LinkedIn: Shivam Sahni, Byron Hsu, Yanning Chen
Meta: Ankith Gunapal, Evan Smothers
本博客探讨了自定义 Triton 内核 Liger Kernel 与 torch.compile 的集成,以提升 torchtune 微调大型语言模型(LLM)的性能。torchtune 是一个 PyTorch 原生库,提供模块化构建块和可定制的微调方案,其中包括对各种 LLM 的 torch.compile 支持,而 Liger Kernel 则提供优化的 Triton 内核,以提高训练效率并减少内存使用。此次集成涉及修改 torchtune 中的 TransformerDecoder 模块,以绕过线性层计算,允许 Liger Fused Linear Cross Entropy Loss 处理前向投影权重。在 NVIDIA A100 实例上进行的实验表明,torch.compile 在吞吐量和内存效率方面优于 PyTorch Eager,Liger Kernel 进一步降低了峰值内存分配并支持更大的批量大小。结果显示,在使用 meta-llama/Llama-3.2-1B 时,批量大小为 256 时峰值内存减少了 47%,吞吐量略有增加,证实了该集成的有效性且不影响损失曲线。
torchtune 简介
torchtune 是一个 PyTorch 原生库,专为微调 LLM 而设计。torchtune 提供可组合的模块化构建块以及可根据您的用例轻松定制的微调方案,本博客将对此进行展示。
torchtune 提供:
- Llama、Gemma、Mistral、Phi 和 Qwen 模型家族中流行 LLM 模型架构的 PyTorch 实现
- 用于全微调、LoRA、QLoRA、DPO、PPO、QAT、知识蒸馏等的可修改训练方案
- 开箱即用的内存效率、性能改进以及通过最新的 PyTorch API(包括
torch.compile)进行扩展 - 用于轻松配置训练、评估、量化或推理方案的 YAML 配置
- 对许多流行数据集格式和提示模板的内置支持
Liger Kernel 简介
Liger Kernel 是一个优化的 Triton 内核开源库,旨在提高训练大型语言模型 (LLM) 的效率和可扩展性。它专注于内核级优化,例如操作融合和输入分块,与 HuggingFace 等现有实现相比,在训练吞吐量和 GPU 内存使用方面取得了显著改进。通过使用一行代码,Liger Kernel 可以将 训练吞吐量提高 20%,内存使用量减少 60%。
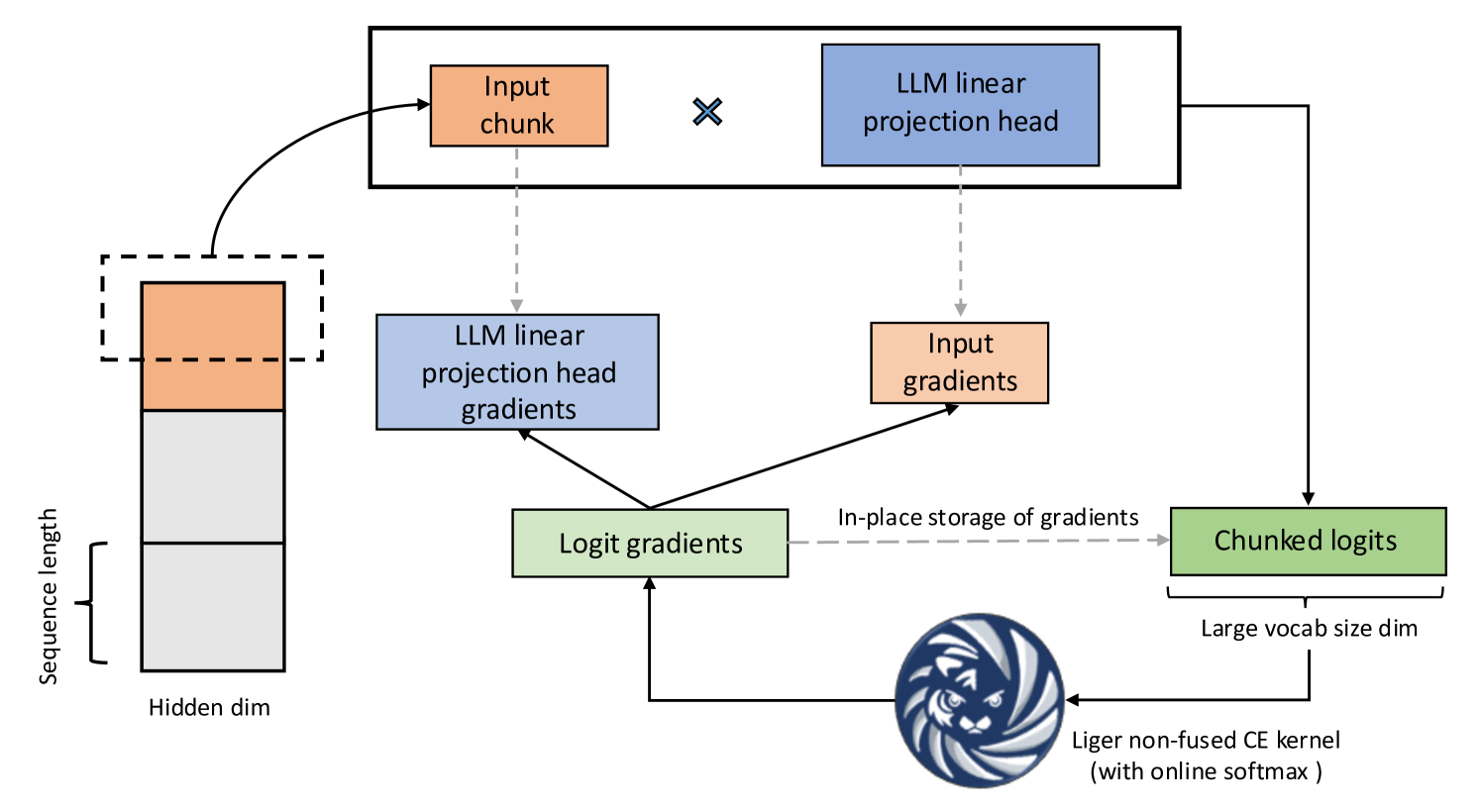
图 1:融合线性交叉熵
Liger Kernel 性能提升的主要来源是融合线性交叉熵(FLCE)损失,其核心思想如下:
在 LLM 中,词汇量显著增加,导致交叉熵(CE)损失计算期间的 logits 张量过大。这个 logits 张量消耗过多的内存,导致训练瓶颈。例如,当以批量大小为 8、序列长度为 4096 进行训练时,256k 的词汇量会产生 16.8 GB 的 logits 张量。FLCE 内核将计算分解成更小的块,从而减少内存消耗。
它的工作原理如下:
- 通过折叠批量大小和序列长度维度,将 3D 隐藏状态展平为 2D 矩阵。
- 在分块的隐藏状态上按顺序应用线性投影头。
- 使用 Liger CE 内核计算部分损失并返回分块的 logits 梯度。
- 导出分块的隐藏状态梯度并累积投影头梯度。
torchtune 的方案开箱即用地支持 torch.compile。已经证明,结合 torch.compile 使用 FLCE 可以使 FLCE 提速 2 倍。
Liger Kernel 与 torch.compile 和 torchtune 的集成
我们通过运行 meta-llama/Llama-3.2-1B 的完整微调方案来演示 Liger Kernel 与 torch.compile 和 torchtune 的集成。为了实现这一集成,我们定义了一个自定义的完整微调方案,具体更改如下所述。
CUDA_VISIBLE_DEVICES=0,1,2,3 tune run --nproc_per_node 4 recipes/full_finetune_distributed.py --config llama3_2/1B_full optimizer=torch.optim.AdamW optimizer.fused=True optimizer_in_bwd=False gradient_accumulation_steps=1 dataset.packed=True compile=True enable_activation_checkpointing=True tokenizer.max_seq_len=512 batch_size=128
LCE 内核的一个输入是前向投影权重。torchtune 被设计为一个具有可组合块的模块化库。在 TransformerDecoder 块 的末尾,我们通过一个线性层来处理最终隐藏状态以获得最终输出。由于线性层与 LCE 内核中的 CE 损失结合在一起,我们为 TransformerDecoder 编写了一个自定义的 forward 函数,其中我们跳过了通过线性层的计算。
在完整的微调方案中,我们用这个自定义方法覆盖模型的 forward 方法。
import types
from liger_kernel.torchtune.modules.transformers import decoder_forward
self._model.forward = types.MethodType(decoder_forward, self._model)
然后,我们传递模型的前向投影权重,以便使用 LCE 内核计算损失。
from liger_kernel.transformers.fused_linear_cross_entropy import (
LigerFusedLinearCrossEntropyLoss,
)
# Use LCE loss instead of CE loss
self._loss_fn = LigerFusedLinearCrossEntropyLoss()
# call torch.compile on the loss function
if self._compile:
training.compile_loss(self._loss_fn, verbose=self._is_rank_zero)
# pass the model's forward projection weights for loss computation
current_loss = (
self._loss_fn(
self._model.output.tied_module.weight,
logits,
labels,
)
* current_num_tokens
)
完整的代码和说明可以在 GitHub 仓库中找到。
实验与基准测试结果
我们进行了 3 种类型的实验,以展示 Liger Kernel 与 torch.compile 的集成如何提升 torchtune 的性能。我们将实验设置在运行 NVIDIA A100 的实例上。我们使用不同的批量大小微调一个小型 LLM meta-llama/Llama-3.2-1B。我们记录了以 tokens/秒为单位的吞吐量,并测量了微调期间分配的峰值内存。由于它是一个小型模型,我们只使用了 4 个 A100 GPU 进行基准测试。以下是我们进行的实验:
- 使用 PyTorch Eager 将批量大小按 2 的幂次增加。
- 使用 torch.compile 将批量大小按 2 的幂次增加。
- 使用 torch.compile 和 Liger 集成将批量大小按 2 的幂次增加。
我们注意到,使用 PyTorch Eager 时,吞吐量随着批量大小的增加而增加,直到批量大小为 256 时达到 OOM。使用 torch.compile 时,每个批量大小的吞吐量都高于 PyTorch Eager。我们看到,随着批量大小的增加,峰值内存分配急剧减少,在批量大小为 128 时,峰值内存减少了 50% 以上。这使得 torch.compile 能够支持批量大小为 256,因此,torch.compile 的总吞吐量比 PyTorch Eager 高 36%。将 Liger Kernel 与 torch.compile 集成并不会降低较低批量大小的吞吐量,但随着批量大小的增加,我们注意到 torchtune 比 torch.compile 消耗更少的内存。在批量大小为 256 时,我们看到 Liger 内核使峰值内存分配减少了 47%。这使我们能够使用 torch.compile 和 Liger 实现批量大小为 512。我们注意到,与没有自定义 Triton 内核的 torch.compile 相比,吞吐量略微增加了 1-2%。
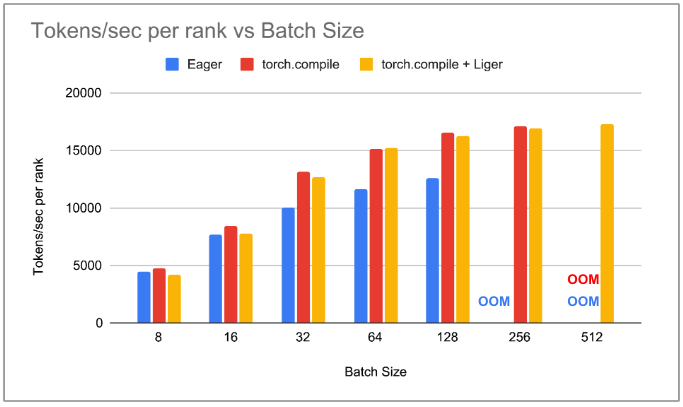
图 2:每个等级的 tokens/秒与批量大小的关系图

图 3:峰值内存分配与批量大小的关系图
为了排除 Liger Kernel 与 torchtune 集成可能存在的任何功能问题,我们绘制了有无 Liger 的损失曲线与训练步数的关系图。我们看到损失曲线没有明显的差异。
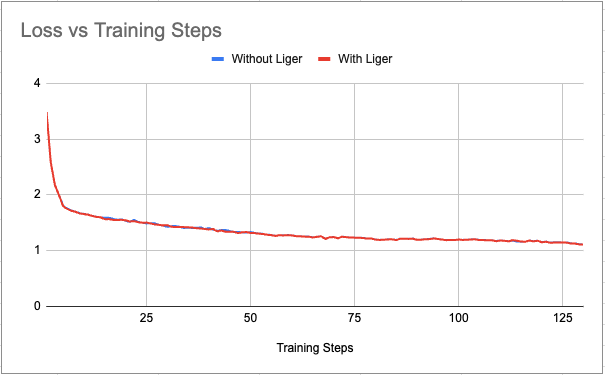
图 4:批量大小 = 128 时损失与训练步数的关系图
下一步
鸣谢
我们感谢 Hamid Shojanazeri (Meta)、Less Wright (Meta)、Horace He (Meta) 和 Gregory Chanan (Meta) 对这篇博客文章的反馈和支持。