语言识别是指从多个音频输入样本中识别主要语言的过程。在自然语言处理 (NLP) 中,语言识别是一个重要且具有挑战性的问题。有许多与语言相关的任务,例如在手机上输入文本、查找您喜欢的新闻文章或发现您可能遇到的问题的答案。所有这些任务都由 NLP 模型提供支持。为了决定在特定时间调用哪个模型,我们必须执行语言识别。
本文介绍了一个深入的语言识别解决方案和代码示例,使用了 Intel® Extension for PyTorch(一个针对英特尔® 处理器进行优化的流行 PyTorch AI 框架版本)和 Intel® Neural Compressor(一个在不牺牲准确性的前提下加速 AI 推理的工具)。
代码示例演示了如何使用 Hugging Face SpeechBrain* 工具包训练模型以执行语言识别,并使用 Intel® AI Analytics Toolkit (AI Kit) 对其进行优化。用户可以修改代码示例,并使用 Common Voice 数据集识别多达 93 种语言。
语言识别的建议方法
在提出的解决方案中,用户将使用 Intel AI Analytics Toolkit 容器环境来训练模型,并利用针对 PyTorch 优化的 Intel 库执行推理。还有一个选项可以使用 Intel Neural Compressor 对训练好的模型进行量化,以加速推理。
数据集
此处使用了 Common Voice 数据集,特别是 Common Voice Corpus 11.0 的日语和瑞典语版本。该数据集用于训练 Emphasized Channel Attention, Propagation and Aggregation Time Delay Neural Network (ECAPA-TDNN) 模型,该模型使用 Hugging Face SpeechBrain 库实现。时间延迟神经网络 (TDNN),也称为一维卷积神经网络 (1D CNN),是多层人工神经网络架构,用于分类具有平移不变性的模式,并在网络的每一层对上下文进行建模。ECAPA-TDNN 是一种新型的基于 TDNN 的说话人嵌入提取器,用于说话人验证;它建立在原始 x-vector 架构之上,并更加强调通道注意力、传播和聚合。
实现
下载 Common Voice 数据集后,通过将 MP3 文件转换为 WAV 格式来预处理数据,以避免信息丢失,并将其分为训练集、验证集和测试集。
使用 Hugging Face SpeechBrain 库,根据 Common Voice 数据集重新训练 预训练的 VoxLingua107 模型,以关注感兴趣的语言。VoxLingua107 是一个语音数据集,用于训练能够很好地处理真实世界和不同语音数据的口语识别模型。该数据集包含 107 种语言的数据。默认情况下,使用日语和瑞典语,也可以包含更多语言。然后,该模型用于对测试数据集或用户指定的数据集进行推理。此外,还可以选择使用 SpeechBrain 的语音活动检测 (VAD),其中仅从音频文件中提取语音片段并进行组合,然后随机选择样本作为模型的输入。此 链接 提供了执行 VAD 所需的所有工具。为了提高性能,用户可以使用 Intel Neural Compressor 将训练好的模型量化为 INT8,以减少延迟。
训练
训练脚本的副本被添加到当前工作目录,包括用于创建 WebDataset 分片的 `create_wds_shards.py`,用于执行实际训练过程的 `train.py`,以及用于配置训练选项的 `train_ecapa.yaml`。用于创建 WebDataset 分片和 YAML 文件的脚本已修补以与此代码示例选择的两种语言配合使用。
在数据预处理阶段,执行 `prepareAllCommonVoice.py` 脚本,随机选择指定数量的样本,将输入从 MP3 格式转换为 WAV 格式。其中,80% 的样本将用于训练,10% 用于验证,10% 用于测试。建议输入样本数量至少为 2000 个,这也是默认值。
下一步,从训练和验证数据集创建 WebDataset 分片。这会将音频文件存储为 tar 文件,从而可以为大规模深度学习编写纯顺序 I/O 管道,以实现本地存储的高 I/O 速率——比随机访问快约 3 到 10 倍。
YAML 文件将由用户修改。这包括设置 WebDataset 分片的最大数量、输出神经元到感兴趣的语言数量、在整个数据集上训练的 epoch 数量以及批次大小。如果在运行训练脚本时 CPU 或 GPU 内存不足,应减小批次大小。
在此代码示例中,训练脚本将在 CPU 上执行。在运行脚本时,“cpu”将作为输入参数传递。`train_ecapa.yaml` 中定义的配置也将作为参数传递。
运行脚本以训练模型的命令是
python train.py train_ecapa.yaml --device "cpu"
未来,训练脚本 `train.py` 将通过 Intel Extension for PyTorch 的更新,旨在适用于 Intel® GPU,例如 Intel® Data Center GPU Flex 系列、Intel® Data Center GPU Max 系列和 Intel® Arc™ A 系列。
运行训练脚本以了解如何训练模型并执行训练脚本。由于其通过 Intel® Advanced Matrix Extensions (Intel® AMX) 指令集带来的性能提升,建议将第 4 代 Intel® Xeon® 可扩展处理器用于此迁移学习应用程序。
训练完成后,检查点文件可用。这些文件用于加载模型进行推理。
推理
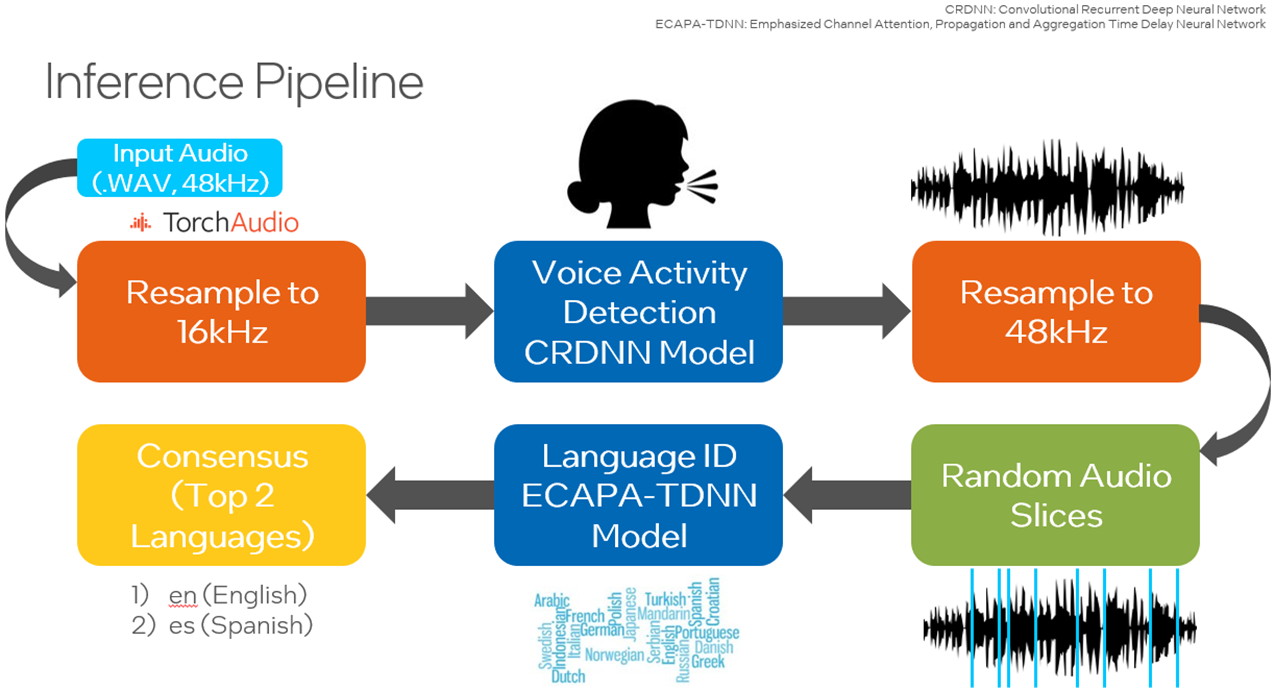
运行推理之前最关键的一步是修补 SpeechBrain 库的预训练 `interfaces.py` 文件,以便可以运行 PyTorch TorchScript* 来改善运行时性能。TorchScript 要求模型的输出仅为张量。
用户可以选择使用 Common Voice 的测试集或自己 WAV 格式的自定义数据运行推理。以下是推理脚本(`inference_custom.py` 和 `inference_commonVoice.py`)可以运行的选项
| 输入选项 | 描述 |
| -p | 指定数据路径。 |
| -d | 指定波形样本的持续时间。默认值为 3。 |
| -s | 指定样本波形的大小,默认值为 100。 |
| --vad | (仅适用于 `inference_custom.py`)启用 VAD 模型以检测活动语音。VAD 选项将识别音频文件中的语音片段,并构建一个仅包含语音片段的新 .wav 文件。这提高了用作语言识别模型输入的语音数据的质量。 |
| --ipex | 使用 Intel Extension for PyTorch 的优化运行推理。此选项将对预训练模型应用优化。使用此选项应能提高延迟相关的性能。 |
| --ground_truth_compare | (仅适用于 `inference_custom.py`)启用预测标签与真实值之间的比较。 |
| --verbose | 打印附加调试信息,例如延迟。 |
必须指定数据路径。默认情况下,将从原始音频文件中随机选择 100 个 3 秒的音频样本,并用作语言识别模型的输入。
一个在 LibriParty 数据集上预训练的小型卷积循环深度神经网络 (CRDNN) 用于处理音频样本并输出检测到语音活动的片段。这可以在推理中与 `--vad` 选项一起使用。
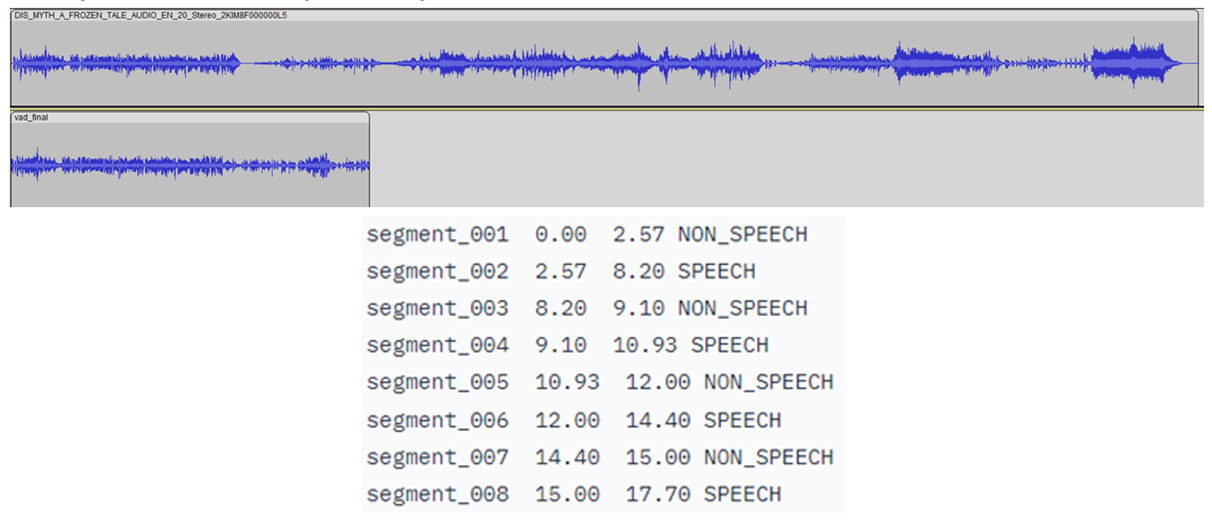
从下图可以看出,检测到语音的时间戳由 CRDNN 模型提供,这些时间戳用于构建一个新的、更短的只包含语音的音频文件。从这个新的音频文件进行采样将对主要语言的预测提供更好的效果。
自己运行推理脚本。运行推理的示例命令:
python inference_custom.py -p data_custom -d 3 -s 50 --vad
这将对您在 *data_custom* 文件夹中提供的数据执行推理。此命令使用语音活动检测功能,对 50 个随机选择的 3 秒音频样本执行推理。
如果您想运行其他语言的代码示例,请下载其他语言的 Common Voice Corpus 11.0 数据集。
使用 Intel Extension for PyTorch 和 Intel Neural Compressor 进行优化
PyTorch
Intel 扩展通过最新功能和优化扩展了 PyTorch,可在 Intel 硬件上提供额外的性能提升。查看如何安装 Intel Extension for PyTorch。该扩展可以作为 Python 模块加载,也可以作为 C++ 库链接。Python 用户可以通过导入 `intel_extension_for_pytorch` 来动态启用它。
- CPU 教程提供了有关 Intel CPU 的 Intel Extension for PyTorch 的详细信息。源代码可在 master 分支中找到。
- GPU 教程提供了有关 Intel GPU 的 Intel Extension for PyTorch 的详细信息。源代码可在 xpu-master 分支中找到。
要使用 Intel Extension for PyTorch 优化模型以进行推理,可以传入 `--ipex` 选项。模型通过插件进行优化。TorchScript 会因为 PyTorch 在图模式下运行而加速推理。使用此优化运行的命令是
python inference_custom.py -p data_custom -d 3 -s 50 --vad --ipex --verbose
注意:需要 `--verbose` 选项才能查看延迟测量。
自动混合精度(例如 bfloat16 (BF16))支持将在未来版本的代码示例中添加。
Intel Neural Compressor
这是一个在 CPU 或 GPU 上运行的开源 Python 库,它:
- 执行模型量化以减少模型大小并提高深度学习推理的速度以进行部署。
- 自动化了多种深度学习框架中流行的量化、压缩、剪枝和知识蒸馏等方法。
- 是 AI Kit 的一部分
通过运行 `quantize_model.py` 脚本并传入模型路径和验证数据集,可以将模型从 float32 (FP32) 精度量化为 integer-8 (INT8)。以下代码可用于加载此 INT8 模型进行推理
from neural_compressor.utils.pytorch import load
model_int8 = load("./lang_id_commonvoice_model_INT8", self.language_id)
signal = self.language_id.load_audio(data_path)
prediction = self.model_int8(signal)
请注意,加载量化模型时需要原始模型。使用 `quantize_model.py` 将训练后的模型从 FP32 量化到 INT8 的命令是
python quantize_model.py -p ./lang_id_commonvoice_model -datapath $COMMON_VOICE_PATH/commonVoiceData/commonVoice/dev
下一步是什么?
通过将硬件升级到具有 Intel AMX 的第 4 代 Intel Xeon 可扩展处理器,并识别来自 Common Voice 数据集的多达 93 种不同的语言,来试用上述代码示例。
我们鼓励您了解更多关于英特尔的其他AI/ML 框架优化和端到端工具组合,并将其融入您的 AI 工作流程。此外,请访问AI & ML 页面,其中涵盖了英特尔用于准备、构建、部署和扩展 AI 解决方案的 AI 软件开发资源。
有关新的第 4 代英特尔至强可扩展处理器的更多详细信息,请访问英特尔的 AI 解决方案平台门户,您可以在其中了解英特尔如何赋能开发者在这些强大的 CPU 上运行端到端 AI 管道。
有用资源
- 英特尔 AI 开发者工具和资源
- oneAPI 统一编程模型
- 官方文档 – Intel® Optimization for TensorFlow*
- 官方文档 – Intel® Neural Compressor
- 使用 Intel® AMX 加速 AI 工作负载