在过去的几个月中,交互式聊天生成(或对话响应生成)模型受到了极大的关注。ChatGPT 和 Google Bard 等对话响应生成模型席卷了人工智能世界。交互式聊天生成的目的是回答人类提出的各种问题,这些基于人工智能的模型利用自然语言处理 (NLP) 生成几乎与人类生成无异的对话。
本文展示了一个代码示例,说明如何基于 Hugging Face 预训练的 DialoGPT 模型并结合用于 PyTorch 的 Intel® Extension 对模型执行动态量化,从而创建交互式聊天。
开始使用
为什么选择 DialoGPT?
DialoGPT(**Dialo**gue **G**enerative **P**re-trained **T**ransformer)是一个大规模、预训练的对话响应生成模型,它基于从 Reddit 评论链和讨论帖子中提取的 1.47 亿个类似对话的交流进行训练。DialoGPT 由微软于 2019 年提出。其主要目标是创建能够针对各种对话主题生成自然响应的开放域聊天机器人。利用 DialoGPT 的对话响应生成系统能够生成更适用、更丰富、更多样化和更具上下文特异性的回复。
DialoGPT 架构
DialoGPT 架构基于 GPT-2 模型。它被表述为自回归语言模型,并使用多层 Transformer 作为模型架构。GPT-2 由 OpenAI 提出。GPT-2 模型在通用文本数据上进行训练,而 DialoGPT 则在 Reddit 讨论帖子中进行训练。
让我们看看 GPT-2 架构。通用 Transformer 架构中有两种类型的块:
- 编码器——包含自注意力层和前馈神经网络
- 解码器——类似于编码器,但自注意力层被掩蔽
自注意力层允许一个位置查看当前单词右侧的标记(文本中的后续单词),而掩蔽自注意力层则阻止这种情况发生。
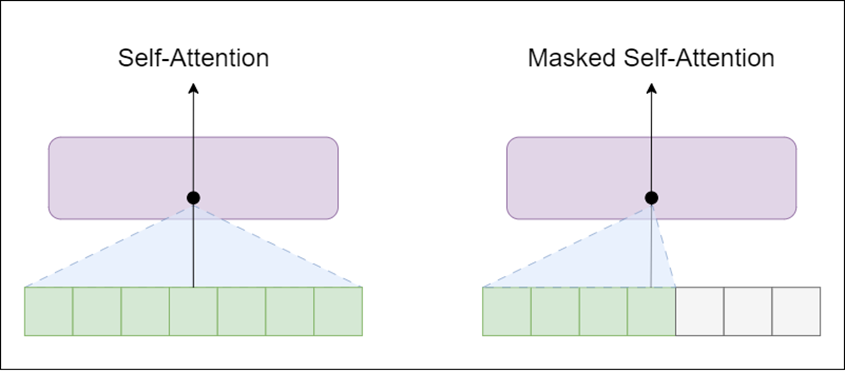
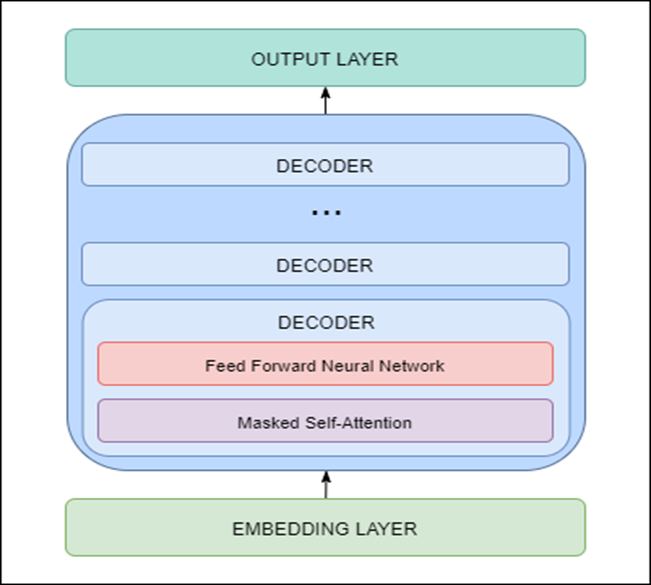
GPT-2 是使用 Transformer 解码器块构建的。这意味着架构中使用了以下层:
- 嵌入层——负责将输入文本转换为嵌入(每个单词被转换为固定长度的向量表示)
- Transformer 解码器——包括多个带有掩蔽自注意力和前馈神经网络层的解码器块
- 输出层——负责将从解码器获得的嵌入转换为单词
GPT-2 架构(和 DialoGPT 架构)如下图所示。
由于模型基于 Transformer 架构,它存在重复和复制输入的问题。为了避免重复,我们可以使用 Top-K 采样和 Top-p 采样。
- Top-K 采样——过滤 K 个最可能的下一个单词,并在这些 K 个下一个单词之间重新分配概率质量。
- Top-p 采样——不是只选择最可能的 K 个单词,而是选择累积概率超过概率 p 的最小可能单词集。
然后将概率质量重新分配到集合中的单词之间。因此,单词集合的大小可以根据下一个单词的概率分布动态地增加和减少。
使用 Intel® Extension for PyTorch 进行量化
什么是量化?
量化是对模型中所有或几层精度进行系统性降低。这意味着将深度学习中主要使用的高精度类型(如单精度浮点数 (FP32))转换为低精度类型(如 FP16(16 位)或 INT8(8 位))。
这有助于实现:
- 更低的内存带宽
- 更低的存储需求
- 在最小甚至零精度损失的情况下实现更高的性能
量化对于大型模型(例如基于 Transformer 架构的模型,如 BERT 或 GPT)尤为重要。
量化有两种类型:
- 静态量化——静态量化对模型的权重和激活进行量化。当内存带宽和计算节省都很重要时,使用这种量化。
- 动态量化——在动态量化中,权重是预先量化的,但激活是在推理过程中动态量化的。
适用于 PyTorch 的 Intel 扩展: Intel 扩展为 PyTorch 提供了最新的功能和优化,可在 Intel® 硬件上提供额外的性能提升。了解如何独立安装或作为Intel® AI Analytics Toolkit 的一部分获取。
该扩展可以作为 Python* 模块加载,也可以作为 C++ 库链接。Python 用户可以通过导入 intel_extension_for_pytorch 动态启用它。
- 此CPU 教程提供了有关适用于 Intel CPU 的 Intel Extension for PyTorch 的详细信息。源代码可在master 分支上获取。
- 此GPU 教程提供了有关适用于 Intel GPU 的 Intel Extension for PyTorch 的详细信息。源代码可在xpu-master 分支上获取。
如何使用 Intel Extension for PyTorch 执行动态量化?
以下是使用动态量化将现有 FP32 模型量化为 INT8 模型的步骤:
- 准备量化配置 – 我们可以使用带有 ipex.quantization.default_dynamic_qconfig 的默认动态量化配置。
- 通过使用 **ipex.quantization.prepare** 方法准备 FP32 模型(提供输入参数,例如要量化的 FP32 模型、准备好的配置、示例输入以及量化是否应就地进行的信息)。
- 将模型从 FP32 转换为 INT8 – 使用 **ipex.quantization.convert** 方法进行转换。输入模型将是步骤 2 中准备好的模型。
我们还鼓励您查看 Intel® Neural Compressor 工具,该工具可在多个深度学习框架中自动化流行的模型压缩技术,例如量化、剪枝和知识蒸馏。
代码示例
以下步骤在代码示例中实现:
- 加载模型和分词器:此步骤中使用 Transformers 库(查看 Intel® Extension for Transformers)和 Hugging Face 主类中可用的 Auto Classes。这些允许我们通过给定名称自动查找相关模型。它还允许轻松更改模型,而无需开发者在代码中进行重大更改,如下所示:
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModelForCausalLM.from_pretrained(model)模型参数被指定为分词器的输入,模型初始化只是预训练 DialoGPT 模型的路径。在此示例中,我们使用“microsoft/DialoGPT-large”。如果资源有限,您可以使用“microsoft/DialoGPT-medium”或“microsoft/DialoGPT-small”模型,并获得可比较的结果。
- 执行模型的动态量化
- 使用来自 Intel Extension for PyTorch 库的默认动态量化配置创建配置。
- 准备模型。
- 将模型从 FP32 转换为 INT8。
这些步骤在上面的部分中详细解释。
- **响应生成:**响应生成的第一步是编码输入句子,如以下代码所示:
new_input_ids = tokenizer.encode(input(">> You:") + tokenizer.eos_token, return_tensors='pt')在此示例中,我们希望模型保存历史记录,因此我们将输入句子以令牌的形式添加到聊天历史记录中。
bot_input_ids = torch.cat([chat_history_ids, new_input_ids], dim=-1) if chat_round > 0 else new_input_ids文本生成可以通过 model.generate 函数完成,我们可以在其中指定所有重要参数,例如保存的聊天历史记录、以令牌为单位的响应长度以及 Top-K 和 Top-p 采样的使用。
chat_history_ids = model.generate(bot_input_ids, do_sample=True, max_length=2000, top_k=50, top_p=0.95, pad_token_id=tokenizer.eos_token_id) 最后一步是解码并打印响应
- **交互式对话的准备:**响应生成后,最后一步是添加交互。这可以通过使用简单的 for 循环来完成。根据初始化的分词器、模型和空的聊天历史记录,为多个回合生成响应。
for chat_round in range(n):
chat_history_ids = generate_response(
tokenizer,
model,
chat_round,
chat_history_ids
)交互式聊天生成的一个示例如下图所示。

下一步是什么?
开始使用适用于 PyTorch 的 Intel Extension 和 DialoGPT 构建交互式聊天生成模型。下载并亲自试用Intel AI Analytics Toolkit 和适用于 PyTorch 的 Intel Extension,以构建各种端到端 AI 应用程序。
我们鼓励您查看并融入英特尔的其他AI/ML 框架优化和端到端工具组合到您的 AI 工作流程中,并了解构成英特尔AI 软件组合基础的统一、开放、基于标准的oneAPI 编程模型,以帮助您准备、构建、部署和扩展您的 AI 解决方案。
有关新的第四代 Intel® Xeon® 可扩展处理器的更多详细信息,请访问英特尔的 AI 解决方案平台门户,您可以在其中了解英特尔如何赋能开发者在这些强大的 CPU 上运行端到端 AI 管道。