概述
英特尔 PyTorch 团队一直与 PyTorch Geometric (PyG) 社区合作,为图神经网络 (GNN) 和 PyG 工作负载提供 CPU 性能优化。在 PyTorch 2.0 版本中,引入了几项关键优化,以提高 CPU 上 GNN 训练和推理的性能。开发人员和研究人员现在可以利用 英特尔的 AI/ML 框架优化,显著加快模型训练和推理速度,从而可以直接使用 PyG 进行 GNN 工作流。
在这篇博客中,我们将深入探讨如何在利用 PyTorch 2.0 旗舰功能 torch.compile 加速 PyG 模型的同时,优化 PyG 的训练和推理性能。
消息传递范式
消息传递是指节点通过相互发送消息与其各自邻居交换信息的过程。在 PyG 中,消息传递过程可以概括为三个步骤:
- 收集:收集相邻节点和边的边级信息。
- 应用:使用用户定义函数 (UDF) 更新收集到的信息。
- 聚合:聚合成节点级信息,例如通过特定的归约函数,如求和、求平均值或求最大值。
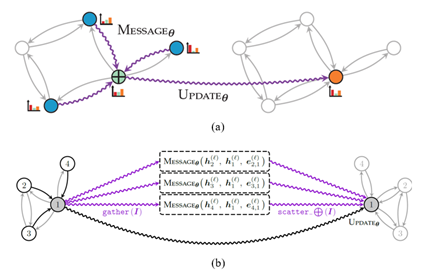
图1:消息传递范式(来源:Matthias Fey)
消息传递性能与图的邻接矩阵的存储格式高度相关,邻接矩阵记录了节点对的连接方式。存储格式有两种方法:
- COO(坐标格式)中的邻接矩阵:图数据物理存储为二维张量形状 [2, num_edges],它映射源节点和目标节点的每个连接。性能瓶颈是 scatter-reduce。
- CSR(压缩稀疏行)中的邻接矩阵:与 COO 格式类似,但在行索引上进行了压缩。这种格式允许更高效的行访问和更快的稀疏矩阵-矩阵乘法 (SpMM)。性能瓶颈是稀疏矩阵相关的归约操作。
Scatter-Reduce(分散归约)
scatter-reduce 的模式本质上是并行的,它使用来自 src 张量的值,根据 index 指定的条目来更新 self 张量的值。理想情况下,在外维度上并行化将是最有效的。然而,直接并行化会导致写入冲突,因为不同的线程可能同时尝试更新同一条目。
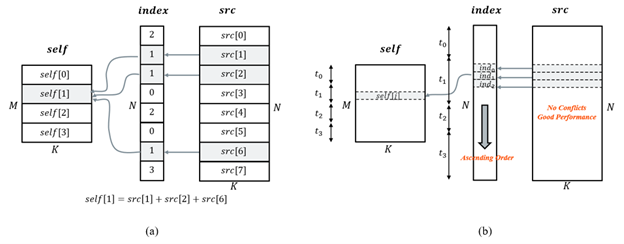
图2:Scatter-reduce 及其优化方案(来源:马明飞)
为了优化此内核,我们使用排序和归约:
- 排序:使用并行基数排序对 index 张量进行升序排序,以便指向 self 张量中同一条目的索引由同一线程管理。
- 归约:在 self 的外维度上并行化,并对每个索引的 src 条目进行向量化归约。
在训练过程中的反向路径(即 gather)中,不需要排序,因为其内存访问模式不会导致任何写入冲突。
SpMM-Reduce(稀疏矩阵-矩阵归约)
稀疏矩阵-矩阵归约是 GNN 中的一个基本操作,其中 A 是 CSR 格式的稀疏邻接矩阵,B 是一个稠密特征矩阵,归约类型可以是 sum、mean 或 max。
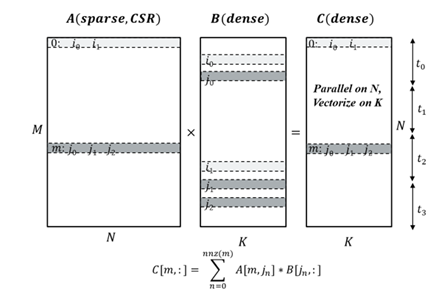
图3:SpMM 优化方案(来源:马明飞)
优化此内核时最大的挑战是如何在稀疏矩阵 A 的行上并行化时平衡线程负载。A 中的每一行对应一个节点,其连接数可能彼此差异很大;这导致线程负载不平衡。解决此类问题的一种技术是在线程分区之前进行负载扫描。除此之外,还引入了其他技术来进一步利用 CPU 性能,例如向量化、展开和分块。
这些优化通过使用 amax、amin、mean、sum 等归约标志的 torch.sparse.mm 完成。
性能提升:高达 4.1 倍的加速
我们收集了 pytorch_geometric/benchmark 和 Open Graph Benchmark (OGB) 中的推理和训练基准性能,以展示上述方法在英特尔® 至强® 白金 8380 处理器上的性能提升。
| 模型 – 数据集 | 选项 | 加速比 |
| GCN-Reddit(推理) | 512-2-64-dense | 1.22x |
| 1024-3-128-dense | 1.25x | |
| 512-2-64-sparse | 1.31x | |
| 1024-3-128-sparse | 1.68x | |
| GraphSage-ogbn-products(推理) | 1024-3-128-dense | 1.15x |
| 512-2-64-sparse | 1.20x | |
| 1024-3-128-sparse | 1.33x | |
| full-batch-sparse | 4.07x | |
| GCN-PROTEINS(训练) | 3-32 | 1.67x |
| GCN-REDDIT-BINARY(训练) | 3-32 | 1.67x |
| GCN-Reddit(训练) | 512-2-64-dense | 1.20x |
| 1024-3-128-dense | 1.12x |
表1:PyG 基准测试中的性能加速1
从基准测试结果可以看出,我们在 PyTorch 和 PyG 中的优化使推理和训练实现了 1.1倍至4.1倍的加速。
用于 PyG 的 torch.compile
PyTorch 2.0 的旗舰功能 torch.compile 完全兼容 PyG 2.3 版本,由于适用于 CPU 的 TorchInductor C++/OpenMP 后端,它在 PyG 模型推理/训练中比命令式模式带来了额外的加速。具体而言,在使用英特尔至强白金 8380 处理器进行模型训练时,基本 GNN 模型的性能提升了 3.0 倍至 5.4 倍2。
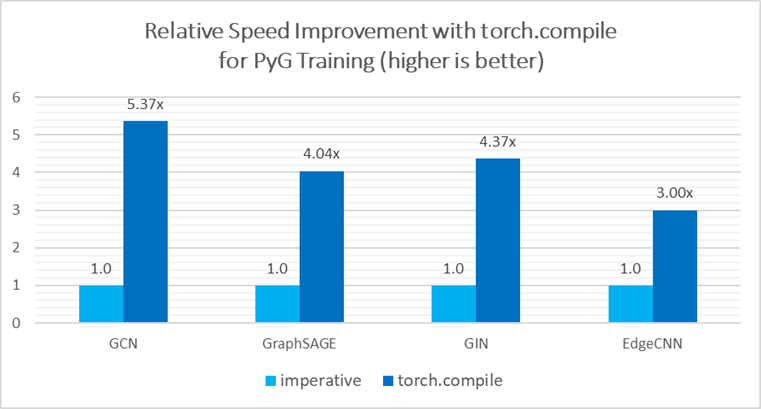
图4:使用 Torch Compile 带来的性能加速
Torch.compile 可以将消息传递的多个阶段融合到一个内核中,由于节省了内存带宽,这提供了显著的加速。有关更多支持,请参阅此pytorch geometric 教程。
请注意,PyG 中的 torch.compile 处于测试版,并正在积极开发中。目前,某些功能尚未无缝协同工作,例如 torch.compile(model, dynamic=True),但英特尔正在提供修复。
结论与未来工作
在本博客中,我们介绍了 PyTorch 2.0 在 CPU 上包含的 GNN 性能优化。我们正在与 PyG 社区紧密合作,开展未来的优化工作,重点将放在 torch.compile、稀疏优化和分布式训练的深入优化上。
致谢
本博客中展示的结果是英特尔 PyTorch 团队和 Kumo 共同努力的成果。特别感谢 Matthias Fey (Kumo)、Pearu Peterson (Quansight) 和 Christian Puhrsch (Meta) 付出了宝贵的时间并提供了实质性帮助!我们共同在改进 PyTorch CPU 生态系统的道路上又向前迈进了一步。
参考文献
- 加速英特尔 CPU 上的 PyG
- PyG 2.3.0:支持 PyTorch 2.0、原生稀疏张量支持、可解释性和加速
脚注
产品和性能信息
1至强白金 8380:1 节点,2 个英特尔至强白金 8380 处理器,256GB(16 插槽/16GB/3200)总 DDR4 内存,uCode 0xd000389,HT 开启,Turbo 开启,Ubuntu 20.04.5 LTS,5.4.0-146-generic,INTEL SSDPE2KE016T8 1.5T;GCN + Reddit FP32 推理,GCN+Reddit FP32 训练,GraphSAGE + ogbn-products FP32 推理,GCN-PROTAIN,GCN-REDDIT-BINARY FP32 训练;软件:PyTorch 2.1.0.dev20230302+cpu,pytorch_geometric 2.3.0,torch-scatter 2.1.0,torch-sparse 0.6.16,由英特尔于 2023 年 3 月 2 日测试。
2至强白金 8380:1 节点,2 个英特尔至强白金 8380 处理器,256GB(16 插槽/16GB/3200)总 DDR4 内存,uCode 0xd000389,HT 开启,Turbo 开启,Ubuntu 20.04.5 LTS,5.4.0-146-generic,INTEL SSDPE2KE016T8 1.5T;GCN、GraphSAGE、GIN 和 EdgeCNN,FP32;软件:PyTorch 2.1.0.dev20230411+cpu,pytorch_geometric 2.4.0,torch-scatter 2.1.1+pt20cpu,torch-sparse 0.6.17+pt20cpu,由英特尔于 2023 年 4 月 11 日测试。
3性能因使用、配置和其他因素而异。请访问 www.Intel.com/PerformanceIndex 了解更多信息。