在这篇博客中,我们展示了一个案例研究,使用torchtune的知识蒸馏配方将Llama 3.1 8B模型蒸馏为Llama 3.2 1B。我们演示了知识蒸馏(KD)如何在训练后用于改进指令遵循任务的性能,并展示了用户如何利用该配方。
什么是知识蒸馏?
知识蒸馏是一种广泛使用的压缩技术,它将知识从一个更大的(教师)模型转移到一个更小的(学生)模型。更大的模型具有更多的参数和知识容量,然而,这种更大的容量在部署时也更昂贵。知识蒸馏可用于将更大模型的知识压缩到更小的模型中。其思想是,通过从更大模型的输出中学习,可以提高更小模型的性能。
知识蒸馏如何工作?
通过在迁移集上进行训练,将知识从教师模型转移到学生模型,学生模型被训练模仿教师模型的token级概率分布。假设教师模型分布与迁移数据集相似。下图是KD工作原理的简化表示。
图1:从教师模型到学生模型的知识转移的简化表示
由于LLM的知识蒸馏是一个活跃的研究领域,有诸如MiniLLM、DistiLLM、AKL和Generalized KD等论文正在研究不同的损失方法。在本案例研究中,我们关注的是作为基线的标准交叉熵(CE)损失与前向Kullback-Leibler(KL)散度损失。前向KL散度旨在通过强制学生分布与所有教师分布对齐来最小化差异。
为什么知识蒸馏有用?
知识蒸馏的理念是,一个更小的模型可以通过使用教师模型的输出作为额外的信号来获得比从头开始训练或使用监督微调更好的性能。例如,Llama 3.2 轻量级1B和3B文本模型整合了Llama 3.1 8B和70B的logits,以在修剪后恢复性能。此外,对于指令遵循任务的微调,LLM蒸馏研究表明,知识蒸馏方法可以优于单独的监督微调(SFT)。
| 模型 | 方法 | DollyEval | 自指导 | S-NI |
| GPT-4 评估 | GPT-4 评估 | Rouge-L | ||
| Llama 7B | SFT | 73.0 | 69.2 | 32.4 |
| KD | 73.7 | 70.5 | 33.7 | |
| MiniLLM | 76.4 | 73.1 | 35.5 | |
| Llama 1.1B | SFT | 22.1 | – | 27.8 |
| KD | 22.2 | – | 28.1 | |
| AKL | 24.4 | – | 31.4 | |
| OpenLlama 3B | SFT | 47.3 | 41.7 | 29.3 |
| KD | 44.9 | 42.1 | 27.9 | |
| SeqKD | 48.1 | 46.0 | 29.1 | |
| DistiLLM | 59.9 | 53.3 | 37.6 |
表1:知识蒸馏方法与监督微调的比较
下面是知识蒸馏与监督微调有何不同之处的简化示例。
| 监督微调 | 知识蒸馏 |
|---|---|
model = llama3_2_1b() ce_loss = CrossEntropyLoss() kd_loss = ForwardKLLoss() tokens, labels = batch["tokens"], batch["labels"] logits = model(tokens, ...) loss = ce_loss(logits, labels) loss.backward() |
model = llama3_2_1b() teacher_model = llama3_1_8b() ce_loss = CrossEntropyLoss() kd_loss = ForwardKLLoss() tokens, labels = batch["tokens"], batch["labels"] logits = model(tokens, ...) teacher_logits = teacher_model(tokens, ...) loss = ce_loss(logits, labels) + kd_loss(logits, teacher_logits, labels) loss.backward() |
torchtune中的KD配方
使用torchtune,我们可以通过torchtune的KD配方轻松地将知识蒸馏应用于Llama3以及其他LLM模型系列。此配方的目标是通过从Llama3.1-8B中蒸馏,在Alpaca指令遵循数据集上微调Llama3.2-1B。此配方侧重于训练后,并假设教师和学生模型已经预训练过。
首先,我们必须下载模型权重。为了与其他torchtune微调配置保持一致,我们将使用Llama3.1-8B的指令微调模型作为教师模型,Llama3.2-1B作为学生模型。
tune download meta-llama/Meta-Llama-3.1-8B-Instruct --output-dir /tmp/Meta-Llama-3.1-8B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
tune download meta-llama/Llama-3.2-1B-Instruct --output-dir /tmp/Llama-3.2-1B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
为了使教师模型分布与Alpaca数据集相似,我们将使用LoRA微调教师模型。根据我们下一节所示的实验,我们发现当教师模型已经在目标数据集上微调时,KD表现更好。
tune run lora_finetune_single_device --config llama3_1/8B_lora_single_device
最后,我们可以运行以下命令,在单个GPU上将微调后的8B模型蒸馏为1B模型。在本案例研究中,我们使用了单个A100 80GB GPU。我们还有一个分布式配方,用于在多个设备上运行。
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device
消融研究
在本节中,我们演示了更改配置和超参数如何影响性能。默认情况下,我们的配置使用LoRA微调的8B教师模型,下载的1B学生模型,学习率为3e-4,KD损失比为0.5。在本案例研究中,我们对alpaca_cleaned_dataset进行了微调,并通过EleutherAI的LM评估工具评估了模型在truthfulqa_mc2、hellaswag和commonsense_qa任务上的表现。我们来看看以下因素的影响:
- 使用微调后的教师模型
- 使用微调后的学生模型
- KD损失比和学习率的超参数调优
使用微调后的教师模型
配置中的默认设置使用微调后的教师模型。现在,我们来看看不先微调教师模型的影响。
从损失来看,使用基线8B作为教师模型会导致比使用微调后的教师模型更高的损失。KD损失也保持相对恒定,这表明教师模型应该与迁移数据集具有相同的分布。

图2:(从左到右)前向KL散度的KD损失,交叉熵的类别损失,总损失:KD和类别损失的均匀组合。
在我们的基准测试中,我们可以看到1B模型的监督微调比基线1B模型获得了更好的准确性。通过使用微调后的8B教师模型,我们在truthfulqa上看到了可比较的结果,并在hellaswag和commonsense上有所改进。当使用基线8B作为教师模型时,我们在所有指标上都看到了改进,但低于其他配置。
| 模型 | TruthfulQA | hellaswag | 常识 | |
| mc2 | 准确率 | acc_norm | 准确率 | |
| 基线 Llama 3.1 8B | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| 使用LoRA微调的Llama 3.1 8B | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| 基线 Llama 3.2 1B | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| 使用LoRA微调的Llama 3.2 1B | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| 使用基线8B作为教师的KD | 0.444 | 0.4576 | 0.6123 | 0.5561 |
| 使用微调8B作为教师的KD | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
表2:使用基线和微调8B作为教师模型的比较
使用微调后的学生模型
对于这些实验,我们考察了当学生模型已经微调时KD的效果。我们分析了使用基线和微调8B和1B模型的不同组合的效果。
根据损失图,使用微调后的教师模型会导致较低的损失,无论学生模型是否经过微调。值得注意的是,在使用微调后的学生模型时,类别损失开始增加。
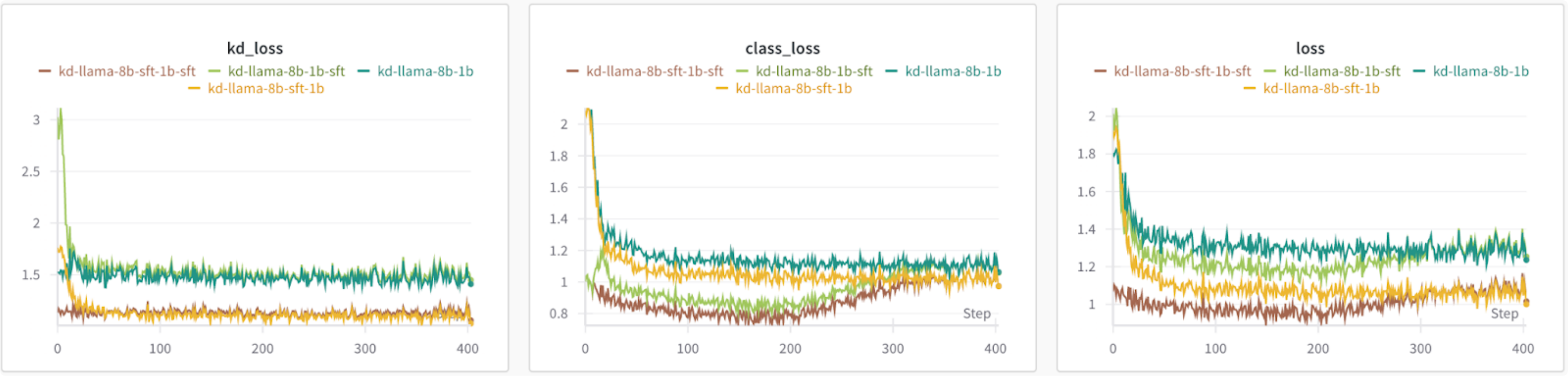
图3:比较不同教师和学生模型初始化的损失
使用微调后的学生模型可以进一步提高truthfulqa的准确性,但hellaswag和commonsense的准确性有所下降。使用微调后的教师模型和基线学生模型在hellaswag和commonsense数据集上取得了最好的结果。根据这些发现,最佳配置将根据您优化的评估数据集和指标而变化。
| 模型 | TruthfulQA | hellaswag | 常识 | |
| mc2 | 准确率 | acc_norm | 准确率 | |
| 基线 Llama 3.1 8B | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| 使用LoRA微调的Llama 3.1 8B | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| 基线 Llama 3.2 1B | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| 使用LoRA微调的Llama 3.2 1B | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| 使用基线8B和基线1B进行KD | 0.444 | 0.4576 | 0.6123 | 0.5561 |
| 使用基线8B和微调1B进行KD | 0.4508 | 0.448 | 0.6004 | 0.5274 |
| 使用微调8B和基线1B进行KD | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| 使用微调8B和微调1B进行KD | 0.4713 | 0.4512 | 0.599 | 0.5233 |
表3:使用基线和微调教师模型和学生模型的比较
超参数调优:学习率
默认情况下,该配方的学习率为3e-4。对于这些实验,我们将学习率从1e-3高到1e-5低进行了更改。
根据损失图,除了1e-5,所有学习率都导致相似的损失,而1e-5的KD和类别损失更高。
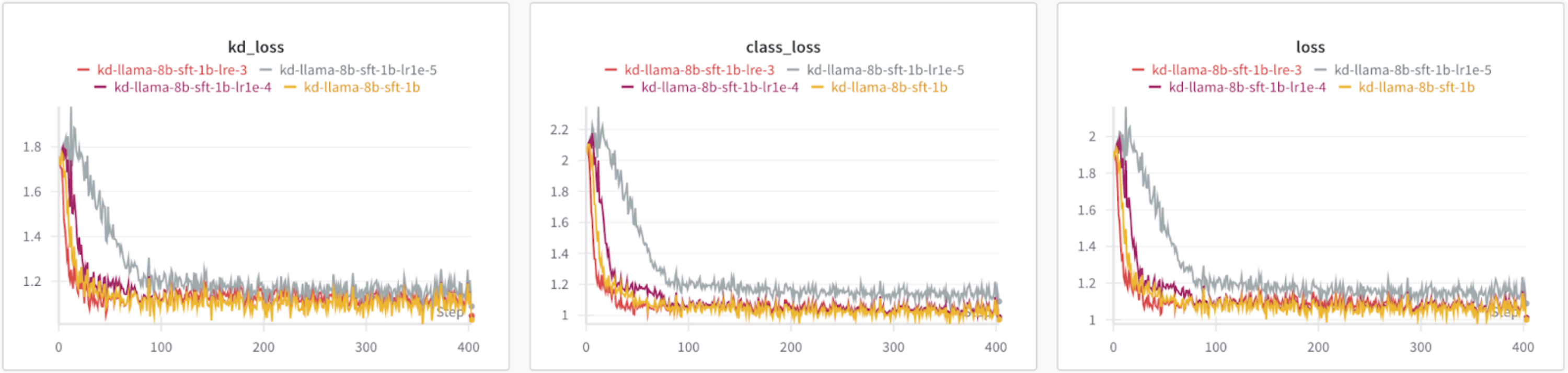
图4:比较不同学习率的损失
根据我们的基准测试,最佳学习率会根据您优化的指标和任务而变化。
| 模型 | 学习率 | TruthfulQA | hellaswag | 常识 | |
| mc2 | 准确率 | acc_norm | 准确率 | ||
| 基线 Llama 3.1 8B | – | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| 使用LoRA微调的Llama 3.1 8B | – | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| 基线 Llama 3.2 1B | – | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| 使用LoRA微调的Llama 3.2 1B | – | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| 使用微调8B和基线1B进行KD | 3e-4 | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| 使用微调8B和基线1B进行KD | 1e-3 | 0.4453 | 0.4535 | 0.6071 | 0.5258 |
| 使用微调8B和基线1B进行KD | 1e-4 | 0.4489 | 0.4606 | 0.6156 | 0.5586 |
| 使用微调8B和基线1B进行KD | 1e-5 | 0.4547 | 0.4548 | 0.6114 | 0.5487 |
表4:调整学习率的效果
超参数调优:KD比率
默认情况下,KD比率设置为0.5,这给类别损失和KD损失均等的权重。在这些实验中,我们研究了不同KD比率的影响,其中0只使用类别损失,1只使用KD损失。
总体而言,基准测试结果表明,对于这些任务和指标,更高的KD比率表现略好。
| 模型 | kd_ratio (lr=3e-4) | TruthfulQA | hellaswag | 常识 | |
| mc2 | 准确率 | acc_norm | 准确率 | ||
| 基线 Llama 3.1 8B | – | 0.5401 | 0.5911 | 0.7915 | 0.7707 |
| 使用LoRA微调的Llama 3.1 8B | – | 0.5475 | 0.6031 | 0.7951 | 0.7789 |
| 基线 Llama 3.2 1B | – | 0.4384 | 0.4517 | 0.6064 | 0.5536 |
| 使用LoRA微调的Llama 3.2 1B | – | 0.4492 | 0.4595 | 0.6132 | 0.5528 |
| 使用微调8B和基线1B进行KD | 0.25 | 0.4485 | 0.4595 | 0.6155 | 0.5602 |
| 使用微调8B和基线1B进行KD | 0.5 | 0.4481 | 0.4603 | 0.6157 | 0.5569 |
| 使用微调8B和基线1B进行KD | 0.75 | 0.4543 | 0.463 | 0.6189 | 0.5643 |
| 使用微调8B和基线1B进行KD | 1.0 | 0.4537 | 0.4641 | 0.6177 | 0.5717 |
表5:调整KD比率的效果
展望未来
在这篇博客中,我们介绍了一项研究,关于如何通过torchtune使用前向KL散度损失,将Llama 3.1 8B和Llama 3.2 1B的logits进行LLM蒸馏。未来有很多方向可以进一步探索,以提高性能并提供更大的蒸馏方法灵活性。
- 扩展KD损失种类。KD配方使用前向KL散度损失。然而,如上所述,使学生分布与整个教师分布对齐可能效果不佳。有许多论文,例如MiniLLM、DistiLLM和Generalized KD,引入了新的KD损失和策略来解决这一限制,并已证明优于结合前向KL散度损失的标准交叉熵用法。例如,MiniLLM使用反向KL散度来防止学生高估教师的低概率区域。DistiLLM引入了倾斜KL损失和自适应训练策略。
- 实现跨分词器蒸馏。当前的配方要求教师模型和学生模型使用相同的分词器,这限制了跨不同LLM系列进行蒸馏的能力。已经有一些关于跨分词器方法的研究(例如通用Logit蒸馏),我们可以进行探索。
- 将蒸馏扩展到多模态LLM和编码器模型。KD配方的一个自然扩展是扩展到多模态LLM。类似于部署更高效的LLM,也需要部署更小、更高效的多模态LLM。此外,也有一些工作展示了LLM作为编码器模型(例如LLM2Vec)。从LLM作为编码器到更小的编码器模型的蒸馏也可能是一个有前景的探索方向。