美国等发达国家的道路每年变化高达15%,Mapillary 通过将来自任何摄像机的图像组合成一个世界的 3D 可视化,满足了对地图保持更新日益增长的需求。Mapillary 独立且协作的方法使任何人都可以收集、共享和使用街道级别图像,以改进地图、发展城市和推动汽车行业。
如今,世界各地的人们和组织已为 Mapillary 的使命贡献了超过6亿张图像,即通过图像帮助人们了解世界各地,并提供这些数据,其客户和合作伙伴包括世界银行、HERE 和丰田研究院。
Mapillary 的计算机视觉技术以前所未有的方式为地图带来了智能,增加了我们对世界的整体理解。 Mapillary 对所有图像进行最先进的语义图像分析和基于图像的 3D 建模。在这篇文章中,我们将讨论 Mapillary Research 的两项最新工作及其在 PyTorch 中的实现——无缝场景分割 [1] 和原地激活 BatchNorm [2]——分别生成全景分割结果并在训练期间节省高达 50% 的 GPU 内存。
无缝场景分割
Github 项目页面: https://github.com/mapillary/seamseg/
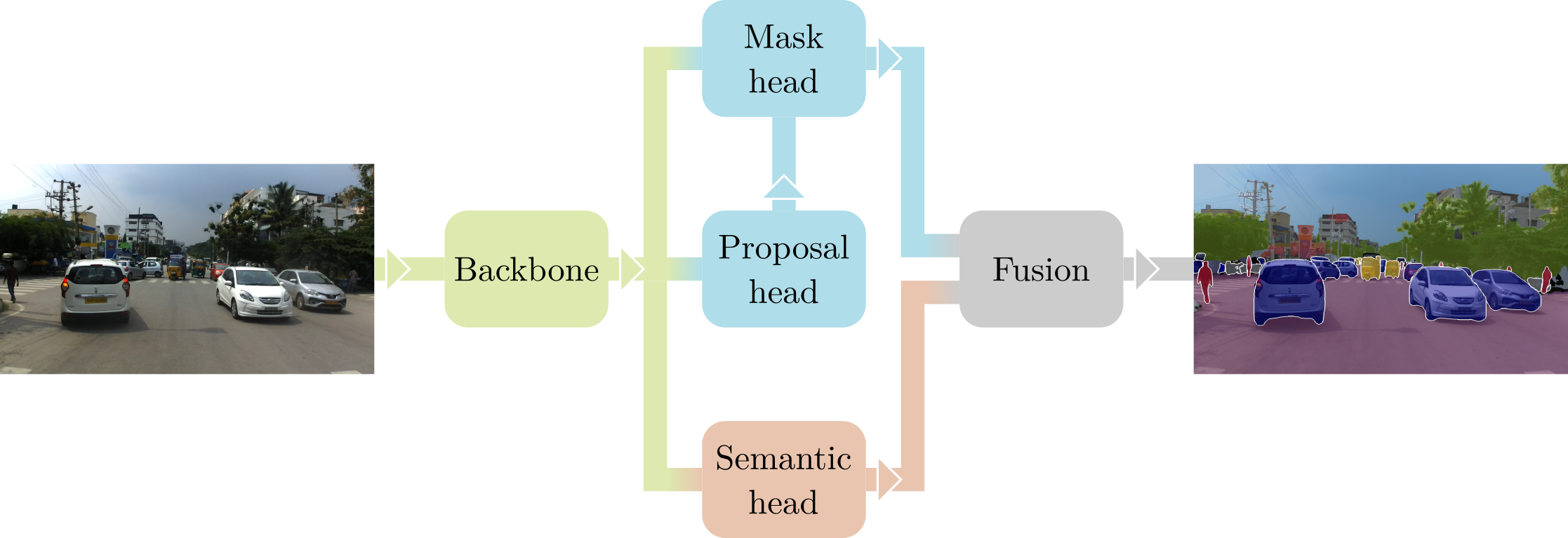
无缝场景分割的目标是从图像中预测“全景”分割 [3],即完整的标签,其中每个像素都分配有一个类别 ID,并且在可能的情况下,分配一个实例 ID。与许多处理实例检测和分割的现代 CNN 一样,我们采用 Mask R-CNN 框架 [4],使用 ResNet50 + FPN [5] 作为主干。该架构分两个阶段工作:首先,“Proposal Head”在图像上选择一组可能包含对象的候选边界框(即提案);然后,“Mask Head”专注于每个提案,预测其类别和分割掩码。此过程的输出是“稀疏”实例分割,仅覆盖图像中包含可计数对象(例如汽车和行人)的部分。
为了完成我们称为无缝场景分割的全景方法,我们在 Mask R-CNN 中添加了第三个阶段。从相同的主干出发,“Semantic Head”对整个图像进行密集语义分割,同时考虑不可数或无定形的类别(例如道路和天空)。Mask 和 Semantic 头的输出最终使用简单的非极大值抑制算法融合,以生成最终的全景预测。有关实际网络架构、使用的损失和底层数学的所有详细信息,请访问我们 CVPR 2019 论文 [1] 的 项目网站。
虽然 Mask R-CNN 的几个版本已公开发布,包括用 Caffe2 编写的 官方实现,但在 Mapillary,我们决定使用 PyTorch 从头开始构建无缝场景分割,以完全控制和理解整个流程。在此过程中,我们遇到了一些主要的绊脚石,并不得不提出一些创造性的变通方法,我们将在下面进行描述。
处理可变大小的张量
使全景分割网络与传统 CNN 区分开来的一点是可变大小数据的普遍性。事实上,我们处理的许多量无法轻易用固定大小的张量表示:每张图像包含不同数量的对象,Proposal head 可以为每张图像生成不同数量的提案,图像本身也可以具有不同的大小。虽然这本身不是问题——可以一次处理一张图像——但我们仍然希望尽可能多地利用批处理级别的并行性。此外,当使用多个 GPU 执行分布式训练时,DistributedDataParallel 期望其输入是批处理的、大小统一的张量。
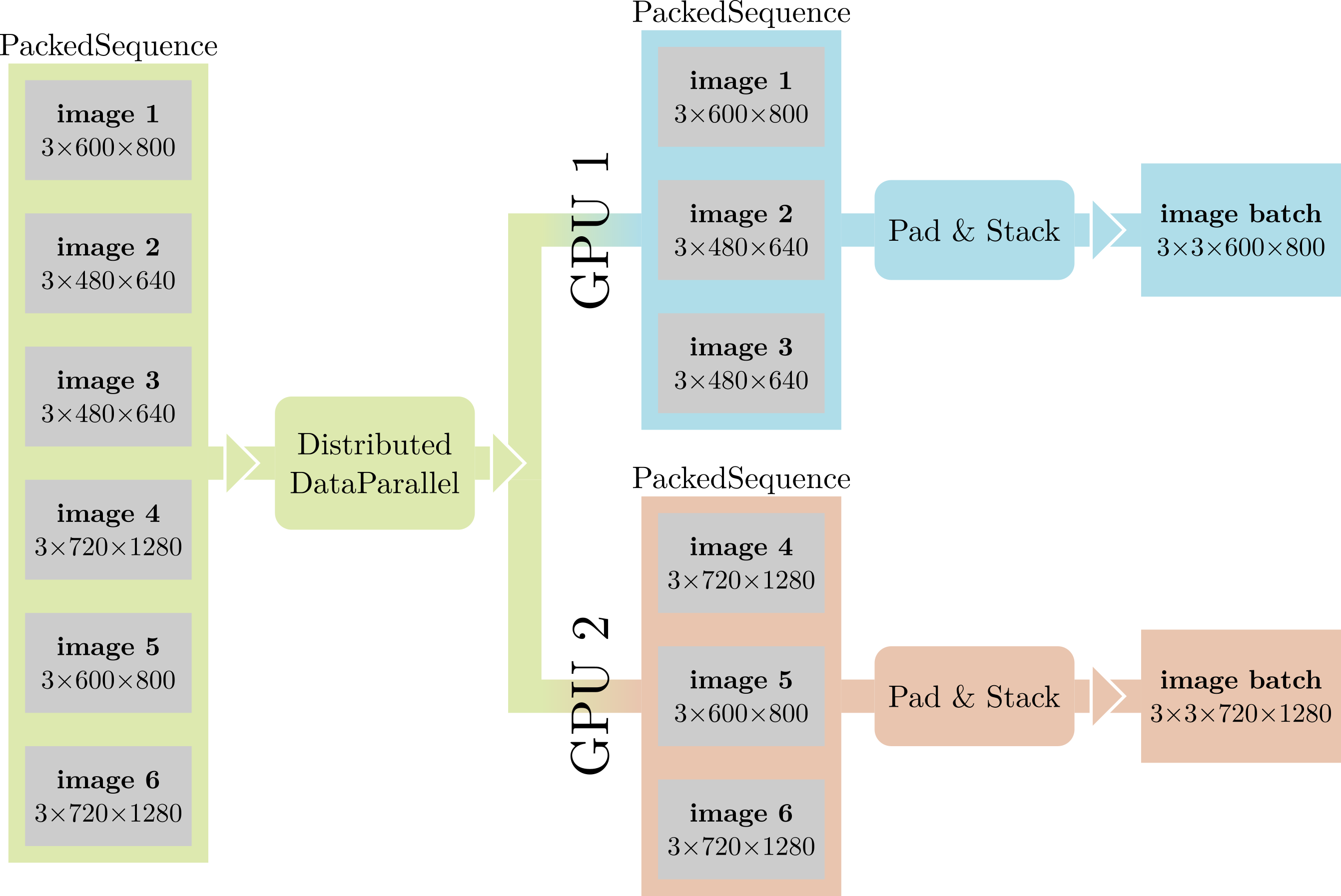
我们解决这些问题的方法是将每个可变大小张量批处理封装在 PackedSequence 中。 PackedSequence 更像是一个用于张量的列表类,它将其内容标记为“相关”,确保它们都具有相同的类型,并提供有用的方法,例如将所有张量移动到特定设备等。当执行轻量级操作时,如果批处理级别并行性不会快很多,我们只需在 for 循环中迭代 PackedSequence 的内容。当性能至关重要时,例如在网络主体中,我们只需连接 PackedSequence 的内容,根据需要添加零填充(就像具有可变长度输入的 RNN 一样),并跟踪每个张量的原始维度。
PackedSequence 也有助于我们解决上面强调的第二个问题。我们稍微修改了 DistributedDataParallel 以识别 PackedSequence 输入,将其分成大小相等的块,并将其内容分发到 GPU。
使用分布式数据并行处理非对称计算图
我们网络的另一个可能更微妙的特点是,它可以在 GPU 之间生成非对称计算图。事实上,构成网络的一些模块是“可选的”,这意味着它们并非总是为所有图像计算。例如,当 Proposal head 不输出任何提案时,Mask head 根本不被遍历。如果我们使用 DistributedDataParallel 在多个 GPU 上进行训练,这将导致其中一个副本不计算 Mask head 参数的梯度。
在 PyTorch 1.1 之前,这会导致崩溃,因此我们不得不开发一个变通方法。我们简单但有效的解决方案是在不需要实际前向传播时计算“伪前向传播”,即类似这样:
def fake_forward():
fake_input = get_correctly_shaped_fake_input()
fake_output = mask_head(fake_input)
fake_loss = fake_output.sum() * 0
return fake_loss
在这里,我们生成一批虚假数据,将其通过 Mask head,并返回一个始终将零反向传播到所有参数的损失。
从 PyTorch 1.1 开始,不再需要此变通方法:通过在构造函数中设置 find_unused_parameters=True,可以告诉 DistributedDataParallel 识别所有副本都未计算梯度的参数并正确处理它们。这大大简化了我们的代码库!
原地激活 BatchNorm
Github 项目页面: https://github.com/mapillary/inplace_abn/
大多数研究人员可能会同意,无论他们的研究实验室能够访问少量还是数千个 GPU,在可用的 GPU 资源方面总是有限制的。在 Mapillary 仍然使用少量且主要是 12GB Titan X 风格的专业消费级 GPU 的时候,我们正在寻找一种解决方案,可以虚拟地增强训练期间可用的内存,以便我们能够在语义分割等密集标签任务上获得并推动最先进的结果。原地激活 BatchNorm 使我们能够使用多达 50% 的内存(计算开销很小),因此它已深度集成到我们目前的所有项目中(包括上面描述的无缝场景分割)。
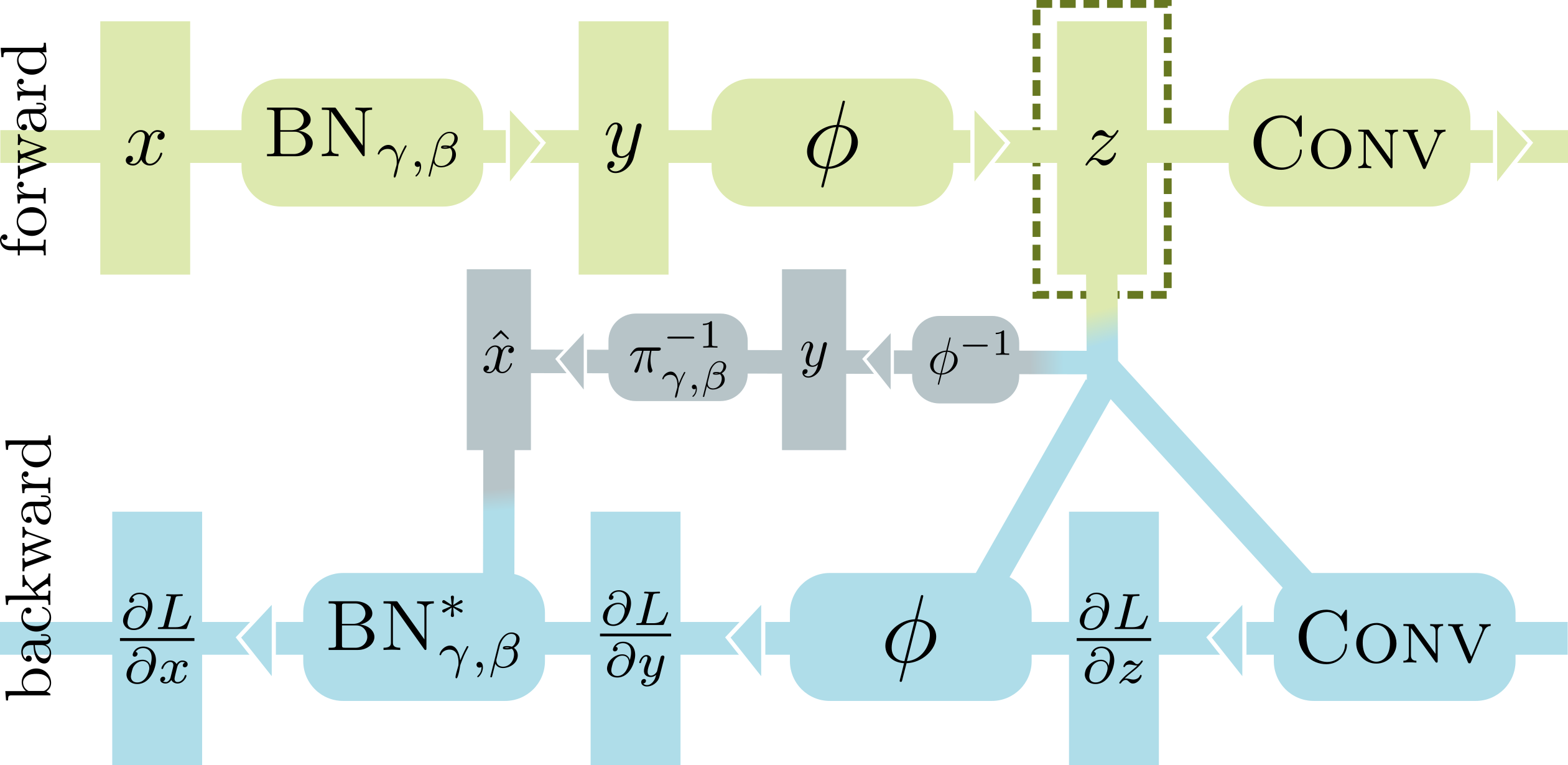
在正向传播中处理 BN-激活-卷积序列时,大多数深度学习框架(包括 PyTorch)需要存储两个大缓冲区,即 BN 的输入 x 和 Conv 的输入 z。这是必要的,因为 BN 和 Conv 的标准反向传播实现依赖于它们的输入来计算梯度。使用 InPlace-ABN 替换 BN-激活序列,我们可以安全地丢弃 x,从而在训练时节省高达 50% 的 GPU 内存。为了实现这一点,我们根据其输出 y 重写了 BN 的反向传播,而 y 又通过反转激活函数从 z 重构。
InPlace-ABN 的唯一限制是它需要使用可逆激活函数,例如 leaky relu 或 elu。除此之外,它可以在任何网络中直接替换 BN+激活模块。我们的原生 CUDA 实现与 PyTorch 的标准 BN 相比计算开销极小,并且可供任何人在此处使用: https://github.com/mapillary/inplace_abn/。
具有非对称图和不平衡批次的同步 BN
当在多个 GPU 和/或多个节点上使用同步 SGD 训练网络时,通常的做法是在每个设备上单独计算 BatchNorm 统计信息。然而,根据我们使用语义和全景分割网络的工作经验,我们发现累积所有 worker 的均值和方差可以大幅提高准确性。当处理小批量时尤其如此,例如在无缝场景分割中,我们每个 GPU 训练一张超高分辨率图像。
InPlace-ABN 支持在多个 GPU 和多个节点上进行同步操作,并且从 1.1 版开始,这也可以在标准 PyTorch 库中使用 SyncBatchNorm 实现。然而,与 SyncBatchNorm 相比,我们支持一些对无缝场景分割特别重要的附加功能:不平衡批次和非对称图。
如前所述,Mask R-CNN 类似的网络自然会产生可变大小的张量。因此,在 InPlace-ABN 中,我们使用 此处 描述的并行算法变体计算同步统计信息,该算法适当地考虑了每个 GPU 可以容纳不同数量样本的事实。PyTorch 的 SyncBatchNorm 目前正在修订以支持此功能,改进后的功能将在未来版本中提供。
非对称图(如上所述)是创建同步 BatchNorm 实现时必须处理的另一个复杂因素。幸运的是,PyTorch 的分布式组功能允许我们将分布式通信限制在 worker 的子集内,轻松排除当前不活动的 worker。唯一缺少的部分是,为了创建一个分布式组,每个进程都需要知道将参与该组的所有进程的 ID,即使不属于该组的进程也需要调用 new_group() 函数。在 InPlace-ABN 中,我们通过这样的函数处理它:
import torch
import torch.distributed as distributed
def active_group(active):
"""Initialize a distributed group where each process can independently decide whether to participate or not"""
world_size = distributed.get_world_size()
rank = distributed.get_rank()
# Gather active status from all workers
active = torch.tensor(rank if active else -1, dtype=torch.long, device=torch.cuda.current_device())
active_workers = torch.empty(world_size, dtype=torch.long, device=torch.cuda.current_device())
distributed.all_gather(list(active_workers.unbind(0)), active)
# Create group
active_workers = [int(i) for i in active_workers.tolist() if i != -1]
group = distributed.new_group(active_workers)
return group
首先,每个进程(包括非活动进程)通过 all_gather 调用将其状态传达给所有其他进程,然后它使用共享信息创建分布式组。在实际实现中,我们还为组添加了缓存机制,因为 new_group() 通常在每个批次调用时开销太大。
参考文献
[1] 无缝场景分割;Lorenzo Porzi, Samuel Rota Bulò, Aleksander Colovic, Peter Kontschieder;计算机视觉与模式识别 (CVPR),2019
[2] 用于 DNN 内存优化训练的原地激活 BatchNorm;Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder;计算机视觉与模式识别 (CVPR),2018
[3] 全景分割;Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, Piotr Dollar;计算机视觉与模式识别 (CVPR),2019
[4] Mask R-CNN;Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick;国际计算机视觉会议 (ICCV),2017
[5] 用于目标检测的特征金字塔网络;Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie;计算机视觉与模式识别 (CVPR),2017