本周,我们正式发布了 PyTorch 1.1,这是 PyTorch 1.0 的一个重大功能更新。我们新增的功能之一是更好地支持使用 TorchScript(PyTorch JIT)实现快速、自定义的循环神经网络(fastrnns)(https://pytorch.ac.cn/docs/stable/jit.html)。
RNN 是一种流行的模型,在各种不同形状和大小的自然语言处理任务中表现出色。PyTorch 实现了其中一些最流行的模型,包括 Elman RNN、GRU 和 LSTM,以及多层和双向变体。
然而,许多用户希望根据最近的文献思想实现自己的自定义 RNN。将 层归一化 应用于 LSTM 就是其中一种用例。由于 PyTorch CUDA LSTM 实现使用了融合核,因此很难插入归一化甚至修改基本的 LSTM 实现。许多用户转向使用标准 PyTorch 运算符编写自定义实现,但此类代码存在高开销:大多数 PyTorch 操作在 GPU 上至少启动一个核,而 RNN 由于其循环特性通常运行许多操作。然而,我们可以应用 TorchScript 来融合操作并自动优化我们的代码,从而在 GPU 上启动更少、更优化的核。
我们的目标是让用户能够用 TorchScript 编写快速的自定义 RNN,而无需编写专门的 CUDA 核即可获得相似的性能。在这篇文章中,我们将提供一个教程,介绍如何使用 TorchScript 编写自己的快速 RNN。为了更好地理解 TorchScript 应用的优化,我们将研究这些优化在标准 LSTM 实现上的工作方式,但大多数优化可以应用于一般的 RNN。
编写自定义 RNN
要开始,您可以将 此文件 作为模板来编写您自己的自定义 RNN。
我们正在不断改进基础设施,努力提高性能。如果您想获得 TorchScript 目前提供的速度/优化(例如运算符融合、批矩阵乘法等),以下是一些遵循的准则。下一节将深入解释这些优化。
- 如果所有自定义操作都是逐元素的,那太棒了,因为您可以自动获得 PyTorch JIT 运算符融合的好处!
- 如果您有更复杂的操作(例如,减少操作与逐元素操作混合),请考虑将减少操作和逐元素操作分开分组,以便将逐元素操作融合到一个融合组中。
- 如果您想了解您的自定义 RNN 中已融合了哪些内容,您可以使用
graph_for检查操作的优化图。以LSTMCell为例
# get inputs and states for LSTMCell
inputs = get_lstm_inputs()
# instantiate a ScriptModule
cell = LSTMCell(input_size, hidden_size)
# print the optimized graph using graph_for
out = cell(inputs)
print(cell.graph_for(inputs))这将为提供的特定输入生成优化的 TorchScript 图(又称 PyTorch JIT IR)
graph(%x : Float(*, *),
%hx : Float(*, *),
%cx : Float(*, *),
%w_ih : Float(*, *),
%w_hh : Float(*, *),
%b_ih : Float(*),
%b_hh : Float(*)):
%hy : Float(*, *), %cy : Float(*, *) = prim::DifferentiableGraph_0(%cx, %b_hh, %b_ih, %hx, %w_hh, %x, %w_ih)
%30 : (Float(*, *), Float(*, *)) = prim::TupleConstruct(%hy, %cy)
return (%30)
with prim::DifferentiableGraph_0 = graph(%13 : Float(*, *),
%29 : Float(*),
%33 : Float(*),
%40 : Float(*, *),
%43 : Float(*, *),
%45 : Float(*, *),
%48 : Float(*, *)):
%49 : Float(*, *) = aten::t(%48)
%47 : Float(*, *) = aten::mm(%45, %49)
%44 : Float(*, *) = aten::t(%43)
%42 : Float(*, *) = aten::mm(%40, %44)
...some broadcast sizes operations...
%hy : Float(*, *), %287 : Float(*, *), %cy : Float(*, *), %outgate.1 : Float(*, *), %cellgate.1 : Float(*, *), %forgetgate.1 : Float(*, *), %ingate.1 : Float(*, *) = prim::FusionGroup_0(%13, %346, %345, %344, %343)
...some broadcast sizes operations...
return (%hy, %cy, %49, %44, %196, %199, %340, %192, %325, %185, %ingate.1, %forgetgate.1, %cellgate.1, %outgate.1, %395, %396, %287)
with prim::FusionGroup_0 = graph(%13 : Float(*, *),
%71 : Tensor,
%76 : Tensor,
%81 : Tensor,
%86 : Tensor):
...some chunks, constants, and add operations...
%ingate.1 : Float(*, *) = aten::sigmoid(%38)
%forgetgate.1 : Float(*, *) = aten::sigmoid(%34)
%cellgate.1 : Float(*, *) = aten::tanh(%30)
%outgate.1 : Float(*, *) = aten::sigmoid(%26)
%14 : Float(*, *) = aten::mul(%forgetgate.1, %13)
%11 : Float(*, *) = aten::mul(%ingate.1, %cellgate.1)
%cy : Float(*, *) = aten::add(%14, %11, %69)
%4 : Float(*, *) = aten::tanh(%cy)
%hy : Float(*, *) = aten::mul(%outgate.1, %4)
return (%hy, %4, %cy, %outgate.1, %cellgate.1, %forgetgate.1, %ingate.1)从上面的图中我们可以看到,它有一个 prim::FusionGroup_0 子图,该子图融合了 LSTMCell 中所有逐元素操作(转置和矩阵乘法不是逐元素操作)。有些图节点一开始可能难以理解,但我们将在优化部分解释其中一些,我们还在本文中省略了一些冗长啰嗦但只为正确性而存在的运算符。
可变长度序列的最佳实践
TorchScript 不支持 PackedSequence。通常,处理可变长度序列时,最好将它们填充成单个张量,然后通过 TorchScript LSTM 传输该张量。下面是一个例子:
sequences = [...] # List[Tensor], each Tensor is T' x C
padded = torch.utils.rnn.pad_sequence(sequences)
lengths = [seq.size(0) for seq in sequences]
padded # T x N x C, where N is batch size and T is the max of all T'
model = LSTM(...)
output, hiddens = model(padded)
output # T x N x C
当然,output 在填充区域可能有一些垃圾数据;使用 lengths 来跟踪不需要的部分。
优化
我们现在将解释 PyTorch JIT 为加速自定义 RNN 所做的优化。我们将使用 TorchScript 中的一个简单自定义 LSTM 模型来说明这些优化,但其中许多是通用的,也适用于其他 RNN。
为了说明我们所做的优化以及我们如何从中获益,我们将运行一个用 TorchScript 编写的简单自定义 LSTM 模型(您可以参考 custom_lstm.py 中的代码或下面的代码片段),并计时我们的更改。
我们在一台配备 2 个 Intel Xeon 芯片和 1 个 Nvidia P100、安装 cuDNN v7.3、CUDA 9.2 的机器上设置了环境。LSTM 模型的基本设置如下:
input_size = 512
hidden_size = 512
mini_batch = 64
numLayers = 1
seq_length = 100
PyTorch JIT 最重要的一点是将 Python 程序编译成 PyTorch JIT IR,这是一种用于建模程序图结构的中间表示。然后,该 IR 可以受益于全程序优化、硬件加速,并且总体上有可能提供巨大的计算增益。在此示例中,我们运行初始 TorchScript 模型,仅使用 JIT 提供的编译器优化过程,包括公共子表达式消除、常量池、常量传播、死代码消除和一些窥孔优化。我们在预热后运行模型训练 100 次并平均训练时间。模型前向传播时间的初始结果约为 27 毫秒,反向传播时间约为 64 毫秒,这与 PyTorch cuDNN LSTM 提供的结果相去甚远。接下来,我们将解释我们在训练或推断方面提高性能的主要优化,首先是 LSTMCell 和 LSTMLayer,以及一些杂项优化。
LSTM Cell (前向传播)
LSTM 中几乎所有的计算都发生在 LSTMCell 中,因此我们检查它所包含的计算以及如何提高它们的速度非常重要。下面是 TorchScript 中 LSTMCell 实现的示例
class LSTMCell(jit.ScriptModule):
def __init__(self, input_size, hidden_size):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.weight_ih = Parameter(torch.randn(4 * hidden_size, input_size))
self.weight_hh = Parameter(torch.randn(4 * hidden_size, hidden_size))
self.bias_ih = Parameter(torch.randn(4 * hidden_size))
self.bias_hh = Parameter(torch.randn(4 * hidden_size))
@jit.script_method
def forward(self, input, state):
# type: (Tensor, Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]
hx, cx = state
gates = (torch.mm(input, self.weight_ih.t()) + self.bias_ih +
torch.mm(hx, self.weight_hh.t()) + self.bias_hh)
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1)
ingate = torch.sigmoid(ingate)
forgetgate = torch.sigmoid(forgetgate)
cellgate = torch.tanh(cellgate)
outgate = torch.sigmoid(outgate)
cy = (forgetgate * cx) + (ingate * cellgate)
hy = outgate * torch.tanh(cy)
return hy, (hy, cy)
TorchScript 生成的这种图表示(IR)可以实现多种优化和可伸缩计算。除了我们可以进行的典型编译器优化(CSE、常量传播等)之外,我们还可以运行其他 IR 转换来加速我们的代码。
- 逐元素运算符融合。PyTorch JIT 将自动融合逐元素运算符,因此当您有相邻的运算符都是逐元素时,JIT 将自动将所有这些操作组合成一个 FusionGroup,然后可以通过单个 GPU/CPU 内核启动该 FusionGroup 并一次完成。这避免了每次操作昂贵的内存读写。
- 重新排序分块和逐点操作以实现更多融合。LSTM 单元将门控相加(一个逐点操作),然后将门控分成四部分:ifco 门控。然后,它像上面那样对 ifco 门控执行逐点操作。这实际上导致了两个融合组:一个用于分块前的逐元素操作,另一个用于分块后的逐元素操作。这里有趣的是,逐点操作与
torch.chunk交换:我们不必对一些输入张量执行逐点操作并分块输出,而是可以分块输入张量,然后对输出张量执行相同的逐点操作。通过将分块移动到第一个融合组之前,我们可以将第一个和第二个融合组合并为一个大组。
- 在 CPU 上创建张量开销很大,但正在进行的工作旨在使其更快。目前,一个 LSTMCell 运行三个 CUDA 内核:两个
gemm内核和一个用于单个逐点组的内核。我们注意到的一件事是,第二个gemm结束和单个逐点组开始之间存在很大的差距。这个差距是 GPU 空闲无事可做的一段时间。深入研究后,我们发现问题是torch.chunk构造了新的张量,并且张量构造的速度不如预期。我们没有构造新的 Tensor 对象,而是教融合编译器如何操作数据指针和步长来执行torch.chunk,然后将其发送到融合内核,从而缩短了第二个 gemm 和逐元素融合组启动之间的空闲时间。这使 LSTM 前向传播的速度提高了约 1.2 倍。
通过上述技巧,我们能够将几乎所有的 LSTMCell 前向图(除了两个 gemm 核)融合到一个融合组中,这对应于上述 IR 图中的 prim::FusionGroup_0。然后它将被启动到一个单独的融合核中执行。通过这些优化,模型性能显著提高,平均前向传播时间减少了约 17ms(提速 1.7 倍)至 10ms,平均反向传播时间减少了 37ms 至 27ms(提速 1.37 倍)。
LSTM 层 (前向传播)
class LSTMLayer(jit.ScriptModule):
def __init__(self, cell, *cell_args):
super(LSTMLayer, self).__init__()
self.cell = cell(*cell_args)
@jit.script_method
def forward(self, input, state):
# type: (Tensor, Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]
inputs = input.unbind(0)
outputs = torch.jit.annotate(List[Tensor], [])
for i in range(len(inputs)):
out, state = self.cell(inputs[i], state)
outputs += [out]
return torch.stack(outputs), state
我们对为 TorchScript LSTM 生成的 IR 做了几项技巧以提高性能,例如我们做的一些优化:
- 循环展开:我们自动展开代码中的循环(对于大型循环,我们只展开其中一小部分),这使我们能够对 for 循环控制流进行进一步优化。例如,融合器可以融合循环体迭代之间的操作,这对于像 LSTM 这样控制流密集型的模型来说,可以显著提高性能。
- 批矩阵乘法:对于输入经过预乘法的 RNN(即模型有很多与相同 LHS 或 RHS 的矩阵乘法),我们可以有效地将这些操作批处理成单个矩阵乘法,同时对输出进行分块以实现等效语义。
通过应用这些技术,我们将前向传播时间额外减少了 1.6 毫秒至 8.4 毫秒(提速 1.2 倍),并将反向传播时间减少了 7 毫秒至约 20 毫秒(提速 1.35 倍)。
LSTM 层 (反向传播)
- “树形”批量矩阵乘法:在 LSTM 反向传播图中,单个权重经常被多次重用,形成一个以矩阵乘法为叶子,加法为节点的树。这些节点可以通过在不同维度上连接 LHS 和 RHS 来组合,然后作为单个矩阵乘法进行计算。等效公式可以表示为:L1∗R1+L2∗R2=torch.cat((L1,L2),dim=1)∗torch.cat((R1,R2),dim=0)
- 自动微分是使 PyTorch 成为如此优雅的机器学习框架的关键组成部分。因此,我们将其延续到 PyTorch JIT 中,但使用了一种在 IR 级别工作的新型 自动微分 (AD) 机制。JIT 自动微分将前向图切割成符号可微分的子图,并为这些子图生成反向节点。以上述 IR 为例,我们将图节点分组到一个
prim::DifferentiableGraph_0中,用于具有 AD 公式的操作。对于尚未添加到 AD 公式的操作,我们将在执行期间回退到 Autograd。 - 优化反向路径很困难,隐式广播语义使自动微分的优化更加困难。PyTorch 使编写张量操作变得方便,无需担心形状,因为它会为您广播张量。对于性能而言,反向传播的痛点是我们这种可广播操作需要进行求和。这导致每个可广播操作的导数后面都有一个求和。由于我们目前无法融合规约操作,这导致 FusionGroups 分裂成多个小组,从而导致性能不佳。要解决这个问题,请参考 Thomas Viehmann 撰写的这篇很棒的 文章。
杂项优化
- 除了上述步骤,我们还消除了 CUDA 内核启动和不必要的张量分配之间的开销。一个例子是当您进行张量设备查找时。这最初可能会导致许多不必要的分配,从而导致糟糕的性能。当我们消除这些时,内核启动之间的延迟从毫秒级减少到纳秒级。
- 最后,自定义 LSTMCell 中可能会应用归一化,例如 LayerNorm。由于 LayerNorm 和其他归一化操作包含规约操作,因此很难将其完全融合。相反,我们自动将 Layernorm 分解为统计计算(规约操作)+ 逐元素转换,然后将这些逐元素部分融合在一起。截至本文发表时,我们的自动微分和图融合器基础设施存在一些限制,将当前支持限制为仅推理模式。我们计划在未来的版本中添加反向传播支持。
通过上述操作融合、循环展开、批矩阵乘法和一些杂项优化,我们可以从下图中看到我们的自定义 TorchScript LSTM 前向和反向性能显著提升
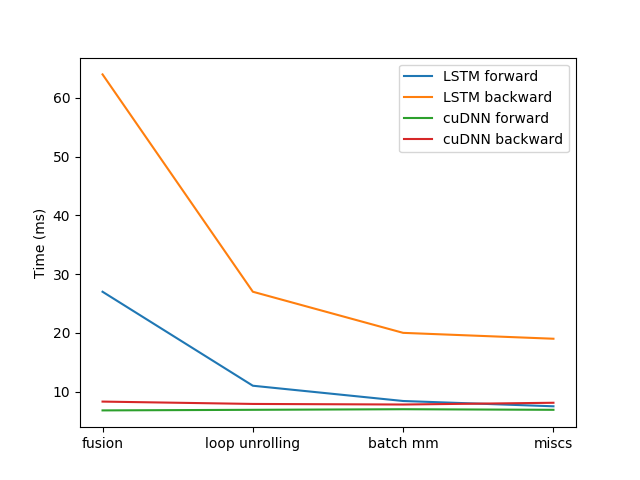
我们在这篇文章中还有许多其他优化没有涉及。除了本文中列出的优化之外,我们现在看到我们的自定义 LSTM 前向传播与 cuDNN 不相上下。我们还在努力优化反向传播,并期望在未来版本中看到改进。除了 TorchScript 提供的速度之外,我们还引入了更灵活的 API,使您能够手写更多自定义 RNN,这是 cuDNN 无法提供的。