
我们很高兴向 PyTorch 生态系统介绍新项目 depyf,旨在帮助用户理解、学习和适应 torch.compile!
动机
torch.compile 是 PyTorch 2.x 的基石,只需一行代码即可为训练和推理加速机器学习工作流。仅仅包含 @torch.compile 就可以显著提升代码性能。然而,找到 torch.compile 的最佳插入点并不容易,更不用说调整各种参数以实现最大效率的复杂性了。
torch.compile 堆栈的复杂性,包括 Dynamo、AOTAutograd、Inductor 等,带来了陡峭的学习曲线。这些组件对于深度学习性能优化至关重要,但如果没有扎实的基础,它们可能会令人望而生畏。
注意:有关 torch.compile 如何工作的介绍性示例,请参阅此演练解释。
一个常用工具:TORCH_COMPILE_DEBUG
为了揭开 torch.compile 的神秘面纱,常用的方法是利用 TORCH_COMPILE_DEBUG 环境变量。虽然它提供了更多信息,但解读输出仍然是一项艰巨的任务。
例如,当我们有以下代码时
# test.py
import torch
from torch import _dynamo as torchdynamo
from typing import List
@torch.compile
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
def main():
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
if __name__ == "__main__":
main()
并使用 TORCH_COMPILE_DEBUG=1 python test.py 运行它,我们将得到一个名为 torch_compile_debug/run_2024_02_05_23_02_45_552124-pid_9520 的目录,其中包含这些文件
.
├── torchdynamo
│ └── debug.log
└── torchinductor
├── aot_model___0_debug.log
├── aot_model___10_debug.log
├── aot_model___11_debug.log
├── model__4_inference_10.1
│ ├── fx_graph_readable.py
│ ├── fx_graph_runnable.py
│ ├── fx_graph_transformed.py
│ ├── ir_post_fusion.txt
│ ├── ir_pre_fusion.txt
│ └── output_code.py
├── model__5_inference_11.2
│ ├── fx_graph_readable.py
│ ├── fx_graph_runnable.py
│ ├── fx_graph_transformed.py
│ ├── ir_post_fusion.txt
│ ├── ir_pre_fusion.txt
│ └── output_code.py
└── model___9.0
├── fx_graph_readable.py
├── fx_graph_runnable.py
├── fx_graph_transformed.py
├── ir_post_fusion.txt
├── ir_pre_fusion.txt
└── output_code.py
生成的文件和日志常常提出比解答更多的问题,让开发人员对数据中的含义和关系感到困惑。TORCH_COMPILE_DEBUG 的常见困惑包括
model__4_inference_10.1是什么意思?- 我有一个函数,但目录中有三个
model__xxx.py,它们之间有什么对应关系? debug.log中的那些LOAD_GLOBAL是什么?
一个更好的工具:depyf 助你解决问题
让我们看看 depyf 如何帮助开发人员解决上述挑战。要使用 depyf,只需执行 pip install depyf 或按照项目页面https://github.com/thuml/depyf 安装最新版本,然后将主要代码包围在 with depyf.prepare_debug 中。
# test.py
import torch
from torch import _dynamo as torchdynamo
from typing import List
@torch.compile
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
def main():
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
if __name__ == "__main__":
import depyf
with depyf.prepare_debug("depyf_debug_dir"):
main()
执行 python test.py 后,depyf 将生成一个名为 depyf_debug_dir(prepare_debug 函数的参数)的目录。该目录下将包含这些文件
.
├── __compiled_fn_0 AFTER POST GRAD 0.py
├── __compiled_fn_0 Captured Graph 0.py
├── __compiled_fn_0 Forward graph 0.py
├── __compiled_fn_0 kernel 0.py
├── __compiled_fn_3 AFTER POST GRAD 0.py
├── __compiled_fn_3 Captured Graph 0.py
├── __compiled_fn_3 Forward graph 0.py
├── __compiled_fn_3 kernel 0.py
├── __compiled_fn_4 AFTER POST GRAD 0.py
├── __compiled_fn_4 Captured Graph 0.py
├── __compiled_fn_4 Forward graph 0.py
├── __compiled_fn_4 kernel 0.py
├── __transformed_code_0_for_torch_dynamo_resume_in_toy_example_at_8.py
├── __transformed_code_0_for_toy_example.py
├── __transformed_code_1_for_torch_dynamo_resume_in_toy_example_at_8.py
└── full_code_for_toy_example_0.py
并且有两个明显的优点
- 冗长难懂的
torchdynamo/debug.log不见了。其内容被清理并以人类可读的源代码形式显示在full_code_for_xxx.py和__transformed_code_{n}_for_xxx.py中。值得注意的是,depyf最繁琐和困难的工作是将torchdynamo/debug.log中的字节码反编译成 Python 源代码,将开发人员从 Python 令人望而生畏的内部细节中解放出来。 - 函数名与计算图之间的对应关系得到了尊重。例如,在
__transformed_code_0_for_toy_example.py中,我们可以看到一个名为__compiled_fn_0的函数,我们将立即知道其对应的计算图在__compiled_fn_0_xxx.py中,因为它们共享相同的__compiled_fn_0前缀名。
从 full_code_for_xxx.py 开始,并遵循所涉及的函数,用户将清楚地了解 torch.compile 对其代码做了什么。
还有一件事:逐步调试能力
使用调试器逐行调试代码是理解代码工作原理的好方法。然而,在 TORCH_COMPILE_DEBUG 下,这些文件仅供用户参考,无法用用户关心的数据执行。
注意:“调试”指的是检查和改进程序的过程,而不是纠正有错误的代码。
depyf 的一个突出特点是它能够促进 torch.compile 的逐步调试:它生成的所有文件都与 Python 解释器内部的运行时代码对象关联,我们可以在这些文件中设置断点。用法很简单,只需添加一个上下文管理器 with depyf.debug(),它就能实现这一功能
# test.py
import torch
from torch import _dynamo as torchdynamo
from typing import List
@torch.compile
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
def main():
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
if __name__ == "__main__":
import depyf
with depyf.prepare_debug("depyf_debug_dir"):
main()
with depyf.debug():
main()
只有一个注意事项:调试 torch.compile 的工作流程偏离了标准调试工作流程。使用 torch.compile,许多代码是动态生成的。因此,我们需要
- 启动程序
- 当程序退出
with depyf.prepare_debug("depyf_debug_dir")时,代码将在depyf_debug_dir中可用。 - 当程序进入
with depyf.debug()时,它将自动在内部设置一个断点,从而使程序暂停。 - 导航到
depyf_debug_dir设置断点。 - 继续运行代码,调试器将命中这些断点!
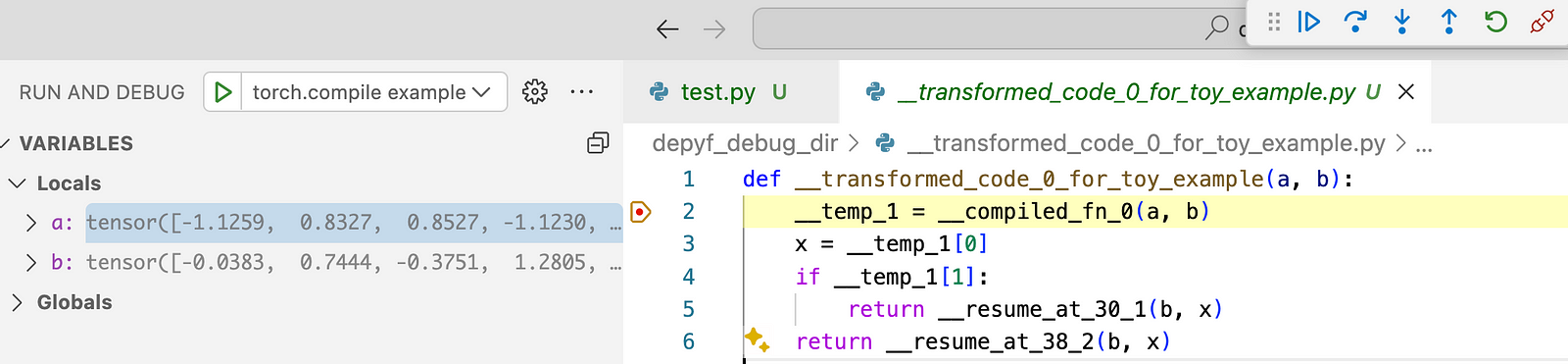
这是它看起来的截图。所有代码和张量变量都是实时的,我们可以检查任何变量,并逐步执行代码,就像我们现在日常的调试工作流程一样!唯一的区别是我们正在调试 torch.compile 生成的代码而不是人工编写的代码。
结论
torch.compile 是一个宝贵的工具,可以轻松加速 PyTorch 代码。对于那些希望深入研究 torch.compile 的人来说,无论是为了充分利用其潜力还是为了集成自定义操作,学习曲线都可能非常陡峭。depyf 旨在降低这一障碍,提供用户友好的体验来理解、学习和适应 torch.compile。
请探索 depyf 并亲身体验它的好处!该项目是开源的,可在https://github.com/thuml/depyf 上获取。通过 pip install depyf 安装非常简单。我们希望 depyf 能够增强每个人的 torch.compile 开发工作流程。