专家混合 (Mixture-of-Experts, MoE) 是一种流行的大型语言模型 (LLM) 架构。尽管它通过每个 token 激活更少的参数来减少训练和推理中的计算量,但由于高内存和通信压力,以及处理模型动态性和稀疏性性质的复杂性,它在实现最佳计算效率方面带来了额外的挑战。在此,我们介绍一种新的 MoE 推理解决方案,即 MetaShuffling,它使我们能够高效地部署 Llama 4 模型进行生产推理。
Llama 4 架构
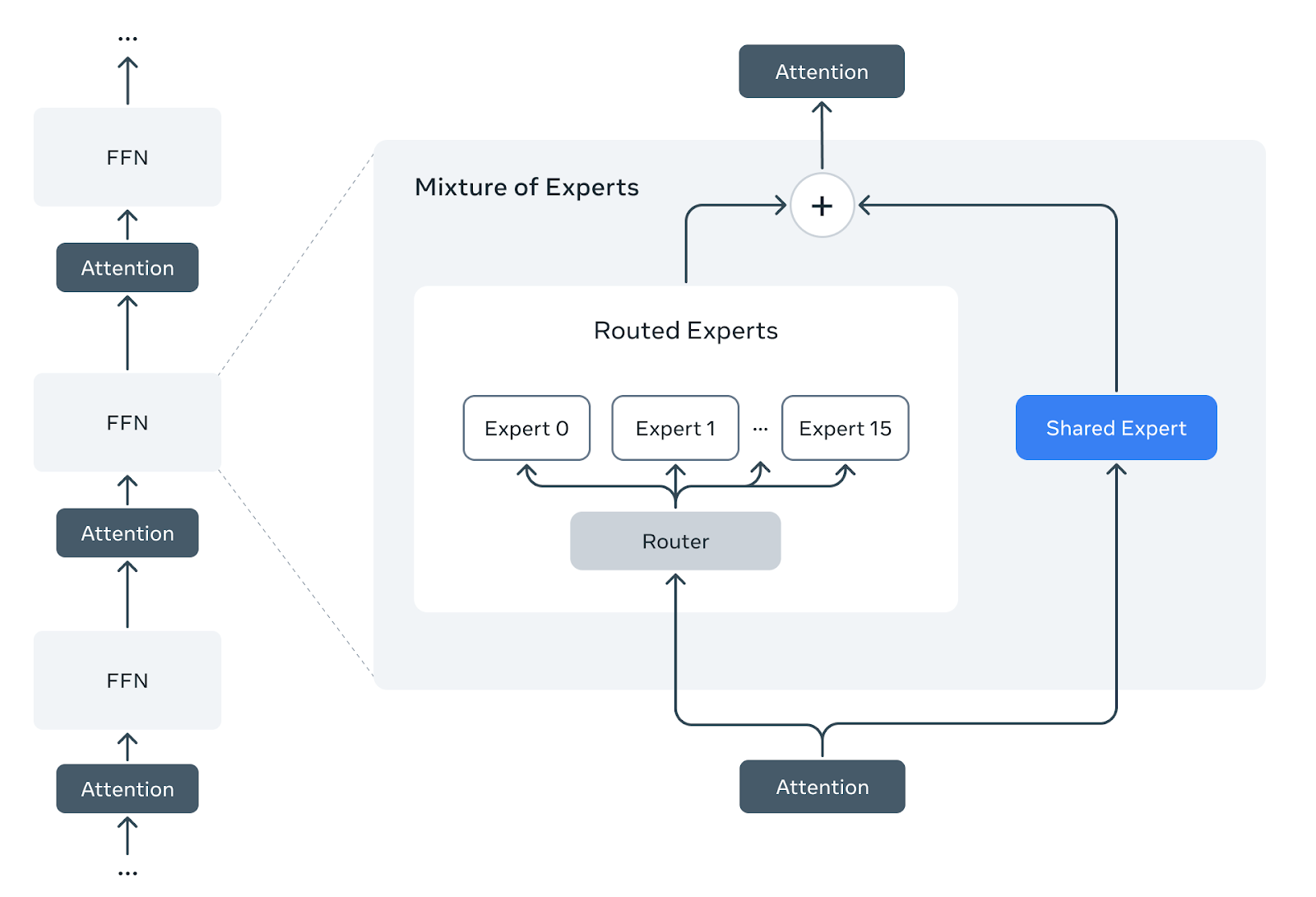
Llama 4 Scout 和 Maverick 模型已正式发布。Scout / Maverick 在每个 MoE 层都有一个共享专家和 16 / 128 个路由专家,采用无丢弃的 token 选择路由和 Top-1 选择。此外,共享专家和路由专家都使用带有 3 个线性层的 SwiGLU 激活函数。有关模型的更多信息,请参阅 Llama 4 系列:原生多模态 AI 创新新时代的开始。
核心概念
有多种常见的解决方案来处理 MoE 层中引入的动态性和稀疏性问题。在此,我们演示了采用 Top-1 选择的 token 选择路由的不同解决方案。
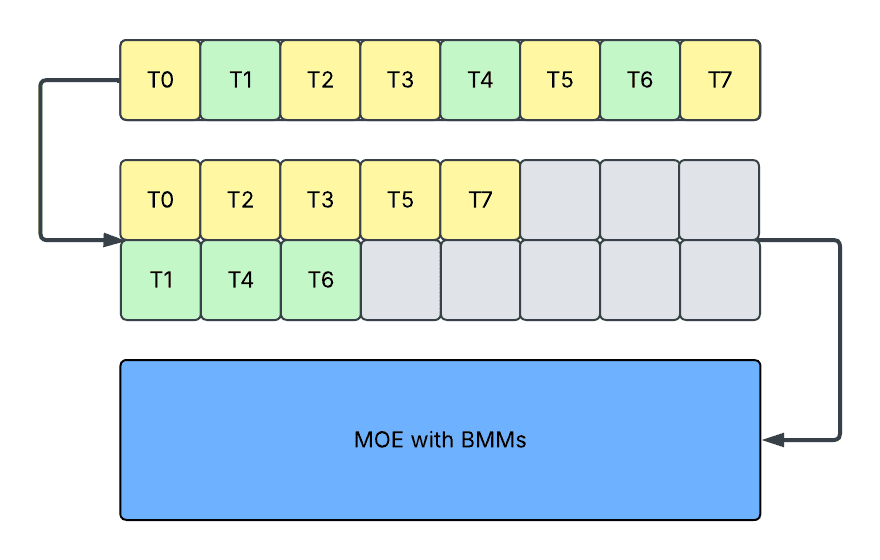
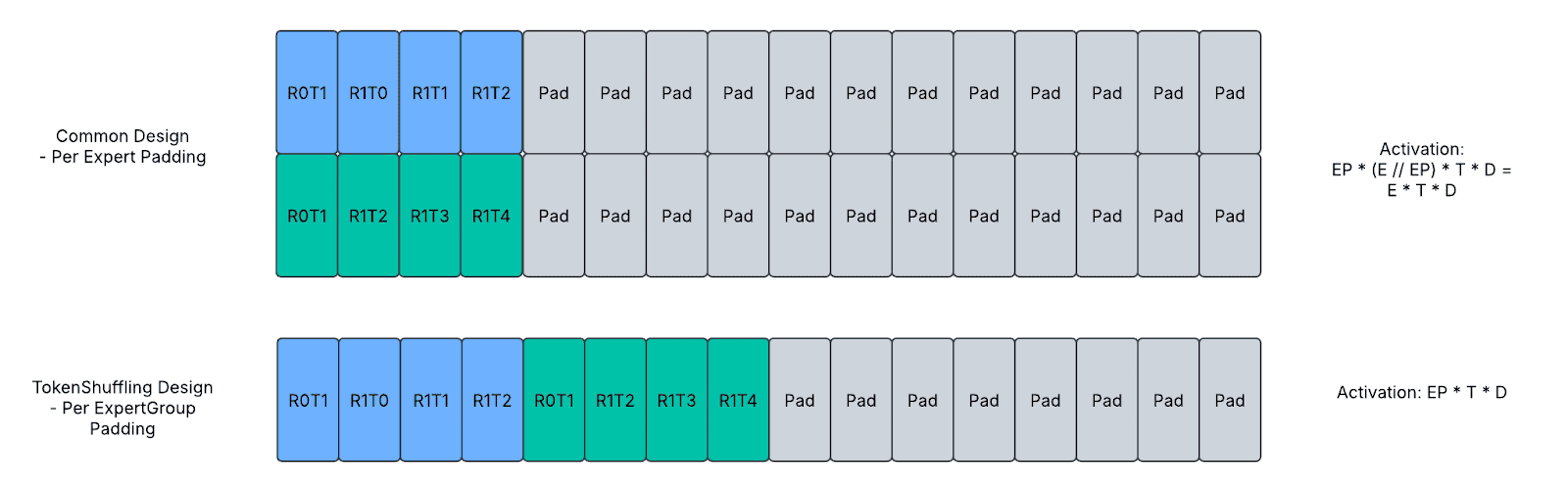
上图显示了填充设计。每个方框代表一个 token,黄色/绿色代表分配给不同路由专家的有效 token,灰色代表填充 token。第二步中的每行方框代表不同的路由专家。Ti 代表数据并行组当前 rank 的第 i 个 token。
- 填充 (Padding):在这种方法中,我们将每个专家的激活填充到最大序列长度并运行单个批处理矩阵乘法 (BMM)。它导致:
- 增加持有填充的内存。
- 增加处理填充的延迟。请注意,可以通过锯齿形内核避免处理填充,但当专家数量很大时,锯齿形内核也可能导致高开销。
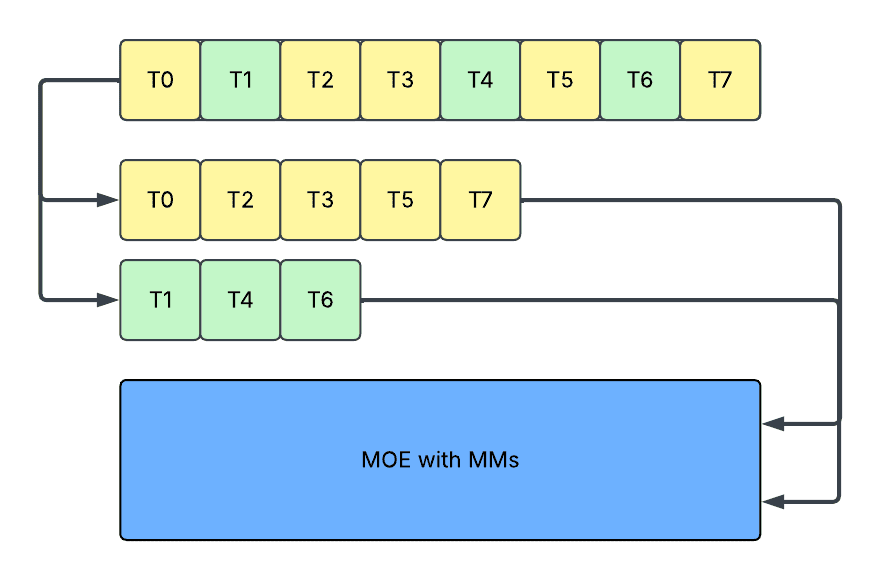
- 切片 (Slicing):在这种方法中,我们将每个专家的激活切片到精确的序列长度并运行多个矩阵乘法 (MM)。它避免了填充中的问题,但它导致:
- 内核效率降低,由小形状上的重复内核启动引起。
- 设备利用率降低,由动态形状上频繁的主机和设备同步以及额外的内核启动开销引起,因为它与图形捕获机制(例如 CUDAGraph 和 torch.compile)不兼容。
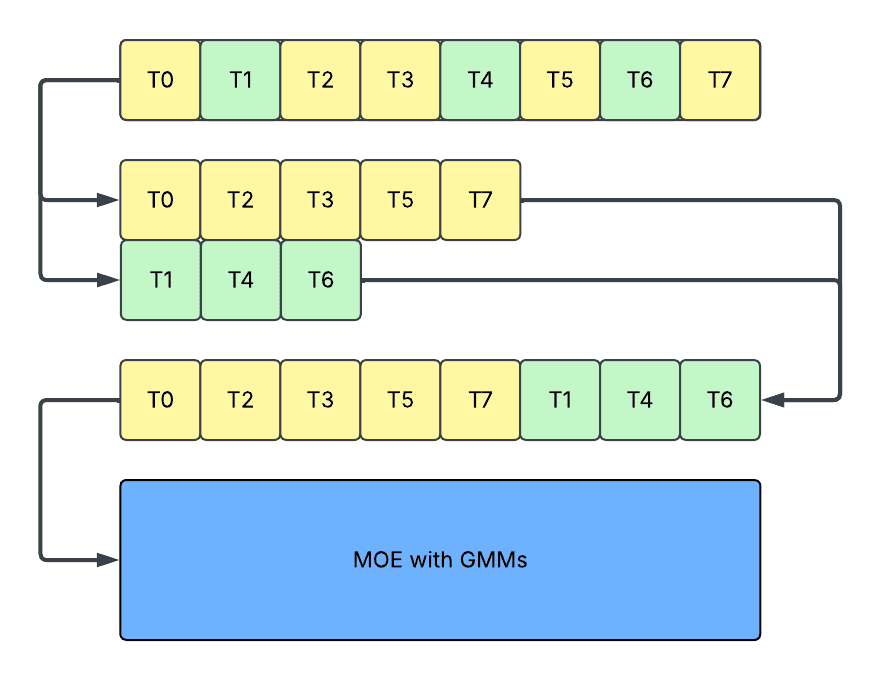
- 拼接 (Concatenation):在这种方法中,我们在切片后进一步拼接激活并运行单个分组矩阵乘法 (GMM)。它避免了切片中的内核效率问题,但仍然导致
- 设备利用率降低,因为它仍然需要主机和设备同步,并且仍然与图形捕获机制不兼容。
为了进一步改进解决方案,我们提出了一种基于洗牌的机制
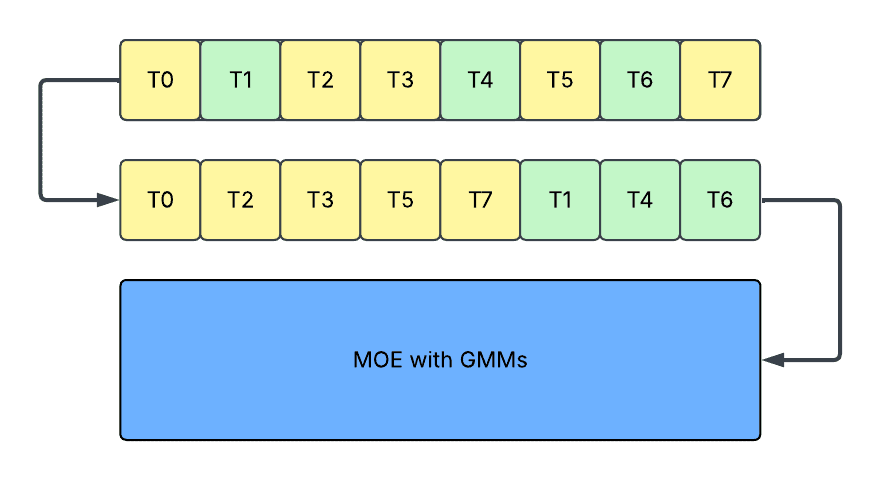
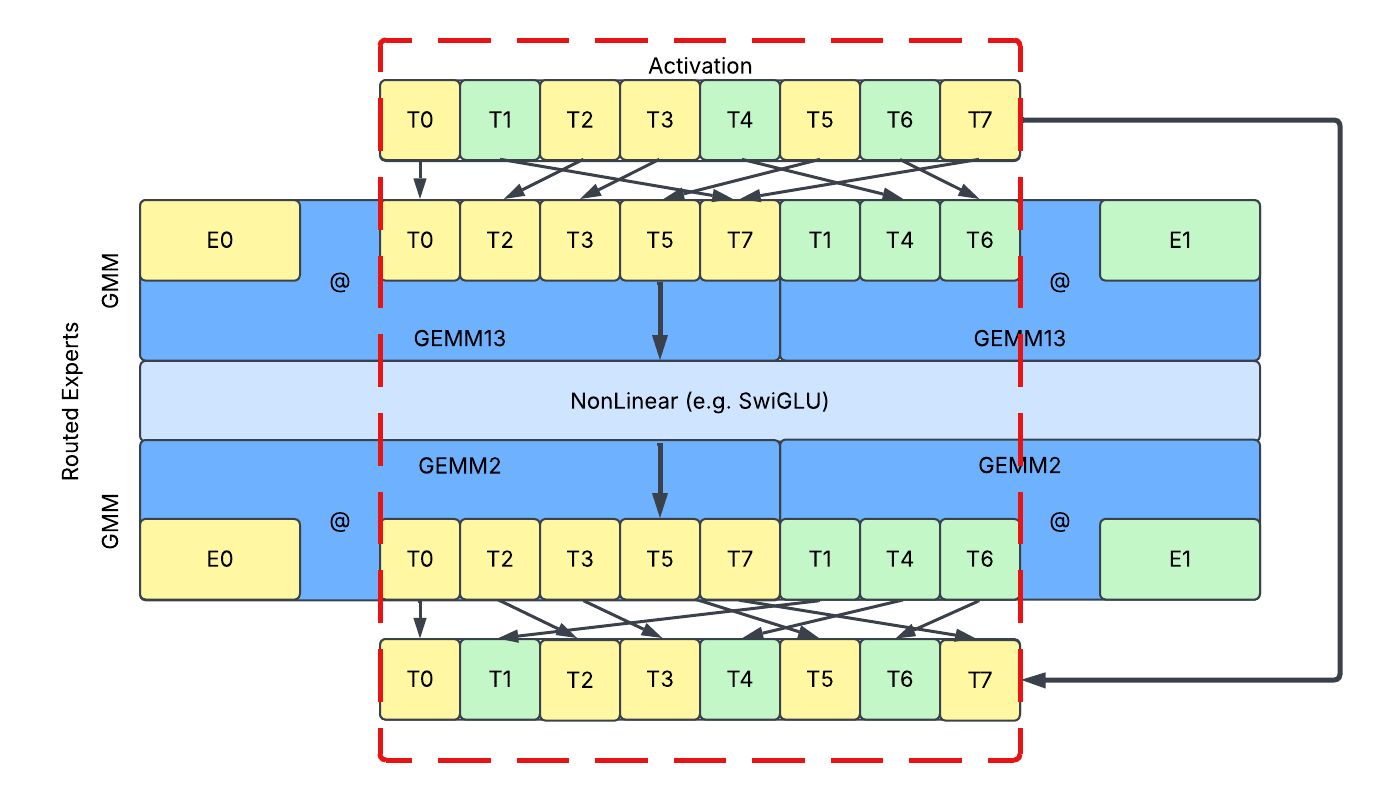
- 洗牌 (Shuffling):在这种方法中,我们直接对 token 进行排序,使路由的 token 按路由专家的 ID 排序。通过这样做,不引入填充或拆分,分配给同一专家的 token 存储在一起,可以在 GroupedGEMM 内部一起处理。它提供了一个密集模型接口,并避免了上述所有问题。
- 没有填充,因为激活仍然是密集张量。
- 没有主机和设备同步,因为激活仍然是静态形状的张量。
我们基于此设计构建了一个端到端的 MoE 推理解决方案,即 MetaShuffling。
运行时设计
单 GPU 推理无并行
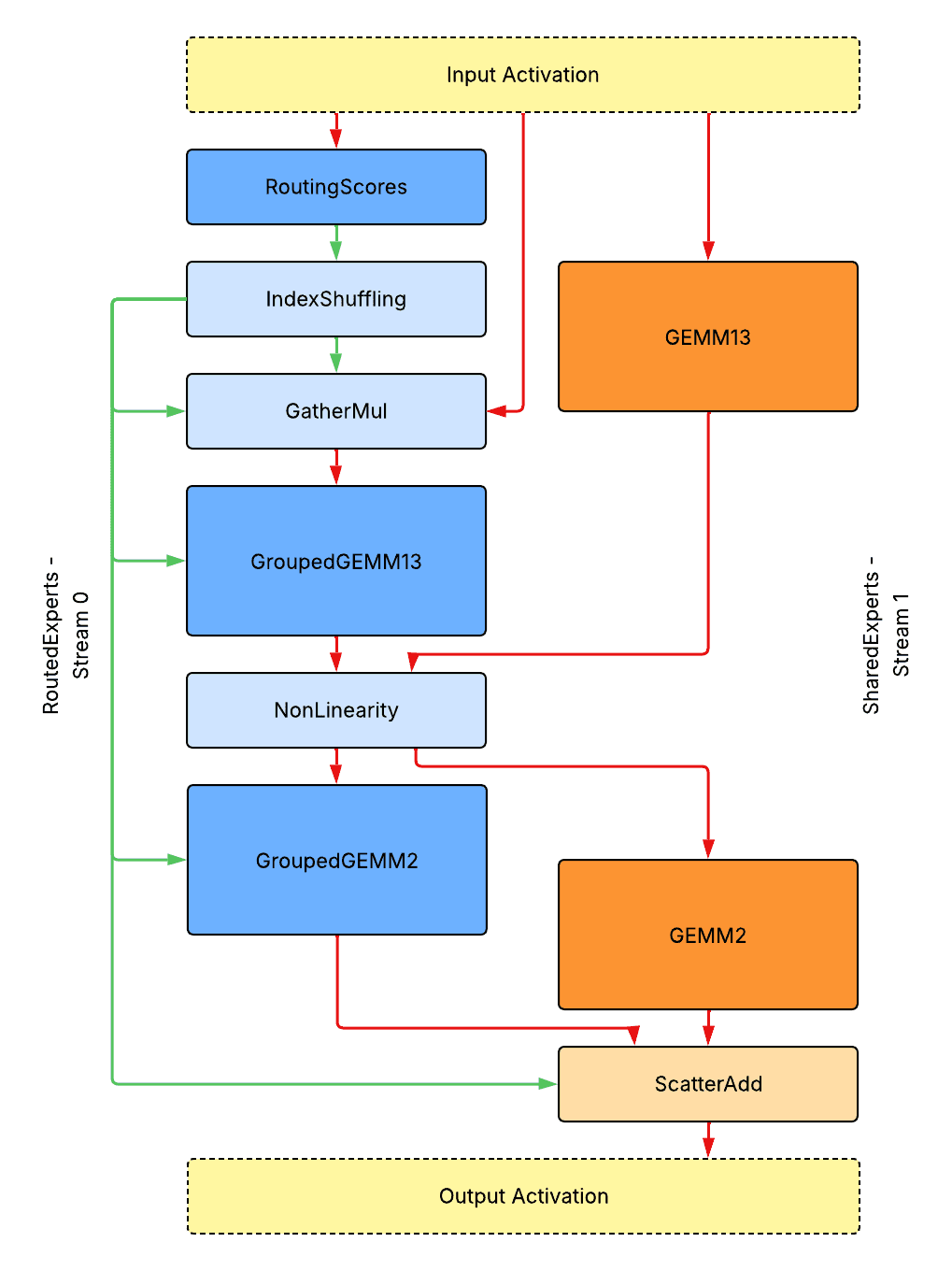
上面是单 GPU 推理无模型并行的整体运行时设计。请注意,为了优化性能,SwiGLU 激活的第一个和第三个线性层合并为 GroupedGEMM13 / GEMM13。
- 深蓝色/橙色实心框表示路由专家/共享专家流上的 Tensor Core 密集型内核。
- 浅蓝色/橙色实心框表示路由专家/共享专家流上的 CUDA Core 或内存流量密集型内核。
- 红色箭头表示激活张量的数据流。
- 绿色箭头表示元数据张量的数据流。
所有元数据张量都放置在设备上。没有阻塞设备到主机的同步。所有内核都是背靠背启动的,没有气泡。该图仅显示数据流,不演示实际的性能分析轨迹。
内核接口和数据流
- RoutingScores:一个处理路由分数计算的函数或融合内核。
- 输入:input_tokens: [T, D](T:token 数量;D:特征维度);router_weights: [D, E](E:专家数量);router_biases: [E];
- 输出:routing_scores: [T, E];scaling_factors: [T, E];
- IndexShuffling:一个处理索引洗牌和排序的融合内核。我们将在 内核设计部分介绍一种优化的实现。
- 输入:routing_scores: [T, E];K(top-k 路由的阈值);
- 输出:routed_token_indices: [K * T];routed_expert_indices: [K * T];routed_token_counts_per_expert: [E];
- GatherMul:一个融合内核,根据排序索引洗牌 token 并对其进行缩放。
- 输入:input_tokens: [T, D];routed_token_indices: [K * T];routed_expert_indices: [K * T];scaling_factors: [T, E];
- 输出:scaled_routed_tokens: [K * T, D]
- GroupedGEMM:一个优化的 GroupedGEMM 内核,可处理关于 M 维度上批次设备形状信息而无限制。我们将在内核设计部分介绍一种优化的实现。
- 输入:tokens: [K * T, D];weights: [E, D, HD](HD:隐藏维度);routed_token_counts_per_expert: [E];
- 输出:tokens: [K * T, HD]
- GEMM:一个优化的 GEMM 内核。接口类似于密集模型。
- NonLinearity:一个处理非线性的融合内核。接口类似于密集模型。
- ScatterAdd:一个优化的内核,根据排序索引反转 token 洗牌,并直接对共享专家输出执行 scatter add,而无需实例化未洗牌的张量。
- 输入:shared_output_tokens: [T, D];routed_output_tokens: [K * T, D];routed_token_indices: [K * T];
- 输出:combined_output_tokens: [T, D]
请注意,如果应用了量化,则激活量化内核将融合到前面的非 GEMM 内核中,这意味着融合到 GroupedGEMM13 的 GatherMul 和 GroupedGEMM2 的 NonLinearity 等。
请注意,如果使用较大的 K * T,GatherMul 和 ScatterAdd 操作可以进一步融合到后续/前面的 GroupedGEMM 操作中,这应该作为序言/跋语中全局内存到共享内存/寄存器或共享内存到全局内存的步骤完成,但是,它在内核设计级别上与 Tensor Core 执行重叠增加了额外的挑战。此外,融合 ScatterAdd 要求共享专家在路由专家之前完成,如果这些内核可以用于隐藏 AlltoAll 延迟,这可能不是一个好的设计选择。
单主机推理的张量并行
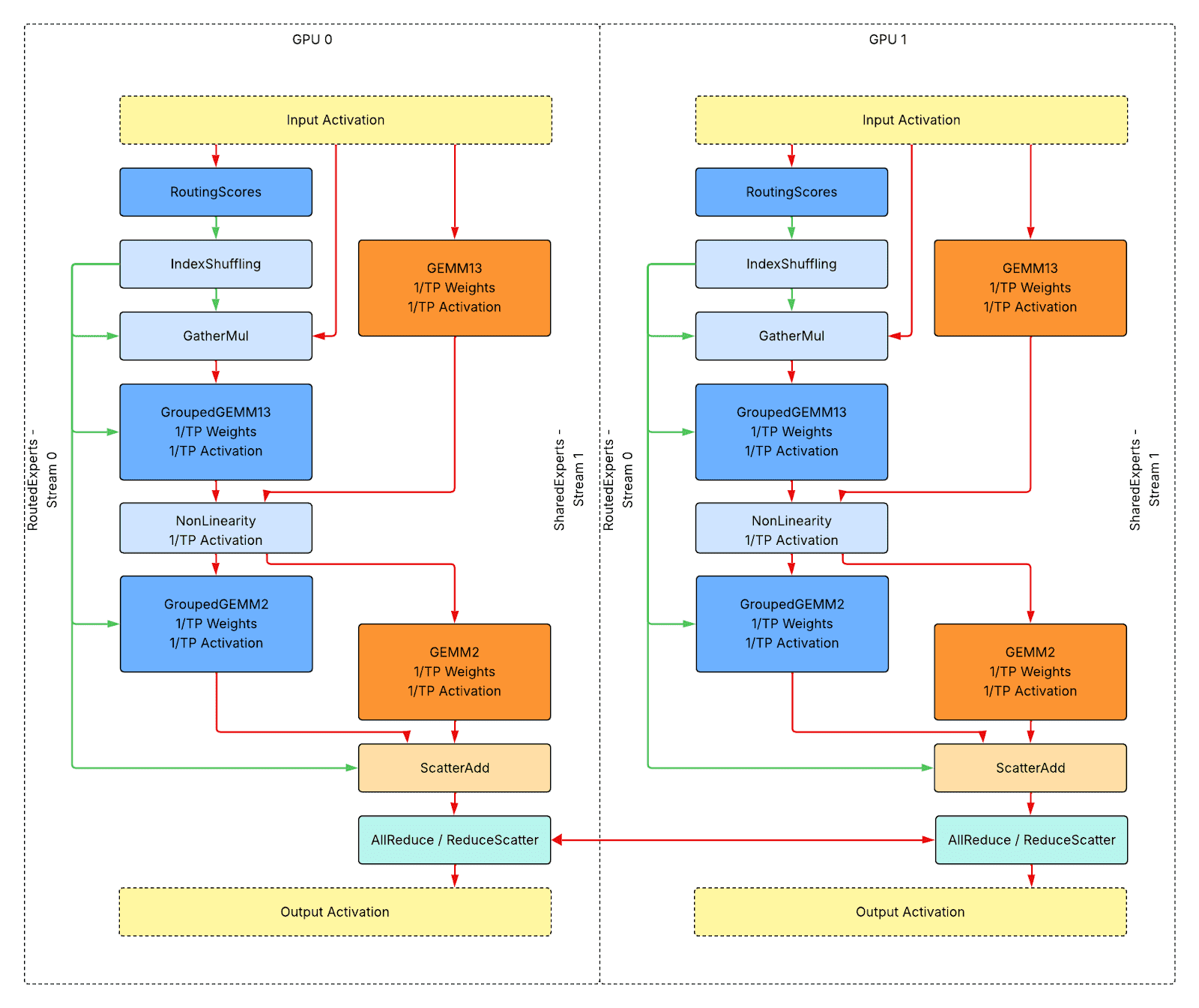
上面是带有张量并行 (TP) 的单主机推理的整体运行时设计。与单 GPU 推理相比,附加步骤是
- 浅薄荷色实心框代表网络流量密集型通信内核。
所有元数据张量仍然放置在设备上,没有设备到主机的同步。所有内核都是背靠背启动的,没有气泡。该图仅显示数据流,不演示实际的性能分析轨迹。
工作负载分片和附加内核
与单 GPU 推理用例相比,没有引入额外的自定义内核。对于 GEMM、GroupedGEMM 和非线性内核,激活和权重都沿不同维度共享到 1/TP,计算/内存开销也共享到 1/TP。
如果只应用张量并行,最后一步应该是 AllReduce。或者,如果张量并行与序列并行一起应用,则为 ReduceScatter。
多主机推理的专家并行
为了启用专家并行 (EP),我们将数据并行维度从路由专家中交换出来,作为路由专家内部的专家并行维度。请注意,张量并行可以进一步与专家并行交换,以提高 GEMM 效率,同时增加路由不平衡的风险,但我们不会在本博客中介绍此设计。
如果专家并行与 token 选择路由一起启用,那么我们必须在使用密集张量或使用静态形状之间做出选择,因为路由到不同专家组的 token 数量是动态的。
- 当我们偏好使用 eager 模式时,我们使用密集张量和动态形状,以避免因运行未填充的 AlltoAll 而造成的网络流量和内存空间浪费。
- 当我们偏好使用图形模式时,我们使用稀疏张量和静态形状,以避免通过运行 CUDAGraph 而造成的 CPU 启动开销和设备到主机同步引起的 GPU 气泡。
请注意,使用自定义 AlltoAll 实现也可以避免填充激活造成的网络流量浪费,但我们不会在本博客中介绍任何关于自定义通信或通信与计算融合内核的主题。
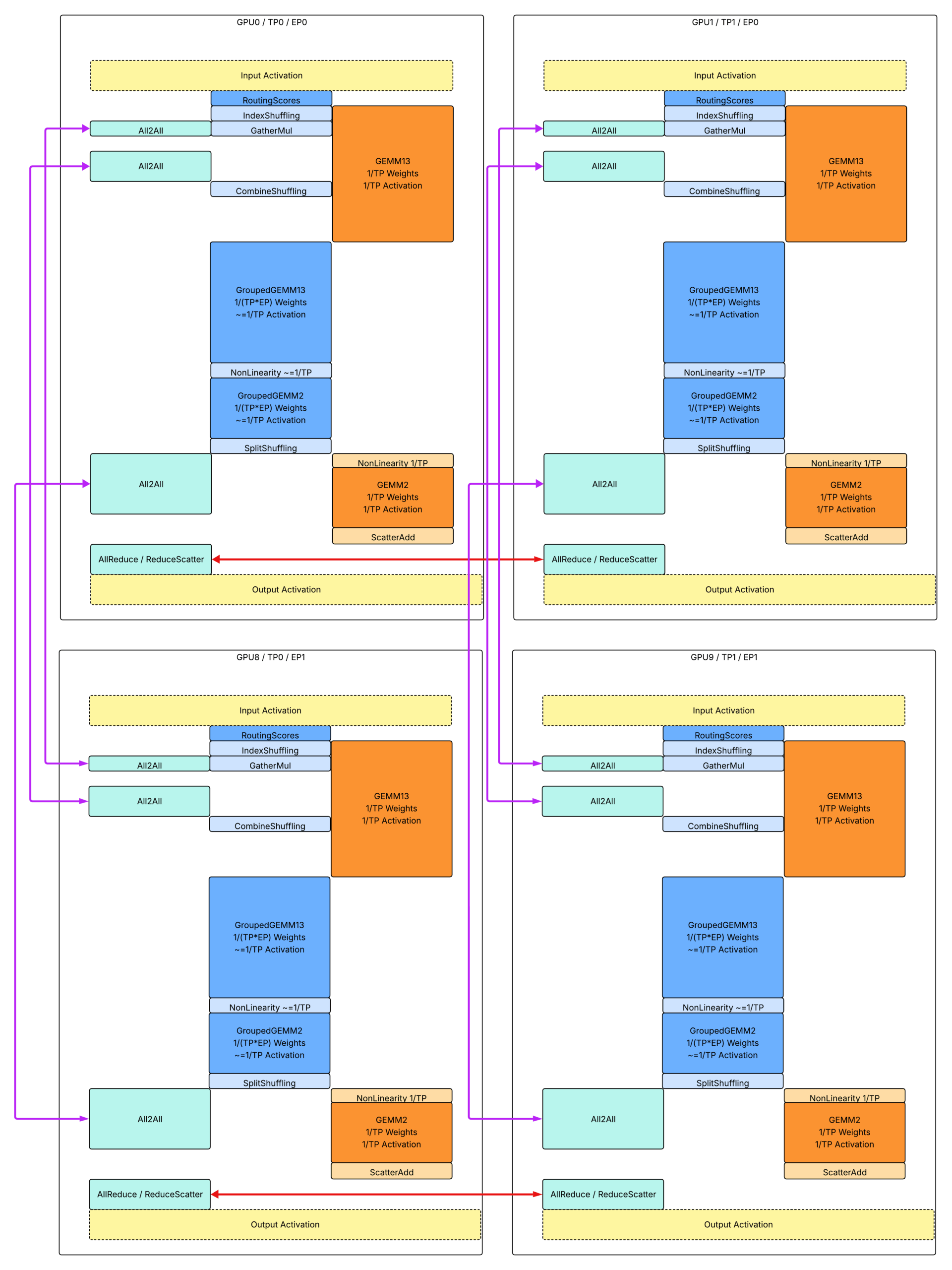
上面是带有张量并行和专家并行的多主机推理的整体运行时设计。与带有张量并行的单主机推理相比。
- 实心红色箭头表示节点内通信。
- 实心紫色箭头表示节点间通信。
内核接口和数据流
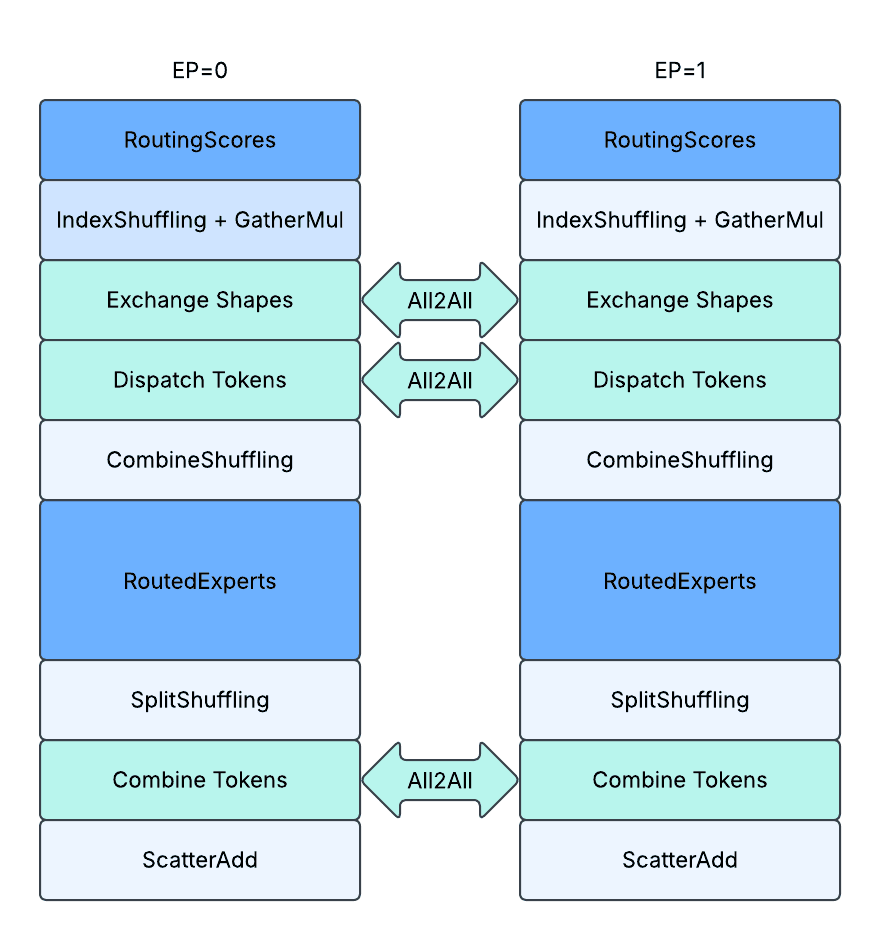
对于添加的基于专家并行的通信,我们使用 3 次 All2All 通信来交换形状和 token
- 第一次 A2A:交换关于路由到每个专家的 token 数量的设备上元数据张量,即 `routed_token_counts_per_expert: [E]`,这是从 IndexShuffling 内核生成的输出。
- 第二次 A2A:交换从基于数据并行的 token 到基于专家并行的 token,根据路由分派到不同的 EP 秩。
- 第三次 A2A:交换从基于专家并行的 token 到基于数据并行的 token,根据路由从不同的 EP 秩组合。
此外,我们添加了 2 个额外的洗牌内核和 1 个特殊的 scatter 内核
- CombineShuffling (密集或填充):将从秩优先顺序接收到的 token 重新洗牌为专家优先顺序。以下 T* 表示从所有对等方接收到的 token 总数,这可以根据 routed_token_counts_per_rank_per_expert 张量的形状信息进一步解释为锯齿状维度。
- 输入:received_tokens: [T*, D](首先按 dp 秩排序,然后按专家索引排序);routed_token_counts_per_rank_per_expert: [EP, E // EP];
- 输出:reshuffled_tokens: [T*, D](首先按专家索引排序,然后按 dp 秩排序);routed_token_counts_per_expert: [E // EP];
- SplitShuffling (密集或填充): CombineShuffling 的反向过程。将要发送的 token 从专家优先顺序重新洗牌为秩优先顺序。
- 输入:reshuffuled_tokens: [T*, D](首先按专家索引排序,然后按 dp 秩排序);routed_token_counts_per_rank_per_expert: [EP, E // EP];
- 输出:to_send_tokens: [T*, D](首先按 dp 秩排序,然后按专家索引排序);
- ScatterAdd (填充): 从填充张量中分散添加有效 token。
- 输入:shared_output_tokens: [T, D];received_padded_routed_output_tokens: [EP, K*T, D]; routed_token_indices: [K * T]; routed_token_counts_per_expert: [E];
- 输出:combined_output_tokens: [T, D]
我们将在 “图形模式下带静态形状的填充通信” 部分提供上述内核的更好演示。
急切模式下带动态形状的未填充通信
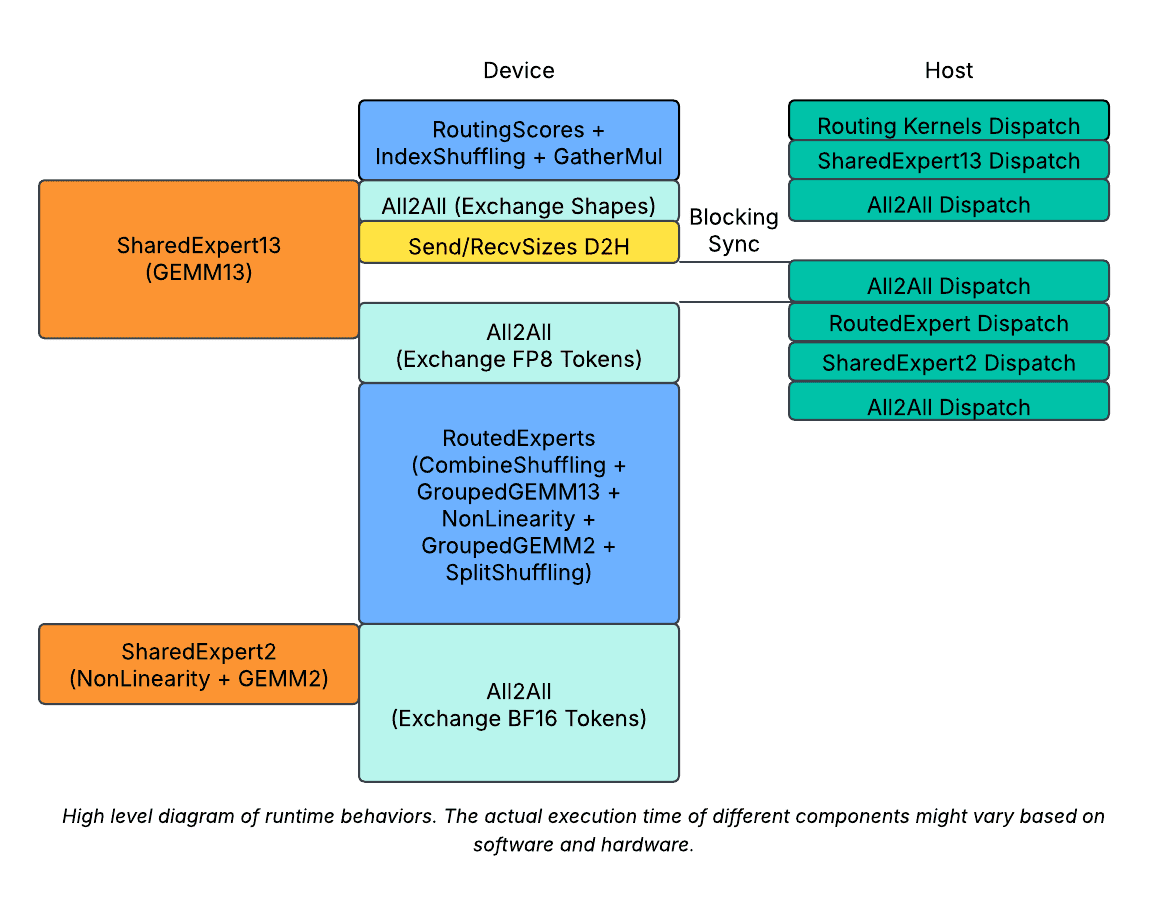
运行时行为的高级图。不同组件的实际运行时可能会因软件和硬件而异。
最小化动态形状的使用
由于路由是每个 MoE 层动态的,因此所需的最小设备/主机同步量是每层一次。为了实现这一点,我们延迟了 `send_sizes` 的 D2H 复制,并将其与 `recv_sizes` 拼接在一起,通过一次 D2H 复制将它们一起传输。这将设备/主机同步减少到每层一次。
最小化动态形状的负面影响
为了进一步隐藏设备/主机同步开销,我们进一步将共享专家分成两部分。
- 我们在路由之后,但在调度 A2A 之前,分派了第一部分。然后,当设备/主机同步发生时,设备仍然忙于运行共享专家。
- 我们在 MoE 之后,但在合并 A2A 之前,分派了第二部分。这将进一步有助于重叠第二次 A2A。
图形模式下带静态形状的填充通信
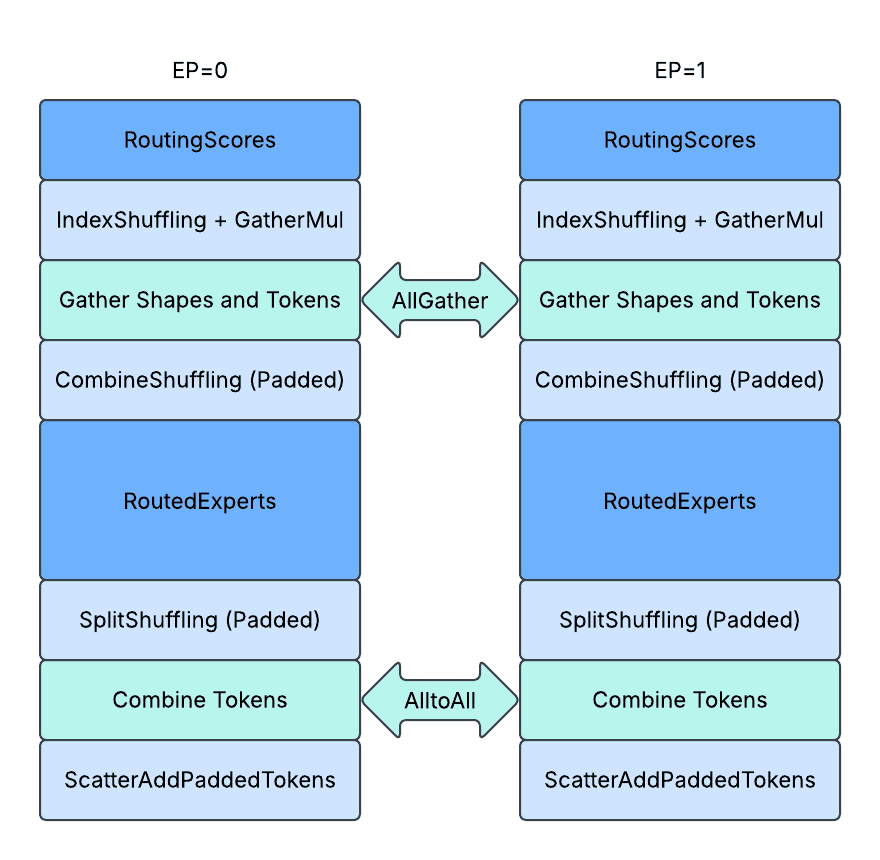
最小化填充的使用
通过无丢弃的 token 选择设计,路由到任何单个专家的最大可能 token 数量是 T。然而,如果我们将多个专家组合在一起并通过专家并行分片将它们放置在单个 GPU 上,对于 TopK 路由,
- 路由到 1 个专家的最大 token 数量是 T。
- 路由到 2 个专家的最大 token 数量是 2 * T。
- …
- 路由到 K 个专家的最大 token 数量是 K * T。
- 路由到 K + 1 个专家的最大 token 数量仍然是 K * T。
- …
因此,路由到 N 个专家的专家组的最大 token 数量将限制为 min(N, K) * T 个 token。
对于 Top1 路由,路由到任意大小的专家组的 token 数量将始终限制为 T 个 token,并且动态 token 所需的最小内存分配和持有量为 EP * T 个 token,因为有 EP 个专家组。
为了实现所需的最小填充,我们直接使用 AllGather 从不同的 EP 秩收集所有活动 token,然后通过自定义内核在本地拆分和重新洗牌路由 token。激活大小压缩到 1 / (E // EP),这对应于内存和网络流量的减少。
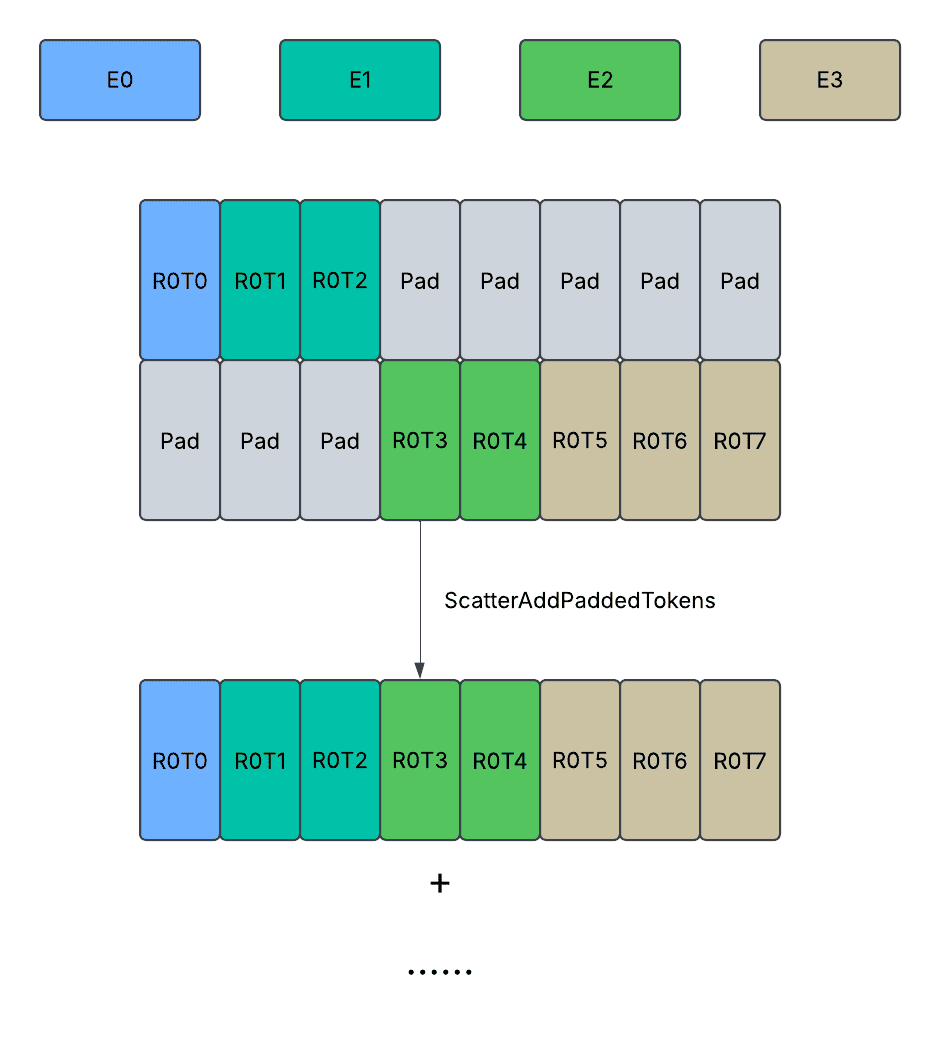
上图显示了填充设计。每个方框代表一个 token,蓝色/绿色代表具有专家分配的有效 token,灰色代表填充 token。RiTj 代表专家并行组中第 i 个秩的第 j 个 token。
最小化填充的负面影响
尽管填充已减少到最小允许量,但我们还确保填充仅导致内存空间(分配)和网络流量(通信),而不会导致冗余计算(GroupedGEMM / NonLinear)、冗余内存带宽(CombineShuffling / SplitShuffling / ScatterAdd),通过获取设备上的形状信息 `routed_token_counts_per_expert` 或 `routed_token_counts_per_rank_per_expert`。
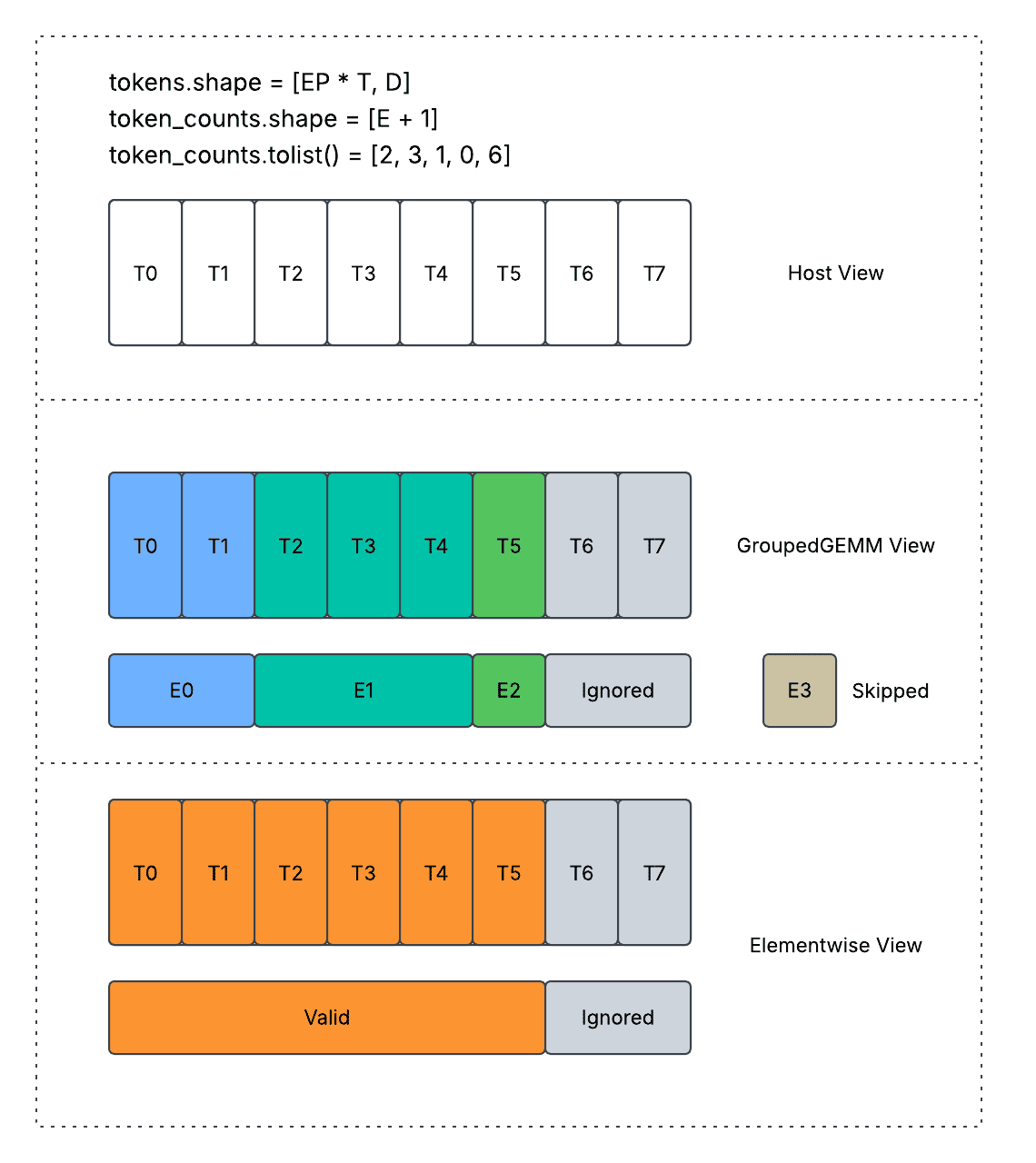
激活概念性解释
最重要的是,
- 当所有 EP 秩中的活动 token 总数较少时,这样做很重要,以避免在 GroupedGEMM 中激活冗余专家并导致额外的内存流量。
- 当所有 EP 秩中的活动 token 总数较多时,这样做也很重要,以避免将 GroupedGEMM 从内存限制转换为计算限制。
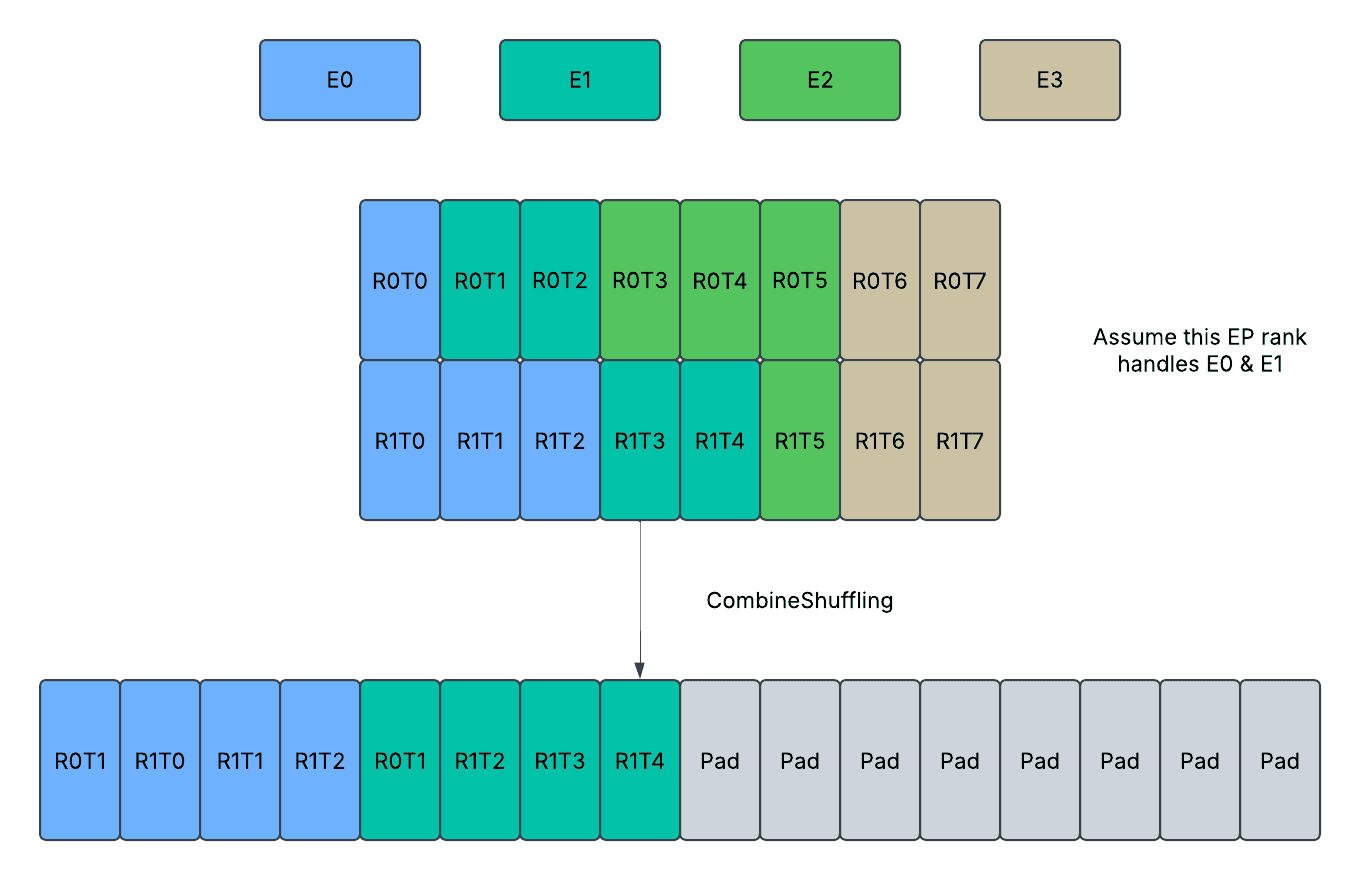
CombineShuffling:在 AllGather 之后,分配给当前 EP 秩的 token 从专家优先顺序重新洗牌为秩优先顺序。未分配的 token 不会被复制,并且张量末尾剩余的已分配内存空间保持不变。
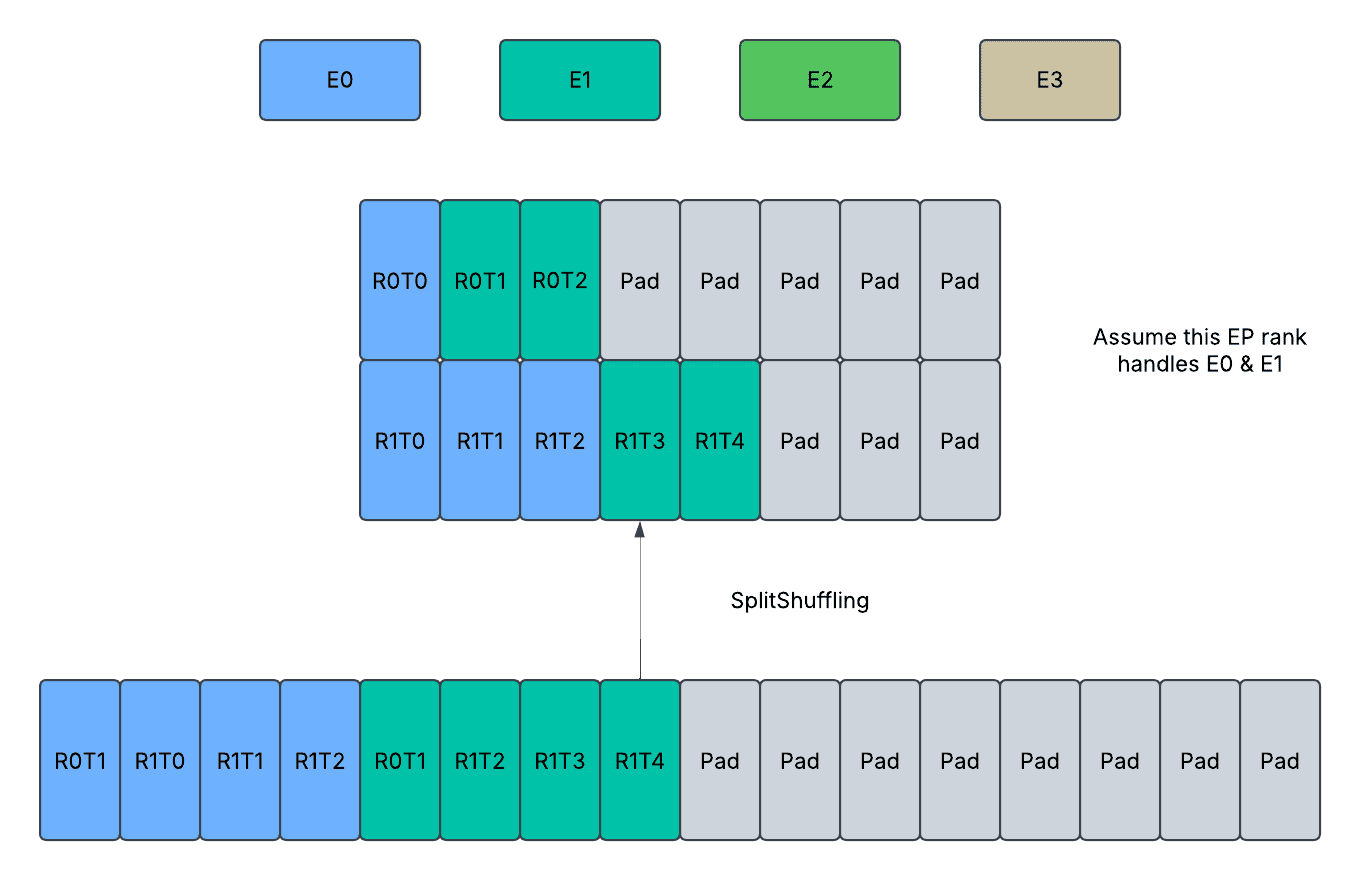
SplitShuffling:分配给当前 EP 秩的 token 在 AlltoAll 之前从秩优先顺序重新洗牌为专家优先顺序。未分配的 token 不会被复制,并且重新洗牌的张量以交错方式存储填充。
ScatterAdd (填充):每个 EP 秩最终接收从所有其他秩计算的激活,它将了解哪些是有效 token,哪些是填充 token,然后只读取有效 token 进行 scatter_add。
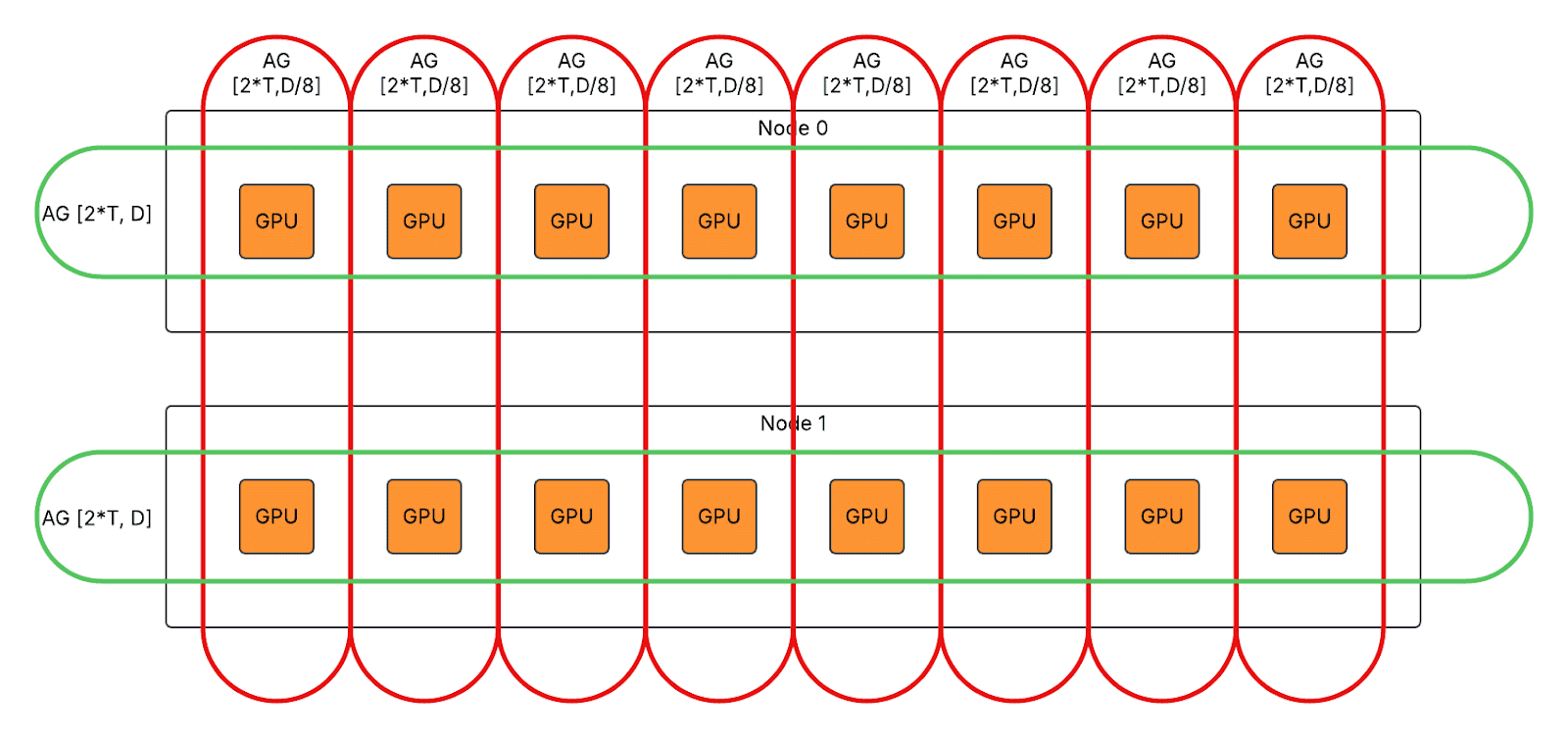
通信去重
不同张量并行秩在第一次 GroupedGEMM 之前和第二次 GroupedGEMM 之后具有相同的激活,因此相同的 token 在节点间重复交换。
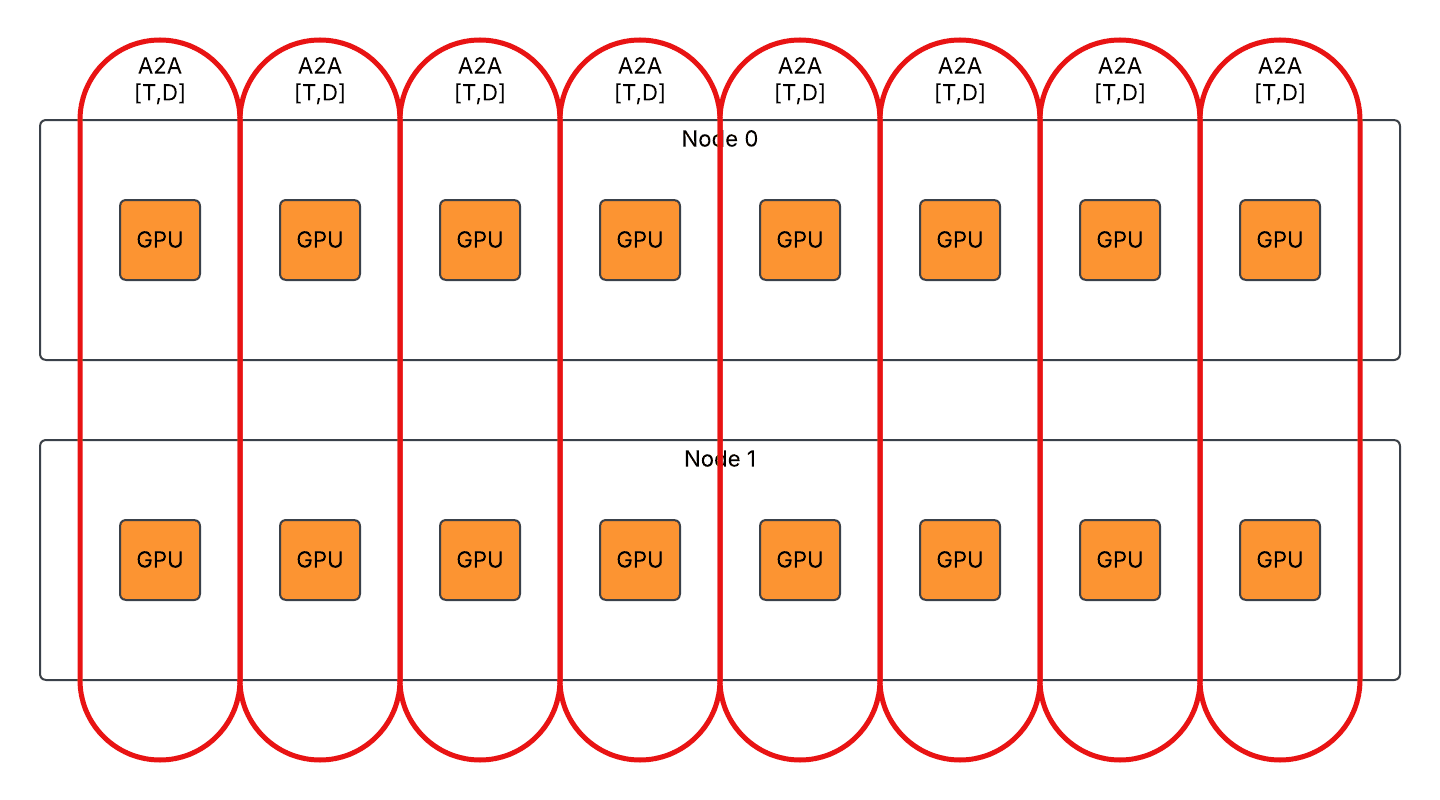
我们启用了通信去重,以将节点间通信工作负载均匀分布到不同的秩,同时引入额外的节点内通信。DP2/TP8/EP2 的示例
- 对于急切模式下的第一个 AlltoAll,将 T*D 节点间 AlltoAll 拆分为 T*D/8 节点间 AlltoAll 和 T*D 节点内 AllGather。
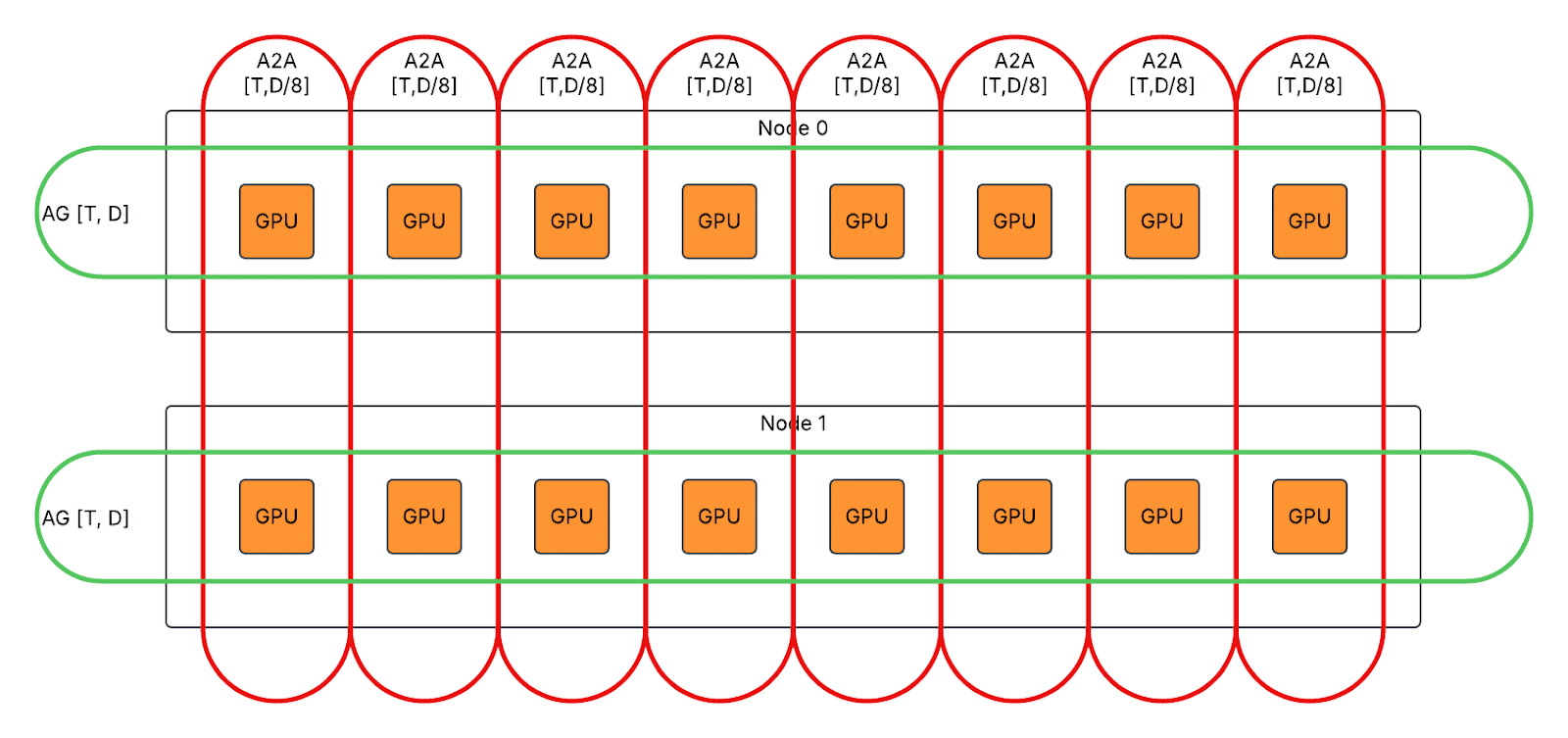
- 对于急切/图形模式下的第二个 AlltoAll,将 T*D 节点间 AlltoAll 拆分为 T*D/8 节点内 ReduceScatter 和 T*D/8 节点间 AlltoAll。
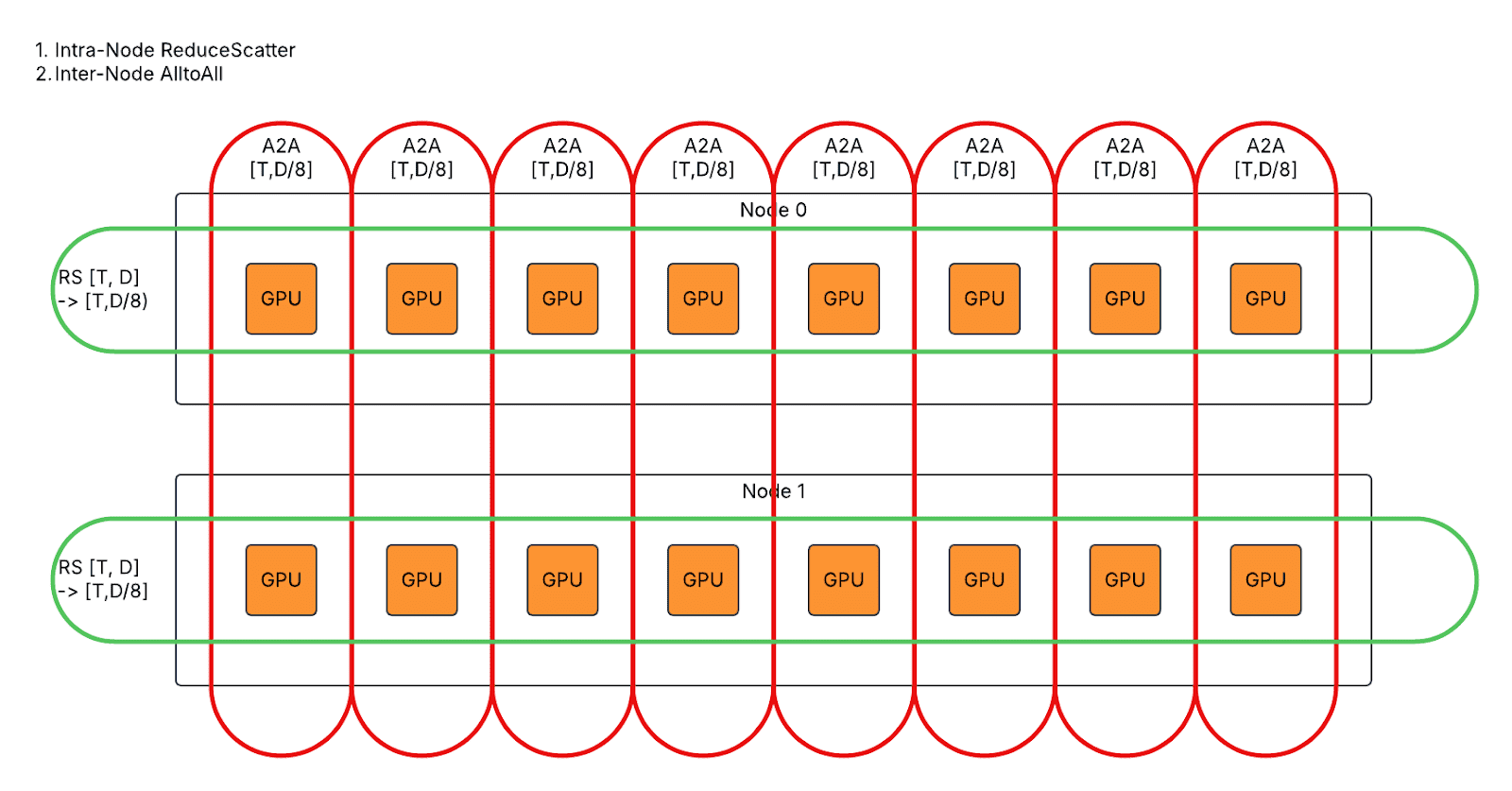
- 对于图形模式下的第一个 AllGather,将 2*T*D 节点间 AlltoAll 拆分为 2*T*D/8 节点间 AllGather 和 2*T*D 节点内 AllGather。
内核设计
我们实现了 10 多个自定义内核,以支持 MetaShuffling MoE 推理设计在不同用例中运行在 Nvidia H100 GPU 和 AMD MI300X GPU 上。我们已将所有计算内核作为 PyTorch 运算符开源在 FBGEMM Generative AI Kernel Library 中。我们希望它能帮助用户 在他们偏好的框架和加速器中高效地服务 Llama 4 模型,例如 vLLM / SGLang。在本博客中,我们将重点介绍两个最有趣的内核设计,它们是提高推理 性能的关键,即 GroupedGEMM 和 IndexShuffling。
GroupedGEMM
我们为 BF16 / FP16 / FP8 Rowwise 实现了基于 Triton 的 GroupedGEMM 内核。
接口
def grouped_gemm_fp8_rowwise(
x: torch.Tensor, # shape: [M, K]
w: torch.Tensor, # shape: [G*N, K]
m_sizes: torch.Tensor, # shape: [G]
x_scales: torch.Tensor, # shape: [M]
w_scales: torch.Tensor, # shape: [G*N]
) -> torch.Tensor: # shape: [M, N]
...
该接口与单个 GEMM 非常相似,它接受单个 LHS、单个 RHS 张量并生成单个输出。从运行时角度来看,没有动态性或稀疏性。
但是,内核使用 `m_sizes` 的数据动态拆分 LHS 张量的 M 维度,并使用 `m_sizes` 的形状静态拆分 RHS 张量的 N 维度。这种设计有几个优点:
- 不同批次的 Ms 内部没有额外的填充或对齐要求。因此 `m_sizes` 可以存储任何非负值,只要其总和不超过 `M`。
- “m_sizes”可以是零值,以跳过加载未激活专家的权重。
- `m_sizes` 的总和可以小于 `M`,以跳过末尾填充 token 的计算而没有额外开销。
- `m_sizes`,或者 LHS 激活的拆分,设备已知但主机未知。因此,它支持动态路由信息,而不会导致设备到主机同步。
工作负载分区
我们采用持久内核设计,为每个 SM 启动 1 个 CTA,并让所有 CTA 交错运行所有分区瓦片。从概念上讲,工作负载分区如下发生。
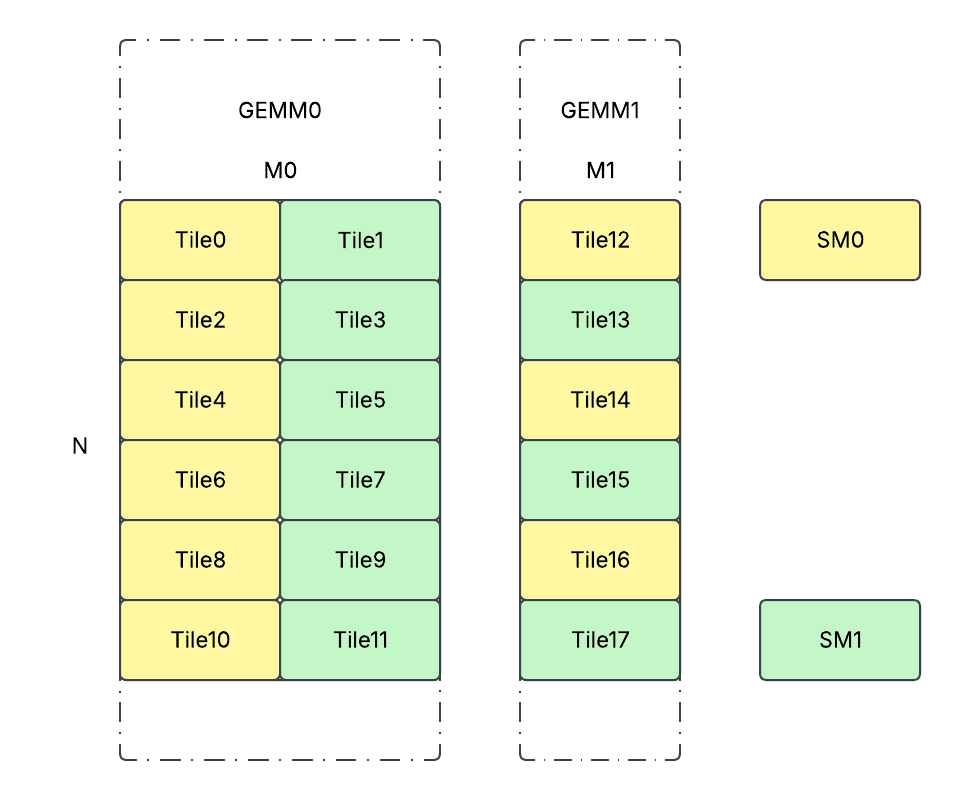
def partition_workload(G: int, Ms: List[int], N: int):
partitions = []
for g in range(G):
for n in range(0, N, BLOCK_N):
for m in range(0, Ms[g], BLOCK_M):
partitions.append((g, m, n))
paritions_per_cta = [[] for _ in NUM_SMS]
for i, part in enumerate(partitions):
paritions_per_cta[i % NUM_SMS].append(part)
分区在运行时在设备端动态计算,开销很小。但是,通过这样做,我们可以实现
- 不同 SM 之间工作负载均衡。
- 启动开销小,因为每个 SM 只会启动 1 个 CTA。
- L2 缓存命中率高。工作负载分区的顺序确保权重/激活很可能只从 HBM 加载一次并缓存到 L2。因为来自不同 SM 的相同权重/激活瓦片的使用几乎总是并发/连续发生的。
具有 Warp Specialization 的持久内核
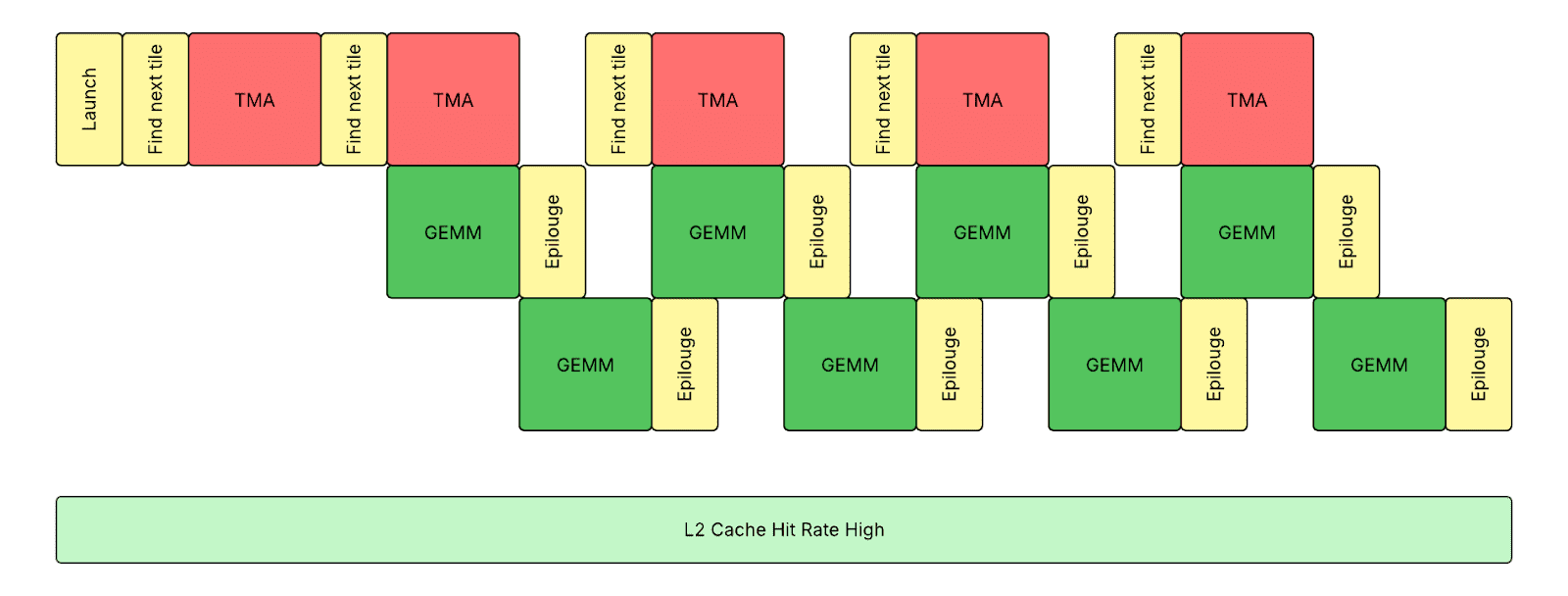
我们采用基于主机端张量映射的激活和权重加载,以及可选的基于设备端张量映射的输出存储,以减少 Hopper GPU 上的内存传输开销。通过连续存储格式的激活,我们可以使用单个主机端 TMA(张量内存加速器)描述符加载激活并屏蔽掉属于其他 token 的 token。但是,我们需要创建多个设备端 TMA 描述符来存储输出,而不支持动态屏蔽。
我们采用了基于 warp specialization 的内核设计,使内核以真正的持久方式运行,每个 SM 在 3 个 warp 组(1 个生产者和 2 个消费者)之间切换。这种设计使 TMA 引擎、Tensor Core 和 CUDA Core 执行相互重叠,利用异步 TMA 指令和 WGMMA(异步 Warpgroup 级别矩阵乘累加)指令以及共享内存上的内存屏障。我们得到了 Meta Triton 编译器团队的巨大帮助才得以实现。只有通过 warp specialization 才能隐藏序言和跋语,因为传统的软件流水线方法无法处理带有指针追逐的复杂控制流。
IndexShuffling
我们实现了基于 CUDA / HIP 的索引洗牌内核。
接口
def index_shuffling(
scores: torch.Tensor, # shape: [T, E]
):
token_counts: torch.Tensor = ... # shape: [E]
expert_indices: torch.Tensor = ... # shape: [T]
token_indices: torch.Tensor = ... # shape: [T]
return token_counts, expert_indices, token_indices
内核获取所有 token 在所有专家上的路由分数,找出每个 token 路由到的特定专家,重新排序 token 索引,使所有路由到同一专家的 token 连续放置,并返回:
- `token_counts`:每个专家路由到的 token 数量。它将作为输入提供给上面讨论的 GroupedGEMM 内核。
- `expert_indices`:每个洗牌 token 所属的专家索引。它将作为输入提供给上面讨论的 GatherMul 内核。
- `token_indices`:每个洗牌 token 所属的原始 token 索引。它将作为输入提供给上面讨论的 GatherMul 和 ScatterAdd 内核。
协同内核
我们采用了协同内核设计,将内核分为两个主要阶段:top-k 归约阶段和桶排序阶段,中间有一个全局同步。
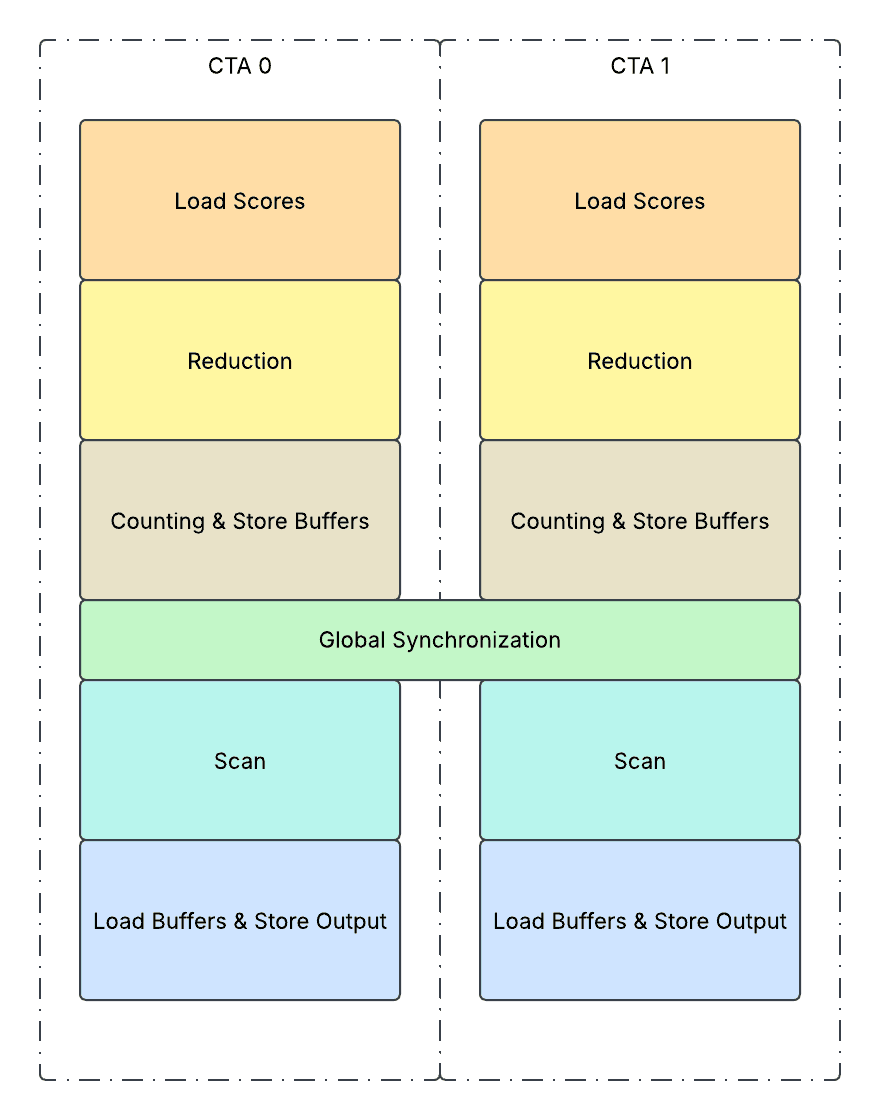
- 1. 加载分数:
- 它将路由分数瓦片从全局内存 (HBM) 加载到共享内存 (SMEM),并将其相关的专家索引一起存储在 SMEM 上。
- 2. 归约:
- 在 SMEM 上沿 E 维度执行 TopK 归约。对于 Llama 4 用例,它执行 ArgMax 排序作为 Top1 归约,其中包括在 SMEM 上对分数和相关专家索引执行 2D 并行树归约。在不同的树归约阶段之间,
- 所有线程将并发地处理 SMEM 上多个 token 的归约。
- 每个线程将顺序地处理 SMEM 上多个 token 的归约。
- 在 SMEM 上沿 E 维度执行 TopK 归约。对于 Llama 4 用例,它执行 ArgMax 排序作为 Top1 归约,其中包括在 SMEM 上对分数和相关专家索引执行 2D 并行树归约。在不同的树归约阶段之间,
- 3. 计数与存储缓冲区:
- 它迭代瓦片上的所有 token,从 SMEM 获取选定的专家索引,将其存储到 HBM 上的缓冲区 (`buf_expert_index`),并对 HBM 上的输出计数器 (`token_counts`) 执行 `atomicAdd` 操作。
- 有趣的是,`atomicAdd` 操作将返回内存位置上先前的值,这表示 token 在组中的位置,我们将把这个值存储在一个缓冲区 (`buf_local_token_index`) 中,并用它来确定所有 token 的全局顺序。
- 重复 1-3 迭代,直到处理完分配给 CTA 的所有 token。
- 4. 全局同步:
- 它对 HBM 上的全局计数器执行 `atomicAdd` 操作。之后,所有 CTA 将等待全局计数器达到 token 总数,并通过 `st.release` + `ld.acquire` 屏障保护前面的存储操作和后面的加载操作,以确保正确性。
- 5. 扫描:
- 它执行简单的加载和 `token_counts` 的前缀和,并将其转换为 SMEM 上的 `token_counts_cumsums`。
- 6. 加载缓冲区并存储输出:
- 它迭代分配给此 CTA 的所有 token。对于每个 token,它从 `buf_expert_index` 加载 token 所分配的专家索引,然后计算洗牌后的新 token 索引,作为以下各项的总和:
- 它之前属于先前专家的 token 数量,使用 SMEM 张量 `token_counts_cumsums`。
- 它之前属于同一专家的 token 数量,使用 HBM 张量 `buf_local_token_index`。
- 之后,它只需在洗牌后的新 token 索引处直接存储 `expert_indices` 和 `token_indices` 输出。
- 它迭代分配给此 CTA 的所有 token。对于每个 token,它从 `buf_expert_index` 加载 token 所分配的专家索引,然后计算洗牌后的新 token 索引,作为以下各项的总和:
性能
示例内核性能
我们的设置使用 H100 80GB SMX5 HBM3 700W SKU、Python 3.12 和 CUDA 12.8。单个 H100 的理论峰值 HBM 内存带宽为 3.35 TB/s。
GroupedGEMM
预填充性能
下表显示了 Llama 4 Scout 和 Maverick 单主机服务上内核的预填充性能。实验设置假定总 token 数为 16,384,并进行张量并行分片。
| 精度 | G | M | N | K | 时间
(微秒) |
计算
(TFlops) |
内存
(GB/s) |
| BF16 | 16 | 1,024 | 2,048 | 5,120 | 523.85 | 655.90 | 1,088.90 |
| BF16 | 16 | 1,024 | 5,120 | 1,024 | 294.95 | 582.46 | 1,251.39 |
| BF16 | 128 | 128 | 2,048 | 5,120 | 975.41 | 352.26 | 2,992.82 |
| BF16 | 128 | 128 | 5,120 | 1,024 | 510.78 | 336.35 | 3,021.86 |
| FP8 | 16 | 1,024 | 2,048 | 5,120 | 286.89 | 1,197.64 | 1,111.10 |
| FP8 | 16 | 1,024 | 5,120 | 1,024 | 182.41 | 941.83 | 1,471.62 |
| FP8 | 128 | 128 | 2,048 | 5,120 | 517.16 | 664.40 | 2,887.28 |
| FP8 | 128 | 128 | 5,120 | 1,024 | 290.25 | 591.90 | 2,947.93 |
注:G 表示组数。M 表示每组的 token 数。N 表示每组的输出特征维度。K 表示每组的输入特征维度。FP8 表示带快速累加的 FP8 行向缩放(激活按 token 缩放,权重按通道缩放)。基准测试中不包含量化内核。内存带宽计算中不包含缩放。使用旋转缓冲区和 CUDAGraph 进行基准测试。
解码性能
下表显示了 Llama 4 Scout 和 Maverick 单主机服务上内核的解码性能。实验设置假定总 token 数为 128,并进行张量并行分片。
| 精度 | G | M | N | K | 时间
(微秒) |
计算
(TFlops) |
内存
(GB/s) |
| BF16 | 16 | 8 | 2,048 | 5,120 | 112.54 | 23.85 | 2,997.82 |
| BF16 | 16 | 8 | 5,120 | 1,024 | 60.00 | 22.37 | 2,822.50 |
| BF16 | 128 | 1 | 2,048 | 5,120 | 861.22 | 3.12 | 3,119.07 |
| BF16 | 128 | 1 | 5,120 | 1,024 | 433.15 | 3.10 | 3,102.26 |
| FP8 | 16 | 8 | 2,048 | 5,120 | 59.81 | 44.88 | 2,824.60 |
| FP8 | 16 | 8 | 5,120 | 1,024 | 34.86 | 38.50 | 2,447.64 |
| FP8 | 128 | 1 | 2,048 | 5,120 | 440.53 | 6.09 | 3,049.44 |
| FP8 | 128 | 1 | 5,120 | 1,024 | 225.14 | 5.96 | 2,987.15 |
IndexShuffling
下表显示了 Llama 4 Scout 和 Maverick 单主机服务上内核的性能,并与原生 PyTorch 实现进行了比较。
| Token 数量 | 专家数量 | IndexShuffling (微秒) | 未融合操作 (微秒) | 加速比 |
| 128 | 16 | 5.08 | 36.71 | 722.53% |
| 128 | 128 | 8.95 | 34.36 | 384.05% |
| 2048 | 16 | 7.06 | 57.10 | 808.51% |
| 2048 | 128 | 13.53 | 69.84 | 516.18% |
| 4096 | 16 | 7.42 | 68.96 | 929.98% |
| 4096 | 128 | 18.89 | 87.46 | 463.09% |
| 8192 | 16 | 9.26 | 123.94 | 1339.16% |
| 8192 | 128 | 30.56 | 165.21 | 540.71% |
注:使用旋转缓冲区和 CUDAGraph 进行基准测试。
示例跟踪分析
Llama 4 Scout BF16 解码
以下是使用我们的 MetaShuffling MoE 推理解决方案对 64 个 token 的 Llama 4 Scout BF16 进行解码的示例跟踪。
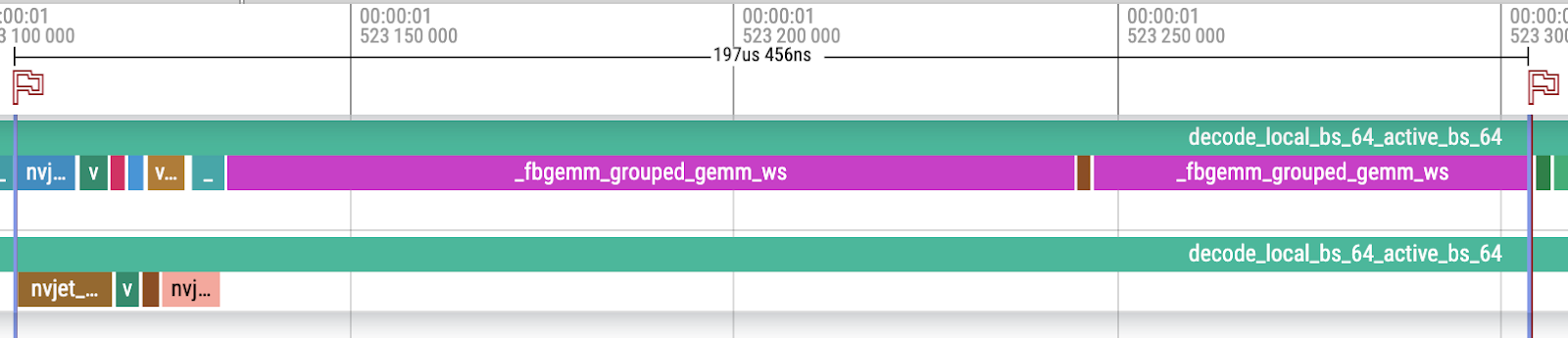
- MoE 的总内存流量为(忽略激活)
- 路由器:5120x16x2 = 163,840 字节
- 共享专家:(2048×5120 + 5120×1024)x2 = 31,457,280 字节
- 路由专家:16x(2048×5120 + 5120×1024)x2 = 503,316,480 字节
- 总计:163,840 + 31,457,280 + 503,316,480 = 534,937,600 字节
- MoE 的总执行时间为 197.456us。实现的内存带宽为 534,937,600 / (197.456 * 10^-6) = 2,709,148,367,231 字节/秒 ≈ 2.71 TB/s,达到 H100 80GB SMX5 HBM3 理论峰值 HBM 内存带宽 3.35 TB/s 的 80.90%。
以下是跟踪中不同组件的细分。

首先是路由和共享专家的细分。这两个组件在 2 个不同的流上并发运行,以实现更好的资源利用。
对于路由器流(红色框标记)
- 1. 路由器 GEMM:基于 CuBLAS 的 GEMM,采用 split-k 设计。它启动 2 个内核,第二个内核是归约内核。
- 2. Sigmoid(路由器激活):PyTorch 原生 Sigmoid。
- 3. IndexShuffling:基于 FBGEMM 的索引洗牌,采用协同内核设计。它可以看作是 topk、bincount 和 sort 三个操作的融合。它启动 2 个内核,第一个内核是设置内核。
- 4. GatherMul:基于 FBGEMM 的 gather 缩放。它可以看作是 gather(token)、gather(分数)和 mul 三个操作的融合。
对于共享专家流(橙色框标记)
- 5. SharedExpert GEMM13:基于 CuBLAS 的 GEMM,采用 split-k 设计。它启动 2 个内核,第二个内核是归约内核。
- 6. SwiGLU:融合的 SwiGLU。它可以看作是 sigmoid 和 mul 两个操作的融合。
- 7. SharedExpert GEMM2:基于 CuBLAS 的 GEMM。

其次是路由专家的细分。此组件在 1 个流上独占运行,以使 GroupedGEMM 内核完全拥有所有 SM。
对于路由专家流(红色框标记)
- 8. RoutedExperts GroupedGEMM13:基于 FBGEMM 的 GroupedGEMM,采用持久内核设计。
- 9. SwiGLU:融合的 SwiGLU。如 6 中所述。
- 10. RoutedExperts GroupedGEMM2:基于 FBGEMM 的 GroupedGEMM,采用持久内核设计,在跋语中融合了 scatter add。
解码步骤在带静态形状的密集张量上使用 CUDAGraph 运行。
Llama 4 Maverick FP8 预填充
以下是使用我们的 MetaShuffling MoE 推理解决方案对 5000 个 token 的 Llama 4 Maverick FP8 进行预填充的示例跟踪。请注意,路由专家使用 FP8 行向缩放,路由器和共享专家使用 BF16。

与解码跟踪相比
- 它使用单个流来避免内核在路由器和共享专家之间交互。由于内核在足够大的问题规模上工作,可以使计算资源饱和,因此额外的重叠只会导致争用,尤其是在 L2 缓存上。
- 它在具有静态形状的密集张量上运行,但处于 eager 模式。由于内核执行时间足够长且没有设备/主机同步,因此内核可以背靠背启动而不会产生气泡。
这里我们重点介绍这两个跟踪之间除了执行时间之外的内核差异。
- 路由器 GEMM 和 SharedExpertGEMM13:基于 CuBLAS 的 GEMM,不使用 split-k 设计。因此它启动 1 个内核而不是 2 个。
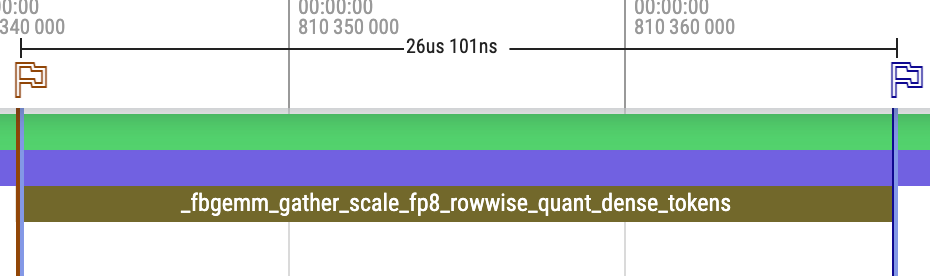
- 4. GatherMul (FP8 行向量化):基于 FBGEMM 的 gather 缩放和量化。它可以看作是 8 个操作的融合:gather(token)、gather(分数)、mul、max、divide、mul、clamp 和 typecast。
- 9. SwiGLU (FP8 行向量化):融合的 SwiGLU 和量化。 它可以看作是 7 个操作的融合:sigmoid 和 mul、max、divide、mul、clamp 和 typecast。

总结
我们逐步采取以下措施来优化 MoE 解决方案的推理性能
-
- 通过避免主机和设备同步来提高设备级利用率。
- 通过移除填充或避免处理填充来减少资源浪费。
- 通过积极的内核融合来减少内核启动和 I/O 开销。
- 通过各种内核优化来提高计算和内存效率,将性能推向硬件极限。
- 通过并发执行计算、内存流量或网络流量密集型内核来提高硬件组件级利用率,同时避免不良争用。
单主机服务
我们使用 1000 个随机提示请求对 Llama 4 Maverick 和 Llama 4 Scout 的单主机服务性能进行了基准测试,使用我们内部的 MetaShuffling-MoE 推理堆栈。我们在 8xH100 主机上运行 Maverick(FP8)和 Scout(BF16),最大批处理大小为 64。我们的设置使用了 H100 80GB SMX5 HBM3 700W SKU、Python 3.12 和 CUDA 12.8。我们已将 MetaShuffling MoE 推理堆栈中使用的所有计算内核开源到 FBGEMM,并提供了 一个 MetaShuffling 的示例实现作为参考。
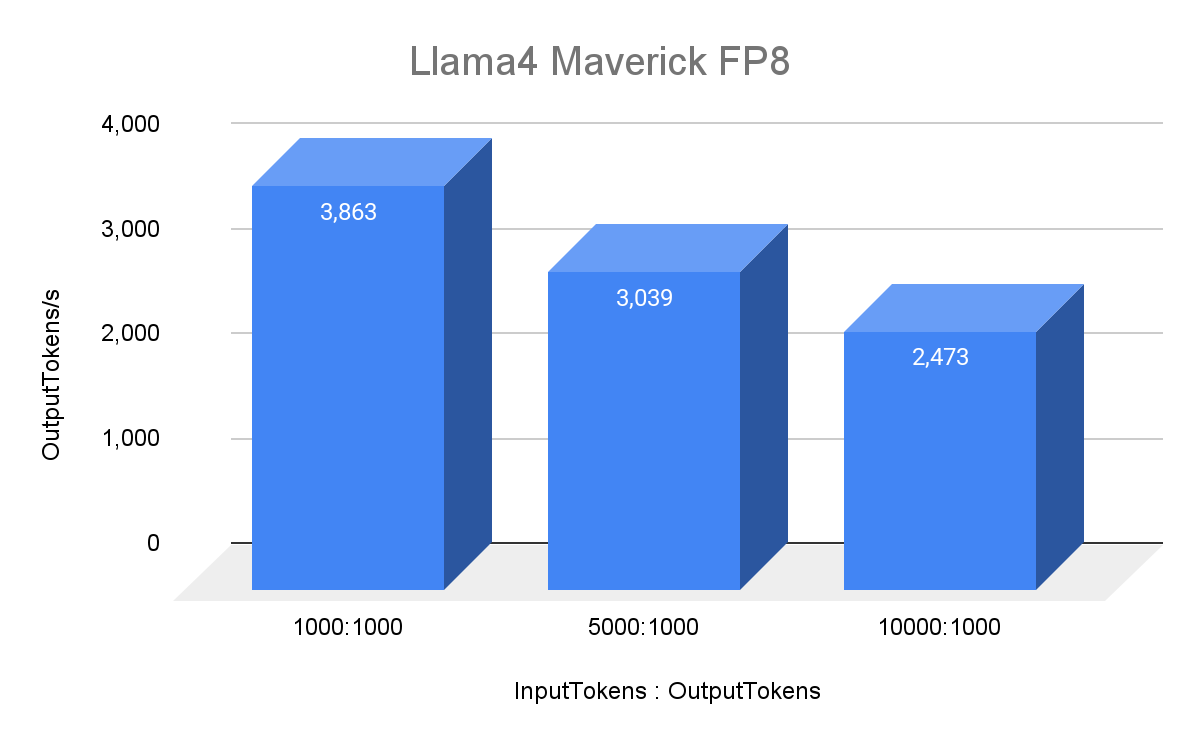
为了保持最佳精度,我们使用 FP8 精度对路由专家上的 Llama 4 Maverick 进行了基准测试。注意力线性层、注意力、共享专家、路由器和 KV 缓存均使用 BF16 精度。
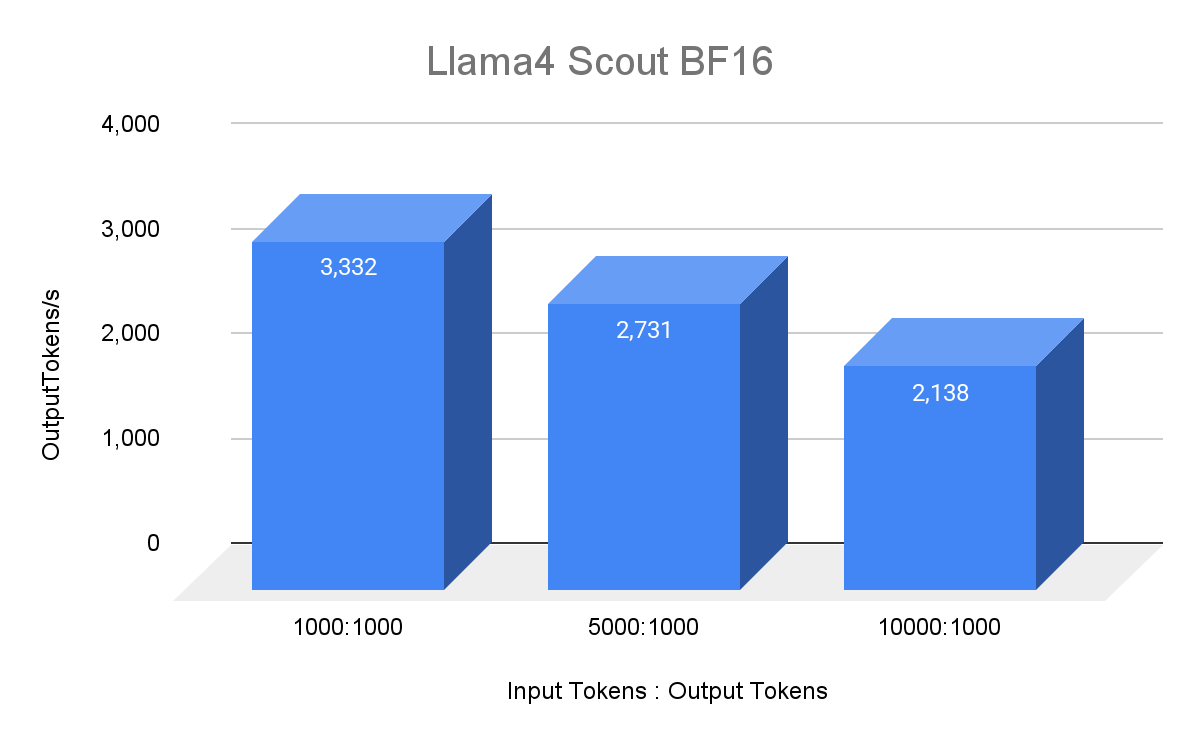
我们使用 BF16 精度对所有线性层(注意力线性层、共享专家、路由器和路由专家)、注意力以及 KV 缓存上的 Llama 4 Scout 进行了基准测试。
最后,我们希望社区能够不断打破记录,提高 Llama 4 模型服务的效率,并期待报告更好的数据。
致谢
我们要感谢 Jing Zhang、Ying Zhang 和 Manman Ren 提供的技术评审和指导。
我们还要感谢 Bradley Davis、Yan Cui、Rengan Xu、Josh Fromm、Jiawen Liu、Sarunya Pumma、Jie Wang、Xinfeng Xie、Benson Ma、Michael Shu、Bingzhe Liu、Jingyi Yang、Min Si、Pavan Balaji、Dhruva Kaushal 对本项目做出的贡献。