我们有好消息!PyTorch 2.4 现已支持 Intel® 数据中心 GPU Max 系列和 SYCL 软件栈,让您更轻松地加速训练和推理的 AI 工作流程。此更新让您可以通过最少的编码工作获得一致的编程体验,并扩展了 PyTorch 的设备和运行时功能,包括设备、流、事件、生成器、分配器和防护,以无缝支持流式设备。此增强功能简化了 PyTorch 在普及硬件上的部署,让您更容易集成不同的硬件后端。
Intel GPU 支持已集成到 PyTorch 中,提供对即时(eager)模式和图模式的支持,并完全运行 Dynamo Hugging Face 基准测试。即时模式现在包含使用 SYCL 实现的常见 Aten 运算符。通过使用 oneAPI 深度神经网络库 (oneDNN) 和 oneAPI 数学核心库 (oneMKL),对性能最关键的图和运算符进行了高度优化。图模式 (torch.compile) 现在已启用 Intel GPU 后端,以实现 Intel GPU 的优化并集成 Triton。此外,还支持 FP32、BF16、FP16 等数据类型以及自动混合精度 (AMP)。基于 Kineto 和 oneMKL 的 PyTorch Profiler 正在为即将发布的 PyTorch 2.5 版本开发中。
请查看已集成到 PyTorch 中的 Intel GPU 当前和计划的前端和后端改进。
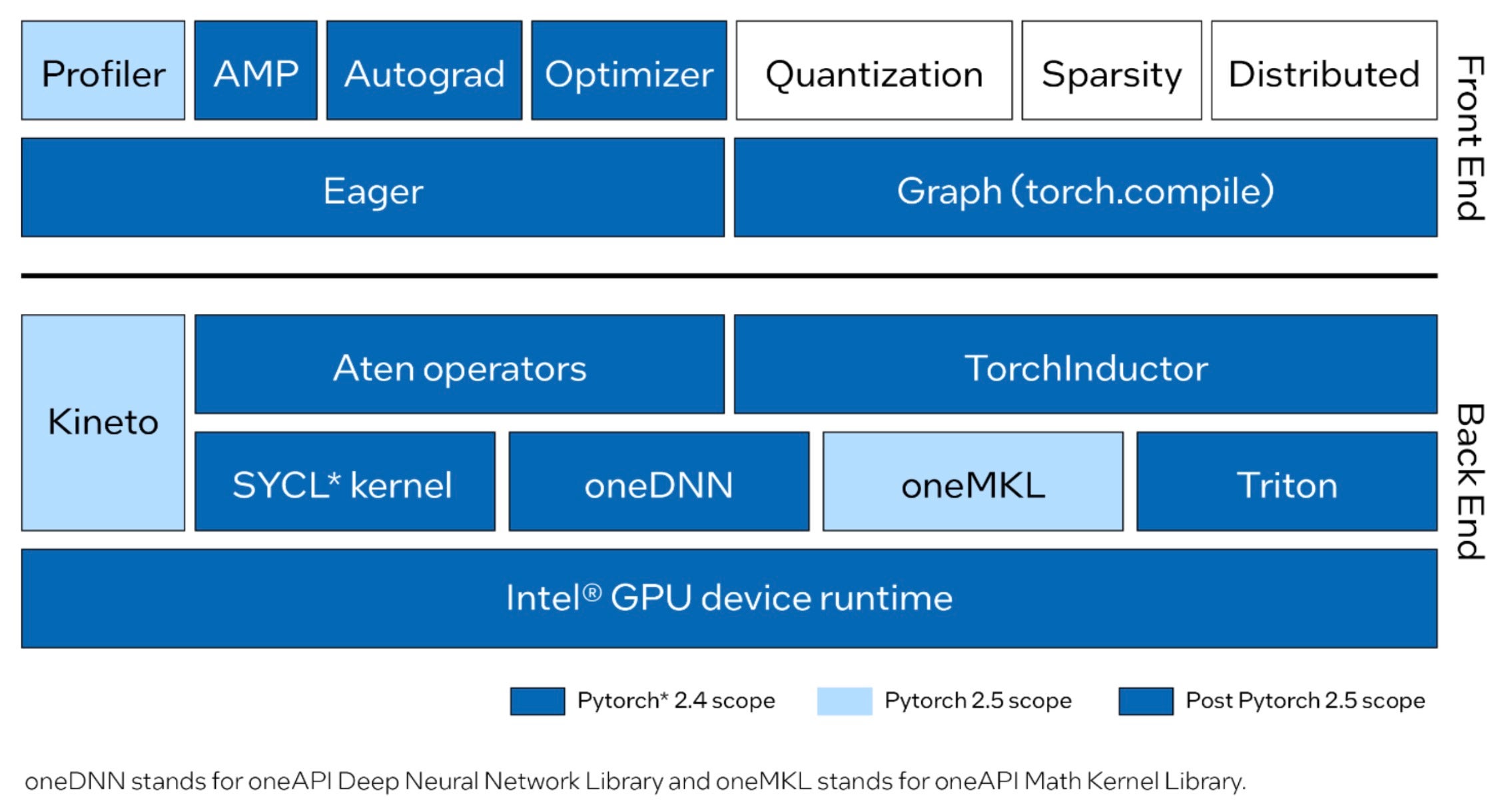
PyTorch 2.4 在 Linux 上支持 Intel 数据中心 GPU Max 系列进行训练和推理,同时保持与其他硬件相同的用户体验。如果您正在从 CUDA 迁移代码,您只需将设备名称从 cuda 更新为 xpu,即可在 Intel GPU 上运行您现有的应用程序,只需极少的更改。例如
# CUDA Code
tensor = torch.tensor([1.0, 2.0]).to("cuda")
# Code for Intel GPU
tensor = torch.tensor([1.0, 2.0]).to("xpu")
开始
通过 Intel® Tiber™ Developer Cloud 试用 Intel 数据中心 GPU Max 系列上的 PyTorch 2.4。了解 环境设置、源构建和示例。要了解如何创建免费的标准帐户,请参阅 开始使用,然后执行以下操作:
总结
PyTorch 2.4 引入了对 Intel 数据中心 GPU Max 系列的初步支持,以加速您的 AI 工作负载。借助 Intel GPU,您将获得持续的软件支持、统一的分发和同步的发布计划,从而获得更流畅的开发体验。我们正在增强此功能,以在 PyTorch 2.5 中达到 Beta 质量。2.5 中计划的功能包括:
- 即时模式下更多 Aten 运算符以及完整的 Dynamo Torchbench 和 TIMM 支持。
- torch.compile 中完整的 Dynamo Torchbench 和 TIMM 基准测试支持。
- torch.profile 中对 Intel GPU 的支持。
- PyPI wheel 分发。
- Windows 和 Intel 客户端 GPU 系列支持。
我们欢迎社区评估对 PyTorch 上的 Intel GPU 支持 的这些新贡献。
资源
致谢
我们要感谢 PyTorch 开源社区的技术讨论和见解:Nikita Shulga、Jason Ansel、Andrey Talman、Alban Desmaison 和 Bin Bao。
我们还要感谢 PyTorch 合作者提供的专业支持和指导。
1 为启用 GPU 支持并提高性能,我们建议安装 Intel® Extension for PyTorch。