引言
我们将混合精度和低精度训练与 Opacus 集成,以提高吞吐量并支持更大的批处理大小训练。我们的初步实验表明,通过使用混合精度或低精度,可以保持与全精度训练相同的效用。这些是早期阶段的结果,我们鼓励进一步研究低精度和混合精度对 DP-SGD 效用影响。
Opacus 在应对大型模型(如 LLM)训练挑战以及弥合隐私训练与非隐私训练之间差距方面取得了重大进展。2024 年,我们向 Opacus 引入了快速梯度裁剪,以减少基于 hook 的 DP-SGD 实现的内存占用。最近,添加的 完全分片数据并行 (FSDP) 功能可以将大型模型训练扩展到不同设备。
混合精度训练结合了不同的数值精度,在加快训练速度和减少内存使用方面非常有效,同时保持了模型效用。通过将低精度(例如 BF16)操作与单精度(FP32)操作结合使用,可以训练更大的模型,使用更大的批处理大小和更快的矩阵操作。例如,Llama 3 模型使用 FP32 和 BF16 的混合精度进行训练,而 Llama 4 使用 BF16 和 FP8。我们邀请开发人员和研究人员利用混合精度和其他最近引入的技术,将 Opacus 训练扩展到更大的模型。
混合精度和低精度训练
单精度浮点数由 32 位表示。较新的 GPU 支持 16 位或 8 位浮点表示的高吞吐量算术运算。这些效率提升已被深度学习应用采用,在这些应用中,通常较低的精度不会损害模型性能。
在低精度训练中,前向传播、后向传播和权重更新都以低精度数据类型(例如 BF16 或 FP8)执行。然而,低精度下的权重更新在数值上可能不稳定。
作为替代方案,混合精度训练在高精度(FP32)下进行权重更新,仅将低精度(例如 BF16)用于前向传播和后向传播。此外,一些层(例如归一化层)也以 FP32 执行操作以保持数值稳定性。
为了在 Opacus 中启用混合精度训练,我们添加了逻辑来处理激活和反向传播具有不同精度类型时(如图 1 中的两个绿色框所示)的每个样本梯度的计算。此逻辑在计算每个样本梯度的函数中实现(例如,此处)。
图 1. 混合精度训练的前向和后向传播。LayerNorm 前向传播以全精度进行。线性层操作(以及大多数其他层)以低精度进行。一个层的输出是下一个层的输入。

图 2. 混合精度下的权重更新。权重始终以全精度存储。反向传播被转换为全精度。

如何在 Opacus 中使用混合精度和低精度训练
在 Opacus 中,只需几行额外的代码即可实现低精度和混合精度训练。它看起来与非隐私训练非常相似。请记住,Opacus 将模型、优化器和数据加载器等训练组件封装到 PrivacyEngine 中,PrivacyEngine 是该库的主要接口。此后,训练循环与原生 PyTorch 相同。
低精度训练
与 Opacus 的全精度训练相比,我们只需要:
- 在训练开始前将模型权重转换为低精度,以及
- 将输入转换为低精度。
from opacus import PrivacyEngine # cast model weights to lower precision before training model = model.to(torch.bfloat16) model.train() privacy_engine = PrivacyEngine() model, optimizer, dataloader = privacy_engine.make_private( module=model, optimizer=optimizer, data_loader=dataloader, noise_multiplier=noise_multiplier max_grad_norm=max_grad_norm ) for x, y in train_loader: # cast input to lower precision # integer inputs should stay as integers # (if y is a float, y should also be cast) if x.is_floating(): x = x.to(torch.bfloat16) # proceed with training step as usual output = model(x) optimizer.zero_grad() loss = criterion(output, y) loss.backward() optimizer.step()
混合精度训练
PyTorch 通过 torch.amp 包支持混合精度训练,我们也在利用它。前向传播和损失计算在上下文内,而后向传播应在上下文之外。这里的主要变化是添加了 torch.amp 上下文。
from opacus import PrivacyEngine privacy_engine = PrivacyEngine() model, optimizer, dataloader = privacy_engine.make_private( module=model, optimizer=optimizer, data_loader=dataloader, noise_multiplier=noise_multiplier max_grad_norm=max_grad_norm ) for x, y in train_loader: # mixed precision training context for forward pass with torch.amp.context("cuda", dtype=torch.bfloat16): output = model(x) optimizer.zero_grad() loss = criterion(output, y) # backward pass is outside of amp context loss.backward() optimizer.step()
BERT 微调任务
我们实验使用 SNLI 数据集微调预训练的 BERT-base 模型(类似于 此 Opacus 教程)。我们考虑两种常见的 DP-SGD 微调设置:
- 仅微调模型的最后几层,同时冻结所有其他层,或
- 使用 LoRA(低秩自适应)微调所有层。
在第一种情况下,鉴于线性层的宽度很大,幽灵裁剪可以改善内存使用。在第二种情况下,由于 LoRA 的有效层宽度非常小,幽灵裁剪没有用处。
我们仅使用 FP32、仅使用 BF16 或混合精度进行训练。
我们发现,虽然非隐私训练在所有精度设置下具有相同的效用,但使用 BF16 对最后几层进行 DP-SGD 微调会导致性能下降。混合精度训练可以弥补这种效用损失。通过 LoRA 微调,DP-SGD 在所有精度设置下都保持相同的效用。我们假设使用 DP-SGD 的低精度训练在仅微调线性层时表现最佳,如 LoRA 的情况。然而,当涉及其他类型的层(例如归一化层)时,它会损害效用,这些层通常需要高精度操作。因此,LoRA 是我们推荐的 DP-SGD 低/混合精度微调设置。
内存和速度改进
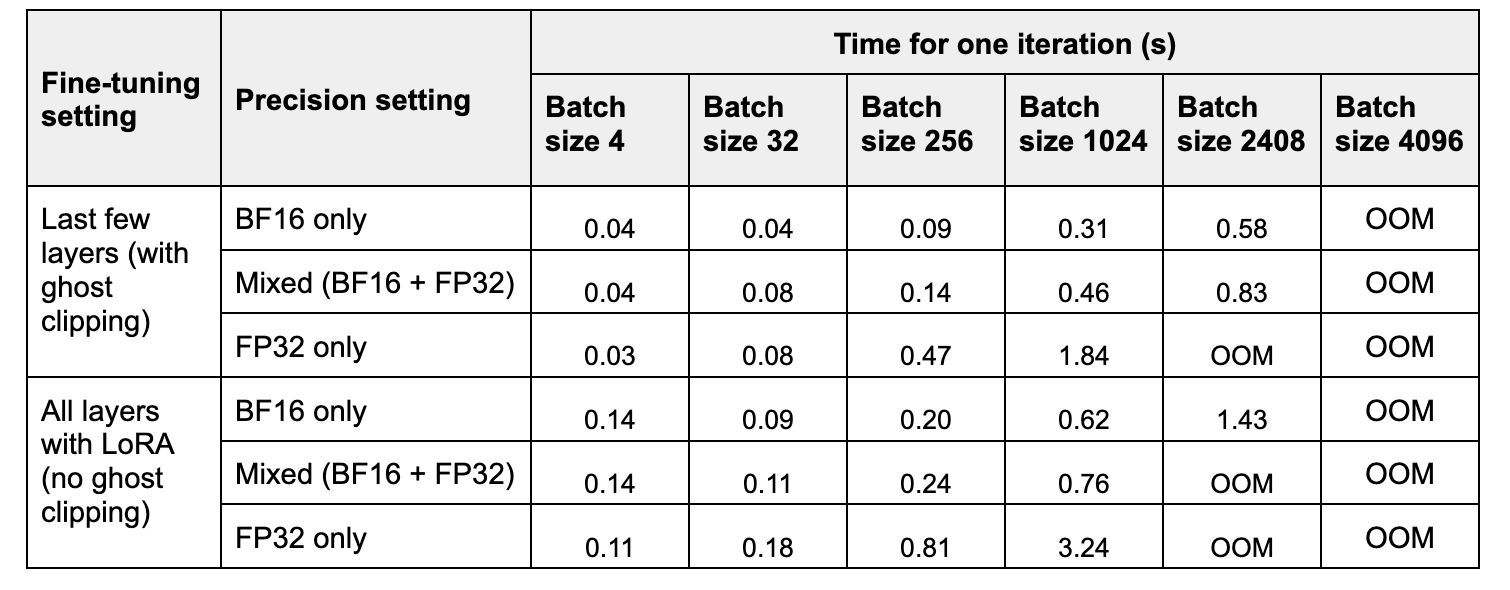
在表 2 中,我们比较了三种精度设置下一次前向和后向传播的峰值内存和时间。与 FP32 相比,BF16 将峰值内存提高了 约 2 倍,而混合精度将其提高了 约 1.2-1.4 倍。请注意,在小批量大小下,混合精度可能比 FP32 使用更多内存,因为模型权重以低精度和高精度存储两次。
在表 2 中,我们比较了三种精度设置下一次训练步骤的时间。与 FP32 相比,BF16 的加速随着批量大小的增加而增加,范围从 约 2 倍到约 6 倍。混合精度训练的加速范围从 约 1 倍到约 4 倍。
实验在配备 40GB 内存的 A100 GPU 上进行。
表 1. 随着批量大小增加,一次迭代(前向+后向传播)的峰值内存。
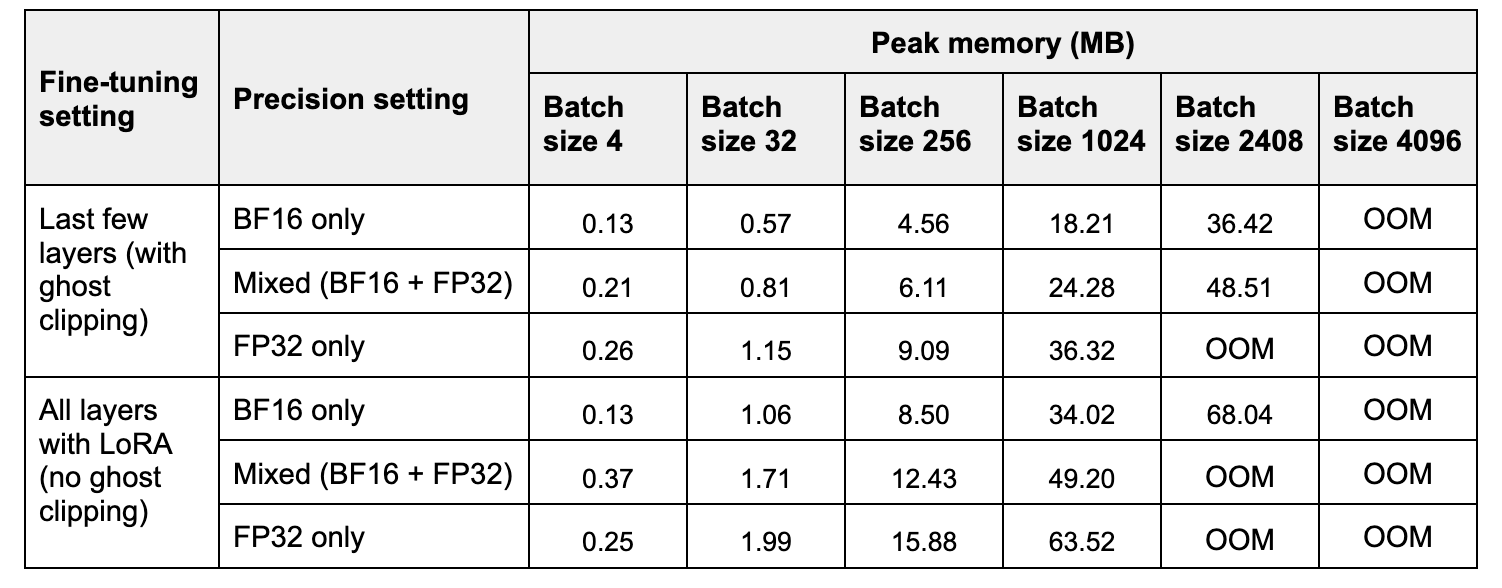
表 2. 随着批量大小增加,一次迭代的运行时间(平均 10 次运行)。
对效用的影响
我们训练一个 epoch,并测量在该 epoch 期间达到的最大测试集准确率。我们对 5 次运行的最大准确率进行平均。
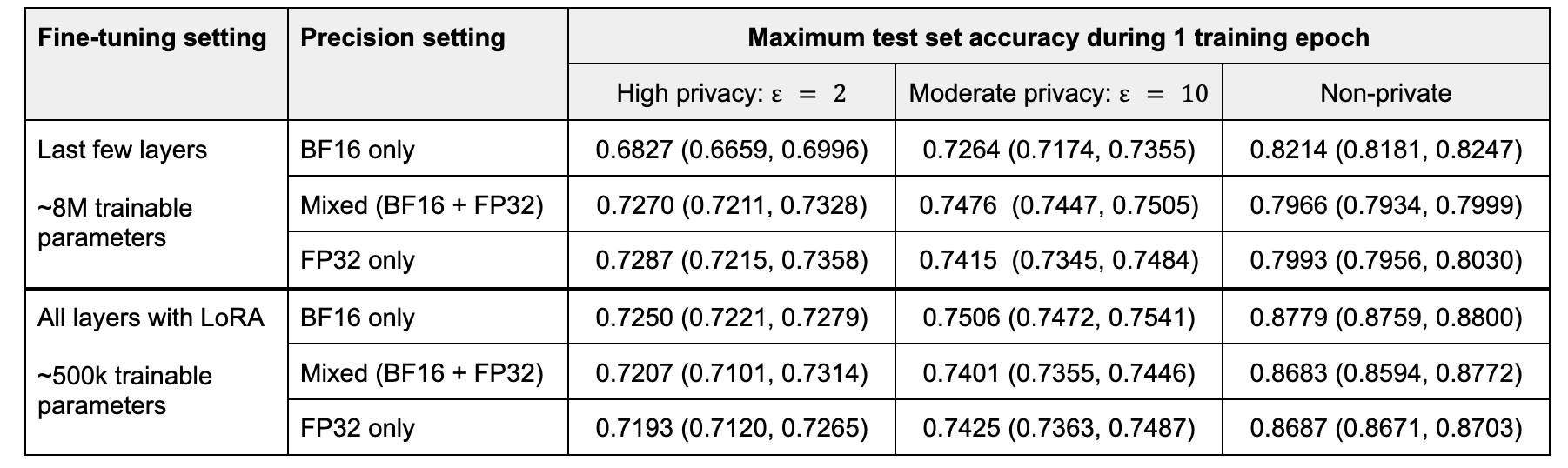
在微调最后几层时,混合精度和 FP32 训练的性能不相上下,而低精度训练会导致效用显著下降。随着隐私预算的增加,效用差距缩小。在非隐私情况下,低精度训练似乎有助于提高性能,这可能是由于噪声矩阵操作的正则化效应抵消了过拟合。
通过 LoRA 微调,BF16 实现了最高的准确率,BF16 的优势随着隐私预算的增加而增加。混合精度和高精度训练的性能不相上下。
我们假设使用 DP-SGD 的低精度训练在仅微调线性层时表现最佳,如 LoRA。当微调涉及其他类型的层(例如归一化层,它们通常需要高精度操作)时,它会损害效用。
表 3. 在不同隐私级别下,5 次运行平均的测试集准确率。批量大小 = 32。
行业用例
我们实验使用 DP-SGD 和 LoRA(约 7M 可训练参数)微调一个具有 8B 参数的大型语言模型。与 FP32 训练相比,BF16 将每秒处理的样本数提高了 3.4 倍,而混合精度提高了 1.1 倍。我们在所有精度设置下都实现了相近的损失和损失收敛速度。
结论
我们已将一种流行的训练大型模型的通用技术集成到 Opacus 中,进一步增强了 Opacus 应对隐私训练挑战的能力。借助混合精度和低精度,Opacus 实现了更高的吞吐量和更大的批处理大小训练。我们的初步实验表明,这可以在不牺牲效用的情况下实现。我们还提供了一些关于哪种精度类型最适合不同微调设置的见解。我们邀请开发人员和研究社区尝试这项新功能,并提供关于 DP-SGD 在混合精度和低精度设置下的效用性能的进一步结果。
要了解有关 Opacus 的更多信息,请访问 opacus.ai 和 github.com/pytorch/opacus。