使用3D可视化矩阵乘法表达式、带有真实权重的注意力头等等。
矩阵乘法(matmuls)是当今机器学习模型的基本组成部分。本文介绍了一个名为 mm 的可视化工具,用于显示矩阵乘法及其组合。
矩阵乘法本质上是一种三维操作。由于mm利用了所有三个空间维度,因此它比通常在纸上绘制的二维图形能够更清晰、更直观地传达含义,特别是(但不限于)对于视觉/空间型思维者。
我们还有空间以几何一致的方式**组合**矩阵乘法——这样我们就可以使用与简单表达式相同的规则来可视化注意力头和MLP层等大型复合结构。更高级的功能,例如动画演示不同的矩阵乘法算法、用于并行化的分区以及加载外部数据以探索实际模型的行为,都自然地建立在此基础上。
mm是完全交互式的,在浏览器中运行,并将其完整状态保存在URL中,因此链接是可共享的会话(本文中的截图和视频都包含打开相应可视化工具的链接)。此参考指南描述了所有可用功能。
我们首先介绍可视化方法,通过可视化一些简单的矩阵乘法和表达式来建立直观认识,然后深入探讨一些更扩展的示例。
- 核心思想 – 为什么这种可视化方式更好?
- 热身 – 动画 – 观看经典的矩阵乘法分解过程
- 热身 – 表达式 – 快速浏览一些基本表达式构建块
- 深入了解注意力头 – 通过NanoGPT深入了解GPT2中几个注意力头的结构、值和计算行为
- 注意力并行化 – 通过最近的Blockwise Parallel Transformer论文中的示例可视化注意力头并行化
- 注意力层中的尺寸 – 当我们将整个注意力层视为一个单一结构时,MHA和FFA两部分组合起来是什么样子?在自回归解码过程中,图像如何变化?
- LoRA – 对注意力头架构这一扩展的视觉解释
- 总结 – 后续步骤和反馈征集
1 核心思想
mm的可视化方法基于一个前提:矩阵乘法本质上是一种三维操作。
换句话说,这个
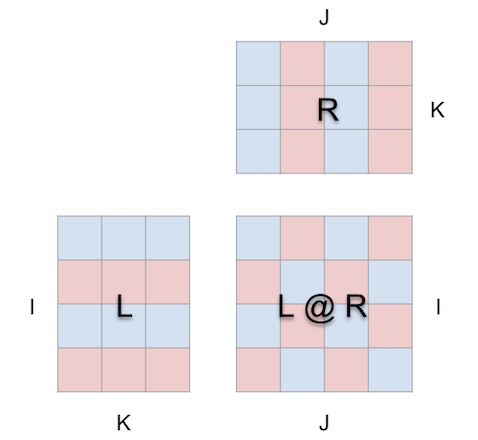
是一张试图变成这样的纸(在mm中打开)

当我们这样将矩阵乘法围绕一个立方体时,参数形状、结果形状和共享维度之间的正确关系都清晰地展现出来。
现在,计算过程具有了**几何意义**:结果矩阵中的每个位置`i, j`锚定了一个沿着立方体内部深度维度`k`运行的向量,其中从`L`的行`i`延伸的水平平面与从`R`的列`j`延伸的垂直平面相交。沿着这个向量,来自左参数和右参数的`(i, k)`和`(k, j)`元素对相遇并相乘,结果乘积沿着`k`求和,并将结果存入结果矩阵的`i, j`位置。
(暂时跳过,这是一个动画)。
这就是矩阵乘法的**直观**含义:
- **将**两个正交矩阵**投影**到立方体内部
- **将**每个交点处的值对**相乘**,形成一个乘积网格
- **沿着**第三个正交维度**求和**,得到结果矩阵。
为了方便定位,工具在立方体内部显示一个指向结果矩阵的箭头,其中蓝色箭头来自左参数,**红**色箭头来自**右**参数。工具还会显示白色参考线以指示每个矩阵的行轴,尽管在此截图中它们很淡。
布局约束很简单:
- 左参数和结果必须沿着它们共享的**高度**(i)维度相邻
- 右参数和结果必须沿着它们共享的**宽度**(j)维度相邻
- 左参数和右参数必须沿着它们共享的(左宽度/右高度)维度相邻,该维度成为矩阵乘法的**深度**(k)维度
这种几何结构为我们可视化所有标准矩阵乘法分解提供了坚实的基础,也为探索非平凡复杂的矩阵乘法**组合**提供了直观的基础,我们将在下文看到。
2 热身 – 动画
在深入研究一些更复杂的示例之前,我们将通过几个直观的构建器来感受这种可视化风格的外观和感觉。
2a 点积
首先是经典算法——通过计算相应左行和右列的点积来计算每个结果元素。我们在动画中看到的是乘积值向量在立方体内部的扫过,每个向量都在相应位置产生一个求和结果。
在这里,`L`的行块填充了1(蓝色)或-1(红色);`R`的列块也类似填充。这里的`k`是24,所以结果矩阵(`L @ R`)的蓝色值为24,红色值为-24(在mm中打开 – 长按或Ctrl+点击以检查值)。
2b 矩阵-向量乘积
一个分解为矩阵-向量乘积的矩阵乘法看起来像一个垂直平面(左参数与右参数的每一列的乘积),当它水平扫过立方体内部时,将列绘制到结果上(在mm中打开)。
即使在简单的例子中,观察分解的中间值也可能非常有趣。
例如,请注意当我们使用随机初始化的参数时,中间矩阵-向量乘积中出现的显著垂直模式——这反映了每个中间乘积都是左参数的列缩放副本这一事实(在mm中打开)。
2c 向量-矩阵乘积
一个分解为向量-矩阵乘积的矩阵乘法看起来像一个水平平面,当它下降穿过立方体内部时,将行绘制到结果上(在mm中打开)。
切换到随机初始化的参数时,我们看到与矩阵-向量乘积中类似的模式——只是这次模式是水平的,这与每个中间向量-矩阵乘积是右参数的行缩放副本这一事实相对应。
在思考矩阵乘法如何表达其参数的秩和结构时,想象这两种模式在计算中同时发生是很有用的(在mm中打开)。
这是另一个使用向量-矩阵乘积的直观构建器,它展示了单位矩阵如何像一面45度角镜子一样,同时反射其对立参数和结果(在mm中打开)。
2d 求和外积
第三种平面分解是沿着`k`轴,通过向量外积的逐点求和来计算矩阵乘法结果。在这里,我们看到外积平面“从后到前”扫过立方体,并累积到结果中(在mm中打开)。
使用这种分解方法随机初始化矩阵时,我们不仅可以看到值,还可以看到**秩**在结果中累积,因为每个秩1外积都被添加到其中。
这有助于直观地理解为什么“低秩分解”(即通过构建一个深度维度较小的矩阵乘法来近似一个矩阵)在被近似矩阵是低秩时效果最好。后面章节中的LoRA(在mm中打开)将对此进行详细解释。
3 热身 – 表达式
我们如何将这种可视化方法扩展到矩阵乘法的**组合**?到目前为止,我们的示例都可视化了一个单一的矩阵乘法`L @ R`,其中`L`和`R`是某些矩阵——那么当`L`和/或`R`本身也是矩阵乘法,并以此类推时会怎样呢?
事实证明,我们可以很好地将该方法扩展到复合表达式。关键规则很简单:子表达式(子)矩阵乘法是另一个立方体,遵循与父级相同的布局约束,并且子级的**结果面**同时是父级的相应**参数面**,就像共价共享的电子一样。
在这些约束下,我们可以随意排列子矩阵乘法的各个面。这里我们使用工具的默认方案,它生成交替的凸形和凹形立方体——这种布局在实践中能很好地最大化空间利用率并最小化遮挡。(然而,布局是完全可定制的——详细信息请参阅参考指南。)
本节中,我们将可视化ML模型中的一些关键构建块,以熟悉视觉表达方式,并了解即使是简单的示例也能给我们带来哪些直观认识。
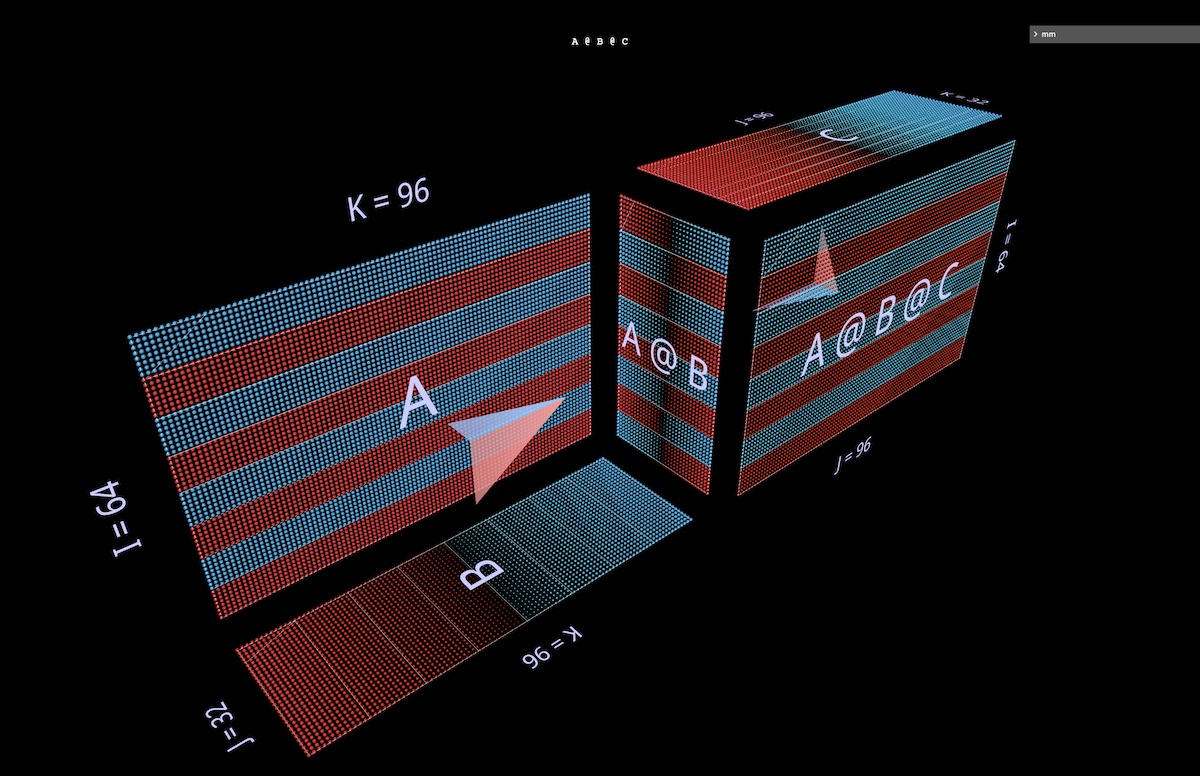
3a 左结合表达式
我们将看到两个`(A @ B)@ C`形式的表达式,每个表达式都有其独特的形状和特征。(注意:mm遵循矩阵乘法是左结合的约定,并将其简写为`A @ B @ C`。)
首先,我们将给`A @ B @ C`赋予典型的FFN形状,其中“隐藏维度”比“输入”或“输出”维度更宽。(具体来说,在这个示例的上下文中,这意味着`B`的宽度大于`A`或`C`的宽度。)
与单个矩阵乘法示例一样,浮动箭头指向结果矩阵,蓝色箭头来自左参数,红色箭头来自右参数(在mm中打开)。

接下来,我们将可视化`A @ B @ C`,其中`B`的宽度**窄于**`A`或`C`的宽度,使其具有瓶颈或“自编码器”形状(在mm中打开)。
这种凸凹块交替的模式可以扩展到任意长度的链:例如,这个多层瓶颈结构(在mm中打开)。

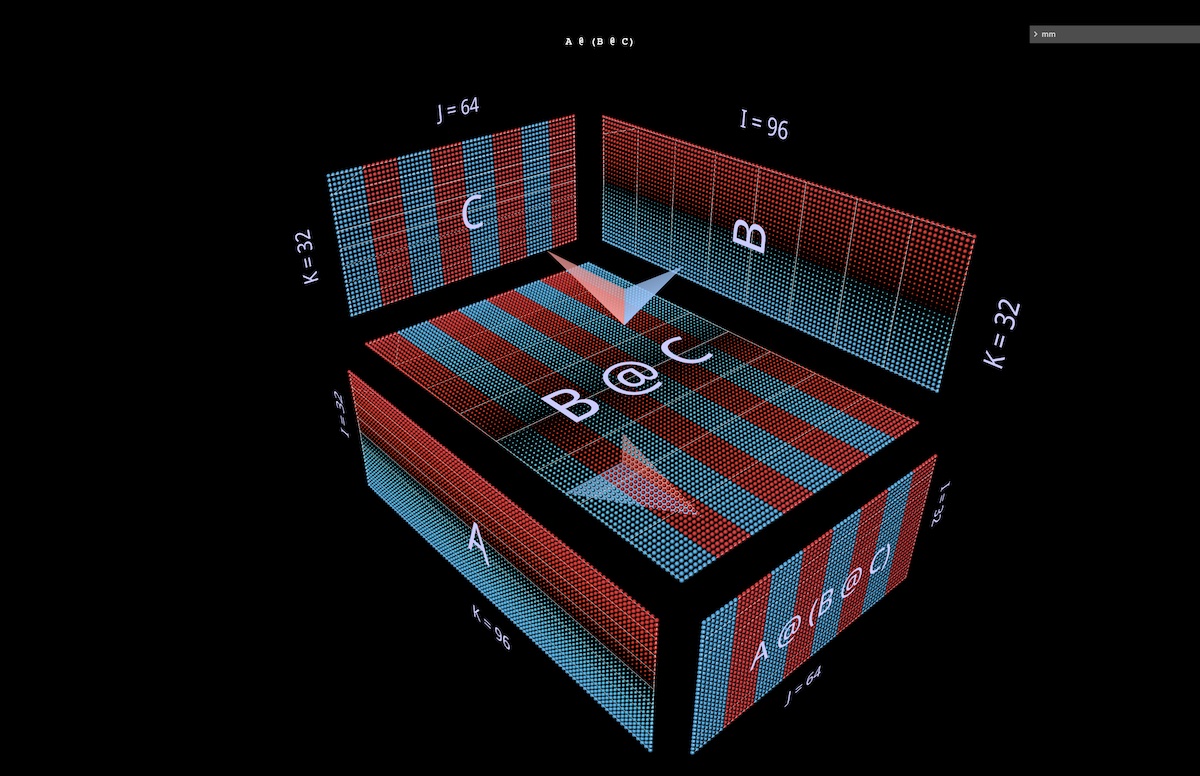
3b 右结合表达式
接下来,我们将可视化一个右结合表达式`A @ (B @ C)`。
左结合表达式水平延伸——可以这么说,从根表达式的左参数萌芽——同样,右结合链垂直延伸,从根表达式的右参数萌芽。
有时会将MLP公式化为右结合,即右侧是列输入,权重层从右向左运行。使用上图中2层FFN示例中的矩阵——适当转置——这里显示的是它看起来的样子,其中`C`现在扮演输入的角色,`B`是第一层,`A`是第二层(在mm中打开)。
除了箭头扇叶的颜色(左参数为蓝色,右参数为红色)之外,区分左右参数的第二个视觉线索是它们的**方向**:左参数的行与结果的行共面——它们沿着相同的轴(`i`)堆叠。这两个线索都告诉我们,例如,`B`是上面`(B @ C)`的左参数。
3c 二元表达式
为了让可视化工具除了简单的教学示例之外还能发挥作用,随着表达式变得更复杂,可视化效果需要保持清晰。实际用例中的一个关键结构组件是二元表达式——左右两侧都有子表达式的矩阵乘法。
在这里,我们将可视化最简单的这种表达式形状:`(A @ B) @ (C @ D)`(在mm中打开)。

3d 快速旁注:分区和并行化
本文不打算全面介绍这个主题,但我们稍后会在注意力头的背景下看到它的实际应用。不过作为热身,两个快速示例应该能让大家了解这种可视化风格如何通过简单的几何分区直观地推断复合表达式的并行化。
在第一个例子中,我们将经典的“数据并行”分区应用于上述左结合多层瓶颈示例。我们沿着`i`轴进行分区,分割初始左参数(“批次”)和所有中间结果(“激活”),但不分割任何后续参数(“权重”)——几何结构清晰地表明表达式中哪些参与者被分割,哪些保持完整(在mm中打开)。

第二个例子(至少对我来说)如果没有清晰的几何结构支持,将更难建立直觉:它展示了如何通过将左子表达式沿着其`j`轴分区,右子表达式沿着其`i`轴分区,以及父表达式沿着其`k`轴分区来实现二元表达式的并行化(在mm中打开)。

4 深入了解注意力头
我们来看看一个GPT2注意力头——具体来说是来自NanoGPT的“gpt2”(小型)配置(层=12,头=12,嵌入=768)的第5层第4个头,使用通过HuggingFace获取的OpenAI权重。输入激活取自对256个token的OpenWebText训练样本的前向传播。
这个特定的注意力头并没有什么特别不寻常的地方;我选择它主要是因为它计算了一种相当常见的注意力模式,并且位于模型的中间,激活已经结构化并显示出一些有趣的纹理。(附注:在后续的笔记中,我将介绍一个注意力头探索器,它允许您可视化此模型的所有层和头,并附带一些旅行笔记。)
在mm中打开 (可能需要几秒钟来获取模型权重)
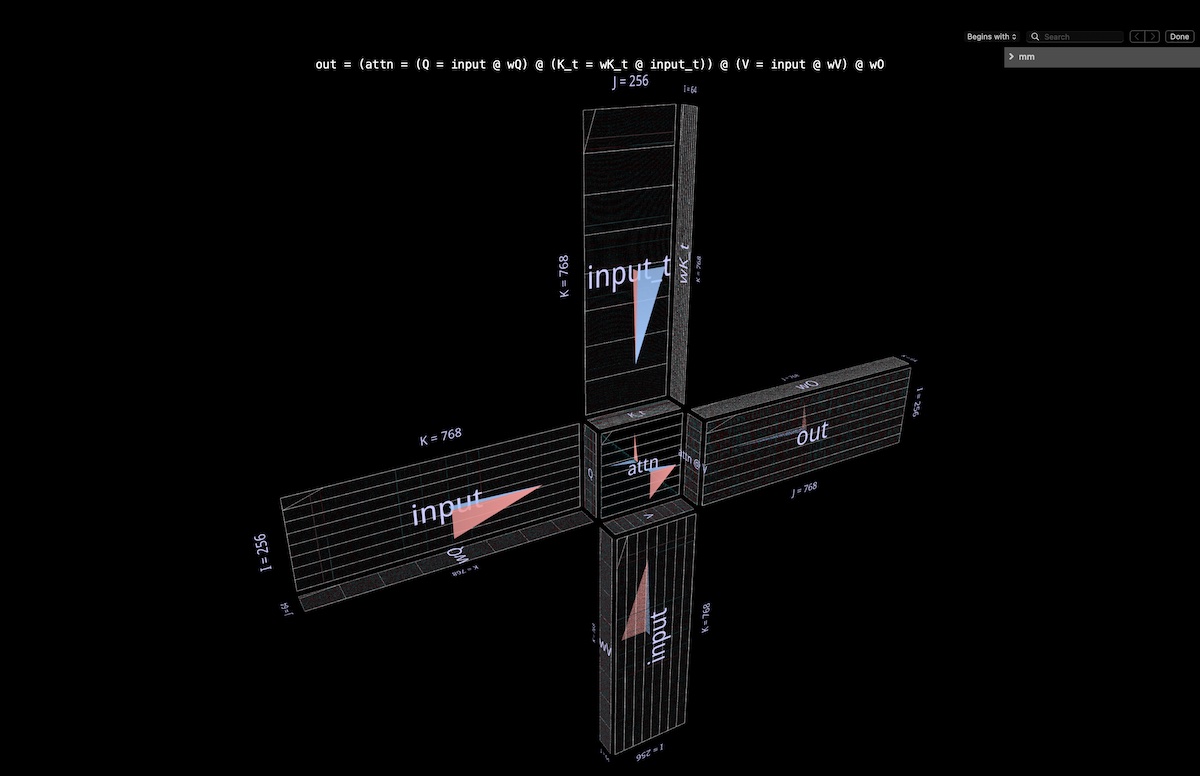
4a 结构
整个注意力头被可视化为一个单一的复合表达式,从输入开始,到投影输出结束。(注意:为了保持内容的自包含性,我们按照Megatron-LM中描述的方式进行每个头的输出投影。)
计算包含六个矩阵乘法
Q = input @ wQ // 1
K_t = wK_t @ input_t // 2
V = input @ wV // 3
attn = sdpa(Q @ K_t) // 4
head_out = attn @ V // 5
out = head_out @ wO // 6
我们所看到的简要描述:
- 风车叶片是矩阵乘法1、2、3和6:前者是将输入投影到Q、K和V;后者是将attn @ V投影回嵌入维度。
- 中心是双重矩阵乘法,首先计算注意力分数(后方的凸形立方体),然后利用它们从值向量生成输出token(前方的凹形立方体)。因果关系意味着注意力分数形成一个下三角形。
但我鼓励大家在工具中探索此示例,而不是依赖截图或下面的视频来传达它可以从中获取多少信号——关于其结构以及流经计算的实际值。
4b 计算与值
这是注意力头计算的动画。具体来说,我们正在观察:
sdpa(input @ wQ @ K_t) @ V @ wO
(即,上面的矩阵乘法1、4、5和6,其中`K_t`和`V`是预计算的)被计算为向量-矩阵乘法的融合链:序列中的每个项都一步从输入经过注意力机制到达输出。关于此动画选择的更多内容将在稍后的并行化部分中讨论,但首先让我们看看正在计算的值告诉我们什么。
这里有很多有趣的事情。
- 甚至在我们进行注意力计算之前,`Q`和`K_t`的低秩特性就非常引人注目。放大 Q @ K_t 向量-矩阵乘积动画,情况更加生动:`Q`和`K`中相当一部分通道(嵌入位置)在整个序列中看起来或多或少保持不变,这意味着有用的注意力信号可能仅由嵌入的一小部分子集驱动。理解和利用这种现象是我们SysML ATOM transformer效率项目正在研究的线索之一。
- 也许最常见的是在注意力矩阵中出现的强烈但不完全的对角线。这是一种常见模式,出现在该模型的许多注意力头中(以及许多Transformer的注意力头中)。它产生**局部化**的注意力:输出token位置之前的小邻域中的值token在很大程度上决定了该输出token的内容模式。
- 然而,这个邻域的大小以及其中单个token的影响程度是显著变化的——这在注意力网格的非对角线“霜冻”中以及在attn[i] @ V 向量-矩阵乘积平面下降注意力矩阵并穿过序列时所呈现的**波动模式**中可以看出。
- 但请注意,局部邻域并非唯一吸引注意力的地方:注意力网格最左侧的列(对应序列的第一个token)完全填充了非零(但波动)值,这意味着每个输出token都会在某种程度上受到第一个值token的影响。
- 此外,当前 token 邻域与初始 token 之间存在不精确但可辨别的注意力分数主导地位振荡,发生在当前token邻域与初始token之间。振荡周期不同,但总体而言,随着序列的推进,周期从短到长(与每个行对应的候选注意力token数量有着令人回味的关联,考虑到因果关系)。
- 要了解`(attn @ V)`是如何形成的,重要的是不要孤立地关注注意力——`V`是同等重要的参与者。每个输出项都是整个`V`向量的加权平均值:在注意力完美对角线的极限情况下,`attn @ V`只是`V`的精确副本。这里我们看到了更具纹理感的东西:在注意力行的连续子序列中,某些token得分很高,形成了可见的条纹,叠加在一个明显类似于`V`但由于粗对角线而有一些垂直模糊的矩阵上。(附注:根据mm参考指南,长按或Ctrl+点击将显示可视化元素的实际数值。)
- 请记住,由于我们处于中间层 (5),因此此注意力头的输入是中间表示,而不是原始的分词文本。因此,输入中看到的模式本身就发人深省——特别是,强大的垂直线程是特定的嵌入位置,其值在序列的长时间段(有时几乎是整个序列)中均匀地保持高幅值。
- 然而,有趣的是,输入序列中的第一个向量具有独特性,不仅打破了这些高幅度列的模式,而且在几乎每个位置都携带了非典型值(旁注:此处未可视化,但此模式在多个样本输入中重复)。
注意:关于最后两点,值得重申的是,我们正在可视化对*单个样本输入*的计算。实际上,我发现每个头都会在一系列样本中持续(但不完全相同)地表达其特征模式(即将推出的注意力头浏览器将提供一系列样本供您试用),但在查看任何包含激活的可视化时,务必记住,完整的输入分布可能会以微妙的方式影响它所激发的想法和直觉。
最后,再推荐一次直接探索动画!
4c 注意力头在有趣方面有所不同
在我们继续之前,这里再演示一个简单地探究模型以详细了解其工作方式的实用性。
这是 GPT2 的另一个注意力头。它的行为与上面的第 5 层、第 4 个头截然不同——正如人们所预期的那样,因为它位于模型的非常不同的部分。这个头在第一层:第 0 层、第 2 个头 (在mm中打开,可能需要几秒钟加载模型权重)。

注意事项
- 此注意力头将注意力均匀地分散。这使得 `attn @ V` 中的每一行都能获得 `V` 的相对**未加权**平均值(或者更确切地说,是 `V` 的适当因果前缀),如此动画中所示:随着我们沿着注意力分数三角形向下移动,`attn[i] @ V` 向量矩阵乘积与简单的 `V` 的缩小、逐步显示的副本之间存在微小波动。
attn @ V具有惊人的垂直一致性——在嵌入的大部分列区域中,相同的值模式在**整个序列**中持续存在。可以将这些视为每个标记共享的属性。- 旁注:一方面,考虑到注意力均匀分散的效果,人们可能会期望`attn @ V`中存在**某种**均匀性。但是,每一行都是由`V`的因果子序列而不是整个序列构建的——为什么这没有引起更多的变化,比如随着序列向下移动而逐渐变形?通过视觉检查,V 的长度并不一致,因此答案必须在于其值分布的某些更微妙的特性。
- 最后,这个头的输出在进行外投影后,甚至在垂直方向上更加均匀。
- 总的来说,这种注意力头所产生的极其规则、高度结构化的信息,很可能是通过一些**不那么奢侈**的计算方式获得的,这种想法难以抗拒。当然,这不是一个未开发的领域,但可视化计算的特异性和信号的丰富性,对于产生新想法和推理现有想法很有用。
总的来说,很难抗拒这样的想法:这种注意力头所产生的极其规律、高度结构化的信息,可能是通过一种稍微……不那么铺张浪费的计算方式获得的。当然,这不是一个未探索的领域,但可视化计算的特异性和丰富的信号,对于产生新想法和推理现有想法很有用。
4d 重访核心观点:免费的不变性
回过头来看,值得重申的是,我们之所以能够可视化像注意力头这样非平凡的复合操作并保持其直观性,是因为重要的代数属性——例如参数形状如何受限,或者哪些并行化轴与哪些操作相交——**不需要额外的思考**:它们直接源于可视化对象的几何形状,而不是需要记住的附加规则。
例如,在这些注意力头可视化中,立即显而易见的是
Q和attn @ V长度相同,K和V长度相同,并且这些对的长度相互独立。Q和K宽度相同,V和attn @ V宽度相同,并且这些对的宽度相互独立。
这些属性是通过构造实现的,是构成部分在复合结构中的位置及其方向的简单结果。
这种“免费的属性”优势在探索规范结构的变化时特别有用——一个显而易见的例子是自回归逐个 token 解码中的单行高注意力矩阵 (在mm中打开)。

5 并行化注意力
在上面第 5 层、第 4 个注意力头的动画中,我们可视化了注意力头中的 6 个矩阵乘法中的 4 个
作为向量-矩阵乘法的融合链,证实了几何直觉,即从输入到输出的整个左结合链沿共享的 `i` 轴是**层状的**,并且可以并行化。
5a 示例:沿 `i` 轴分区
为了在实践中并行化计算,我们将沿 `i` 轴将输入划分为块。我们可以在工具中可视化此分区,方法是指定给定轴分区为特定数量的块——在这些示例中,我们将使用 8,但这并不是一个特殊的数字。
除其他事项外,此可视化清楚地表明,`wQ`(用于内投影)、`K_t` 和 `V`(用于注意力)以及 `wO`(用于外投影)需要由每个并行计算完全使用,因为它们与分区矩阵沿这些矩阵的未分区维度相邻(在mm中打开)。

5b 示例:双重分区
作为沿**多个**轴进行分区的示例,我们可以可视化此领域中的一些最新工作(块并行Transformer,其基础是Flash Attention及其前身等工作)。
首先,BPT 沿 `i` 轴进行分区,如上所述——并且实际上将序列的这种水平分区一直扩展到注意力层的第二个 (FFN) 半部分。 (我们将在后面的部分中可视化这一点。)
为了彻底解决上下文长度问题,然后向 MHA 添加了第二个分区——即注意力计算本身的分区(即,沿 `Q @ K_t` 的 `j` 轴的分区)。这两个分区一起将注意力划分为一个块网格(在mm中打开)。

这个可视化清晰地说明了
- 这种双重分区作为解决上下文长度问题的方法的有效性,因为我们现在已经明显地将注意力计算中所有出现的序列长度进行了分区
- 这种第二种分区的“范围”:从几何学上可以清楚地看出,`K` 和 `V` 的内投影计算可以与核心双矩阵乘法一起分区。
请注意一个微妙之处:此处视觉上的含义是,我们也可以将后续的矩阵乘法 `attn @ V` 沿 `k` 轴并行化,并以 split-k 风格求和部分结果,从而并行化整个双矩阵乘法。但是 `sdpa()` 中的逐行 softmax 增加了这样一种要求,即每行必须在其所有段都被归一化后才能计算 `attn @ V` 的相应行,从而在注意力计算和最终矩阵乘法之间增加了一个额外的逐行步骤。
6 注意力层中的大小
注意力层的前半部分(MHA)因其二次复杂度而计算量巨大,但后半部分(FFN)由于其隐藏维度的宽度(通常是模型嵌入维度的4倍)而同样计算量巨大。可视化整个注意力层的生物量有助于直观理解该层的两半如何相互比较。
6a 可视化完整层
下面是一个完整的注意力层,前半部分(MHA)在背景中,后半部分(FFN)在前景中。和往常一样,箭头指向计算方向。
注意事项
- 此可视化不描绘单个注意力头,而是显示环绕中心双矩阵乘法的未切片 Q/K/V 权重和投影。当然,这不是对完整 MHA 操作的忠实可视化——但这里的目标是更清晰地呈现层两半中相对矩阵**大小**的感觉,而不是每半部分执行的相对计算量。(此外,使用随机值而非真实权重。)
- 这里使用的维度已缩小以使浏览器(相对)流畅,但比例保持不变(来自 NanoGPT 的小配置):模型嵌入维度 = 192(从 768 缩小),FFN 嵌入维度 = 768(从 3072 缩小),序列长度 = 256(从 1024 缩小),尽管序列长度对模型来说不是根本性的。(视觉上,序列长度的变化将表现为输入叶片宽度的变化,以及随之而来的注意力中心大小和下游垂直平面高度的变化。)

6b 可视化 BPT 分区层
再次简要回顾Blockwise Parallel Transformer,这里我们在整个注意力层的背景下可视化 BPT 的并行化方案(如上所述,省略了单个注意力头)。特别注意沿 `i` 轴(序列块)的分区如何延伸到 MHA 和 FFN 两半部分(在mm中打开)。

6c 分区 FFN
可视化建议进行额外的分区,与上述分区正交——在注意力层的 FFN 半部分,拆分双矩阵乘法 `(attn_out @ FFN_1) @ FFN_2`,首先沿 `j` 轴用于 `attn_out @ FFN_1`,然后沿 `k` 轴用于与 `FFN_2` 的后续矩阵乘法。此分区切片 FFN 的两层权重,以部分结果的最终求和为代价,降低了计算中每个参与者的容量要求。
这是应用于未分区注意力层的分区(在mm中打开)。

这是应用于 BPT 分层分区的层 (在mm中打开)。

6d 可视化逐个 token 解码
在自回归的逐个 token 解码过程中,查询向量由单个 token 组成。设想一下注意力层在这种情况下是什么样子是很有启发性的——一个单一的嵌入行在一个巨大的平铺权重平面中运行。
除了强调与激活相比权重本身的巨大性之外,这种视图还暗示了 `K_t` 和 `V` 在 6 层 MLP 中像动态生成的层一样工作,尽管 MHA 本身的多路复用/解复用计算(如上所述在此处被掩盖)使对应关系不精确(在mm中打开)。

7 LoRA
最近的 LoRA 论文 (LoRA: Low-Rank Adaptation of Large Language Models) 描述了一种高效的微调技术,其基础思想是微调过程中引入的权重增量是低秩的。根据论文,这“使我们能够通过优化密集层在适应过程中变化的秩分解矩阵[...]来间接训练神经网络中的一些密集层,同时保持预训练权重不变。”
7a 基本思想
简而言之,关键的举措是训练权重矩阵的因子,而不是矩阵本身:用一个I x K张量与一个K x J张量的矩阵乘法来替换一个I x J的权重张量,其中K为一个较小的数字。
如果K足够小,尺寸上的节省会非常可观,但权衡是降低K会降低乘积所能表达的秩。为了快速说明尺寸节省和结果的结构化效果,这里是一个随机128 x 4左参数和4 x 128右参数的矩阵乘法——也就是一个128 x 128矩阵的秩为4的分解。注意L @ R中的垂直和水平图案(在mm中打开)。

7b 将LoRA应用于注意力头
LoRA 将这种分解方法应用于微调过程的方式是:
- 为每个要微调的权重张量创建低秩分解并训练这些因子,同时保持原始权重冻结。
- 微调后,将每对低秩因子相乘,得到一个与原始权重张量形状相同的矩阵,并将其添加到原始预训练权重张量中。
以下可视化展示了一个注意力头,其中权重张量wQ、wK_t、wV、wO被低秩分解wQ_A @ wQ_B等替换。在视觉上,因子矩阵在风车叶片的边缘显示为低矮的栅栏(在mm中打开 – 按空格键停止旋转)。
8 总结
8a 征求反馈
我发现这种可视化矩阵乘法表达式的方法对于建立直觉和推理矩阵乘法本身以及机器学习模型及其计算的许多方面(从效率到可解释性)都非常有帮助。
如果你尝试过并有任何建议或意见,我非常想听,可以在这里的评论区或者在仓库中。
8b 后续步骤
- 目前有一个GPT2注意力头探索器是基于这个工具构建的,我正在用它来清点和分类在该模型中发现的注意力头特征。(这个工具就是我在这篇笔记中用来发现和探索注意力头的工具。)完成后,我计划发布一篇包含清单的笔记。
- 如上所述,将这些可视化嵌入到 Python 笔记本中非常简单。但会话 URL 可能会变得…笨重,因此拥有 Python 端的实用工具来从配置对象构建它们将很有用,类似于参考指南中使用的简单 JavaScript 辅助工具。
- 如果你有一个你认为可能受益于这种可视化但又不清楚如何使用该工具来实现的用例,请联系我!我不一定寻求进一步扩展其核心可视化功能(适合这项工作的工具等等),但例如,以编程方式驱动它的 API 非常基础,在这方面还有很多可以做的事情。