大型语言模型领域正转向低精度计算。这种转变要求我们重新思考缩放法则,以考虑量化对量化模型性能的影响。在这项工作中,我们证明了通过更好的量化方案设计和训练改进,可以显著提高先前关于低比特缩放法则的结论的准确性。
我们提出了 ParetoQ,这是第一个统一了二值、三值和2到4比特量化感知训练的算法。ParetoQ 在所有比特宽度下都产生了最先进(SOTA)的模型,超越了先前针对单个比特级别量身定制的工作,从而展示了其稳健性。我们已在 Hugging Face 上发布了MobileLLM 低比特模型集合,其中包含使用我们 ParetoQ 方法量化的模型。最小的模型是一个超高效的1比特125M变体,等效存储大小仅约16MB。
Pareto 图中的这些 SOTA 点确保了我们的缩放法则比较既可靠又一致,因为它们都来自同质设置。我们的缩放法则揭示了二值量化会显著损害准确性,而三值、2比特和3比特量化在性能上不相上下,通常优于4比特。
ParetoQ 基于 PyTorch 模型,包括 LLaMA 和 MobileLLM。我们利用了流行的 PyTorch 库:HuggingFace Transformers 进行准确性实验。对于延迟实验,我们在 CPU 上使用 ExecuTorch 利用了低比特量化核。我们将它们的速度与4比特量化的速度进行了比较。此外,我们实现了最先进的2比特 GPU 核,与 FP16 相比,在 TritonBench 上显示出高达4.14倍的加速,与 Machete 4比特核相比,加速了1.24倍。
ParetoQ 已集成到 torchao [pull] 中。此集成允许用户通过在 torchao 的代码库中将“paretoq”指定为量化方法来利用 ParetoQ。设置后,用户可以使用 torchao 的 ParetoQ 工作流,优化量化参数以平衡准确性和压缩的权衡,并使用 Pareto 前沿分析对不同量化比特进行公平比较。这允许在边缘设备上高效部署模型,而无需手动调整量化设置。
要获取 ParetoQ 量化模型,只需导航到 torchao/prototype/paretoq 目录并执行训练脚本
cd torchao/prototype/paretoq && bash 1_run_train.sh $w_bit
在这里,$w_bit 指定了量化的目标权重位宽。
ParetoQ 代码可在以下网址获取:https://github.com/facebookresearch/ParetoQ
论文链接:https://arxiv.org/abs/2502.02631
1 极低比特LLM的更优QAT调度策略
1.1 训练预算分配
给定固定的训练预算 B_train = B_FPT + B_QAT,如何最佳地在全精度训练 (B_FPT) 和量化感知训练/微调 (B_QAT) 之间分配预算,以最大化量化模型的准确性?
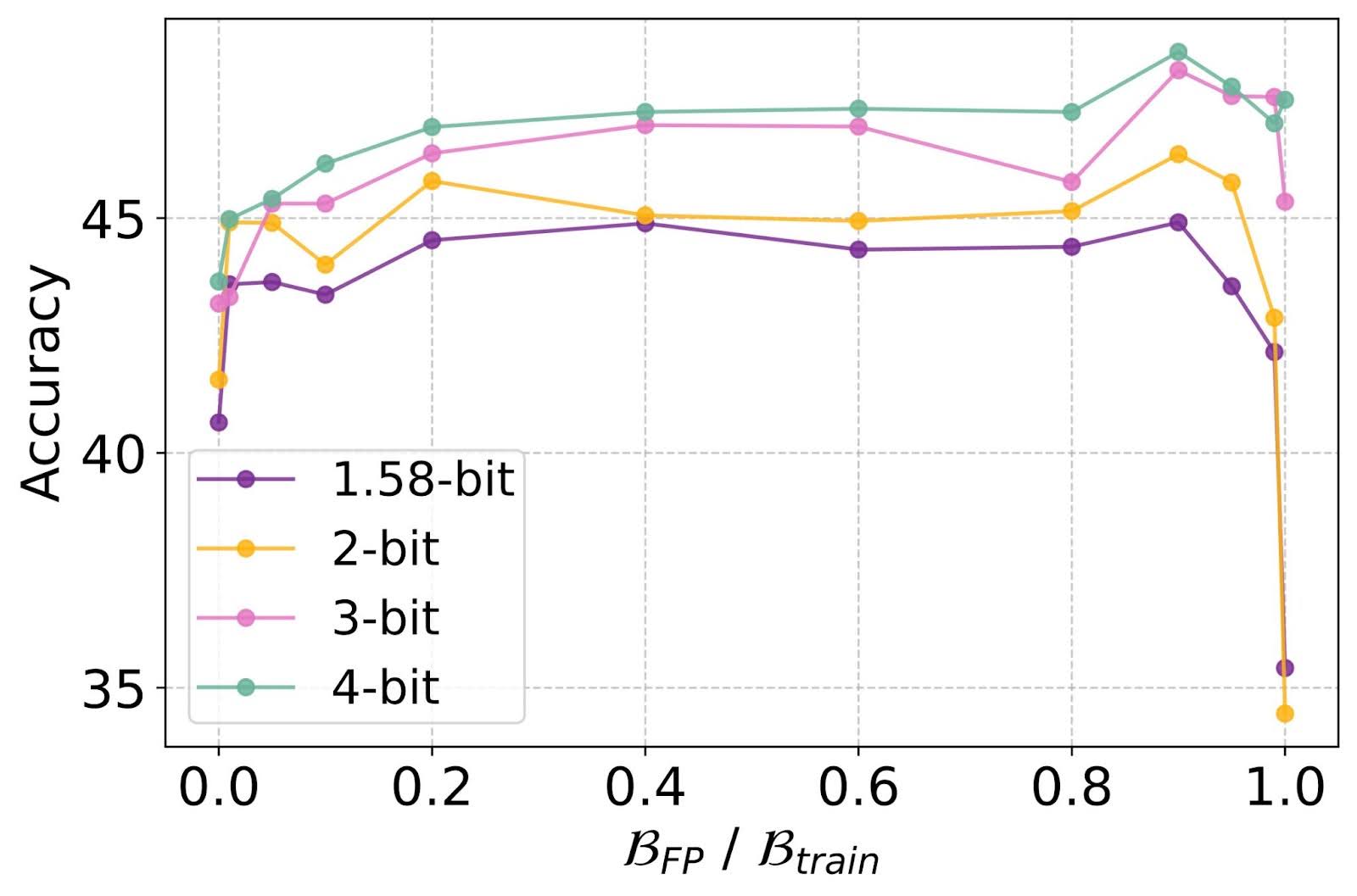
图1:全精度预训练和QAT微调之间的最佳分配。
发现-1 QAT 微调始终优于 B_FPT = B_train 的 PTQ 和 B_QAT = B_train 的从头开始的 QAT。通过将大部分训练预算用于全精度 (FP) 训练,并大约 10% 用于 QAT,几乎可以实现最佳性能。
1.2 微调特性
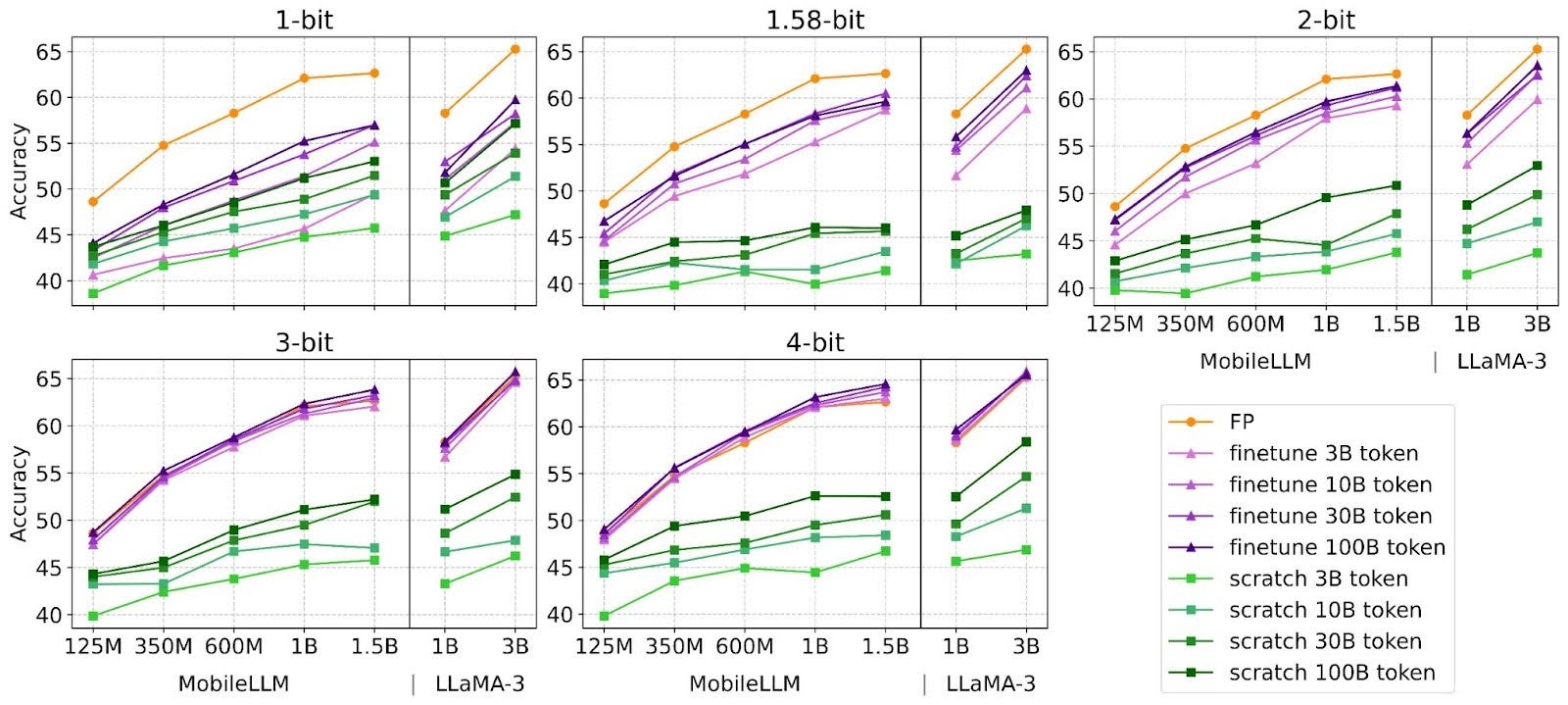
图2:量化感知微调和从头开始训练所需的训练令牌分析
发现-2 尽管微调可以提升所有比特宽度(包括二值和三值)的性能,但最佳微调工作量与比特宽度呈反比关系。对于3比特和4比特权重,微调会在附近的网格内进行调整以减轻精度损失,并且所需的微调令牌更少。相比之下,二值和三值权重会打破网格,创建新的语义表示以保持性能,因此需要更长的微调。
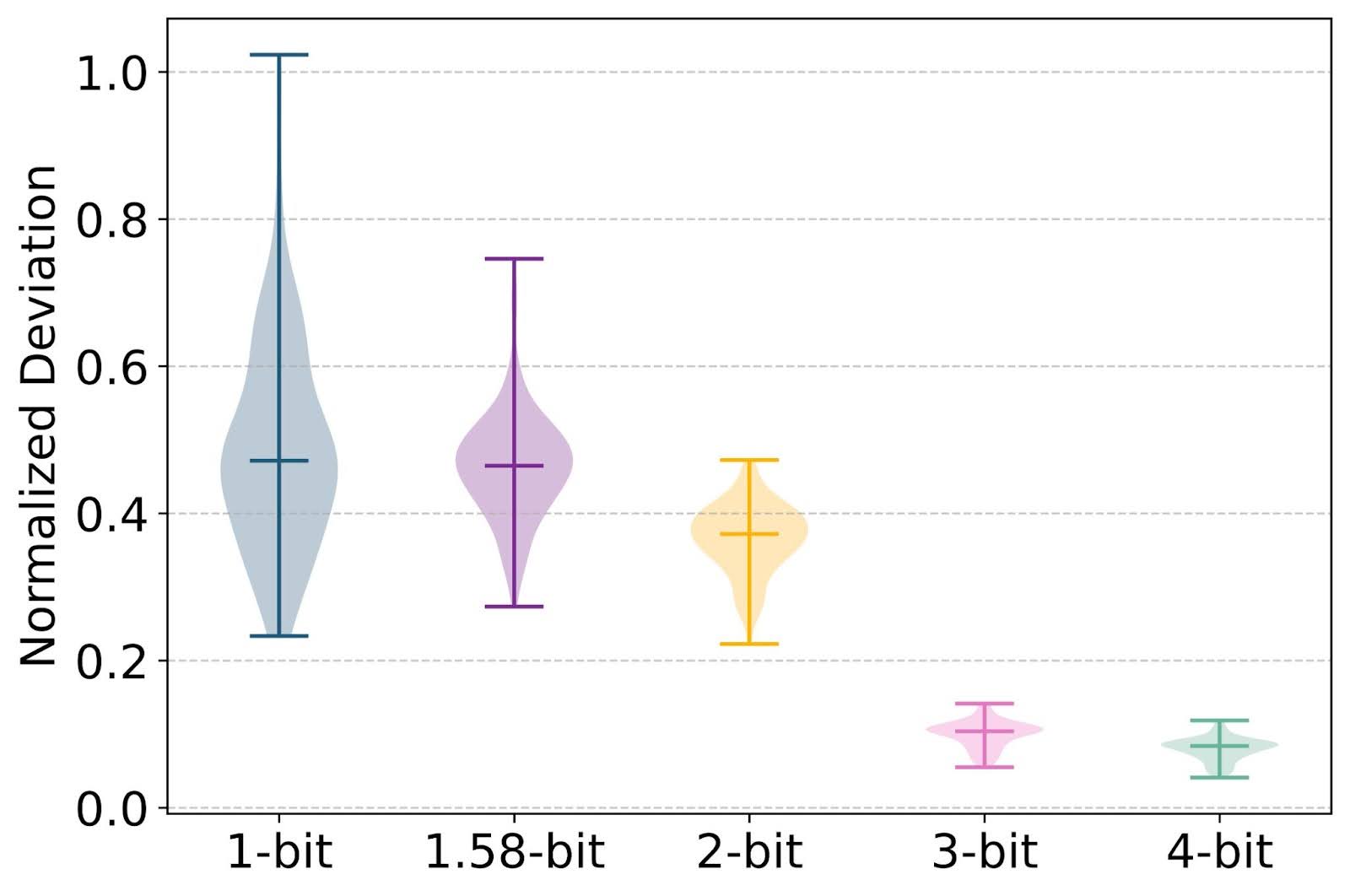
图3:QAT微调权重与全精度初始化之间的L1范数差异 (||W_finetune −W_init||_l1 /||W_init||_l1)。
2 量化方法选择的搭便车指南
在低于4比特的量化中,函数选择高度敏感,会显著改变缩放法则结果。
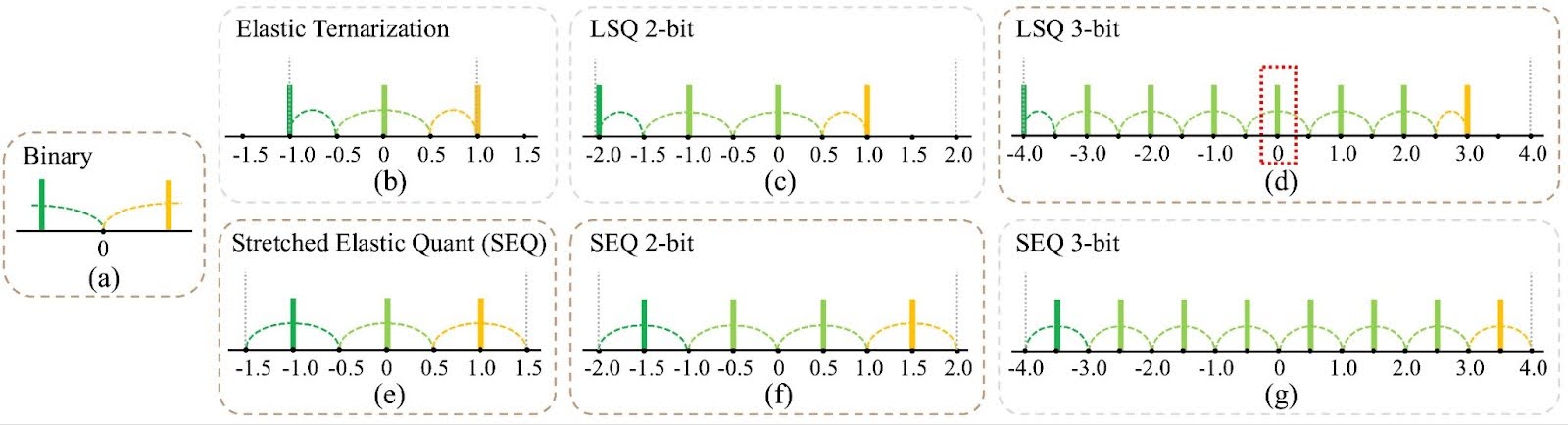
图4:量化网格选择在不同比特宽度下的影响。2.1.1 范围裁剪与基于统计的量化(例如,min-max 量化)相比,可学习的尺度作为网络参数优化量化范围,平衡异常值抑制和精度,可产生更稳定和卓越的性能。如图 (b)-(e) 所示,可学习策略在所有比特宽度下始终优于基于统计的方法。
2.1.2 量化网格
量化网格中的级别对称性对于低比特量化至关重要,但往往被忽视。在偶数级别量化(例如,2比特、3比特、4比特)中包含“0”可能会导致不平衡。例如,2比特量化选项如 (-2, -1, 0, 1) 将正表示限制在一个级别,而 (-1.5, -0.5, 0.5, 1.5) 提供更平衡的表示。我们提出了拉伸弹性量化 (SEQ) 来解决低比特场景中的这个问题。
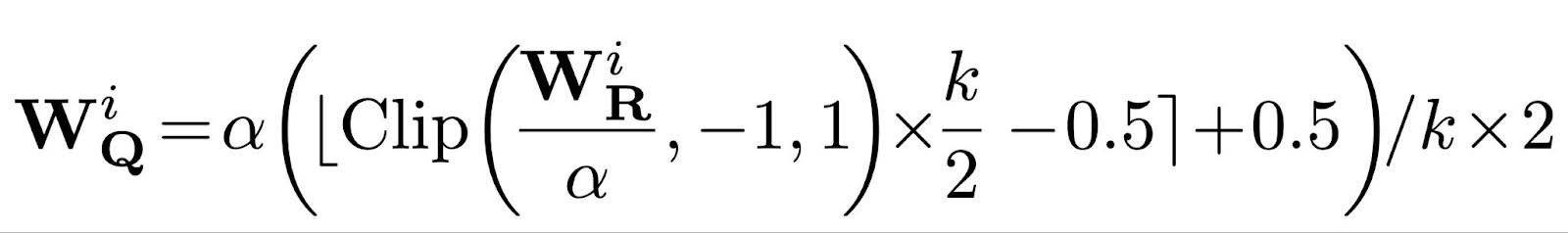
SEQ平衡量化级别,并均匀划分全精度权重范围,这对于极低比特量化至关重要。图表显示了SEQ在三值和2比特量化中的优势,而带有“0”的LSQ在3比特和4比特情况下略有优势。

图5:不同比特宽度下的量化方法比较
2.2 量化函数
根据我们的分析,我们将为每个比特宽度确定的最佳量化函数组合成一个公式,命名为 ParetoQ。这包括用于1比特量化的弹性二值化[1]、用于3比特和4比特量化的LSQ[2],以及用于1.58比特和2比特量化的建议SEQ。
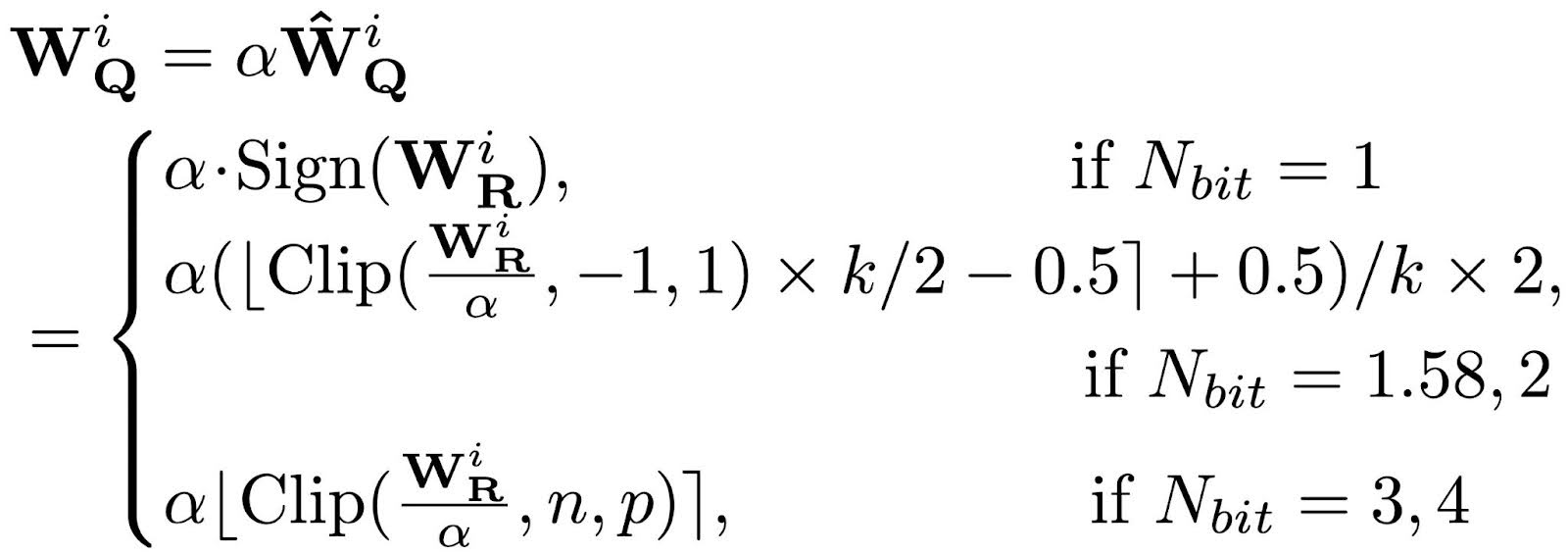
这里,在三值情况下 k 等于 3,否则为 2Nbit;n = –2Nbit-1,p = 2Nbit-1 -1。在反向传播中,可以使用直通估计器轻松计算权重和缩放因子的梯度。
通过ParetoQ,我们提出了一个稳健的比较框架,涵盖了五种比特宽度(1比特、1.58比特、2比特、3比特、4比特),每种都达到了最先进的准确性。这有助于直接、公平的比较,以确定最有效的比特宽度选择。
3 与SoTA的比较
3.1 1.58比特量化比较
下图显示,ParetoQ始终优于先前针对三值量化感知训练的方法,包括 Spectra [3] 和 1-bit Era [4]。鉴于全精度 LLaMA-3 3B 模型达到 69.9 的准确率,值得注意的是,ParetoQ 三值 3B 参数模型将差距缩小到仅 4.1 分,而先前的方法下降超过 11.7 分。
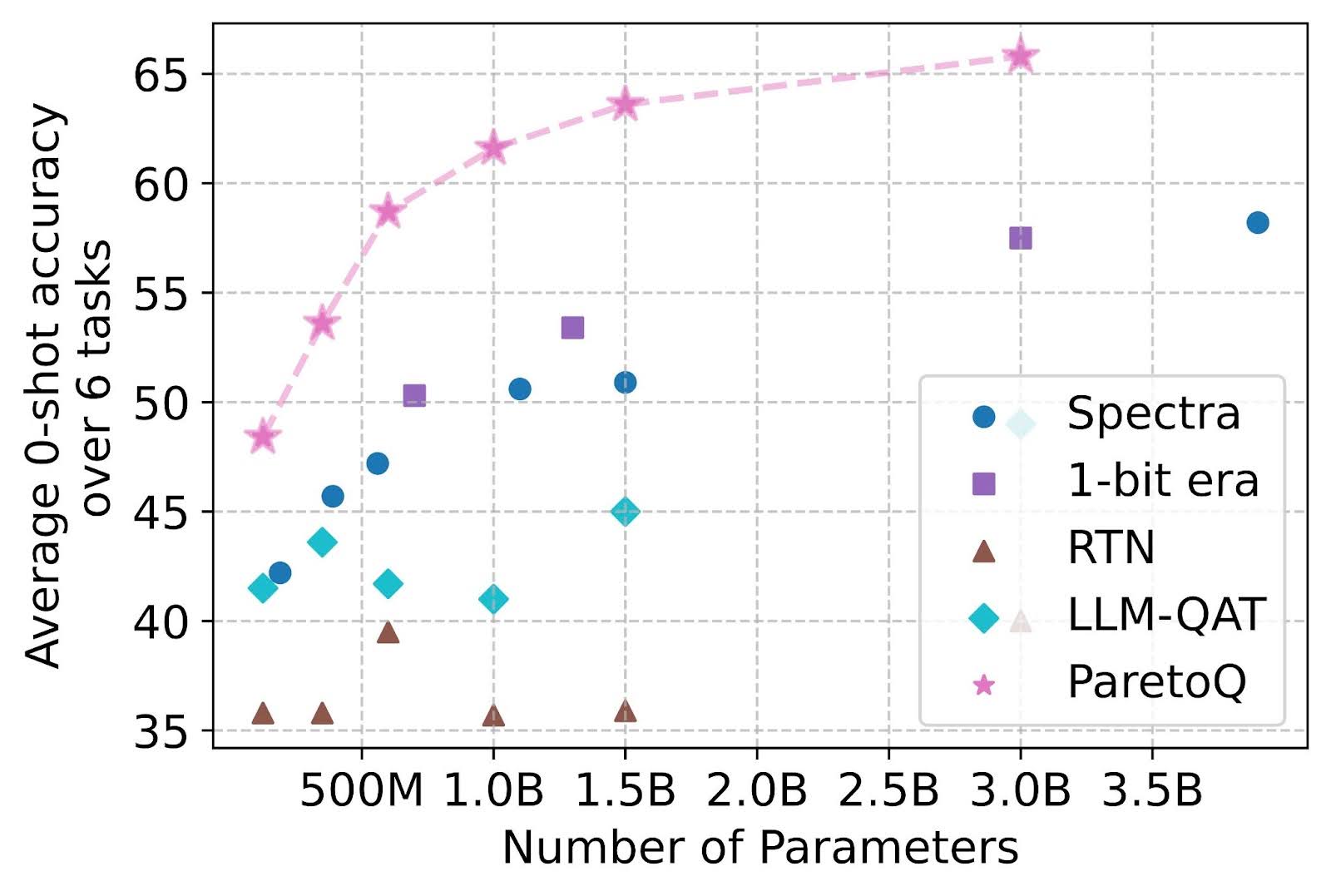
图6:在六项任务(ARC-e、ARC-c、BoolQ、PIQA、HellaSwag 和 WinoGrande)上平均的三值量化准确性。ParetoQ 在三值量化感知训练中始终优于所有先前方法。
3.2 2比特/3比特/4比特量化比较
如图1所示,与之前2、3或4比特量化设置上的最先进PTQ和QAT方法相比,我们的方法始终位于帕累托前沿,在低比特量化设置中具有特别显著的优势。这些结果证实,我们的比特-准确性权衡结论是基于所有比特设置下的SoTA结果进行基准测试的,从而确保了其可靠性。

图7:8个模型的准确性比较。ParetoQ 在2、3和4比特设置中优于所有最先进的PTQ和QAT方法。
4 帕累托曲线
在许多场景中,4比特量化感知训练 (QAT) 实现了接近无损的压缩。通过 ParetoQ,我们能够进一步改善权衡曲线。图 (a) 表明,包括二值、三值、2比特和3比特在内的亚4比特量化通常优于4比特。值得注意的是,2比特和三值模型位于帕累托前沿。
为了评估除了内存缩减之外的潜在加速效益,我们利用高性能低比特操作符进行2比特量化,并与4比特量化进行延迟比较。图8 (c) 中的曲线表明,在我们的实验范围内,2比特量化模型在准确性-速度性能方面始终优于4比特模型,这使得2比特量化成为对延迟和存储都至关重要的设备上应用的卓越选择。
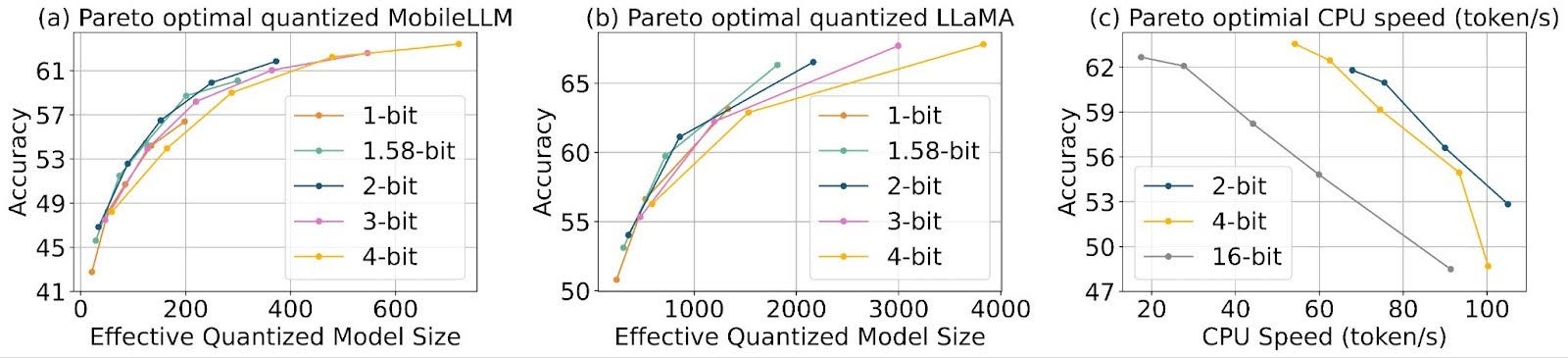
图8:(a) (b) 在亚4比特体系中,1.58比特、2比特和3比特量化在准确性-模型大小权衡方面优于4比特。(c) 在硬件限制下,2比特量化比高比特方案展现出更优越的准确性-速度权衡。
5 GPU延迟
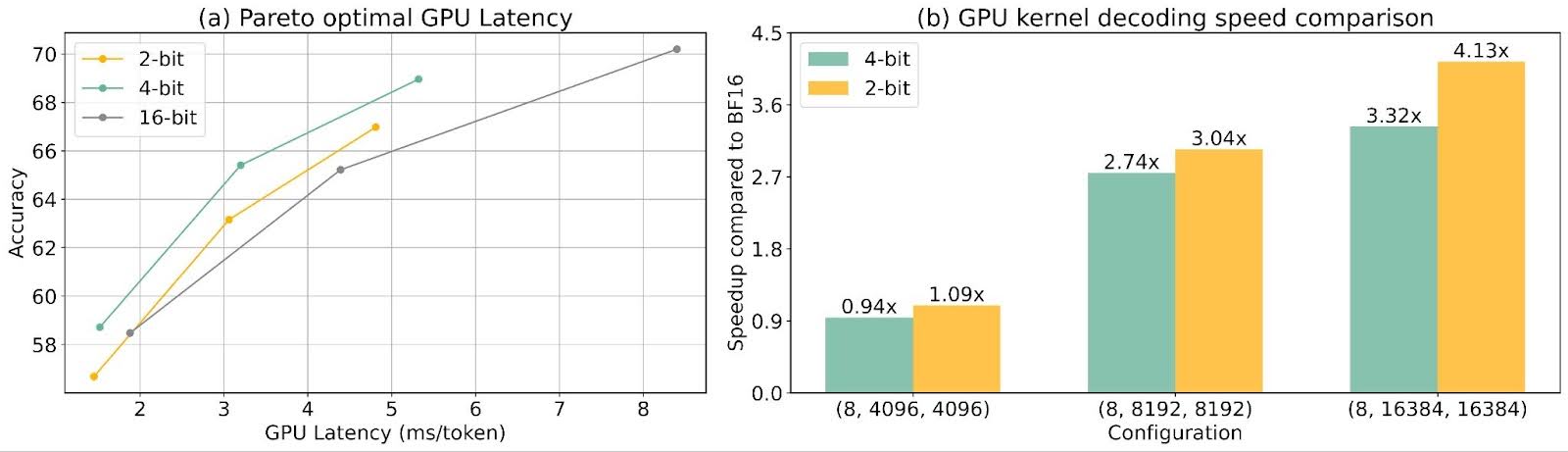
我们测量了 LLaMA 3.2 模型(1B、3B、8B)在 H100 NVL GPU(94GB 内存)上的延迟。W4A16 核使用了 vLLM 的Machete 核,而W2A16 核是基于 CUTLASS 混合精度骨干核实现的。所有测试均在单个 GPU 上进行,上下文长度为 2048 令牌。对于核级延迟,我们比较了 2 比特核与 4 比特 Machete 核在 TritonBench 上的三种权重形状:(4096 x 4096)、(8192 x 8192)和(16384 x 16384)。对于更大尺寸的核,2 比特核可以比 4 比特 Machete 核实现约 24% 的加速。
结论
在这项研究中,我们提出了 ParetoQ,一个先进的量化框架,它在所有比特宽度级别上都达到了最先进的性能。该框架独特地实现了不同比特宽度之间的直接、一致比较,确保了性能指标的公平评估。我们的实证分析表明,与4比特相比,1.58比特、2比特和3比特的量化在准确性和有效量化模型大小之间提供了更优的权衡,突出了它们在优化模型部署方面的潜力。
欢迎尝试从torchao/prototype/paretoq运行ParetoQ,按照该仓库中的步骤操作。如果您有任何疑问,请随时联系 Zechun Liu <zechunliu@meta.com>,Changsheng Zhao <cszhao@meta.com> Andrew Or <andrewor@meta.com>。
参考文献
[1] BiT: 稳健二值化多蒸馏 Transformer。
[2] 学习步长量化。
[3] Spectra: 三值、量化和FP16语言模型的综合研究。
[4] 1比特LLM的时代:所有大型语言模型都是1.58比特。