在这篇博客中,我们展示了 FSDP 在预训练示例中的可扩展性,一个针对 2T 令牌进行训练的 7B 模型,并分享了我们用于实现 3,700 令牌/秒/GPU 的快速训练速度(或在 128 个 A100 GPU 上每天 40B 令牌)的各种技术。这相当于 57% 的模型 FLOPs 利用率 (MFU) 和硬件 FLOPs 利用率 (HFU)。此外,我们观察到 FSDP 近乎线性扩展到 512 个 GPU,这意味着使用这种方法在 512 个 GPU 上训练一个 7B 模型到 2T 令牌只需不到两周的时间。
IBM 研究人员训练了一个 Meta Llama 2 7B 架构,针对 2T 令牌,我们将其称为 LlamaT(est)。该模型在各种学术基准测试中表现出与 Llama 2 相当的模型质量。所有训练代码以及我们实现此吞吐量的方法都可以在此博客中找到。我们还分享了适用于 A100 和 H100 的 Llama 2 模型(7B、13B、34B 和 70B)的配置参数。
在此过程中,我们还提出了一种适用于 FSDP 的_新的_选择性激活检查点机制,它在开箱即用 FSDP 的基础上提供了 10% 的提升。我们已经开源了训练代码库以及相关的可扩展数据加载器,作为实现此吞吐量的方法。
PyTorch 原生训练路径的一个主要优势是能够无缝地在多个硬件后端上进行训练。例如,AllenAI 通过 OLMo 发布的最新端到端训练堆栈也利用 PyTorch FSDP 在 AMD 和 NVIDIA GPU 上进行训练。我们从 FSDP 中利用了三个主要组件来实现我们的吞吐量:
- SDPA Flash attention,可实现融合注意力内核和高效注意力计算
- 计算与通信的重叠,可以更好地利用 GPU
- 选择性激活检查点,使我们能够在 GPU 内存和计算之间进行权衡
IBM 在PyTorch FSDP上与 Meta PyTorch 团队密切合作了近两年:引入速率限制器以在以太网互连上实现更好的吞吐量,分布式检查点将检查点时间提高了一个数量级,并为 FSDP 的混合分片模式实现了早期版本的检查点。去年底,我们使用 FSDP 对一个模型进行了端到端训练。
训练详情
7B 模型在 128 个 A100 GPU 上训练,具有 400Gbps 网络连接和 GPU Direct RDMA。我们使用 SDPA FlashAttention v2 进行注意力计算,对于这个模型,我们关闭了限制批处理大小但提供最高吞吐量的激活检查点——对于 128 个 GPU,每个批次的批处理大小为 100 万个令牌,与激活检查点相比,吞吐量提高了约 10%。通过这些参数,我们实现了计算和通信的几乎完全重叠。我们使用 32 位 AdamW 优化器,beta1 为 0.9,beta2 为 0.95,权重衰减为 0.1,学习率以 3e-5 结束,预热到最大学习率 3e-4,并采用余弦调度在 2T 令牌上降低到 3e-5。训练使用混合精度 bf16 在内部数据集上进行。训练堆栈使用 IBM 的基础模型堆栈用于模型架构,以及 PyTorch 2.2 发布后的 nightly 版本用于 FSDP 和 SDPA。我们在 2023 年 11 月至 2024 年 2 月期间尝试了几种不同的 nightly 版本,并观察到吞吐量的改善。
选择性激活检查点
我们共同实现了一种简单有效的选择性激活检查点 (AC) 机制。在 FSDP 中,常见的做法是检查点每个 Transformer 块。一个简单的扩展是每_n_个块检查点一次,以减少重新计算量,同时增加所需的内存。这对于 13B 模型大小非常有效,吞吐量增加了 10%。对于 7B 模型大小,我们根本不需要激活检查点。FSDP 的未来版本将提供操作符级别的选择性激活检查点,从而实现计算-内存的最佳权衡。上述代码的实现可以在这里找到。
吞吐量和 MFU、HFU 计算
虽然我们只训练了 7B 模型到 2T 令牌,但我们对其他模型大小进行了大量实验,以提供最佳配置选项。下表总结了两种基础设施类型——具有 128 个 GPU 和 400Gbps 节点间互连的 A100 集群,以及具有 96 个 GPU 和 800Gbps 节点间互连的 H100 集群。
| 模型大小 | 批次大小 | 激活检查点 | 吞吐量令牌/秒/GPU(A100 80GB 和 400Gbps 互连) | MFU % (A100 80GB) | HFU % (A100 80GB) | 吞吐量令牌/秒/GPU(H100 80GB 和 800Gbps 互连) | MFU % (H100 80GB) | HFU % (H100 80GB) |
| 7B | 2 | 否 | 3700 | 0.57 | 0.57 | 7500 | 0.37 | 0.37 |
| 13B | 2 | 选择性 | 1800 | 0.51 | 0.59 | 3800 | 0.35 | 0.40 |
| 34B | 2 | 是 | 700 | 0.47 | 0.64 | 1550 | 0.32 | 0.44 |
| 70B | 2 | 是 | 370 | 0.50 | 0.67 | 800 | 0.34 | 0.45 |
表 1:各种模型大小在 A100 和 H100 GPU 上的模型和硬件 FLOPS 利用率
HFU 数字使用PyTorch FLOP 计算器和 A100 和 H100 GPU 的理论 bf16 性能计算,而 MFU 数字使用NanoGPT和PaLM 论文中概述的方法计算。我们还注意到,对于较大的模型,我们有意将每个 GPU 的批处理大小保持在 2,以模仿训练 4k 序列长度模型时所做的选择,并在不超过 4M 令牌的流行批处理大小的情况下,在多达 512 个 GPU 上实现这一点。超出此范围,我们将需要张量并行或序列并行。
我们注意到上表中,对于 A100,激活重新计算会导致 MFU 降低,而 HFU 增加!随着更好的激活检查点方案的引入,我们期望 MFU 能够增加并赶上 HFU。然而,我们观察到对于 H100,MFU 和 HFU 都相对较低。我们分析了 H100 上的 PyTorch 配置文件跟踪,并观察到由于网络“窥探”而导致 10% 的差距。此外,我们推测 H100 的 HBM 带宽是导致 H100 上 HFU/MFU 降低的原因,并且无法获得 3 倍的改进(H100 在理论上比 A100 快 3 倍——312 vs 989TFLOPS,但 HBM 带宽仅为 A100 的不到 2 倍——2.0 vs 3.35TBps)。我们计划尝试其他配置选项,如张量并行,以改进 H100 上 70B 模型的参数。
模型详情
训练的损失曲线如下图所示。
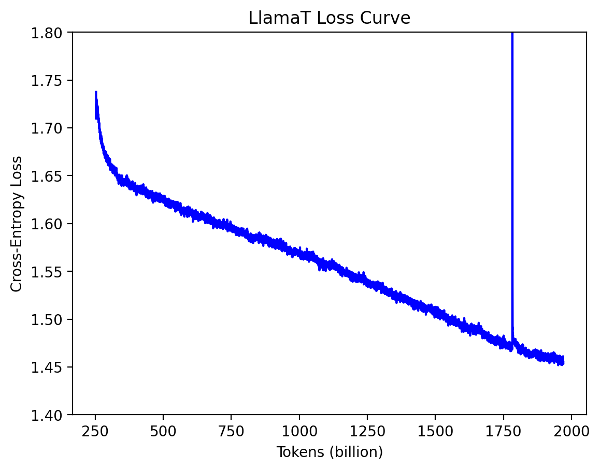
图 1:LlamaT 训练损失曲线
2T 检查点通过存储库中提供的脚本转换为 Hugging Face 格式,然后我们使用lm-evaluation-harness计算关键学术基准,并将其与在 Llama2-7B 上运行的结果进行比较。这些结果已捕获在下表中。
| 评估指标 | Llama2-7B (基线) | LlamaT-7B |
| MMLU (零样本) | 0.41 | 0.43 |
| MMLU (5 样本加权平均) | 0.47 | 0.50 |
| Arc challenge | 0.46 | 0.44 |
| Arc easy | 0.74 | 0.71 |
| Boolq | 0.78 | 0.76 |
| Copa | 0.87 | 0.83 |
| Hellaswag | 0.76 | 0.74 |
| Openbookqa | 0.44 | 0.42 |
| Piqa | 0.79 | 0.79 |
| Sciq | 0.91 | 0.91 |
| Winogrande | 0.69 | 0.67 |
| Truthfulqa | 0.39 | 0.39 |
| GSM8k (8 样本) | 0.13 | 0.11 |
表 1:LM 评估 harness 分数
我们观察到该模型与 Llama2 竞争激烈(粗体字表示更好)。
训练历程
训练稳定,没有崩溃,尽管我们确实遇到了一些小问题
0-200B 令牌:我们观察到迭代时间(执行一个训练步骤所需的时间)变慢。我们停止了作业以确保数据加载器没有导致任何减速,并且检查点性能良好且准确。我们没有发现任何问题。此时,PyTorch 中已经提供了 HSDP 检查点代码,我们借此机会切换到 PyTorch 检查点代码。
200B 令牌-1.9T:我们在 12 月底没有对作业进行任何手动干预。当我们 1 月初回来时,磁盘空间已超出限制,检查点无法写入,尽管训练作业仍在继续。最后一个已知检查点是 1.5T。
1.5T-1.7T:我们使用 lm-evaluation-harness 评估了 1.5T 检查点,发现由于 Hugging Face 分词器引入了分隔符令牌,并且我们的数据加载器也附加了它自己的文档分隔符,模型在两个文档之间多训练了一个特殊令牌。我们修改了数据加载器以消除额外的特殊令牌,并从 1.7T 令牌开始使用修改后的数据加载器继续训练。
1.7T-2T:由于特殊令牌的改变,损失最初飙升,但很快在几十亿个令牌内恢复。训练在没有任何其他手动干预的情况下完成!
主要收获和更高的速度
我们展示了如何使用 FSDP 训练一个模型到 2T 令牌,性能出色,达到 3700 令牌/秒/GPU,并生成了一个高质量模型。作为此项工作的一部分,我们开源了所有训练代码和实现此吞吐量的参数。这些参数不仅可以用于大规模运行,还可以用于小规模微调运行。您可以在这里找到代码。
FSDP API 以 PyTorch 原生方式实现了ZeRO算法,并允许对大型模型进行微调和训练。过去,我们已经看到了 FSDP 的验证点(Stanford Alpaca、Hugging Face、Llama 2 recipes),它们使用简单的训练循环对各种 LLM(如 Meta Llama 2 7B 到 70B Llama)进行微调,并实现了良好的吞吐量和训练时间。
最后,我们注意到有几个可以加速训练的杠杆:
- 节点优化,可以加速特定操作(例如,使用 Flash Attention V2 进行注意力计算)
- 图优化(例如,融合内核,torch.compile)
- 计算-通信重叠
- 激活重新计算
我们在这篇博客中利用了 1、3 和 4 的一个变体,并正在与 Meta PyTorch 团队密切合作,以获取 torch.compile (2) 以及具有每个操作符选择性激活重新计算的更高级版本 4。我们计划分享一个简单的格式化代码和示例数据,以便摄取到我们的数据加载器中,从而使其他人能够使用该代码库进行模型训练。
致谢
有几个团队参与了实现这一验证点,我们要感谢 Meta 和 IBM 的各个团队。特别地,我们向 PyTorch 分布式团队、Facebook Research 和 Applied AI 团队表示感谢,他们构建了FSDP API并根据我们的反馈进行了增强。我们还要感谢 IBM Research 的数据团队,他们策划了本次练习中使用的数据语料库,以及 IBM Research 的基础设施团队(特别是 Claudia Misale、Shweta Salaria 和 Seetharami Seelam),他们优化了 NCCL 和网络配置。通过构建和利用所有这些组件,我们成功地展示了 LlamaT 的验证点。
选择性激活检查点由 IBM 的 Linsong Chu、Davis Wertheimer、Mudhakar Srivatsa 和 Raghu Ganti 构思,并由 Meta 的 Less Wright 实现。
特别感谢Stas Bekman和Minjia Zhang,他们提供了大量的反馈并帮助改进了这篇博客。他们的见解对于突出训练优化的关键方面和探索进一步的增强至关重要。
附录
通信计算重叠
在多节点设置中训练的另一个关键方面是能够重叠通信和计算。在 FSDP 中,有多种重叠的机会——在正向传播的 FSDP 单元收集阶段以及反向传播计算期间。在正向传播期间重叠收集,同时计算前一个单元,以及在反向计算期间重叠下一个单元的收集和梯度分散,有助于将 GPU 利用率提高近 2 倍。我们将在 400Gbps 网络互连和 A100 80GB GPU 上说明这一点。在 HSDP 的情况下,正向传播的预取阶段没有节点间流量,重叠仅用于反向梯度计算阶段。当然,HSDP 只有在模型可以在单个节点内分片时才可行,这将模型大小限制在约 30B 参数左右。
下图显示了 FSDP 中的三个步骤,底部是节点之间的通信,图像下半部分的顶部是计算流。对于没有激活重新计算的 7B 模型,我们观察到重叠是完整的。实际上,可实现的重叠百分比为 90%,因为正向传播的第一个块和反向传播的最后一个块无法重叠。

下面显示了上述三步过程的单个步骤的放大视图。我们可以清楚地看到计算和通信的粒度以及它们如何以交错的方式重叠。
