PyTorch 生态系统可追溯到几年前,其中最早的一些项目,如Hugging Face、Fast.ai和PyTorch Lightning,都发展出了令人惊叹的社区。最初的目标是汇集那些扩展、集成或基于 PyTorch 构建的创新开源 AI 项目。我们关注的一些关键方面包括,例如,它们经过良好测试和维护(包括 CI),用户易于上手,并且社区不断发展。几年过去了,这个生态系统继续蓬勃发展,拥有一个充满活力的项目图谱,涵盖了从隐私、计算机视觉到强化学习的数十个项目。PyTorch 生态系统工作组应运而生。
2025 年初,PyTorch 基金会成立了 PyTorch 生态系统工作组,旨在展示可能引起社区兴趣的项目,并代表那些在各自领域成熟且健康、表现突出的项目。该工作组由生态系统中的成员组成,其任务是定义一个清晰的标准,包括功能性要求(例如,CI、许可…)、可衡量要求(例如,提交和贡献者),以及如何构建其仓库的最佳实践的实施。该工作组还实施了简化的提交和审查流程以及透明的生命周期。目前尚处于早期阶段,但社区的反应非常积极,迄今已收到 21 份提交,并且有一系列强大的项目正在审查中。你可以在这里了解更多关于该工作组目标的信息,包括要求和申请流程。
作为这个新博客系列的一部分,我们每季度都会向社区更新 PyTorch 生态系统中的新项目,并重点介绍正在考虑中、有望获得更多关注和贡献者的即将推出的项目。
生态系统项目聚焦
我们很高兴欢迎 SGLang 和 docTR 加入 PyTorch 生态系统。以下是两者的简短介绍。
SGLang
SGLang是一个用于大型语言模型和视觉语言模型的快速服务引擎。它通过协同设计后端运行时和前端语言,使与模型的交互更快、更可控。
其核心功能包括:
- 快速后端运行时:通过 RadixAttention 实现前缀缓存、零开销 CPU 调度器、连续批处理、令牌注意力(分页注意力)、推测解码、张量并行、分块预填充、结构化输出和量化(FP8/INT4/AWQ/GPTQ),提供高效的服务。
- 灵活的前端语言:提供直观的接口用于编程 LLM 应用程序,包括链式生成调用、高级提示、控制流、多模态输入、并行性和外部交互。
- 广泛的模型支持:支持各种生成模型(Llama、Gemma、Mistral、Qwen、DeepSeek、LLaVA 等)、嵌入模型(e5-mistral、gte、mcdse)和奖励模型(Skywork),并且易于扩展以集成新模型。
- 活跃的社区:SGLang 是开源的,并受到活跃社区的支持,已在行业中得到采用。
SGLang 以其快速著称。在服务吞吐量和延迟方面,它通常能显著优于其他最先进的框架。了解更多。
docTR
docTR是一个由 Mindee 开发和分发的 Apache 2.0 项目,旨在帮助开发人员将 OCR 功能集成到应用程序中,无需任何先验知识。
为了快速高效地提取文本信息,docTR 采用两阶段方法:
- 首先,它执行文本检测以定位单词。
- 然后,它进行文本识别以识别单词中的所有字符。
检测和识别均由用 PyTorch 编写的最先进模型执行。了解更多。
即将推出的项目聚焦
作为本系列的一部分,我们重点介绍正在 PyTorch 生态系统中考虑的项目,我们相信这些项目将受益于更多关注和贡献者。这次轮到 EIR 和 torchcvnn。
EIR
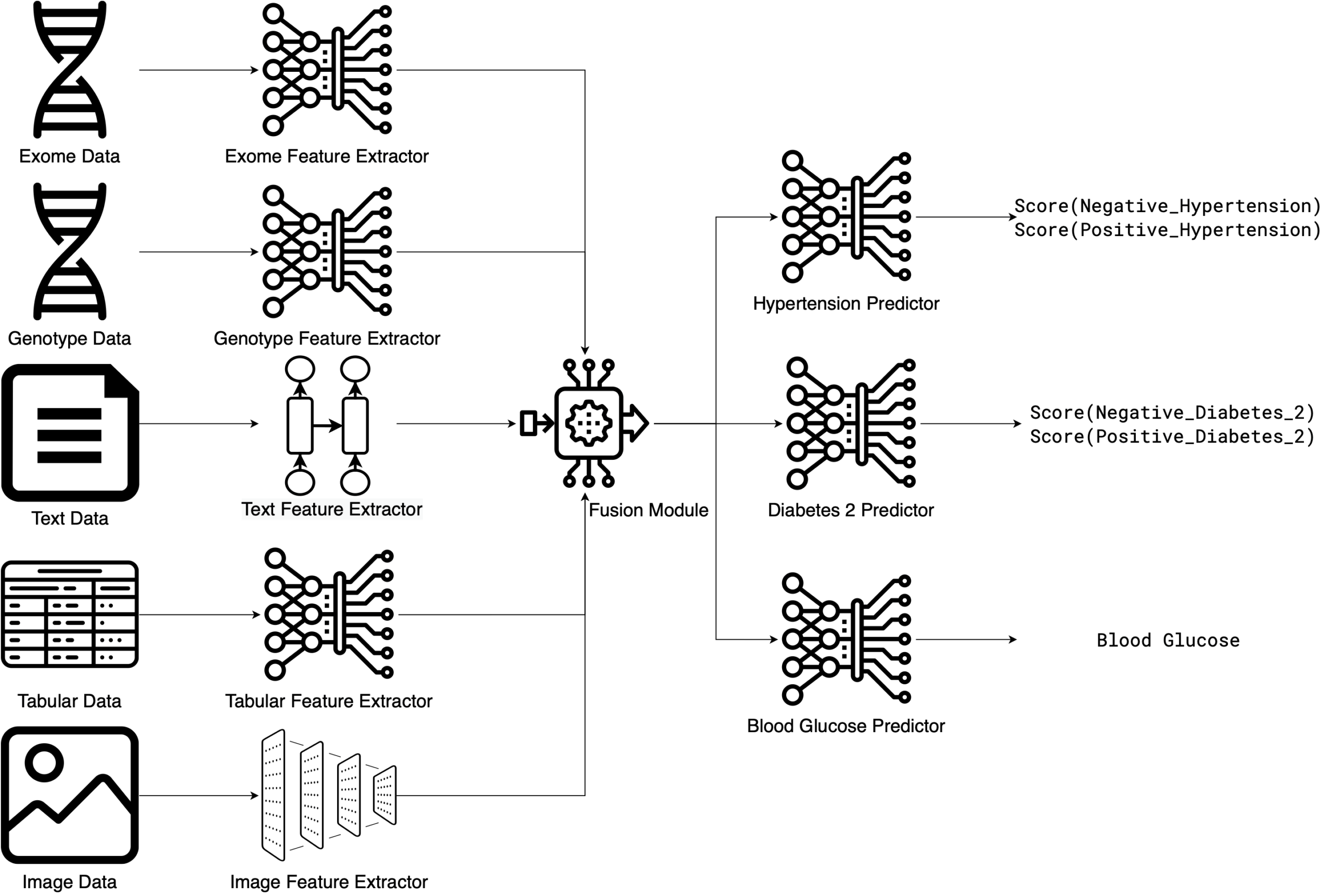
EIR是一个基于 PyTorch 构建的综合深度学习框架,使研究人员和开发人员能够跨多种数据模态执行监督建模、序列生成、图像/数组生成和生存分析。EIR 专门处理复杂数据类型,包括基因型、表格、序列、图像、数组和二进制输入。虽然它在基因组学和生物医学应用方面具有独特优势,但其对这些多样数据类型的通用处理允许在各个领域进行更广泛的应用。例如,EIR 的多模态方法可以通过将图像与设备读数(例如,对于有缺陷的硅晶片)关联起来,通过分析现场照片和操作日志(例如,识别管道中的裂缝)来监控基础设施,或者通过将产品图像与其描述和销售数据结合起来,从而提高零售洞察力。这表明 EIR 的多模态功能可以为广泛的行业带来价值。
该框架提供了一个高级但模块化的 API,减少了训练模型所需的样板代码和预处理,让用户可以专注于其最终目标而不是实现细节。要了解更多信息并探索实际示例,请参阅文档。
主要特点包括:
- 多模态输入:无缝集成基因型、表格、序列、图像、数组和二进制数据。
- 多样化建模选项:使用上述任何输入模态进行监督学习、序列生成、图像/数组生成和生存分析。
- 扩展:支持模型训练的自定义数据流功能。
- 可解释性:在执行监督学习和生存分析时内置可解释性功能。
- 模型部署:只需一个命令即可部署您训练的任何模型,让您或其他人通过 Web 服务与您的模型进行交互。
探索 EIR 并思考它如何增强您的多模态数据处理工作:
- 安装:安装非常简单:
- pip install eir-dl
- 请参阅README了解更多信息。
- 探索教程:文档可在eir.readthedocs.io查阅,示例包括:
- 贡献:请 访问我们的GitHub 仓库。
torchcvnn
torchcvnn是一个帮助研究人员、开发人员和组织轻松实验复数值神经网络 (CVNN) 的库!在某些领域,数据自然以实部-虚部形式表示,例如遥感、MRI 等。这些领域将受益于直接的复数值计算,从而在学习过程中让神经网络了解关键的物理特性。


torchcvnn 让你轻松访问:
- 遥感(SLC 和 ALOS2 格式)和 MRI 的标准数据集,以及不同任务(分类、分割、重建、超分辨率)的数据集。
- 各种激活函数,既可以在实部/虚部独立操作,也可以充分利用表示的复数特性。
- 带有 Trabelsi 等人 (2018) 的复数值 BatchNorm、LayerNorm、RMSNorm 的归一化层。
- Eilers 等人 (2023) 引入的复数值注意力层。
PyTorch 已经通过实现 Wirtinger 微积分支持复数值神经网络的优化。然而,仍然缺少复数值构建模块,无法真正探索复数值神经网络的能力。torchcvnn 的目标是填补这一空白,并提供一个库,帮助 PyTorch 用户深入复数值神经网络领域。
torchcvnn 热烈欢迎对核心 torchcvnn 库或示例仓库的贡献,无论是发现错误、提出改进建议,还是希望贡献源代码。所有组件都在项目文档中有所描述。torchcvnn 团队将于 2025 年 7 月在罗马举行的 IJCNN 会议期间参加“复数值和超复数值神经网络”专题研讨会。
如何加入 PyTorch 生态系统
如果您正在开发支持 PyTorch 社区的项目,欢迎您申请加入生态系统。请查阅PyTorch 生态系统评审流程,以确保您在申请前达到最低要求。
干杯!
PyTorch 生态系统工作组