引言
迪士尼媒体与娱乐发行公司 (DMED) 的众多职责之一是管理和分发海量媒体资产,包括新闻、体育、娱乐和专题节目、系列节目、营销和广告等。
我们的团队作为 DMED 技术内容平台组的一部分,专注于媒体标注。在日常工作中,我们自动分析各种内容,这些内容不断挑战我们机器学习工作流的效率和模型精度。
我们的一些同事最近讨论了我们通过切换到使用 PyTorch 的端到端视频分析流水线所实现的效率,以及我们如何进行动画角色识别。我们邀请您阅读这篇先前的文章,了解更多信息。
虽然转换为端到端 PyTorch 流水线是任何公司都可能受益的解决方案,但动画角色识别是一个迪士尼独有的概念和解决方案。
在本文中,我们将重点关注活动识别,这是一个跨行业的普遍挑战——但在媒体制作领域中利用时具有一些特定的机会,因为我们可以结合音频、视频和字幕来提供解决方案。
多模态实验
处理多模态问题会增加通常训练流水线的复杂性。每个示例都有多种信息模式意味着多模态流水线必须具有特定的实现来处理数据集中的每种模式。通常在此处理步骤之后,流水线必须合并或融合输出。
我们最初的多模态实验是使用 MMF 框架完成的。MMF 是一个用于视觉和语言多模态研究的模块化框架。MMF 包含最先进的视觉和语言模型的参考实现,并且还支持了 Meta AI 研究院的多个研究项目(如 PyTorch 生态系统日 2020 上展示的这篇海报所示)。随着最近发布了 TorchMultimodal(一个用于大规模训练最先进多模态模型的 PyTorch 库),MMF 凸显了人们对多模态理解日益增长的兴趣。
MMF 通过模块化管理流水线的所有元素来解决这种复杂性,它通过各种不同的实现来处理特定的模块,从模态处理到处理后信息的融合。
在我们的场景中,MMF 是一个很好的切入点,可以实验多模态。它允许我们通过结合音频、视频和隐藏字幕快速迭代,并在不同的规模级别上实验某些多模态模型,从单个 GPU 切换到 TPU Pod。
多模态 Transformer
基于 MMF 的工作台,我们的初始模型基于每种模态特征的串联,并演变为包含基于 Transformer 的融合模块的流水线,以组合不同的输入模式。
具体来说,我们使用了与 Meta AI 研究团队合作开发的名为 MMFTransformer 的融合模块。这是一个基于 VisualBERT 的实现,并添加了必要的修改,使其能够处理文本、音频和视频。
尽管 MMFTransformer 开箱即用获得了不错的结果,但我们离目标仍然很远,并且基于 Transformer 的模型需要比我们现有数据更多的数据。
寻找数据需求较小的解决方案
为了寻找数据需求较小的解决方案,我们的团队开始研究 MLP-Mixer。这种新架构由 Google Brain 团队提出,它为计算机视觉任务中已经成熟的事实标准架构(如卷积或自注意力)提供了替代方案。
MLP-Mixer
混合变体的核心思想是用多层感知器取代 Transformer 中使用的卷积或自注意力机制。这种架构上的改变有利于模型在高数据量下的性能(尤其是相对于 Transformer),同时也引发了一些关于卷积和自注意力层中隐藏的归纳偏置的问题。
这些提议通过将图像分成块,将这些块展平为 1D 向量并使其通过一系列 Mixer 层,在解决图像分类任务方面表现出色。
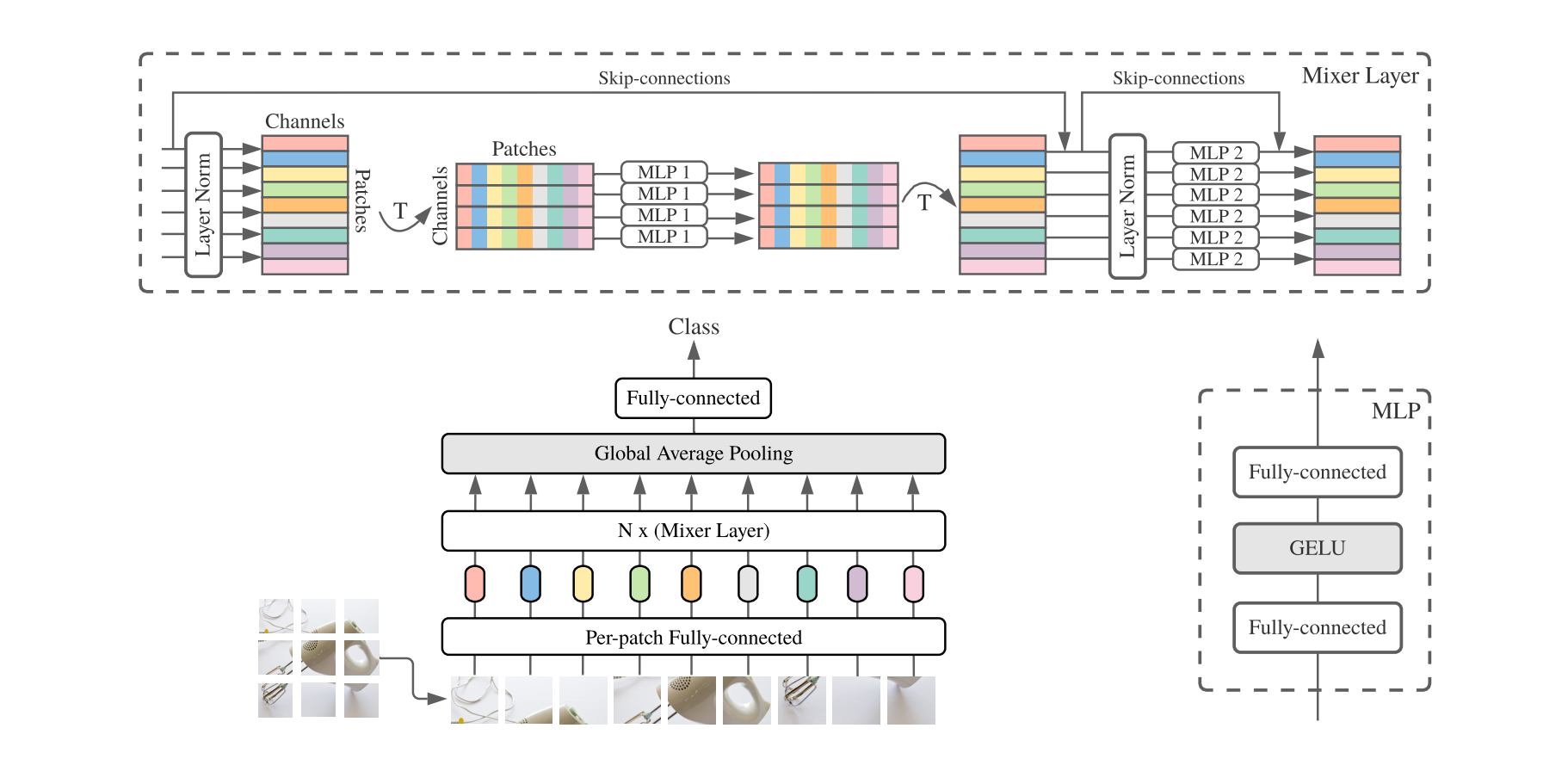
受基于 Mixer 架构优势的启发,我们的团队寻找与我们在视频分类中尝试解决的问题类型相似之处:具体来说,我们不是单一图像,而是一组需要分类的帧,以及以新模态形式出现的音频和隐藏字幕。
重新解读 MLP-Mixer 的活动识别
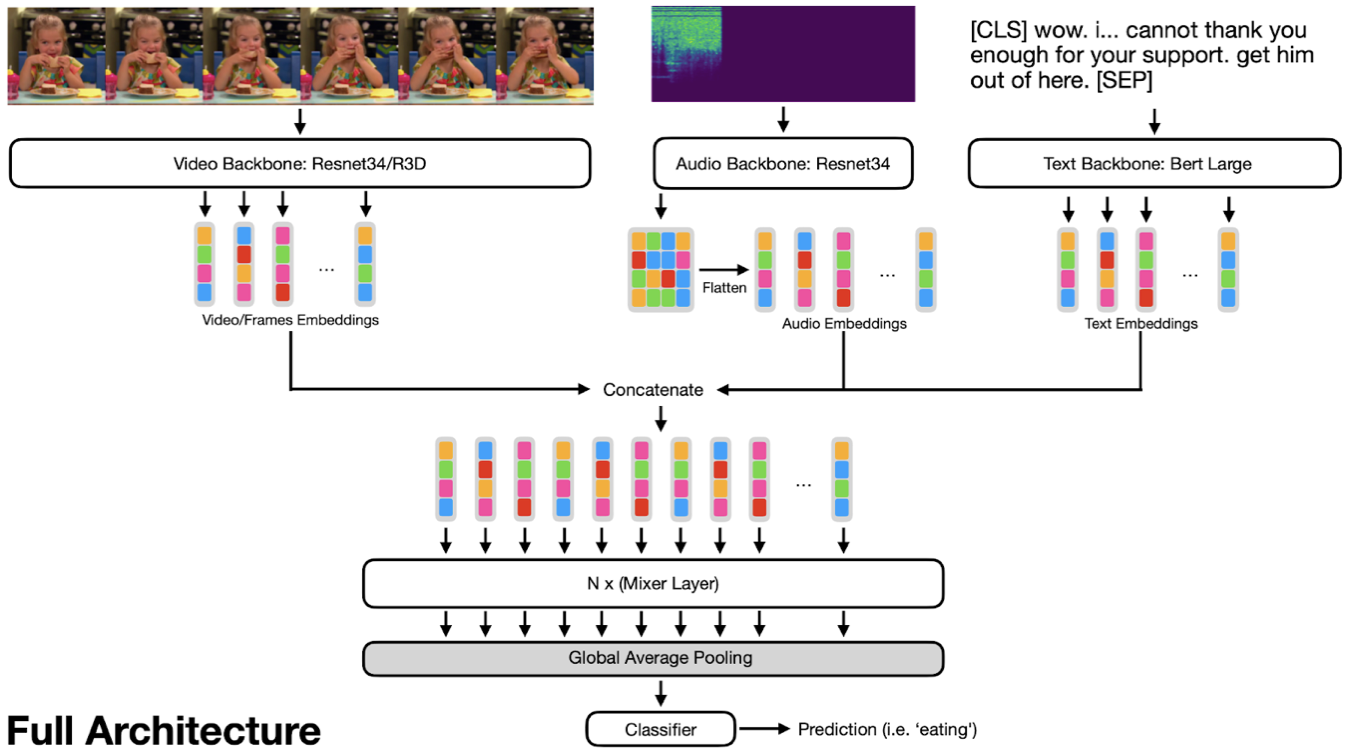
我们的方案采用了 MLP-Mixer 的核心思想——在一系列和转置序列上使用多个多层感知器,并将其扩展到一个多模态框架,使我们能够使用相同的架构处理视频、音频和文本。
对于每种模态,我们使用不同的提取器来提供描述内容的嵌入。鉴于每种模态的嵌入,MLP-Mixer 架构解决了决定哪种模态可能最重要的问题,同时还权衡了每种模态对最终标注的贡献程度。
例如,在检测笑声时,有时关键信息在音频或帧中,而在某些情况下,隐藏字幕中也有很强的信号。
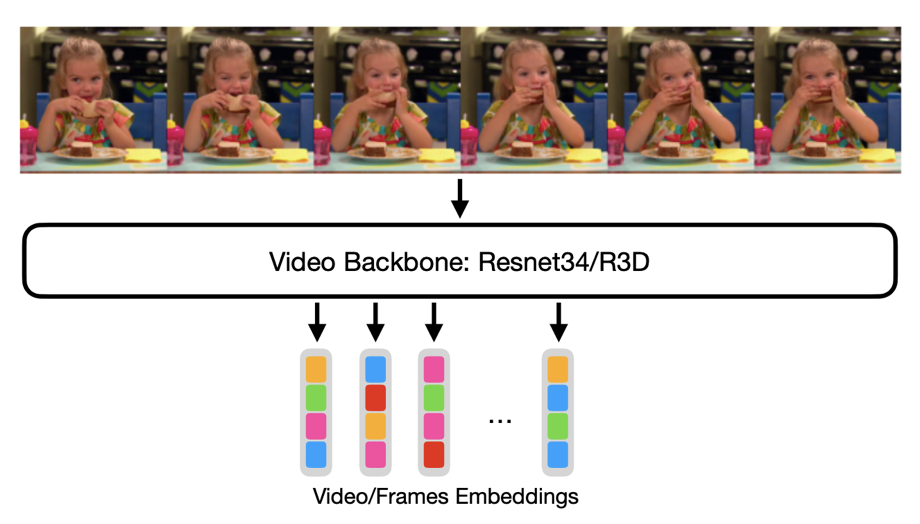
我们尝试使用 ResNet34 分别处理每一帧并获得一系列嵌入,并使用一种称为 R3D 的视频专用模型,它们分别在 ImageNet 和 Kinetics400 上预训练。
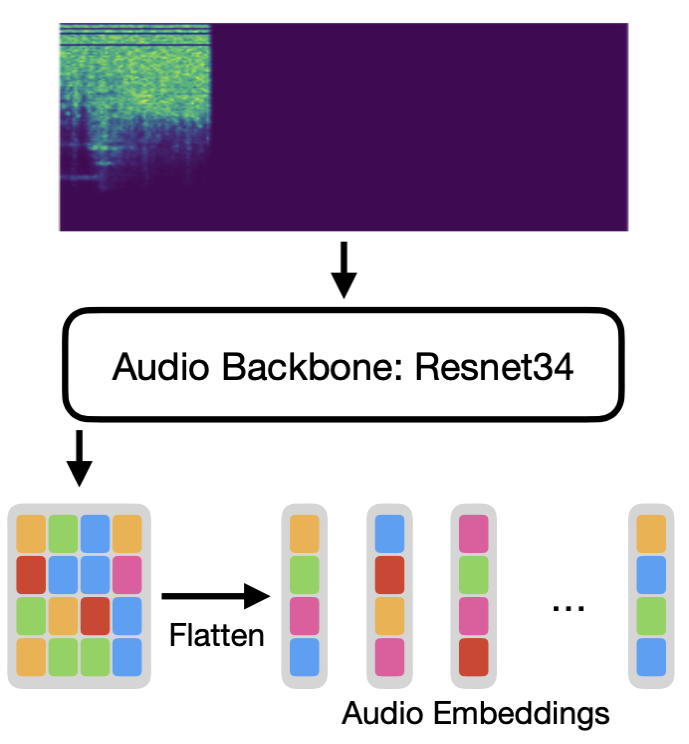
为了处理音频,我们使用预训练的 ResNet34,并移除最终层,以便从音频频谱图(对于 224x224 图像,我们最终得到 7x7 嵌入)中提取 2D 嵌入。
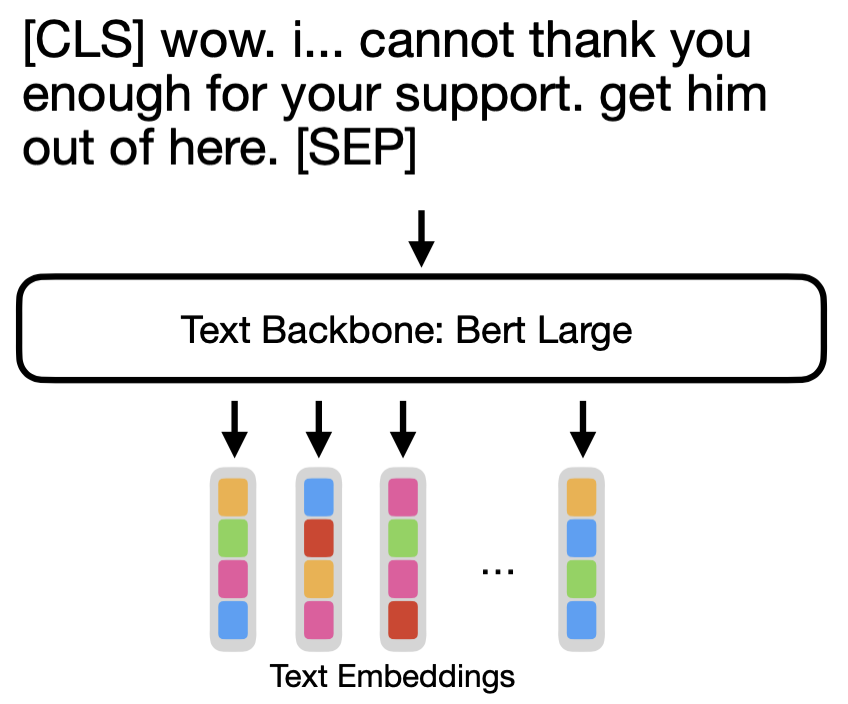
对于隐藏字幕,我们使用预训练的 BERT-large,除了嵌入和 LayerNorms 之外,所有层都已冻结。
一旦我们从每种模态中提取了嵌入,我们将它们连接成一个序列并将其通过一组 MLP-Mixer 块;接下来我们使用平均池化和分类头来获取预测。
我们的实验是在一个自定义的、手动标注的活动识别数据集上进行的,该数据集包含 15 个类别。我们从实验中得知,这些类别很难,并且不能全部使用单一模态准确预测。
这些实验表明,使用我们的方法显著提高了性能,尤其是在低/中数据量(75K 训练样本)的情况下。
当仅使用文本和音频时,我们的实验表明,与在最先进的主干提取的特征之上使用分类器相比,准确性提高了 15%。
使用文本、音频和视频,与使用 Meta AIFacebook 的 MMF 框架相比,准确性提高了 17%。MMF 框架使用类似 VisualBERT 的模型结合模态,并使用更强大的最先进主干。
目前,我们将初始模型扩展到涵盖多达 55 个活动类别和 45 个事件类别。我们期望未来改进的挑战之一是包含所有活动和事件,甚至那些不那么频繁的。
解读 MLP-Mixer 模式组合
MLP-Mixer 是多层感知器的串联。这可以非常粗略地近似为线性操作,即一旦训练完成,权重是固定的,输入将直接影响输出。
一旦我们假设这种近似,我们也假设对于由 NxM 数字组成的输入,我们可以找到一个 NxM 矩阵,该矩阵(当按元素相乘时)可以近似 MLP-Mixer 对某个类别的预测。
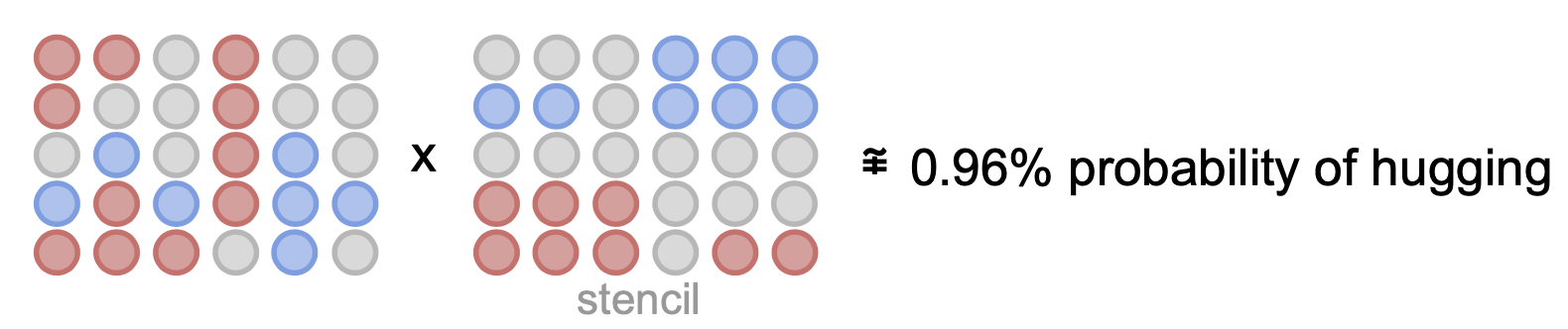
我们称此矩阵为模板,如果我们能够访问它,我们就可以找到输入嵌入的哪些部分负责特定预测。
您可以将其想象成一张带有特定位置孔洞的打孔卡。只有这些位置的信息才会通过并对特定预测做出贡献。因此我们可以测量这些位置输入的强度。

当然,这过于简化了,不存在一个唯一的模板可以完美地代表输入对一个类别的所有贡献(否则就意味着问题可以线性解决)。所以这应该仅用于可视化目的,而不是准确的预测器。
一旦我们为每个类别拥有一组模板,我们就可以毫不费力地测量输入贡献,而无需依赖任何外部可视化技术。
为了找到一个模板,我们可以从一个“随机噪声”模板开始,并通过反向传播通过 MLP-Mixer 来优化它,以最大化特定类别的激活。

通过这样做,我们可以得到许多有效的模板,我们可以通过使用 K-means 将它们聚类到相似的模板中并对每个聚类进行平均来减少它们。
使用 Mixer 获得两全其美
MLP-Mixer 作为没有卷积层的图像分类模型,需要大量数据,因为缺乏归纳偏置——这是模型整体优点之一——在低数据量领域工作时是一个弱点。
当它被用作组合先前由大型预训练主干提取的信息的方式时(而不是作为完整的端到端解决方案使用),它们会大放异彩。Mixer 的优势在于寻找不同输入之间的时间或结构一致性。例如,在视频相关任务中,我们可以使用强大的预训练模型从帧中提取嵌入,该模型了解帧级别正在发生什么,并使用 Mixer 以顺序方式理解它。
这种使用 Mixer 的方式使我们能够使用有限的数据量,并且仍然获得比 Transformer 更好的结果。这是因为 Mixer 在训练期间似乎更稳定,并且似乎会关注所有输入,而 Transformer 倾向于崩溃并且只关注序列的某些模态/部分。
致谢:我们感谢 Meta AI Research 和 Partner Engineering 团队在此次合作中提供的帮助。