总结
PyTorch 分布式检查点 (DCP) 正在投入解决互操作性障碍,以确保像 HuggingFace safetensors 这样的流行格式能够与 PyTorch 生态系统良好协作。由于 HuggingFace 已成为推理和微调领域的主导格式,DCP 开始支持 HuggingFace safetensors。这些更改的第一个客户是 torchtune,他们看到了改进的用户体验,因为他们现在可以直接使用 DCP API 清晰地读写 HuggingFace。
问题
由于 HuggingFace 被广泛使用,拥有超过 500 万用户,许多机器学习工程师希望以 safetensors 格式保存和加载他们的检查点,以便轻松地与他们的生态系统协作。通过在 DCP 中原生支持 safetensors 格式,我们的用户的检查点操作在以下方面得到简化:
- DCP 目前有自己的自定义格式,因此希望使用 HuggingFace 模型但又想利用 DCP 的 性能优势 和功能的用户,必须构建自定义转换器和组件,才能在两个系统之间工作。
- 用户不再需要每次都将检查点下载和上传到本地存储,HuggingFace 模型现在可以直接保存和加载到他们选择的 fsspec 支持的存储中。
如何使用
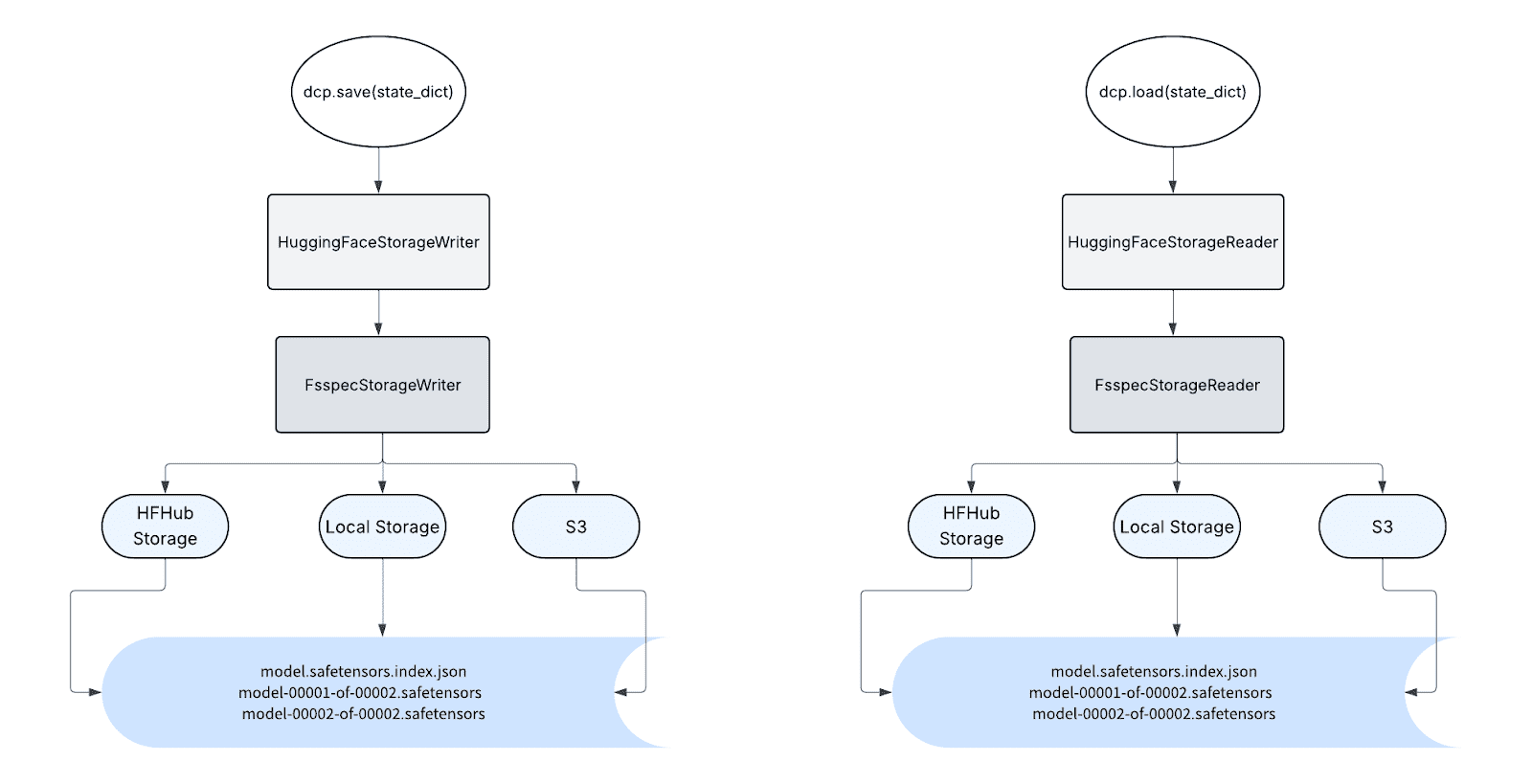
从用户的角度来看,使用 safetensors 所需的唯一更改是使用新的 加载规划器 和 存储读取器 调用加载,类似地,使用新的 保存规划器 和 存储写入器 调用保存。
加载和保存 API 调用如下
load(
state_dict=state_dict,
storage_reader=HuggingFaceStorageReader(path=path),
)
save(
state_dict=state_dict,
storage_writer=HuggingFaceStorageWriter(
path=path,
fqn_to_index_mapping=mapping
),
)
HuggingFaceStorageReader 和 HuggingFaceStorageWriter 可以接受任何基于 fsspec 的路径,因此它可以以 HF safetensors 格式读写到任何 fsspec 支持的后端,包括本地存储和 HF 存储。由于 HuggingFace safetensors 元数据本身不提供与 DCP 元数据相同级别的信息,因此分布式检查点目前在这些 API 中尚未得到良好支持,但 DCP 计划在未来原生支持此功能。
torchtune
我们 HuggingFace DCP 支持的第一个客户是 torchtune——一个用原生 PyTorch 编写的训练后库。torchtune 用户获取模型权重的主要方式是从 Hugging Face Hub。以前,用户必须通过额外的 CLI 命令下载模型权重并上传训练好的检查点;新的 DCP API 允许他们直接读写 HuggingFace,从而带来更好的用户体验。
此外,DCP 中对 safetensor 序列化的支持极大地简化了 torchtune 中的检查点代码。不再需要针对特定格式的检查点解决方案,从而提高了项目中的开发人员效率。
未来工作
DCP 计划处理 HuggingFace safetensors 检查点的分布式加载和保存以及重新分片。DCP 还计划支持将合并后的最终检查点生成到单个文件以供发布的功能。