最近的研究表明,大型模型训练将有助于提高模型质量。在过去 3 年中,模型规模增长了 10,000 倍,从参数量为 1.1 亿的 BERT 增长到万亿参数的 Megatron-2。然而,训练大型 AI 模型并非易事——除了需要大量的计算资源外,软件工程的复杂性也极具挑战性。PyTorch 一直致力于构建工具和基础设施来简化这一过程。
PyTorch 分布式数据并行因其鲁棒性和简洁性而成为可扩展深度学习的主力。然而,它要求模型能够适应单个 GPU。最近的方法,如 DeepSpeed ZeRO 和 FairScale 的全分片数据并行,允许我们通过在数据并行 worker 之间分片模型的参数、梯度和优化器状态来打破这一障碍,同时仍然保持数据并行的简洁性。
PyTorch 1.11 新增了对全分片数据并行 (FSDP) 的原生支持,目前作为原型功能提供。其实现大量借鉴了 FairScale 的版本,同时带来了更精简的 API 和额外的性能改进。
PyTorch FSDP 在 AWS 上的扩展测试表明,它可以扩展到训练具有万亿参数的密集模型。在我们的实验中,对于 GPT 1T 模型,每块 A100 GPU 实现了 84 TFLOPS 的性能;对于 GPT 175B 模型,每块 A100 GPU 实现了 159 TFLOPS 的性能,均在 AWS 集群上。与 FairScale 的原始版本相比,在启用 CPU 卸载时,原生 FSDP 实现也显著缩短了模型初始化时间。
在未来的 PyTorch 版本中,我们将允许用户在 DDP、ZeRO-1、ZeRO-2 和 FSDP 等数据并行模式之间无缝切换,以便用户可以在统一的 API 中通过简单的配置来训练不同规模的模型。
FSDP 的工作原理
FSDP 是一种数据并行训练,但与传统的每个 GPU 维护模型参数、梯度和优化器状态副本的数据并行不同,它将所有这些状态分片到数据并行 worker 中,并且可以选择将分片的模型参数卸载到 CPU。
下图展示了 FSDP 如何处理 2 个数据并行进程
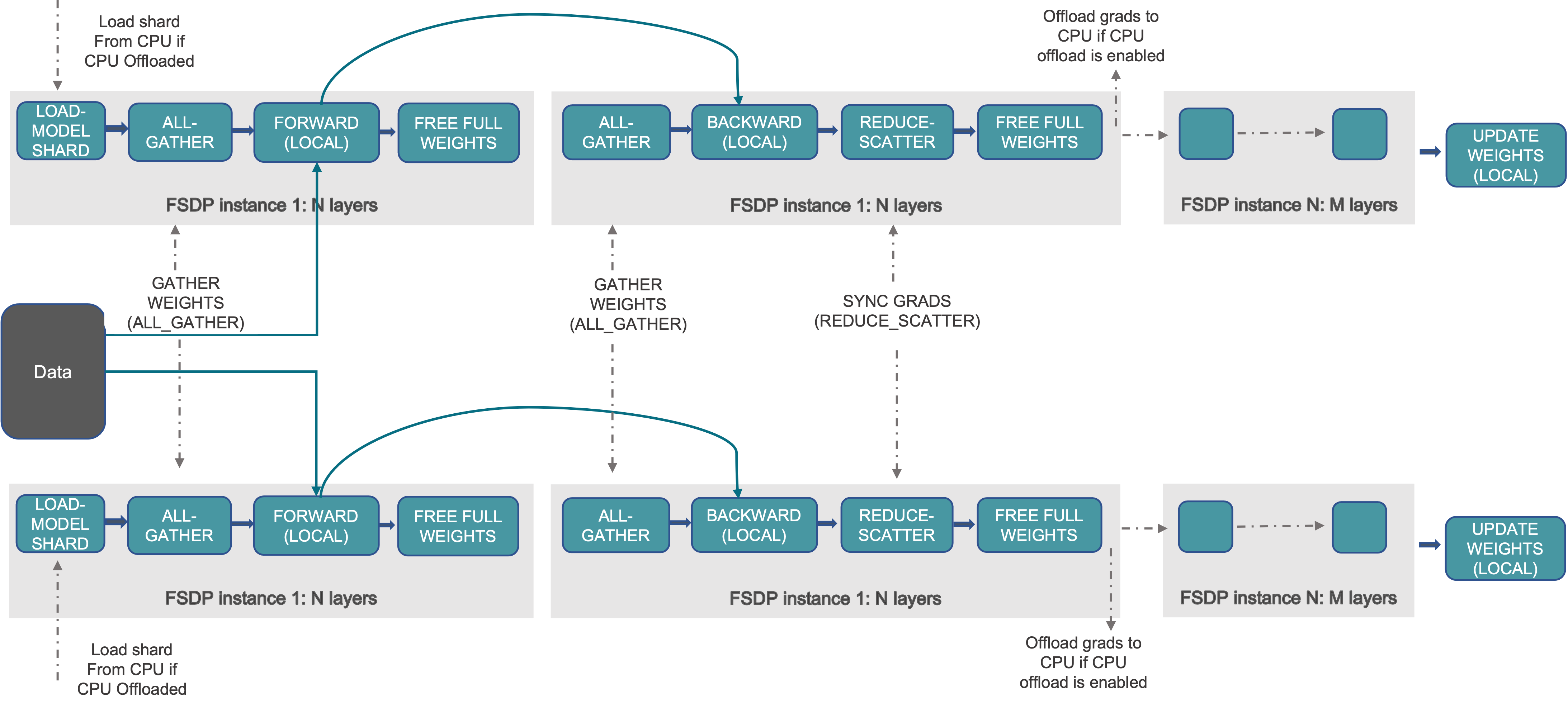
图 1. FSDP 工作流程
通常,模型层以嵌套方式用 FSDP 包装,以便在正向或反向计算期间,单个 FSDP 实例中的层才需要将完整参数收集到单个设备。收集到的完整参数将在计算后立即释放,释放的内存可用于下一层的计算。通过这种方式,可以节省峰值 GPU 内存,从而使训练能够扩展到使用更大的模型尺寸或更大的批量大小。为了进一步最大化内存效率,当实例在计算中不活动时,FSDP 可以将参数、梯度和优化器状态卸载到 CPU。
在 PyTorch 中使用 FSDP
有两种方法可以用 PyTorch FSDP 包装模型。自动包装是 DDP 的即插即用替代品;手动包装需要对模型定义代码进行最小的更改,并能够探索复杂的 sharding 策略。
自动包装
模型层应以嵌套方式包装在 FSDP 中,以节省峰值内存并实现通信和计算重叠。最简单的方法是自动包装,它可以作为 DDP 的即插即用替代品,而无需更改其余代码。
fsdp_auto_wrap_policy 参数允许指定一个可调用函数来递归地用 FSDP 包装层。PyTorch FSDP 提供的 default_auto_wrap_policy 函数递归地包装参数数量大于 1 亿的层。您可以根据需要提供自己的包装策略。编写自定义包装策略的示例显示在 FSDP API 文档中。
此外,可以可选地配置 cpu_offload 以在计算中不使用这些参数时将包装的参数卸载到 CPU。这可以进一步提高内存效率,但代价是主机和设备之间的数据传输开销。
下面的示例展示了如何使用自动包装来包装 FSDP。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
default_auto_wrap_policy,
)
import torch.nn as nn
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(8, 4)
self.layer2 = nn.Linear(4, 16)
self.layer3 = nn.Linear(16, 4)
model = DistributedDataParallel(model())
fsdp_model = FullyShardedDataParallel(
model(),
fsdp_auto_wrap_policy=default_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True),
)
手动包装
手动包装通过对模型某些部分选择性地应用 wrap 来探索复杂的 sharding 策略可能很有用。整体设置可以传递给 enable_wrap() 上下文管理器。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
enable_wrap,
wrap,
)
import torch.nn as nn
from typing import Dict
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = wrap(nn.Linear(8, 4))
self.layer2 = nn.Linear(4, 16)
self.layer3 = wrap(nn.Linear(16, 4))
wrapper_kwargs = Dict(cpu_offload=CPUOffload(offload_params=True))
with enable_wrap(wrapper_cls=FullyShardedDataParallel, **wrapper_kwargs):
fsdp_model = wrap(model())
使用上述两种方法之一用 FSDP 包装模型后,可以像本地训练一样训练模型,如下所示
optim = torch.optim.Adam(fsdp_model.parameters(), lr=0.0001)
for sample, label in next_batch():
out = fsdp_model(input)
loss = criterion(out, label)
loss.backward()
optim.step()
基准测试结果
我们使用 PyTorch FSDP 在 AWS 集群上对 175B 和 1T GPT 模型进行了广泛的扩展测试。每个集群节点都是一个实例,配备 8 块 NVIDIA A100-SXM4-40GB GPU,节点间通过 AWS Elastic Fabric Adapter (EFA) 连接,网络带宽为 400 Gbps。
GPT 模型使用 minGPT 实现。基准测试目的是使用随机生成的数据集。所有实验均以 5 万词汇量、fp16 精度和 SGD 优化器运行。
| 模型 | 层数 | 隐藏层大小 | 注意力头 | 模型大小,数十亿参数 |
|---|---|---|---|---|
| GPT 175B | 96 | 12288 | 96 | 175 |
| GPT 1T | 128 | 25600 | 160 | 1008 |
除了在实验中使用带有参数 CPU 卸载的 FSDP 外,测试中还应用了 PyTorch 中的 激活检查点功能。
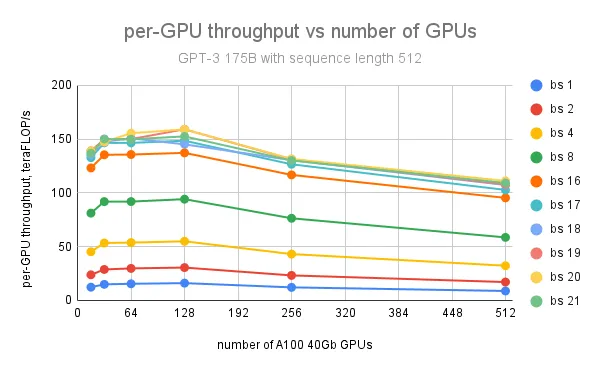
对于 GPT 175B 模型,在使用 128 个 GPU、批量大小为 20、序列长度为 512 的情况下,实现了每 GPU 最大吞吐量 159 teraFLOP/s(NVIDIA A100 峰值理论性能 312 teraFLOP/s/GPU 的 51%);进一步增加 GPU 数量会导致每 GPU 吞吐量下降,原因是节点间通信量增加。
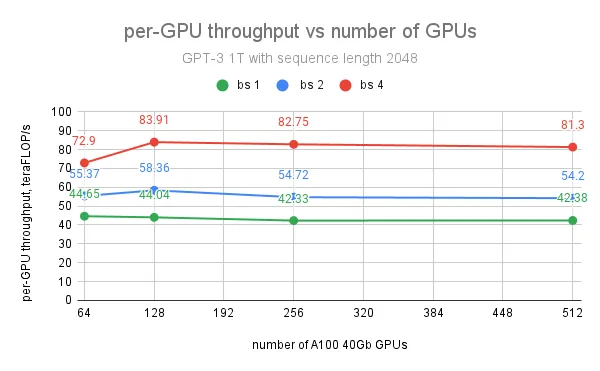
对于 GPT 1T 模型,在使用 128 个 GPU、批量大小为 4、序列长度为 2048 的情况下,实现了每 GPU 最大吞吐量 84 teraFLOP/s(峰值 teraFLOP/s 的 27%)。然而,进一步增加 GPU 数量对每 GPU 吞吐量的影响不大,因为我们观察到 1T 模型训练的最大瓶颈不是来自通信,而是当峰值 GPU 内存达到限制时缓慢的 CUDA 缓存分配器。使用内存容量更大的 A100 80G GPU 将主要解决这个问题,并有助于扩展批量大小以实现更大的吞吐量。
未来工作
在下一个 Beta 版本中,我们计划添加高效的分布式模型/状态检查点 API、用于大型模型具体化的元设备支持,以及 FSDP 计算和通信中的混合精度支持。我们还将使其更容易在新 API 中在 DDP、ZeRO1、ZeRO2 和 FSDP 数据并行模式之间切换。为了进一步提高 FSDP 性能,还计划减少内存碎片和改进通信效率。
FSDP 两个版本的历史
FairScale FSDP 于 2021 年初作为 FairScale 库的一部分发布。然后,我们开始努力将 FairScale FSDP 上游到 PT 1.11 中的 PyTorch,使其达到生产就绪状态。我们有选择地将 FairScale FSDP 中的关键功能上游和重构,重新设计了用户界面并进行了性能改进。
在不久的将来,FairScale FSDP 将保留在 FairScale 存储库中用于研究项目,而通用且广泛采用的功能将逐步上游到 PyTorch 并进行相应的强化。
同时,PyTorch FSDP 将更专注于生产就绪和长期支持。这包括更好地与生态系统集成以及在性能、可用性、可靠性、可调试性和可组合性方面的改进。
致谢
我们感谢 FairScale FSDP 的作者:Myle Ott、Sam Shleifer、Min Xu、Priya Goyal、Quentin Duval、Vittorio Caggiano、Tingting Markstrum、Anjali Sridhar。感谢 Microsoft DeepSpeed ZeRO 团队开发和推广了分片数据并行技术。感谢 Pavel Belevich、Jessica Choi、Sisil Mehta 在不同集群上使用 PyTorch FSDP 运行实验。感谢 Geeta Chauhan、Mahesh Yadav、Pritam Damania、Dmytro Dzhulgakov 对这项工作的支持和富有洞察力的讨论。