PyTorch® 2.5 现已支持英特尔 GPU,为英特尔 GPU 提供改进的功能和性能,其中包括 Intel® Arc™ 独立显卡、内置 Intel® Arc™ 显卡的 Intel® Core™ Ultra 处理器 和 Intel® 数据中心 GPU Max 系列。此集成将英特尔 GPU 和 SYCL* 软件栈带入官方 PyTorch 栈,确保一致的用户体验,并支持更广泛的 AI 应用程序场景,尤其是在 AI PC 领域。
为英特尔 GPU 进行构建和使用的开发人员和客户将通过直接从原生 PyTorch 获取持续软件支持、统一的软件分发和一致的产品发布时间来获得更好的用户体验。
此外,英特尔 GPU 支持为用户提供了更多选择。现在 PyTorch 在前端和后端都提供了一致的 GPU 编程范式。开发人员现在可以用最少的编码工作在英特尔 GPU 上运行和部署工作负载。
英特尔 GPU 支持概述
PyTorch 中对英特尔 GPU 的支持提供了 PyTorch 内置前端的即时模式和图模式支持。即时模式现在使用 SYCL 编程语言实现了常用的 Aten 运算符。图模式 (torch.compile) 现在启用了英特尔 GPU 后端,以实现对英特尔 GPU 的优化并集成 Triton。
英特尔 GPU 支持的基本组件已添加到 PyTorch 中,包括运行时、Aten 运算符、oneDNN、TorchInductor、Triton 和英特尔 GPU 工具链集成。同时,量化和分布式正在积极开发中,为 PyTorch 2.6 版发布做准备。
功能
除了为英特尔® 客户端 GPU 和英特尔® 数据中心 GPU Max 系列提供推理和训练的关键功能外,PyTorch 还保持了与 PyTorch 支持的其他硬件相同的用户体验。如果您从 CUDA* 迁移代码,您可以通过最少的设备名称(从 cuda 到 xpu)代码更改在英特尔 GPU 上运行现有应用程序代码。例如:
# CUDA 代码
tensor = torch.tensor([1.0, 2.0]).to(“cuda”)
# 英特尔 GPU 代码
tensor = torch.tensor([1.0, 2.0]).to(“xpu”)
PyTorch 2.5 搭配英特尔 GPU 的功能包括:
- 推理和训练工作流程。
- 增强 torch.compile 和即时模式功能(更多运算符),同时改进性能,并完全运行即时和编译模式下的三个 Dynamo Hugging Face*、TIMM* 和 TorchBench* 基准测试。
- 数据类型,如 FP32、BF16、FP16 和自动混合精度 (AMP)。
- 在英特尔® 客户端 GPU 和英特尔® 数据中心 GPU Max 系列上运行。
- 支持 Linux(Ubuntu、SUSE Linux 和 Red Hat Linux)和 Windows 10/11。
入门
从 入门指南 了解英特尔® 客户端 GPU 和英特尔® 数据中心 GPU Max 系列上的环境设置、PIP wheel 安装和示例。通过每晚和预览二进制版本安装 PyTorch PIP wheel,可以体验英特尔 GPU 支持。
- 通过英特尔® Arc™ 显卡家族(代号 DG2)、内置英特尔® 显卡的英特尔® Core™ Ultra 处理器家族(代号 Meteor Lake)和内置英特尔® 显卡的英特尔® Core™ Ultra 移动处理器家族(代号 Lunar Lake)试用英特尔® 客户端 GPU。
- 通过 Intel® Tiber™ AI Cloud 试用英特尔数据中心 GPU Max 系列。
- 要了解如何创建免费的标准帐户,请参阅 入门。然后执行以下操作:
- 登录到 云控制台。
- 从 训练 部分,打开 英特尔 GPU 上的 PyTorch 笔记本并点击“启动 Jupyter Notebook”。
- 确保为笔记本选择了 PyTorch 2.5 内核。
- 要了解如何创建免费的标准帐户,请参阅 入门。然后执行以下操作:
性能
PyTorch 上英特尔 GPU 的性能经过持续优化,在即时模式和编译模式下的 Dynamo Hugging Face、TIMM 和 TorchBench 三个基准测试中取得了不错的成绩。
基于 PyTorch Dynamo 基准测试套件,使用英特尔® 数据中心 GPU Max 系列 1100 单卡测量的最新性能数据显示,图 1 显示了 FP16/BF16 在即时模式下相对于 FP32 的显著加速比,图 2 显示了 Torch.compile 模式相对于即时模式的加速比。推理和训练都取得了类似的显著改进。
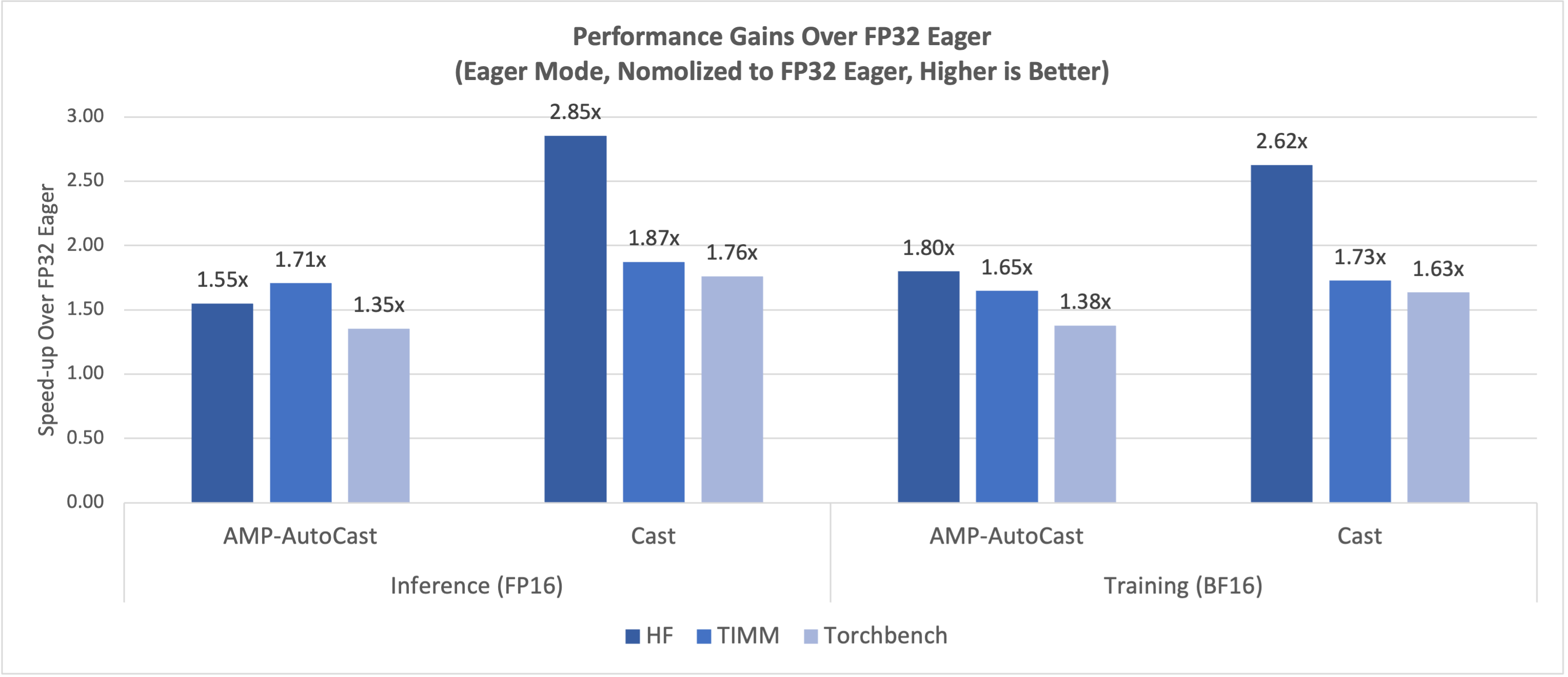
图 2:FP16/BF16 相对于 FP32 即时模式的性能提升
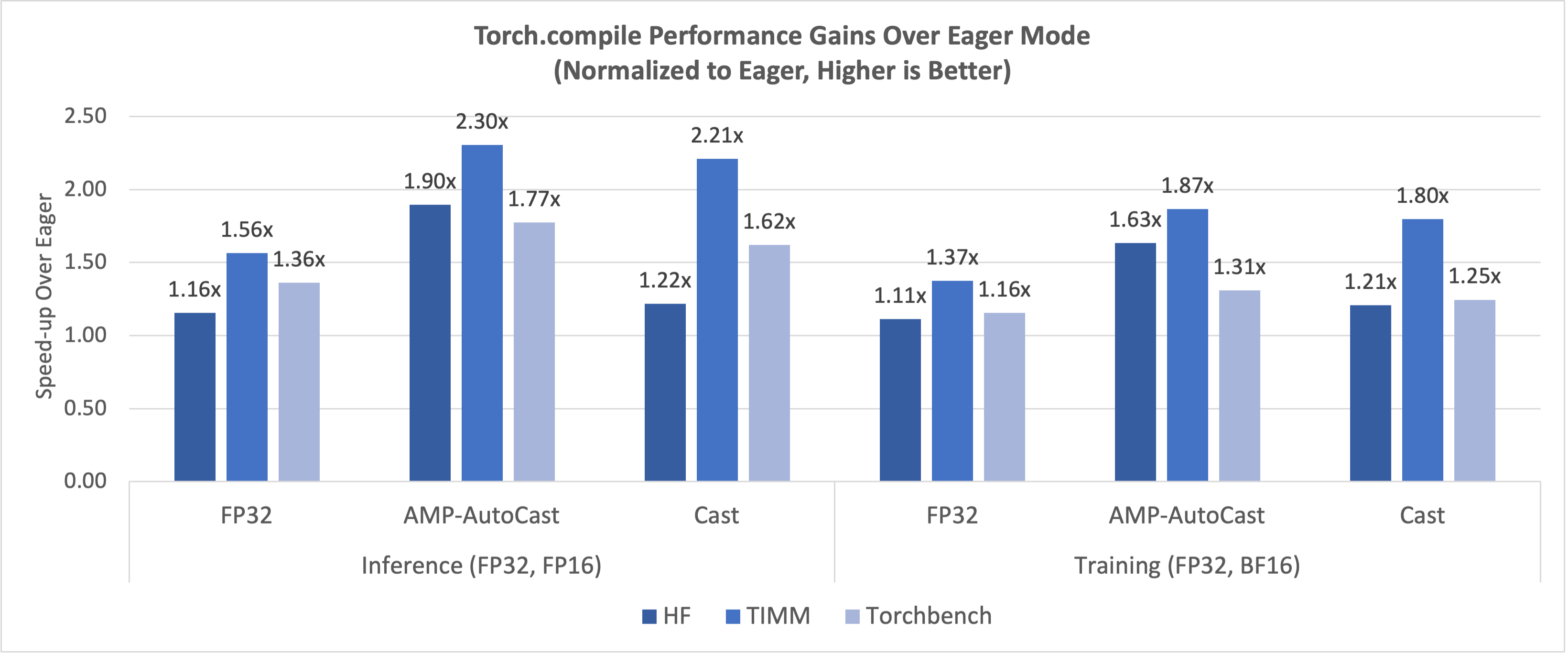
图 3:Torch.compile 相对于即时模式的性能提升
总结
PyTorch 2.5 上的英特尔 GPU 将英特尔® 客户端 GPU(内置英特尔® Arc™ 显卡的英特尔® Core™ Ultra 处理器和用于独立 GPU 的英特尔® Arc™ 显卡)和英特尔® 数据中心 GPU Max 系列引入 PyTorch 生态系统,以加速 AI 工作负载。特别是,客户端 GPU 已添加到 GPU 支持列表中,用于 Windows 和 Linux 环境下的 AI PC 使用场景。
我们热烈欢迎社区评估并提供关于 PyTorch 上英特尔 GPU 支持 这些增强功能的反馈。
资源
鸣谢
我们要感谢 PyTorch 开源社区的技术讨论和见解:Andrey Talman、Alban Desmaison、Nikita Shulga、Eli Uriegas、Jason Ansel 和 Bin Bao。
我们还要感谢 PyTorch 合作者提供的专业支持和指导。
性能配置
表中的配置是使用 svr-info 收集的。由英特尔于 2024 年 9 月 12 日测试。
表 1
| 组件 | 详情 |
|---|---|
| 名称 | 英特尔® Tiber™ 开发人员云中的英特尔® Max 系列 GPU 1100 |
| 时间 | 2024 年 9 月 12 日星期四 08:21:27 UTC |
| 系统 | 超微 SYS-521GE-TNRT |
| 主板 | 超微 X13DEG-OA |
| 机箱 | 超微 其他 |
| CPU 型号 | 英特尔® 至强® 白金 8468V |
| 微架构 | SPR_XCC |
| 插槽数 | 2 |
| 每插槽核心数 | 48 |
| 超线程 | 已启用 |
| CPU | 192 |
| 英特尔® 睿频加速技术 | 已启用 |
| 基频 | 2.4GHz |
| 全核最大频率 | 2.4GHz |
| 最大频率 | 2.9GHz |
| NUMA 节点数 | 2 |
| 预取器 | L2 HW: Enabled, L2 Adj.: Enabled, DCU HW: Enabled, DCU IP: Enabled, AMP: Disabled, Homeless: Disabled, LLC: Disabled |
| PPINs | 5e3f862ef7ba9d50, 6c85812edfcc84b1 |
| 加速器 | DLB 2, DSA 2, IAA 2, QAT (on CPU) 2, QAT (on chipset) 0 |
| 已安装内存 | 1024GB (16x64GB DDR5 4800 MT/s [4800 MT/s]) |
| 大页面大小 | 2048 kB |
| 透明大页面 | madvise |
| 自动 NUMA 平衡 | 已启用 |
| 网卡 | 2 个以太网控制器 X710 用于 10GBASE-T,4 个 MT2892 系列 [ConnectX-6 Dx] |
| 磁盘 | 1 个 894.3G Micron_7450_MTFDKBG960TFR |
| BIOS | 1.4a |
| 微码 | 0x2b0004b1 |
| 操作系统 | Ubuntu 22.04.2 LTS |
| 内核 | 5.15.0-73-generic |
| TDP | 330W |
| 电源与性能策略 | 正常 (6) |
| 频率调控器 | performance |
| 频率驱动 | acpi-cpufreq |
| 最大 C 状态 | 9 |
表 2
| 组件 | 详情 |
|---|---|
| 单卡 | 英特尔 Tiber 开发人员云中第四代英特尔® 至强® 处理器上的英特尔® Max 系列 GPU 1100 系列 |
| 工作负载与版本 | Timm ac34701, TorchBench 03cde49, Torchvision d23a6e1, Torchaudio b3f6f51, Transformers 243e186 |
| 软件栈 | intel-for-pytorch-gpu-dev 0.5.3, intel-pti-dev 0.9.0, Triton 的英特尔 xpu 后端 cc981fe |
| 框架 | Pytorch 4a3dabd67f8ce63f2fc45f278421cca3cc532cfe |
| GPU 驱动 | agama-ci-devel-803.61 |
| GFX 固件版本 | PVC2_1.23374 |
注意事项与免责声明
性能因使用、配置和其他因素而异。请访问性能指数网站了解更多信息。性能结果基于所示配置下的测试日期,可能无法反映所有公开发布的更新。 请参阅备份以获取配置详情。 没有任何产品或组件是绝对安全的。您的成本和结果可能有所不同。英特尔技术可能需要启用硬件、软件或服务激活。
英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能属于他人所有。
AI 免责声明
AI 功能可能需要软件购买、订阅或由软件或平台提供商启用,或者可能有特定的配置或兼容性要求。详情请访问 www.intel.com/AIPC。结果可能有所不同。