1. 引言
PyTorch 支持两种执行模式 [1]:即时模式(eager mode)和图模式(graph mode)。在即时模式下,模型中的操作符在遇到时会立即执行。相比之下,在图模式下,操作符首先会被合成为一个图,然后作为一个整体进行编译和执行。即时模式更易于使用,更适合机器学习研究人员,因此是默认的执行模式。另一方面,图模式通常提供更高的性能,因此在生产环境中被大量使用。
具体来说,图模式支持算子融合 [2],其中一个算子与另一个算子合并,以减少/局部化内存读取以及总内核启动开销。融合可以是水平的——将一个独立应用于许多操作数(例如 BatchNorm)的单个操作合并到数组中;也可以是垂直的——将一个内核与消耗第一个内核输出的另一个内核合并(例如,卷积后跟 ReLU)。
Torch.FX [3, 4] (简称 FX) 是 PyTorch 包中公开可用的工具包,支持图模式执行。它特别 (1) 从 PyTorch 程序中捕获图,并 (2) 允许开发者对捕获的图编写转换。它在 Meta 内部用于优化生产模型的训练吞吐量。通过引入 Meta 开发的一些基于 FX 的优化,我们演示了使用图转换优化 PyTorch 生产性能的方法。
2. 背景
嵌入表在推荐系统中无处不在。第 3 节将讨论三种优化嵌入表访问的 FX 转换。本节将介绍 FX(第 2.1 节)和嵌入表(第 2.2 节)的一些背景知识。
2.1 FX
图 1 是一个简单的例子,摘自 [3],它说明了如何使用 FX 转换 PyTorch 程序。它包含三个步骤:(1) 从程序中捕获图,(2) 修改图(在这个例子中,所有 RELU 的使用都被 GELU 替换),以及 (3) 从修改后的图生成新程序。

图 1:一个 FX 示例,它将 PyTorch 模块中所有 RELU 的使用替换为 GELU。
FX API [4] 提供了更多功能,用于检查和转换 PyTorch 程序图。
2.2 嵌入表
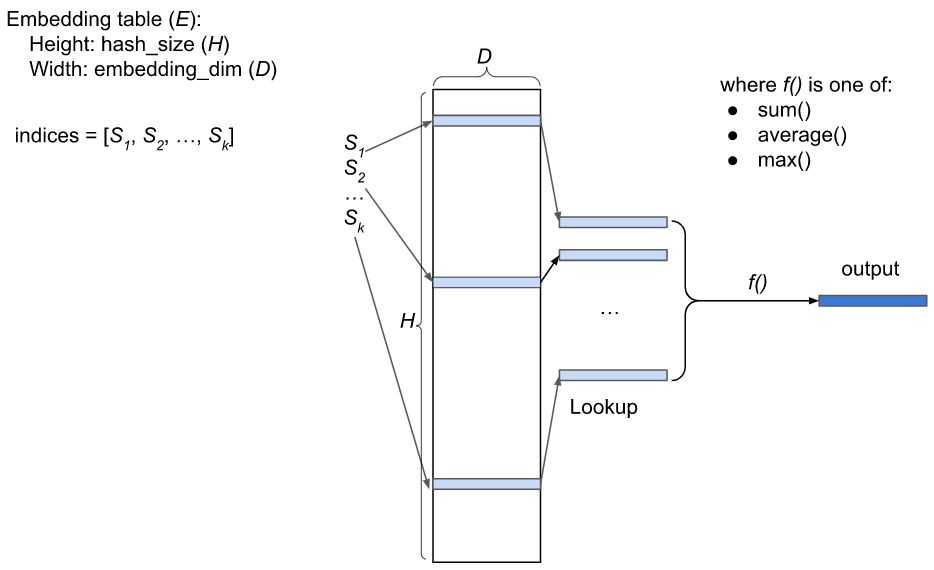
图 2:批量大小为 1 的稀疏特征嵌入表示意图
在推荐系统中,稀疏特征(例如,用户 ID,故事 ID)由嵌入表表示。嵌入表 E 是一个 HxD 矩阵,其中 H 是哈希大小,D 是嵌入维度。E 的每一行都是一个浮点向量。特征哈希 [5] 用于将稀疏特征映射到 E 的索引列表,例如 [S1, S2, …, Sk],其中 0<=Si
为了充分利用 GPU,稀疏特征通常是批量处理的。批次中的每个实体都有自己的索引列表。如果一个批次有 B 个实体,朴素的表示方式是 B 个索引列表。更紧凑的表示方式是将 B 个索引列表合并成一个单一的索引列表,并添加一个索引长度列表(批次中每个实体一个长度)。例如,如果一个批次有 3 个实体,其索引列表如下:
- 实体 1:索引 = [10, 20]
- 实体 2:索引 = [5, 9, 77, 81]
- 实体 3:索引 = [15, 20, 45]
那么整个批次的索引和长度将是
- 索引 = [10, 20, 5, 9, 77, 81, 15, 20, 45]
- 长度 = [2, 4, 3]
整个批次的嵌入表查找输出是一个 BxD 矩阵。
3. 三种 FX 转换
我们开发了三种 FX 转换,可加速对嵌入表的访问。第 3.1 节讨论了一种将多个小型输入张量组合成一个大型张量的转换;第 3.2 节讨论了一种将多个并行计算链融合为一个计算链的转换;第 3.3 节讨论了一种重叠通信与计算的转换。
3.1 组合输入稀疏特征
回想一下,批次中的输入稀疏特征由两个列表表示:一个索引列表和一个 B 个长度列表,其中 B 是批次大小。在 PyTorch 中,这两个列表实现为两个张量。当 PyTorch 模型在 GPU 上运行时,嵌入表通常存储在 GPU 内存中(它更靠近 GPU,并且具有比 CPU 内存更高的读/写带宽)。要使用输入稀疏特征,其两个张量需要首先从 CPU 复制到 GPU。然而,每次主机到设备内存复制都需要启动一个内核,这相对于实际数据传输时间来说是相对昂贵的。如果一个模型使用许多输入稀疏特征,这种复制可能会成为性能瓶颈(例如,1000 个输入稀疏特征需要从主机复制 2000 个张量到设备)。
一种减少主机到设备 memcpy 次数的优化是在将多个输入稀疏特征发送到设备之前将它们组合起来。例如,给定以下三个输入特征:
- 特征 A:索引 = [106, 211, 7],长度 = [2, 1]
- 特征 B:索引 = [52, 498, 616, 870, 1013],长度 = [3, 2]
- 特征 C:索引 = [2011, 19, 351, 790],长度 = [1, 3]
组合形式为
- 特征 A_B_C:索引 = [106, 211, 7, 52, 498, 616, 870, 1013, 2011, 19, 351, 790],长度 = [2, 1, 3, 2, 1, 3]
因此,我们只需要复制 2 个张量,而不是从主机复制 3×2=6 个张量。
图 3(b) 描述了这种优化的实现,它包含两个组件:
- 在 CPU 端:修改输入管道,将稀疏特征的所有索引合并成一个张量,类似地将所有长度合并成另一个张量。然后将这两个张量复制到 GPU。
- 在 GPU 端:使用 FX,我们在模型图中插入一个 Permute_and_Split 操作,从组合的张量中恢复单个特征的索引和长度张量,并将它们路由到相应的下游节点。
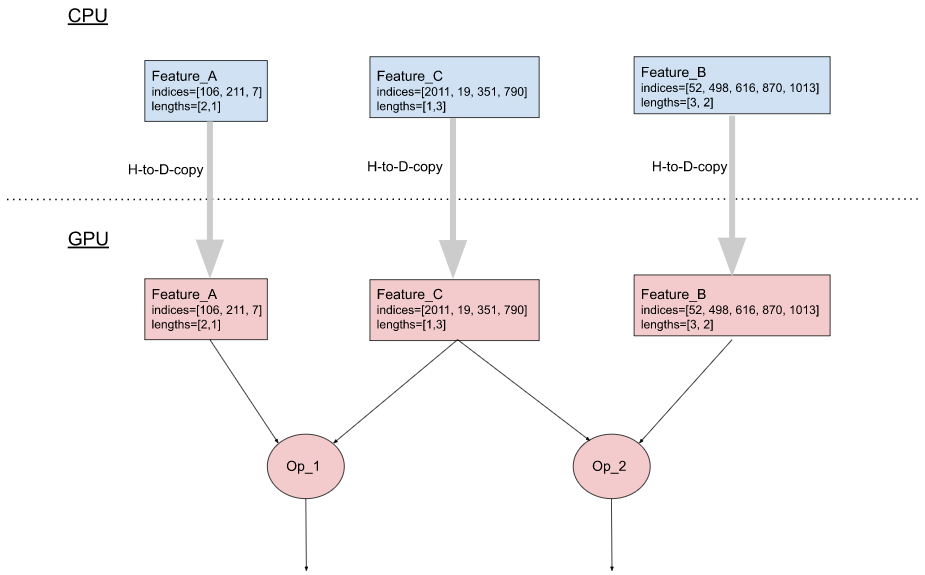
(a). 未经优化
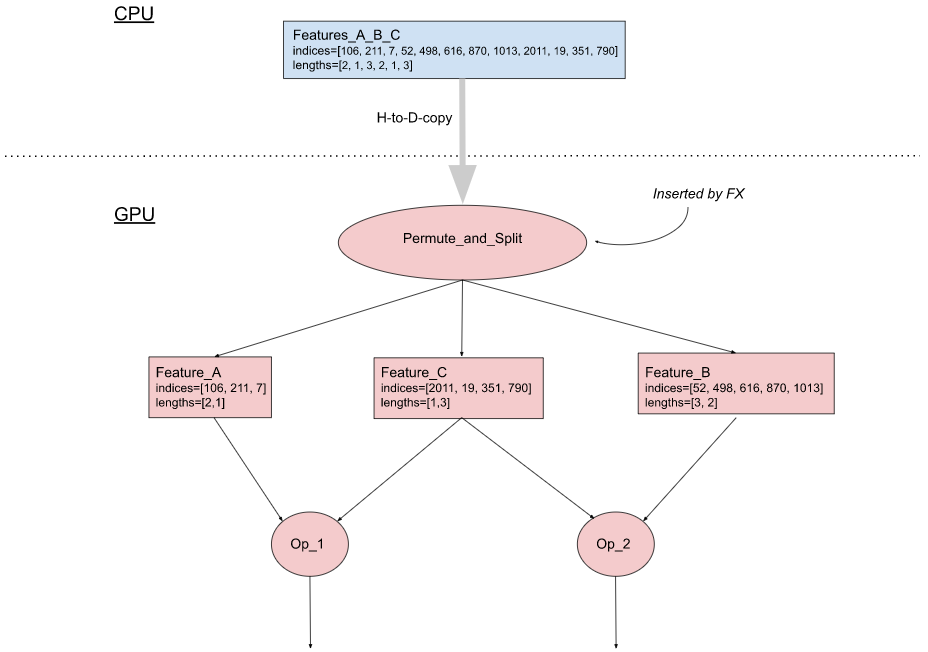
(b). 经过优化
图 3:组合输入稀疏特征
3.2 以访问嵌入表开始的计算链的水平融合
在生产模型中,每个 GPU 上有数十个嵌入表是很常见的。出于性能原因,对这些表的查找被分组在一起,以便它们的输出被连接成一个大的张量(参见图 4(a) 中的红色部分)。为了对单个特征输出应用计算,使用 Split 操作将大张量分成 N 个较小的张量(其中 N 是特征的数量),然后将所需的计算应用于每个张量。如图 4(a) 所示,应用于每个特征输出 O 的计算是 Tanh(LayerNorm(O))。所有计算结果被连接回一个大张量,然后传递给下游操作(图 4(a) 中的 Op1)。
这里主要的运行时开销是 GPU 内核启动开销。例如,图 4(a) 中 GPU 内核启动的次数是 2*N + 3(图中的每个椭圆形都是一个 GPU 内核)。这可能会成为一个性能问题,因为 LayerNorm 和 Tanh 在 GPU 上的执行时间相对于它们的内核启动时间来说很短。此外,Split 操作可能会创建嵌入输出张量的额外副本,消耗额外的 GPU 内存。
我们使用 FX 实现了一个名为水平融合的优化,该优化显著减少了 GPU 内核启动次数(在这个例子中,优化后的 GPU 内核启动次数为 5,参见图 4(b))。我们不进行显式 Split,而是使用 Add_middle_dim 操作将形状为 (B, NxD) 的 2D 嵌入张量重塑为形状为 (B, N, D) 的 3D 张量。然后对其最后一个维度应用单个 LayerNorm。然后对 LayerNorm 的结果应用单个 Tanh。最后,我们使用 Remove_middle_dim 操作将 Tanh 的结果重塑回 2D 张量。此外,由于 Add_middle_dim 和 Remove_middle_dim 只重塑张量而不创建额外副本,GPU 内存消耗也可以减少。
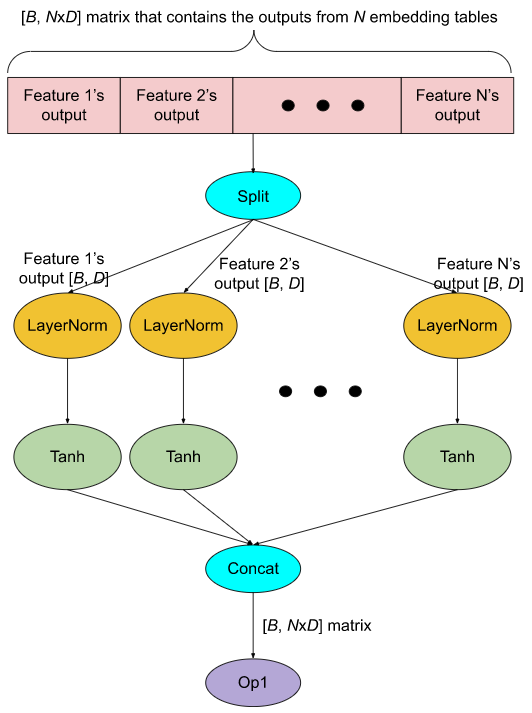
(a). 未经优化
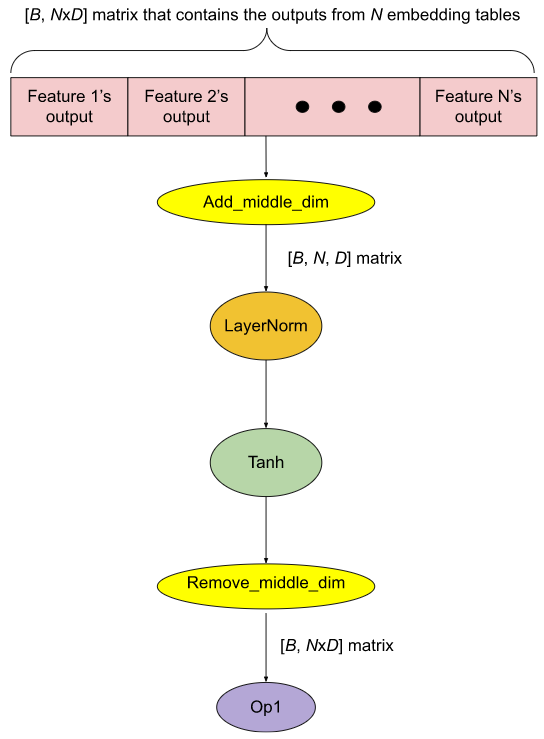
(b). 经过优化
图 4:水平融合
3.3 计算与通信重叠
生产推荐模型的训练通常在分布式 GPU 系统上进行。由于每个 GPU 的设备内存容量不足以容纳模型中的所有嵌入表,因此需要将它们分布在不同的 GPU 之间。
在一个训练步骤中,GPU 需要从/向其他 GPU 上的嵌入表读/写特征值。这被称为 all-to-all 通信 [6],并且可能成为主要的性能瓶颈。
我们使用 FX 来实现一种可以使计算与 all-to-all 通信重叠的转换。图 5(a) 显示了一个模型图的示例,该模型图包含嵌入表访问(EmbeddingAllToAll)和其他操作。在没有任何优化的S情况下,它们在 GPU 流上按顺序执行,如图 5(b) 所示。使用 FX,我们将 EmbeddingAllToAll 分解为 EmbeddingAllToAll_Request 和 EmbeddingAllToAll_Wait,并在它们之间调度独立的运算符。
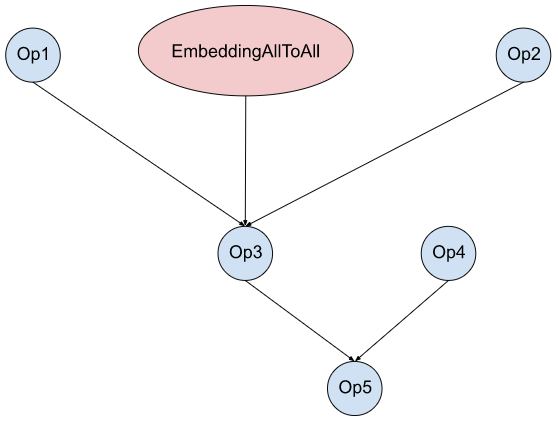
(a) 模型图
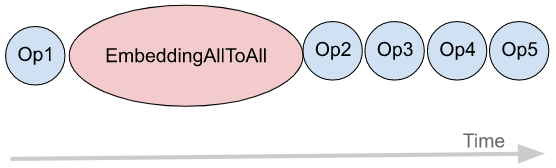
(b) 原始执行顺序
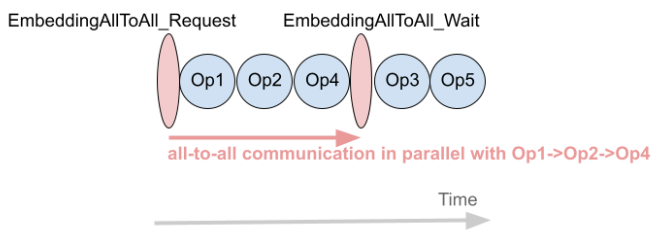
(c) 优化后的执行顺序
图 5:计算与通信重叠
3.4 总结
表 1 总结了本节讨论的优化以及所解决的相应性能瓶颈。
| 优化 | 已解决的性能瓶颈 |
| 组合输入稀疏特征 | 主机到设备的内存复制 |
| 水平融合 | GPU 内核启动开销 |
| 计算与通信重叠 | 嵌入 all-to-all 访问时间 |
表 1:优化和解决的性能瓶颈总结
由于篇幅限制,我们还开发了其他 FX 转换,在此未作讨论。
为了发现哪些模型会受益于这些转换,我们分析了 MAIProf [7] 从 Meta 数据中心运行的模型收集的性能数据。总而言之,这些转换在一些生产模型上比即时模式提供了高达 2-3 倍的加速。
4. 结束语
出于性能原因,PyTorch 中的图模式比即时模式更受生产环境的青睐。FX 是一个强大的工具,用于捕获和优化 PyTorch 程序的图。我们展示了三种 FX 转换,这些转换用于优化 Meta 内部的生产推荐模型。我们希望这篇博文能激励其他 PyTorch 模型开发人员使用图转换来提高其模型的性能。
参考文献
[1] 端到端机器学习框架
[2] DNNFusion:通过高级算子融合加速深度神经网络执行
[3] Torch.FX:Python 中深度学习的实用程序捕获与转换,MLSys 2022。
[5] 用于大规模多任务学习的特征哈希
[6] NVIDIA 集合通信库文档