布式训练系统中训练一个大型模型,其中使用流水线模型并行和数据并行的混合来针对单个 GPU 设备内存无法容纳模型,或者如果加载后批次大小足够小以避免内存不足的情况。更具体地说,我们定义我们的设置如下:
训练任务和模型定义。我们训练 Transformer 模型(例如 Vision Transformer、BERT)在大型图像或文本数据集上。Transformer 模型 mathcal{F} 有 L 层,其中第 i 层由一个前向计算函数 f_i 和一组相应的参数组成。
训练基础设施。假设训练基础设施包含一个 GPU 集群,该集群有 N 台 GPU 服务器(即节点)。每个节点有 I 个 GPU。我们的集群是同构的,这意味着每个 GPU 和服务器都具有相同的硬件配置。每个 GPU 的内存容量为 M_\text{GPU}。服务器通过 InfiniBand 互连等高带宽网络接口连接。
流水线并行。在每台机器中,我们将模型 \mathcal{F} 加载到一个流水线 \mathcal{P} 中,该流水线有 K 个分区(K 也表示流水线长度)。第 kth 个分区 p_k 由连续的层组成。我们假设每个分区由单个 GPU 设备处理。1 \leq K \leq I,这意味着我们可以在一台机器中为多个模型副本构建多个流水线。我们假设流水线中的所有 GPU 设备都属于同一台机器。我们的流水线是同步流水线,不涉及陈旧梯度,微批次的数量为 M。在 Linux 操作系统中,每个流水线由一个进程处理。更多细节请读者参考 GPipe [10]。
数据并行。 DDP 是 R 个并行工作节点内跨机器的分布式数据并行进程组。每个工作节点是一个流水线副本(一个单独的进程)。第 r 个工作节点的索引 (ID) 是 rank r。对于 DDP 中的任意两个流水线,它们可以属于同一个 GPU 服务器或不同的 GPU 服务器,并且它们可以通过 AllReduce 算法交换梯度。
在这些设置下,我们的目标是通过利用冻结训练来加速训练,这不需要在整个训练过程中训练所有层。此外,它可以通过连续冻结层来帮助节省计算、通信和内存成本,并可能防止过拟合。然而,这些好处只能通过克服设计自适应冻结算法、动态流水线重新分区、高效资源重新分配和跨进程缓存的四个挑战来实现,正如引言中讨论的那样。
图 5. PipeTransformer 训练系统概述
PipeTransformer 协同设计了一种实时冻结算法和一个自动化弹性流水线训练系统,该系统可以动态地转换流水线模型的范围和流水线副本的数量。整体系统架构如图 5 所示。为了支持 PipeTransformer 的弹性流水线,我们维护了一个自定义版本的 PyTorch Pipeline。对于数据并行,我们使用 PyTorch DDP 作为基线。其他库是操作系统的标准机制(例如,多进程),因此避免了特殊的软件或硬件定制要求。为了确保我们框架的通用性,我们将训练系统解耦为四个核心组件:冻结算法、AutoPipe、AutoDP 和 AutoCache。冻结算法(灰色)从训练循环中采样指标并做出逐层冻结决策,这将与 AutoPipe(绿色)共享。AutoPipe 是一个弹性流水线模块,通过将冻结层从流水线中排除并将活动层打包到更少的 GPU 中(粉色)来加速训练,从而减少跨 GPU 通信和更小的流水线气泡。随后,AutoPipe 将流水线长度信息传递给 AutoDP(紫色),AutoDP 然后生成更多的流水线副本以增加数据并行宽度(如果可能)。插图还包括一个示例,其中 AutoDP 引入了一个新副本(紫色)。AutoCache(橙色边框)是一个跨流水线缓存模块,如图中流水线之间的连接所示。源代码架构与图 5 对齐,以提高可读性和通用性。
使用 PyTorch API 实现
从图 5 可以看出,PipeTransformers 包含四个组件:冻结算法、AutoPipe、AutoDP 和 AutoCache。其中,AutoPipe 和 AutoDP 分别依赖于 PyTorch DDP(torch.nn.parallel.DistributedDataParallel)[1] 和流水线(torch.distributed.pipeline)。在本博客中,我们只重点介绍 AutoPipe 和 AutoDP 的关键实现细节。有关冻结算法和 AutoCache 的详细信息,请参阅我们的论文。
AutoPipe:弹性流水线
AutoPipe 可以通过将冻结层从流水线中排除并将活动层打包到更少的 GPU 中来加速训练。本节详细阐述了 AutoPipe 的关键组件,这些组件动态地 1) 对流水线进行分区,2) 最小化流水线设备的数量,以及 3) 相应地优化迷你批处理块大小。
PyTorch 流水线的基本用法
在深入 AutoPipe 的细节之前,让我们先了解一下 PyTorch Pipeline (torch.distributed.pipeline.sync.Pipe) 的基本用法(请参阅此教程)。更具体地说,我们提供一个简单的示例来理解 Pipeline 在实践中的设计。
# Step 1: build a model including two linear layers
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
# Step 2: wrap the two layers with nn.Sequential
model = nn.Sequential(fc1, fc2)
# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
model = Pipe(model, chunks=8)
# do training/inference
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)
在这个基本示例中,我们可以看到,在初始化 Pipe 之前,我们需要将模型 nn.Sequential 分区到多个 GPU 设备,并设置最佳的块数 (chunks)。平衡分区之间的计算时间对于流水线训练速度至关重要,因为阶段之间倾斜的工作负载分布可能导致落后者,并迫使工作负载较轻的设备等待。块数也可能对流水线的吞吐量产生不可忽视的影响。
平衡流水线分区
在像 PipeTransformer 这样的动态训练系统中,保持参数数量的最佳平衡分区并不能保证最快的训练速度,因为其他因素也起着关键作用。
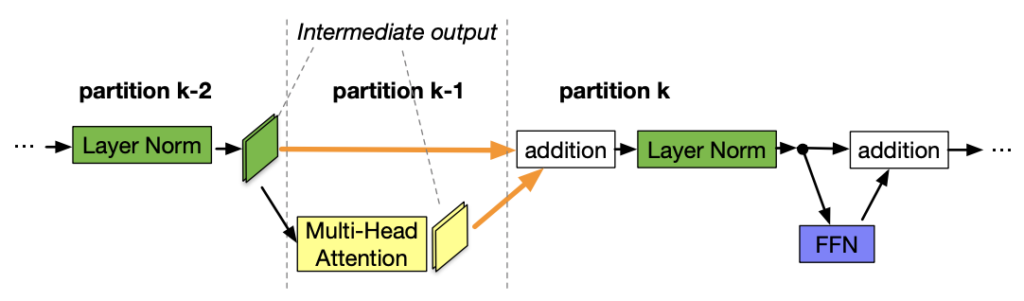
图 6. 分区边界位于跳过连接的中间。
- 跨分区通信开销。将分区边界放置在跳过连接的中间会导致额外的通信,因为跳过连接中的张量现在必须复制到不同的 GPU。例如,在图 6 中的 BERT 分区中,分区 k 必须从分区 k-2 和分区 k-1 获取中间输出。相比之下,如果边界放置在加法层之后,分区 k-1 和 k 之间的通信开销明显更小。我们的测量表明,跨设备通信比轻微不平衡的分区更昂贵(参见我们论文的附录)。因此,我们不考虑破坏跳过连接(在算法 1 的第 7 行中单独突出显示为整个注意力层和 MLP 层,用绿色表示)。
- 冻结层内存占用。在训练期间,AutoPipe 必须多次重新计算分区边界,以平衡两种不同类型的层:冻结层和活动层。鉴于冻结层不需要反向激活图、优化器状态和梯度,其内存成本仅为活动层的一小部分。AutoPipe 不会启动侵入式分析器来获取全面的内存和计算成本指标,而是定义了一个可调的成本因子 lambda_{\text{frozen}} 来估计冻结层相对于相同活动层的内存占用率。根据我们在实验硬件中的经验测量,我们将其设置为 \frac{1}{6}。

基于上述两点考虑,AutoPipe 根据参数大小平衡流水线分区。更具体地说,AutoPipe 使用贪婪算法将所有冻结层和活动层分配到 K 个 GPU 设备中,以均匀分布分区子层。伪代码在算法 1 中的 load\_balance() 函数中描述。冻结层从原始模型中提取,并保存在流水线的第一个设备中的单独模型实例 \mathcal{F}_{\text{frozen}} 中。
请注意,本文采用的分区算法并非唯一选择;PipeTransformer 模块化设计使其可与任何替代方案协同工作。
流水线压缩
流水线压缩有助于释放 GPU 以容纳更多流水线副本并减少分区之间的跨设备通信次数。为了确定压缩的时机,我们可以估计压缩后最大分区的内存成本,然后将其与时间 T=0 时流水线最大分区的内存成本进行比较。为了避免大量的内存分析,压缩算法使用参数大小作为训练内存占用的替代指标。基于此简化,流水线压缩的准则如下:

一旦收到冻结通知,AutoPipe 总是会尝试将流水线长度 K 除以 2(例如,从 8 到 4,然后到 2)。通过将 \frac{K}{2} 作为输入,压缩算法可以验证结果是否满足方程 (1) 中的标准。伪代码显示在算法 1 的第 25-33 行。请注意,这种压缩使得训练期间的加速比呈指数级增长,这意味着如果 GPU 服务器具有更多的 GPU(例如,超过 8 个),加速比将进一步放大。
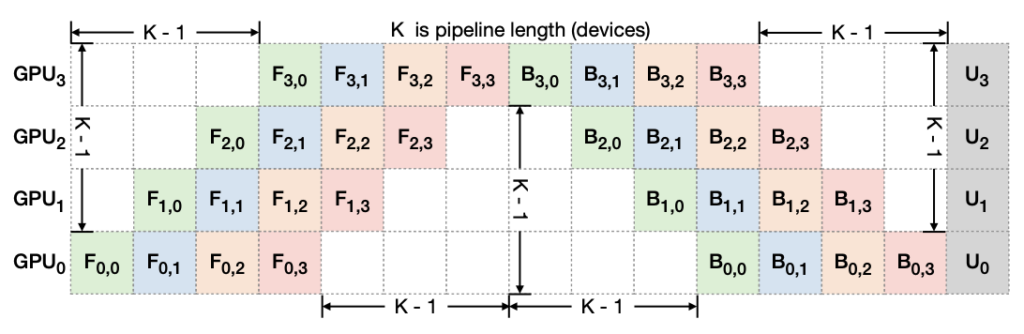
图 7. 流水线气泡:F_{d,b} 和 U_d” 分别表示微批次 b 在设备 d 上的前向、反向和优化器更新。每个迭代中的总气泡大小是 K-1 倍的每个微批次前向和反向成本。
此外,这种技术还可以通过缩小流水线气泡的大小来加速训练。为了解释流水线中的气泡大小,图 7 描绘了 4 个微批次如何通过 4 设备流水线 K = 4 运行。通常,总气泡大小是 (K-1) 乘以每个微批次前向和反向成本。因此,很明显,较短的流水线具有较小的气泡大小。
动态微批次数量
以前的流水线并行系统对每个迷你批次使用固定数量的微批次(M)。GPipe 建议 M \geq 4 \times K,其中 K 是分区数量(流水线长度)。然而,鉴于 PipeTransformer 动态配置 K,我们发现在训练期间保持静态 M 是次优的。此外,当与 DDP 集成时,M 的值也会影响 DDP 梯度同步的效率。由于 DDP 必须等待最后一个微批次完成其参数的反向计算才能启动其梯度同步,因此更细粒度的微批次会导致计算和通信之间的重叠更小。因此,PipeTransformer 不使用静态值,而是在 DDP 环境的混合中通过枚举从 K 到 6K 的 M 值来实时搜索最佳 M。对于特定的训练环境,分析只需要进行一次(参见算法 1 第 35 行)。
有关完整的源代码,请参阅 https://github.com/Distributed-AI/PipeTransformer/blob/master/pipe_transformer/pipe/auto_pipe.py。
AutoDP:生成更多流水线副本
随着 AutoPipe 将相同的流水线压缩到更少的 GPU 中,AutoDP 可以自动生成新的流水线副本以增加数据并行宽度。
尽管概念简单,但对通信和状态的微妙依赖需要仔细设计。挑战有三个方面:
- DDP 通信:PyTorch DDP 中的集体通信需要静态成员资格,这会阻止新流水线与现有流水线连接;
- 状态同步:新激活的进程必须与现有流水线在训练进度(例如,epoch 编号和学习率)、权重和优化器状态、冻结层边界以及流水线 GPU 范围方面保持一致;
- 数据集重新分配:数据集应重新平衡以匹配动态数量的流水线。这不仅避免了落后者,而且还确保了所有 DDP 进程的梯度权重相等。
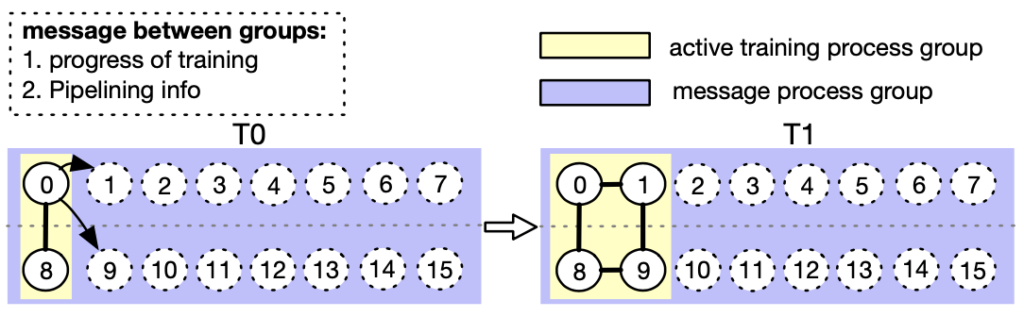
图 8. AutoDP:通过双进程组之间的消息传递处理动态数据并行(进程 0-7 属于机器 0,而进程 8-15 属于机器 1)。
为了应对这些挑战,我们为 DDP 创建了双重通信进程组。如图 8 所示,消息进程组(紫色)负责轻量级控制消息并覆盖所有进程,而活跃训练进程组(黄色)仅包含活跃进程,并在训练期间充当重量级张量通信的载体。消息组保持静态,而训练组被拆除并重建以匹配活跃进程。在 T0 时,只有进程 0 和 8 处于活跃状态。在向 T1 过渡期间,进程 0 激活进程 1 和 9(新添加的流水线副本),并使用消息组同步上述必要信息。然后,四个活跃进程形成一个新的训练组,允许静态集体通信适应动态成员资格。为了重新分配数据集,我们实现了一个 DistributedSampler 的变体,可以无缝调整数据样本以匹配活跃流水线副本的数量。
上述设计也有助于自然地减少 DDP 通信开销。更具体地说,当从 T0 过渡到 T1 时,进程 0 和 1 销毁现有的 DDP 实例,活跃进程使用缓存的流水线模型构建一个新的 DDP 训练组(AutoPipe 分别存储冻结模型和缓存模型)。
我们使用以下 API 来实现上述设计。
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# initialize the process group (this must be called in the initialization of PyTorch DDP)
dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
...
# create active process group (yellow color)
self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
...
# create message process group (yellow color)
self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
...
# create DDP-enabled model when the number of data-parallel workers is changed. Note:
# 1. The process group to be used for distributed data all-reduction.
If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
In our case, we set it as self.active_process_group
# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
self.pipe_len = gpu_num_per_process
if gpu_num_per_process > 1:
model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
else:
model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
# to broadcast message among processes, we use dist.broadcast_object_list
def dist_broadcast(object_list, src, group):
"""Broadcasts a given object to all parties."""
dist.broadcast_object_list(object_list, src, group=group)
return object_list
有关完整的源代码,请参阅 https://github.com/Distributed-AI/PipeTransformer/blob/master/pipe_transformer/dp/auto_dp.py。
实验
本节首先总结实验设置,然后使用计算机视觉和自然语言处理任务评估 PipeTransformer。
硬件。实验在两台通过 InfiniBand CX353A(5GB/s)连接的相同机器上进行,每台机器都配备 8 块 NVIDIA Quadro RTX 5000(16GB GPU 内存)。机器内 GPU 到 GPU 的带宽(PCI 3.0,16 通道)为 15.754GB/s。
实现。我们使用 PyTorch Pipe 作为构建块。BERT 模型定义、配置和相关分词器来自 HuggingFace 3.5.0。我们通过遵循 Vision Transformer 的 TensorFlow 实现,使用 PyTorch 实现了 Vision Transformer。更多详细信息可以在我们的源代码中找到。
模型和数据集。实验采用 CV 和 NLP 中的两个代表性 Transformer:Vision Transformer (ViT) 和 BERT。ViT 运行图像分类任务,使用 ImageNet21K 上的预训练权重进行初始化,并在 ImageNet 和 CIFAR-100 上进行微调。BERT 运行两个任务:来自通用语言理解评估 (GLUE) 基准的 SST-2 数据集上的文本分类,以及 SQuAD v1.1 数据集(斯坦福问题回答),这是一个包含 10 万个众包问答对的集合。
训练方案。鉴于大型模型通常需要数千 GPU 天(例如 GPT-3)才能从头开始训练,因此使用预训练模型微调下游任务已成为 CV 和 NLP 社区的一种趋势。此外,PipeTransformer 是一个复杂的训练系统,涉及多个核心组件。因此,对于 PipeTransformer 系统开发和算法研究的第一个版本,从头开始使用大规模预训练进行开发和评估并不划算。因此,本节中介绍的实验侧重于预训练模型。请注意,由于预训练和微调中的模型架构相同,PipeTransformer 可以同时服务于两者。我们在附录中讨论了预训练结果。
基线。本节中的实验将 PipeTransformer 与最先进的框架(PyTorch Pipeline(PyTorch 对 GPipe 的实现)和 PyTorch DDP 的混合方案)进行了比较。由于这是第一篇研究通过冻结层加速分布式训练的论文,因此尚未有完全对齐的对应解决方案。
超参数。实验对 ImageNet 和 CIFAR-100 使用 ViT-B/16(12 个 Transformer 层,16 \times 16 输入块大小),对 SQuAD 1.1 使用 BERT-large-uncased(24 层),对 SST-2 使用 BERT-base-uncased(12 层)。使用 PipeTransformer,ViT 和 BERT 训练的每个流水线批次大小分别可以设置为大约 400 和 64。所有实验的其他超参数(例如,epoch、学习率)在附录中介绍。
整体训练加速
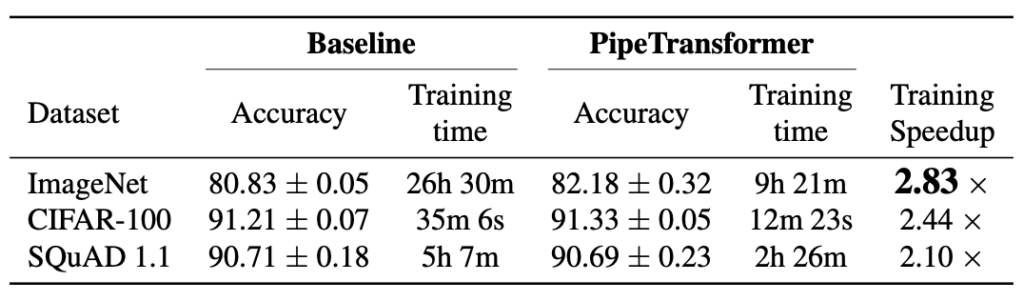
我们总结了上表中的总体实验结果。请注意,我们报告的加速是基于保守的 \alpha \frac{1}{3} 值,该值可以获得可比或甚至更高的准确性。更激进的 \alpha (\frac{2}{5}, \frac{1}{2})可以获得更高的加速,但可能会导致准确性略有下降。请注意,BERT(24 层)的模型大小大于 ViT-B/16(12 层),因此通信需要更多时间。
性能分析
加速分解
本节介绍了评估结果,并分析了 \autopipe 中不同组件的性能。更多实验结果可以在附录中找到。
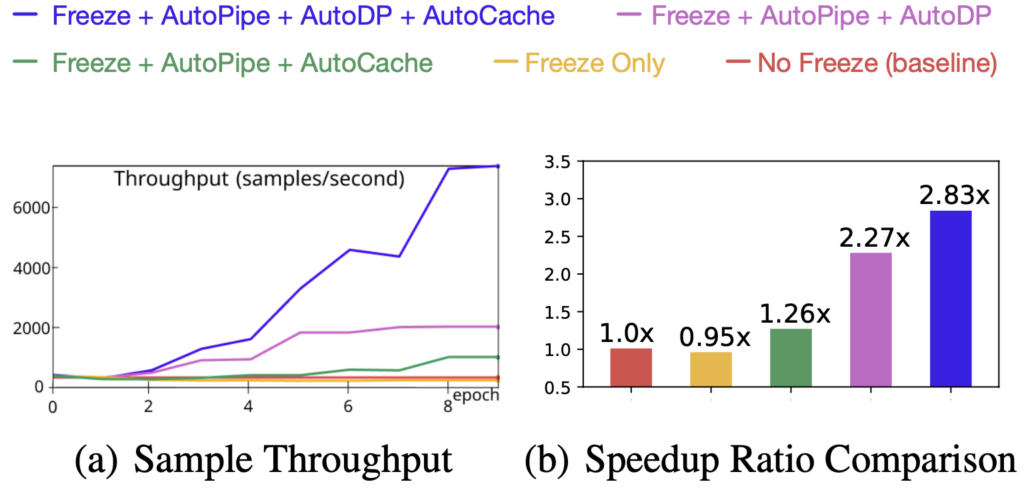
图 9. 加速分解(ViT 在 ImageNet 上)
为了理解所有四个组件的功效及其对训练速度的影响,我们尝试了不同的组合,并使用它们的训练样本吞吐量(样本/秒)和加速比作为指标。结果如图 9 所示。这些实验结果的关键要点是:
- 主要加速是弹性流水线的结果,这通过 AutoPipe 和 AutoDP 的联合使用实现;
- AutoCache 的贡献通过 AutoDP 得到放大;
- 仅冻结训练而没有系统范围的调整甚至会降低训练速度。
冻结算法中的 \alpha 调优
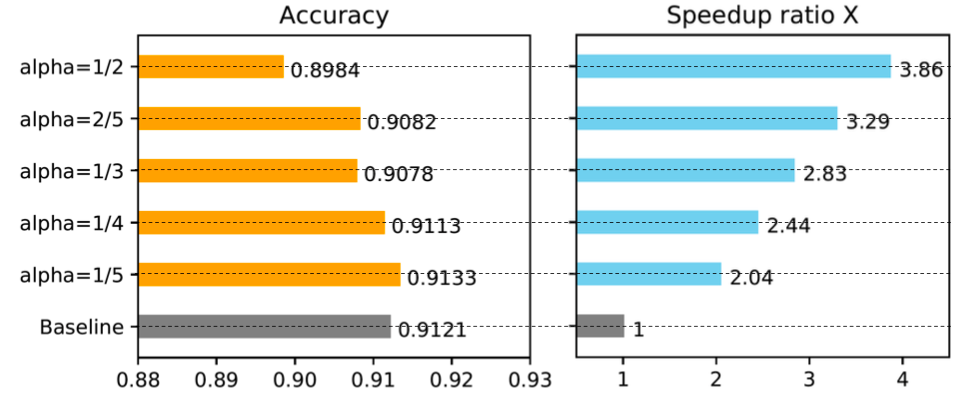
图 10. 冻结算法中的 \alpha 调优
我们进行了实验来展示冻结算法中的 \alpha 如何影响训练速度。结果清楚地表明,更大的 \alpha(过度冻结)会导致更大的加速,但性能会略有下降。在图 10 所示的情况下,当 \alpha=1/5 时,冻结训练优于正常训练,并获得了 2.04 倍的加速。我们在附录中提供了更多结果。
弹性流水线中的最佳分块数
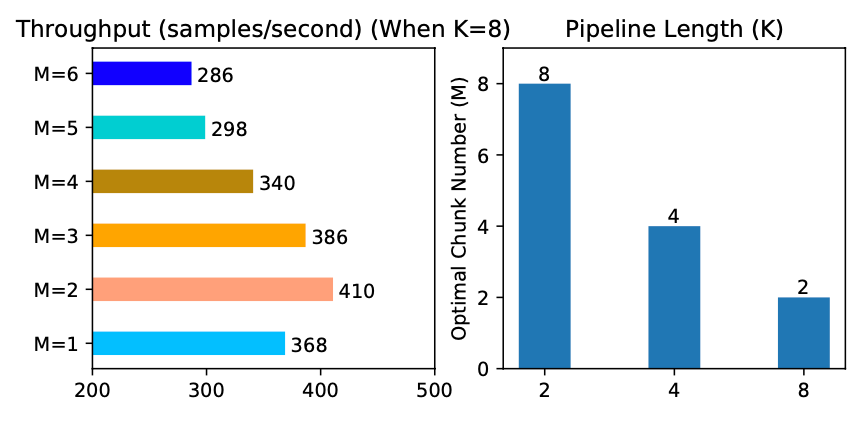
图 11. 弹性流水线中的最佳分块数
我们分析了不同流水线长度 K 下的最佳微批次数量 M。结果总结在图 11 中。正如我们所看到的,不同的 K 值导致不同的最佳 M,并且不同 M 值之间的吞吐量差距很大(如 K=8 时所示),这证实了弹性流水线中前置分析器的必要性。
理解缓存的时机
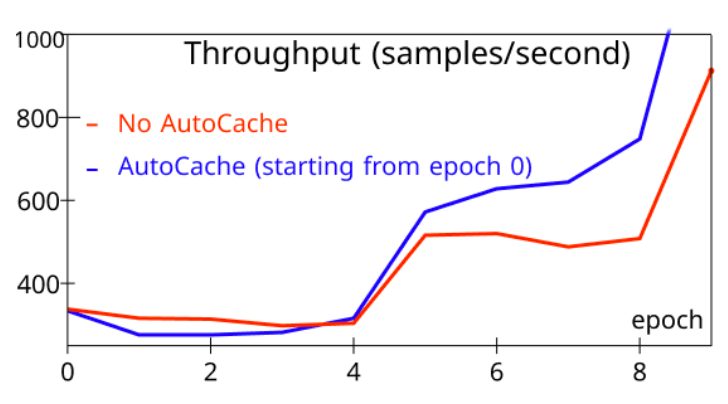
图 12. 缓存的时机
为了评估 AutoCache,我们将从 epoch 0 开始激活 AutoCache(蓝色)的训练样本吞吐量与没有 AutoCache(红色)的训练任务进行了比较。图 12 显示,过早启用缓存会减慢训练速度,因为缓存可能比少量冻结层的前向传播更昂贵。在更多层被冻结后,缓存激活显然优于相应的前向传播。因此,AutoCache 使用分析器来确定启用缓存的合适时机。在我们的系统中,对于 ViT(12 层),缓存从 3 个冻结层开始,而对于 BERT(24 层),缓存从 5 个冻结层开始。
有关更详细的实验分析,请参阅我们的论文。
总结
本博客介绍了 PipeTransformer,它是一个结合了弹性流水线并行和数据并行,利用 PyTorch 分布式 API 进行分布式训练的整体解决方案。更具体地说,PipeTransformer 逐步冻结流水线中的层,将剩余的活动层打包到更少的 GPU 中,并分叉更多流水线副本以增加数据并行宽度。对 ViT 和 BERT 模型的评估表明,与最先进的基线相比,PipeTransformer 在不损失准确性的情况下实现了高达 2.83 倍的加速。
参考文献
[1] Li, S., Zhao, Y., Varma, R., Salpekar, O., Noordhuis, P., Li,T., Paszke, A., Smith, J., Vaughan, B., Damania, P., et al. Pytorch Distributed: Accelerating Dataparallel Training 的经验。Proceedings of the VLDB Endowment,13(12), 2020
[2] Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. BERT: 用于语言理解的深度双向 Transformer 预训练。In NAACL-HLT, 2019
[3] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. 一张图片价值 16x16 个词:用于大规模图像识别的 Transformer。
[4] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. 语言模型是少样本学习器。
[5] Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., and Chen, Z. Gshard: 使用条件计算和自动分片扩展巨型模型。
[6] Li, M., Andersen, D. G., Park, J. W., Smola, A. J., Ahmed, A., Josifovski, V., Long, J., Shekita, E. J., and Su, B. Y. 使用参数服务器扩展分布式机器学习。在第 11 届 {USENIX} 操作系统设计与实现研讨会 ({OSDI} 14) 上,第 583–598 页,2014。
[7] Jiang, Y., Zhu, Y., Lan, C., Yi, B., Cui, Y., and Guo, C. 用于加速异构 GPU/CPU 集群中分布式 DNN 训练的统一架构。在第 14 届 USENIX 操作系统设计与实现研讨会 (OSDI 20) 上,第 463–479 页。USENIX Association,2020 年 11 月。ISBN 978-1-939133-19-9。
[8] Kim, S., Yu, G. I., Park, H., Cho, S., Jeong, E., Ha, H., Lee, S., Jeong, J. S., and Chun, B. G. Parallax: 深度神经网络的稀疏性感知数据并行训练。在第十四届 EuroSys 会议论文集 2019 上,第 1–15 页,2019。
[9] Kim, C., Lee, H., Jeong, M., Baek, W., Yoon, B., Kim, I., Lim, S., and Kim, S. TorchGPipe: 用于训练巨型模型的实时流水线并行。
[10] Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, M. X., Chen, D., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., et al. Gpipe: 使用流水线并行高效训练巨型神经网络。
[11] Park, J. H., Yun, G., Yi, C. M., Nguyen, N. T., Lee, S., Choi, J., Noh, S. H., and ri Choi, Y. Hetpipe: 通过集成流水线模型并行和数据并行,在(弱)异构 GPU 集群上实现大型 DNN 训练。在 2020 USENIX 年度技术大会 (USENIX ATC 20) 上,第 307–321 页。USENIX Association,2020 年 7 月。ISBN 978-1-939133-14-4。
[12] Narayanan, D., Harlap, A., Phanishayee, A., Seshadri, V., Devanur, N. R., Ganger, G. R., Gibbons, P. B., and Zaharia, M. Pipedream: 用于 DNN 训练的广义流水线并行。在第 27 届 ACM 操作系统原理研讨会 (SOSP ’19) 论文集上,第 1–15 页,纽约,纽约州,美国,2019。计算机械协会。ISBN 9781450368735。doi: 10.1145/3341301.3359646。
[13] Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., and Chen, Z. Gshard: 使用条件计算和自动分片扩展巨型模型。
[14] Shazeer, N., Cheng, Y., Parmar, N., Tran, D., Vaswani, A., Koanantakool, P., Hawkins, P., Lee, H., Hong, M., Young, C., Sepassi, R., and Hechtman, B. Mesh-Tensorflow: 用于超级计算机的深度学习。在 Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), 神经信息处理系统进展,第 31 卷,第 10414–10423 页。Curran Associates, Inc.,2018。
[15] Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-LM: 使用模型并行训练数十亿参数语言模型。
[16] Rajbhandari, S., Rasley, J., Ruwase, O., and He, Y. ZERO: 万亿参数模型训练的内存优化。
[17] Raghu, M., Gilmer, J., Yosinski, J., and Sohl Dickstein, J. Svcca: 用于深度学习动力学和可解释性的奇异向量典型相关分析。在 NIPS, 2017。
[18] Morcos, A., Raghu, M., and Bengio, S. 关于具有典型相关性的神经网络中表示相似性的见解。在 Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), 神经信息处理系统进展 31,第 5732–5741 页。Curran Associates, Inc.,2018。