摘要
Hopper (H100) GPU 架构被称为“首个真正的异步 GPU”,它包含了一个全新的、完全异步的硬件复制引擎,用于全局内存和共享内存之间的大量数据移动,称为张量内存加速器 (TMA)。虽然 CUTLASS 通过其异步管道范式内置支持 TMA,但 Triton 通过实验性 API 暴露了 TMA 支持。
在这篇文章中,我们将深入探讨 TMA 的工作原理,以便开发人员了解新的异步复制引擎。我们还将通过在 Triton 中构建一个支持 TMA 的 FP8 GEMM 内核来展示利用 TMA 对 H100 内核的重要性,该内核在中小问题规模上比 cuBLAS FP16 实现了 1.4-2.2 倍的性能提升。最后,我们展示了 Triton 和 CUTLASS 之间关键的实现差异,这些差异可能解释了 Triton 中 TMA 性能下降的报告。我们开源了我们的实现,以便在https://github.com/pytorch-labs/applied-ai/tree/main/kernels 上进行复现和审查。
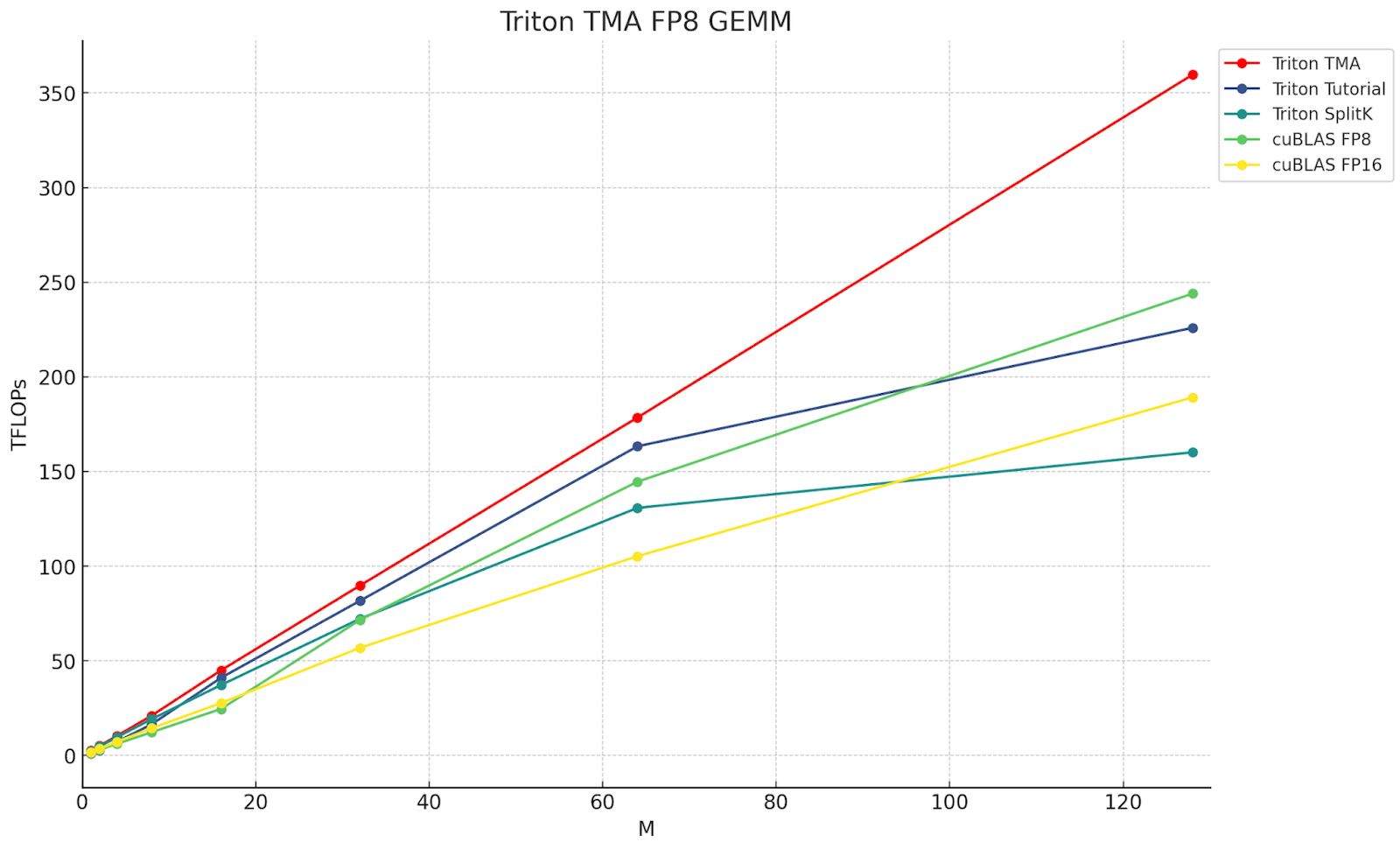
图 1. 各种 Triton 和 cuBLAS FP8 和 FP16 内核的吞吐量 (TFLOPs),M=M, N=4096, K=4096。红线是 Triton TMA,它展示了利用 TMA 的优势。
TMA 背景
TMA 是 H100 的一项硬件新增功能,允许应用程序在 GPU 全局内存和共享内存之间异步双向传输 1D-5D 张量。此外,TMA 不仅可以将相同的数据传输到调用 SM 的共享内存,还可以传输到同一线程块集群中的其他 SM 的共享内存。这被称为“多播”。
TMA 非常轻量级,只需一个线程即可启动 TMA 传输。通过将数据直接从 GMEM(全局)移动到 SMEM(共享),这避免了早期 GPU 在不同内存空间之间移动数据时使用寄存器的要求。
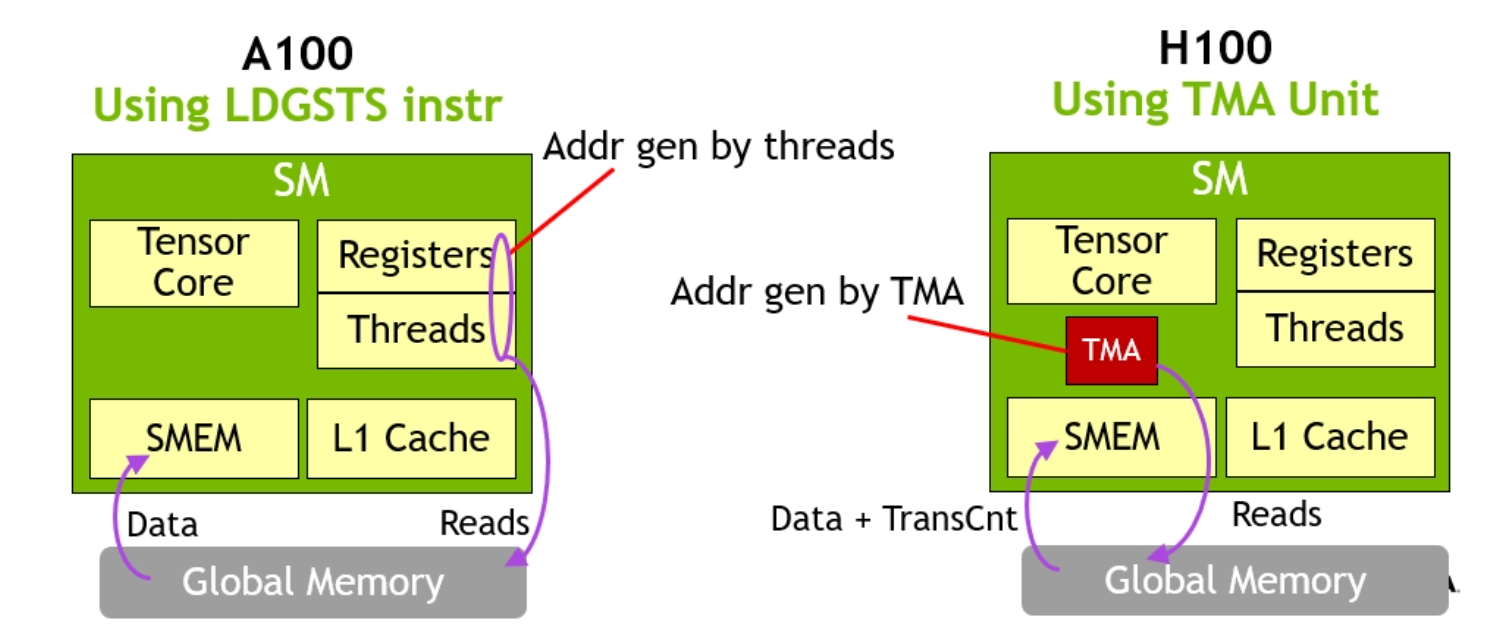
图 2. A100 风格的数据移动与带有 TMA 的 H100。TMA 硬件消除了大量线程和寄存器参与批量数据传输的需要。(图片来源:Nvidia)
单个线程可以发出大型数据移动指令,允许给定线程块的大部分在数据传输过程中继续处理其他指令。结合异步流水线,这使得内存传输可以轻松隐藏,并确保给定线程块集群的大部分可以专注于计算任务。
这种轻量级的数据移动调用使得可以创建 warp-group 专用内核,其中 warp-group 扮演不同的角色,即生产者和消费者。生产者选择一个领导线程发出 TMA 请求,然后通过到达屏障与消费者 (MMA) warp-group 异步协调。然后消费者使用 warp-group MMA 处理数据,并在完成从 SMEM 缓冲区读取后向生产者发出信号,循环重复。
此外,在线程块集群中,生产者可以降低其最大寄存器需求,因为它们只发出 TMA 调用,从而有效地将额外的寄存器转移给 MMA 消费者,这有助于减轻消费者的寄存器压力。
此外,TMA 处理请求数据应放置的共享内存目标的地址计算。这就是为什么调用线程(生产者)可以如此轻量级。
为了确保最大的读取访问速度,TMA 可以根据交织指令布置到达的数据,以确保消费者可以尽可能快地读取到达的数据,因为交织模式有助于避免共享内存 bank 冲突。
最后,对于传出或将数据从 SMEM 移动到 GMEM 的 TMA 指令,TMA 还可以包括归约操作(add/min/max)和按位操作(and/or)。
Triton 中的 TMA 用法
Hopper 前加载
offs_m = pid_m*block_m + tl.arange(0, block_m)
offs_n = pid_n*block_n + tl.arange(0, block_n)
offs_k = tl.arange(0, block_k)
a_ptrs = a_ptr + (offs_am[:, None]*stride_am + offs_k[None, :]*stride_ak)
b_ptrs = b_ptr + (offs_k[:, None]*stride_bk + offs_bn[None, :]*stride_bn)
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
图 3. Triton 中从全局内存到共享内存的传统批量加载方式
在上面展示 Hopper 前加载的 Triton 示例中,我们看到张量 A 和 B 的数据是如何通过每个线程块从其相关的 program_id (pid_m, pid_n, k) 计算全局偏移量 (a_ptrs, b_ptrs),然后请求将内存块移动到 A 和 B 的共享内存中来加载的。
现在让我们研究如何在 Triton 中使用 TMA 执行加载。
TMA 指令需要一种称为张量映射的特殊数据结构,与上述直接传递指向全局内存的指针不同。要构建张量映射,我们首先在 CPU 上创建一个 TMA 描述符。描述符通过使用 cuTensorMapEncode API 处理张量映射的创建。张量映射包含元数据,例如张量的全局和共享内存布局,并作为存储在全局内存中的多维张量结构的压缩表示。
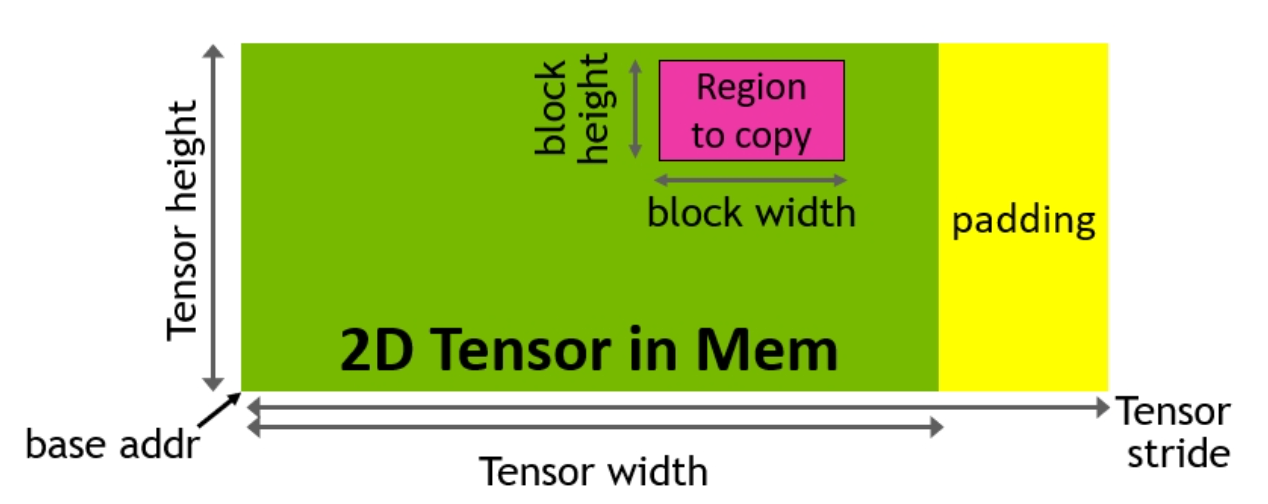
图 4. 通过复制描述符生成 TMA 地址(图片来源:Nvidia)
TMA 描述符包含张量的关键属性:
- 基指针
- 形状和块大小
- 数据类型
TMA 描述符在内核之前在主机上创建,然后通过将描述符传递给 torch 张量来移动到设备。因此,在 Triton 中,GEMM 内核接收指向张量映射的全局指针。
Triton 主机代码
desc_a = np.empty(TMA_SIZE, dtype=np.int8)
desc_b = np.empty(TMA_SIZE, dtype=np.int8)
desc_c = np.empty(TMA_SIZE, dtype=np.int8)
triton.runtime.driver.active.utils.fill_2d_tma_descriptor(a.data_ptr(), m, k, block_m, block_k, a.element_size(), desc_a)
triton.runtime.driver.active.utils.fill_2d_tma_descriptor(b.data_ptr(), n, k, block_n, block_k, b.element_size(), desc_b)
triton.runtime.driver.active.utils.fill_2d_tma_descriptor(c.data_ptr(), m, n, block_m, block_n, c.element_size(), desc_c)
desc_a = torch.tensor(desc_a, device='cuda')
desc_b = torch.tensor(desc_b, device='cuda')
desc_c = torch.tensor(desc_c, device='cuda')
这是用于在内核调用函数中设置描述符的代码。
Triton 设备代码
偏移量/指针运算
offs_am = pid_m * block_m
offs_bn = pid_n * block_n
offs_k = 0
加载
a = tl._experimental_descriptor_load(a_desc_ptr, [offs_am, offs_k], [block_m, block_k], tl.float8e4nv)
b = tl._experimental_descriptor_load(b_desc_ptr, [offs_bn, offs_k], [block_n, block_k], tl.float8e4nv)
存储
tl._experimental_descriptor_store(c_desc_ptr, accumulator, [offs_am, offs_bn])
我们不再需要在内核中为加载和存储函数计算指针数组。相反,我们传递一个描述符指针、偏移量、块大小和输入数据类型。这简化了地址计算并减少了寄存器压力,因为我们不再需要在软件中进行复杂的指针运算并为地址计算分配 CUDA 核心。
TMA 性能分析
下面,我们将讨论 Hopper 上不同加载机制的 PTX 指令。
用于加载 Tile 的 PTX (cp.async) – H100 无 TMA
add.s32 %r27, %r100, %r8;
add.s32 %r29, %r100, %r9;
selp.b32 %r30, %r102, 0, %p18;
@%p1 cp.async.cg.shared.global [ %r27 + 0 ], [ %rd20 + 0 ], 0x10, %r30;
@%p1 cp.async.cg.shared.global [ %r29 + 0 ], [ %rd21 + 0 ], 0x10, %r30;
cp.async.commit_group ;
在这里,我们观察到负责全局内存复制的旧式 cp.async 指令。从下面的跟踪中我们可以看到,两次加载都绕过了 L1 缓存。更新的 TMA 加载的一个主要区别是,在 A 和 B 的 tile 准备好被 Tensor Core 消耗之前,我们需要执行一个 ldmatrix 指令,该指令对寄存器文件中的数据进行操作。在 Hopper 上,数据现在可以直接从共享内存中重用。
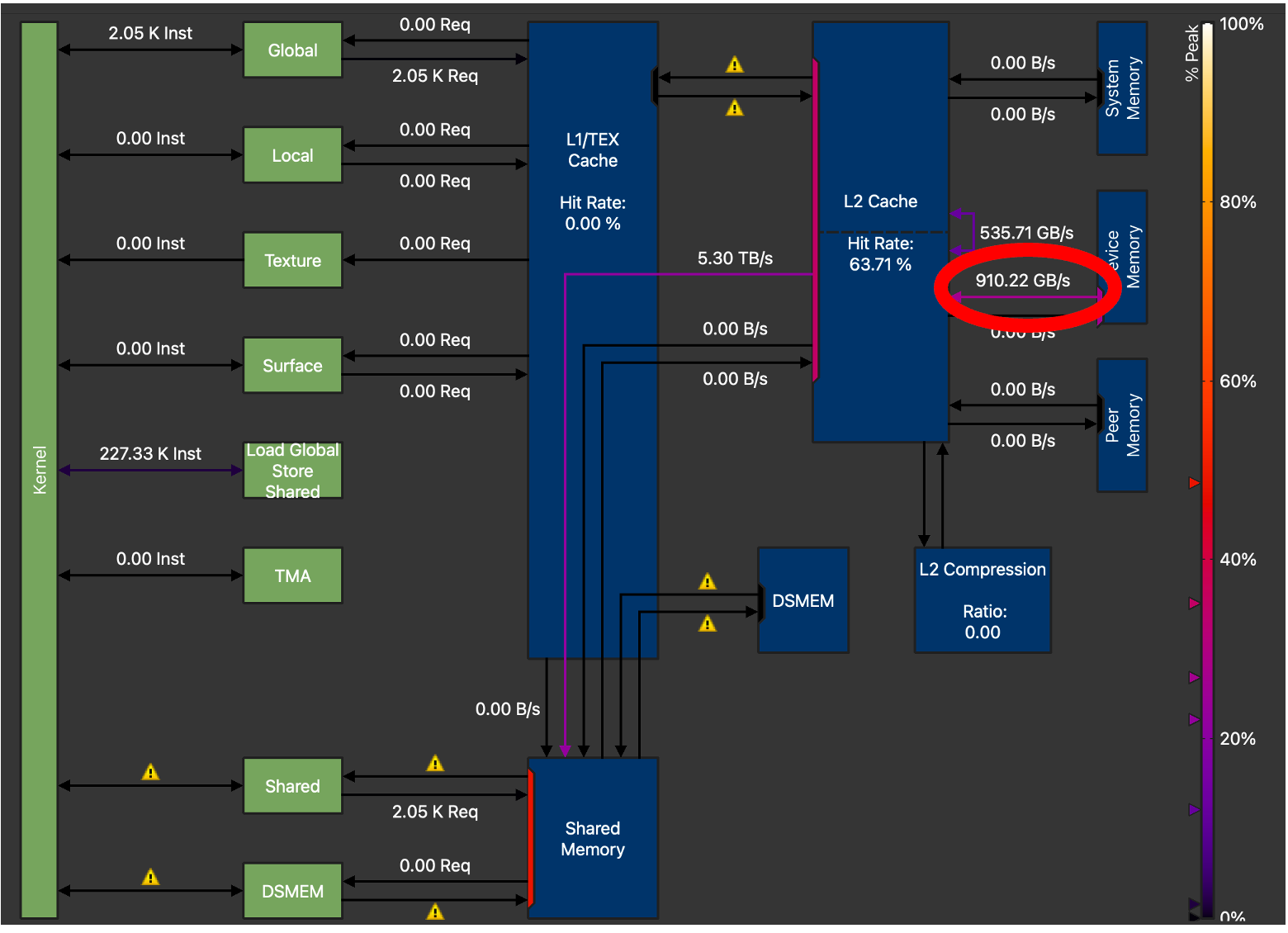
图 5. H100 内存图显示 GMEM 吞吐量 = 910.22 GB/s(不带 TMA 的 Triton GEMM),M=128, N=4096, K=4096
通过我们上面提到的 Triton API 更改利用 TMA,我们可以研究 Triton 为单个 2D tile 加载生成的 PTX。
用于加载 Tile 的 PTX (cp.async.bulk.tensor) – H100 使用 TMA
bar.sync 0;
shr.u32 %r5, %r4, 5;
shfl.sync.idx.b32 %r66, %r5, 0, 31, -1;
elect.sync _|%p7, 0xffffffff;
add.s32 %r24, %r65, %r67;
shl.b32 %r25, %r66, 7;
@%p8
cp.async.bulk.tensor.2d.shared::cluster.global.mbarrier::complete_tx::bytes [%r24], [%rd26, {%r25,%r152}], [%r19];
cp.async.bulk.tensor.2d.shared TMA 指令分别传递共享内存中的目标地址、指向张量映射的指针、张量映射坐标和指向 mbarrier 对象的指针。
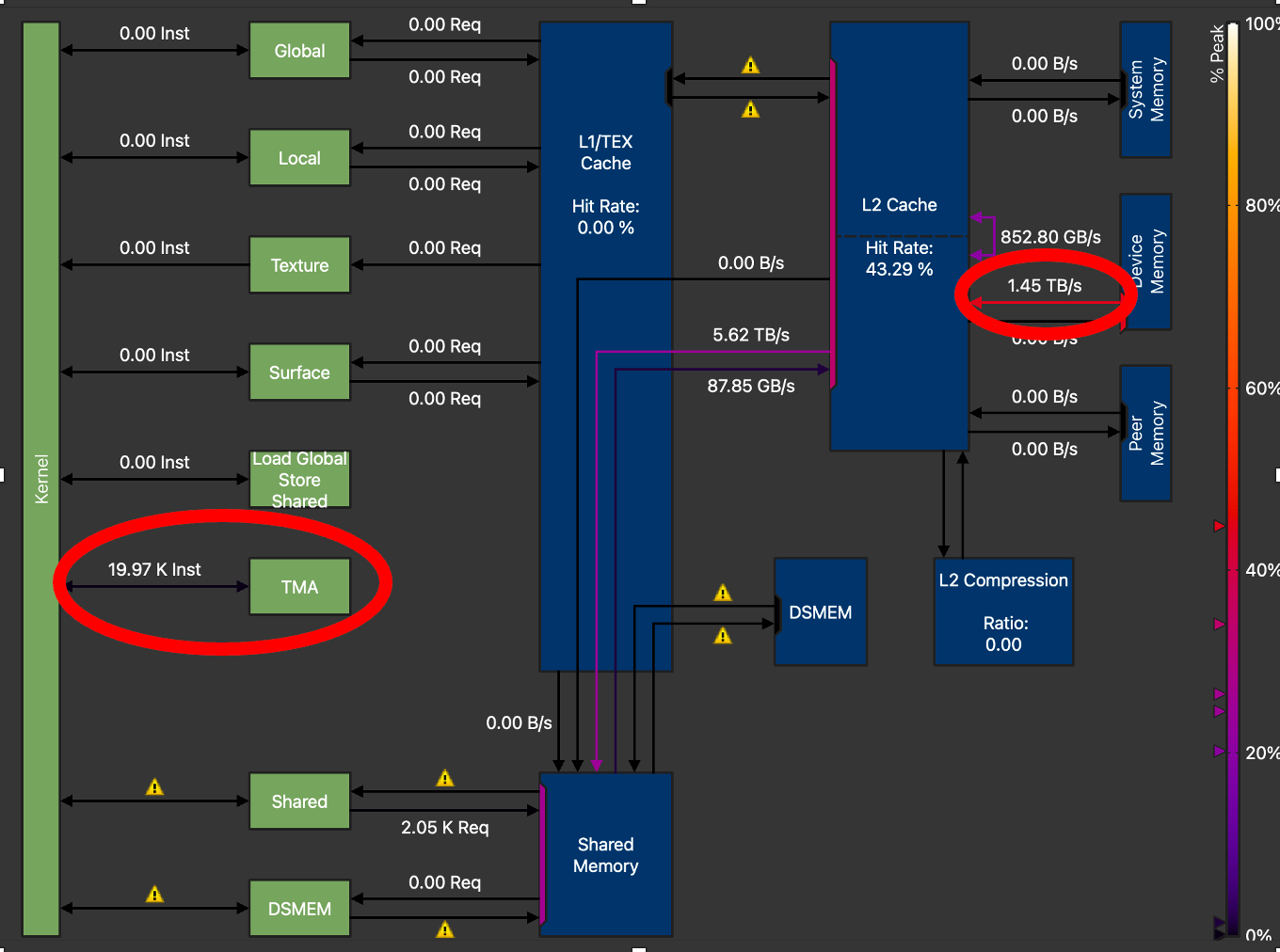
图 6. H100 内存图 GMEM 吞吐量 = 1.45 TB/s(带 TMA 的 Triton GEMM),M=128, N=4096, K=4096
为了获得最佳性能,我们对 TMA GEMM 内核进行了广泛的调优。在其他参数(如 tile 大小、warp 数量和流水线阶段数量)中,我们观察到将 TMA_SIZE(描述符大小)从 128 增加到 512 时,内存吞吐量增加最大。从上面的 NCU 配置文件中,我们可以看到,最终调优后的内核将全局内存传输吞吐量从 910 GB/s 提高到 1.45 TB/s,比非 TMA Triton GEMM 内核的 GMEM 吞吐量增加了 59%。
CUTLASS 和 Triton FP8 GEMM 及 TMA 实现的比较——内核架构
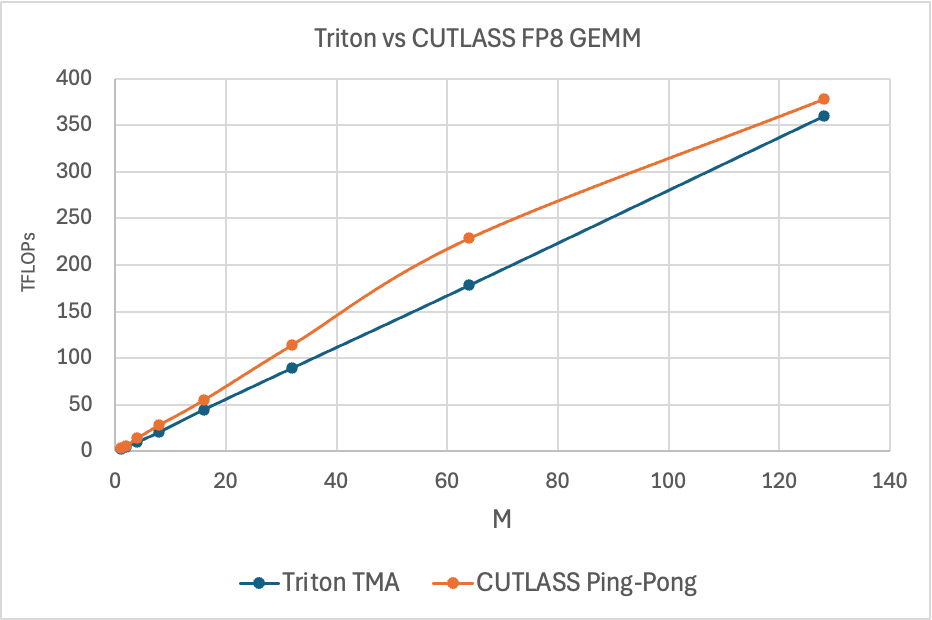
图 7. Triton vs CUTLASS Ping-Pong FP8 GEMM TFLOPs,M=M, N=4096, K=4096
上图显示了 CUTLASS Ping-Pong GEMM 内核与 Triton 的性能。Ping-Pong 内核利用 TMA 的方式与 Triton 不同。它利用了其所有的硬件和软件功能,而 Triton 目前则没有。具体来说,CUTLASS 支持以下 TMA 功能,这些功能有助于解释纯 GEMM 性能中的性能差距:
- TMA 多播
- 支持将数据从 GMEM 复制到多个 SM
- Warp 专用化
- 使线程块内的 warp 组扮演不同的角色
- 张量映射(TMA 描述符)预取
- 支持从 GMEM 预取张量映射对象,从而实现 TMA 加载的流水线操作
为了更直观地展示性能数据,下面我们展示了一个“加速”图,以百分比形式突出显示了延迟差异
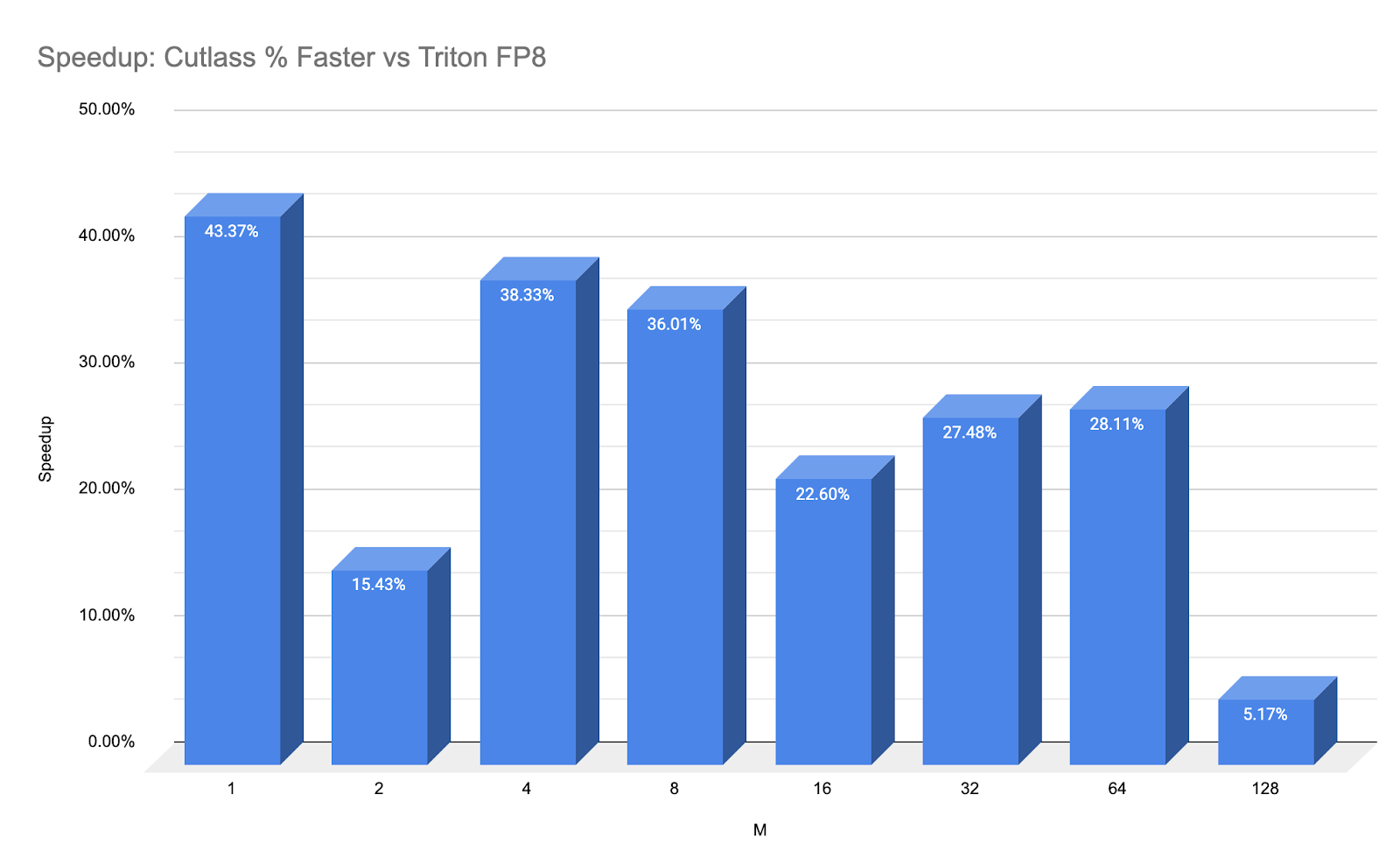
图 8: CUTLASS Ping-Pong 与 Triton FP8 with TMA 的加速百分比。
这种加速纯粹是内核吞吐量,不包括我们将要讨论的 E2E 启动开销。
TMA 描述符移动——Triton 和 CUTLASS 之间的关键差异及其对 E2E 性能的影响
如前所述,2D+ 维 TMA 描述符的创建发生在主机上,然后传输到设备。然而,这种传输过程根据实现方式的不同而大相径庭。
在这里,我们展示了 Triton 与 CUTLASS 传输 TMA 描述符方式之间的差异。
回想一下,TMA 传输需要通过 cuTensorMap API 在 CPU 上创建一种特殊的数据结构——张量映射,对于 FP8 GEMM 内核来说,这意味着需要为 A、B 和 C 各创建三个描述符。我们看到,对于 Triton 和 CUTLASS 内核,都调用了相同的 CPU 过程。
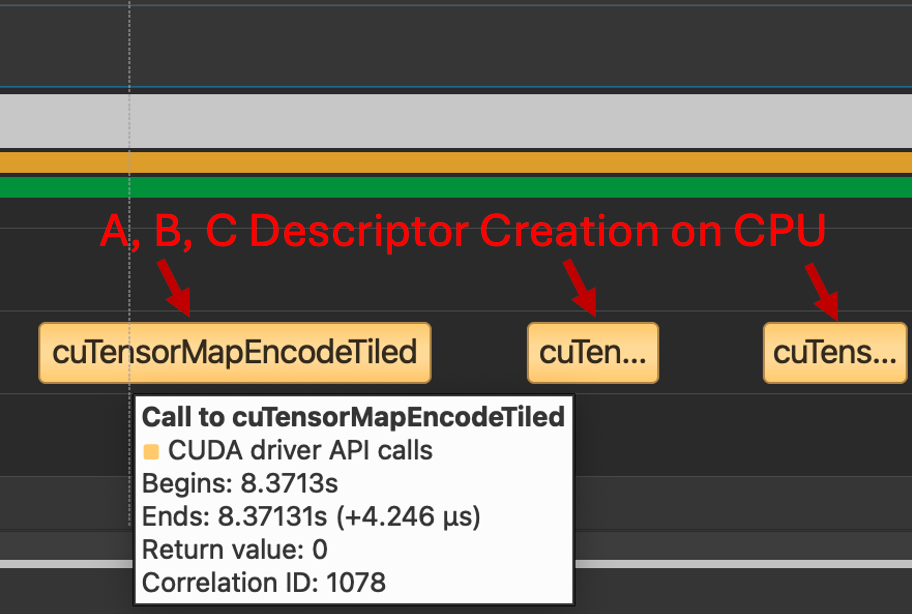
图 7. 调用 cuTensorMapEncodeTiled(Triton 和 CUTLASS 都使用此路径)
然而,对于 Triton,每个描述符都在其自己的独立复制内核中传输,这增加了大量的开销,并成为在端到端推理场景中使用此内核的障碍。

图 8. 在内核执行之前启动三个 H2D 复制内核,分别用于 A、B 和 C。
在 CUTLASS 实现中没有观察到这些副本,这是由于 TMA 描述符传递给内核的方式。我们可以从下面的 PTX 中看到,使用 Cutlass,张量映射是通过值传递给内核的。
.entry _ZN7cutlass13device_kernelIN49_GLOBAL__N__8bf0e19b_16_scaled_mm_c3x_cu_2bec3df915cutlass_3x_gemmIaNS_6half_tENS1_14ScaledEpilogueEN4cute5tupleIJNS5_1CILi64EEENS7_ILi128EEES9_EEENS6_IJNS7_ILi2EEENS7_ILi1EEESC_EEENS_4gemm32KernelTmaWarpSpecializedPingpongENS_8epilogue18TmaWarpSpecializedEE10GemmKernelEEEvNT_6ParamsE(
.param .align 64 .b8 _ZN7cutlass13device_kernelIN49_GLOBAL__N__8bf0e19b_16_scaled_mm_c3x_cu_2bec3df915cutlass_3x_gemmIaNS_6half_tENS1_14ScaledEpilogueEN4cute5tupleIJNS5_1CILi64EEENS7_ILi128EEES9_EEENS6_IJNS7_ILi2EEENS7_ILi1EEESC_EEENS_4gemm32KernelTmaWarpSpecializedPingpongENS_8epilogue18TmaWarpSpecializedEE10GemmKernelEEEvNT_6ParamsE_param_0[1024]
mov.b64 %rd110, _ZN7cutlass13device_kernelIN49_GLOBAL__N__8bf0e19b_16_scaled_mm_c3x_cu_2bec3df915cutlass_3x_gemmIaNS_10bfloat16_tENS1_14ScaledEpilogueEN4cute5tupleIJNS5_1CILi64EEES8_NS7_ILi256EEEEEENS6_IJNS7_ILi1EEESB_SB_EEENS_4gemm24KernelTmaWarpSpecializedENS_8epilogue18TmaWarpSpecializedEE10GemmKernelEEEvNT_6ParamsE_param_0;
add.s64 %rd70, %rd110, 704;
cvta.param.u64 %rd69, %rd70;
cp.async.bulk.tensor.2d.global.shared::cta.bulk_group [%rd69, {%r284, %r283}], [%r1880];
图 9. CUTLASS 内核 PTX 显示按值传递
通过直接传递 TMA 描述符而不是传递全局内存指针,CUTLASS 内核避免了三个额外的 H2D 复制内核,而是将这些复制包含在 GEMM 的单个设备内核启动中。
由于描述符移动到设备的方式不同,包括准备张量供 TMA 消耗的时间在内的内核延迟也大相径庭。对于 M=1-128,N=4096,K=4096,CUTLASS pingpong 内核的平均延迟为 10us,而 Triton TMA 内核的平均完成时间为 4ms。这慢了大约 3330 倍,似乎与 Triton 进行 TMA 描述符传输的 3 个独立内核启动直接相关。
Cuda 图表可能是减少这种情况的一种方法,但考虑到 H2D 副本产生的开销,当前的 Triton 实现(端到端测量时)不具备竞争力。重构 Triton 编译器管理 TMA 描述符的方式可能会解决这个差距。因此,我们上面的数据侧重于比较实际的计算内核吞吐量,而不是端到端性能。
结果总结
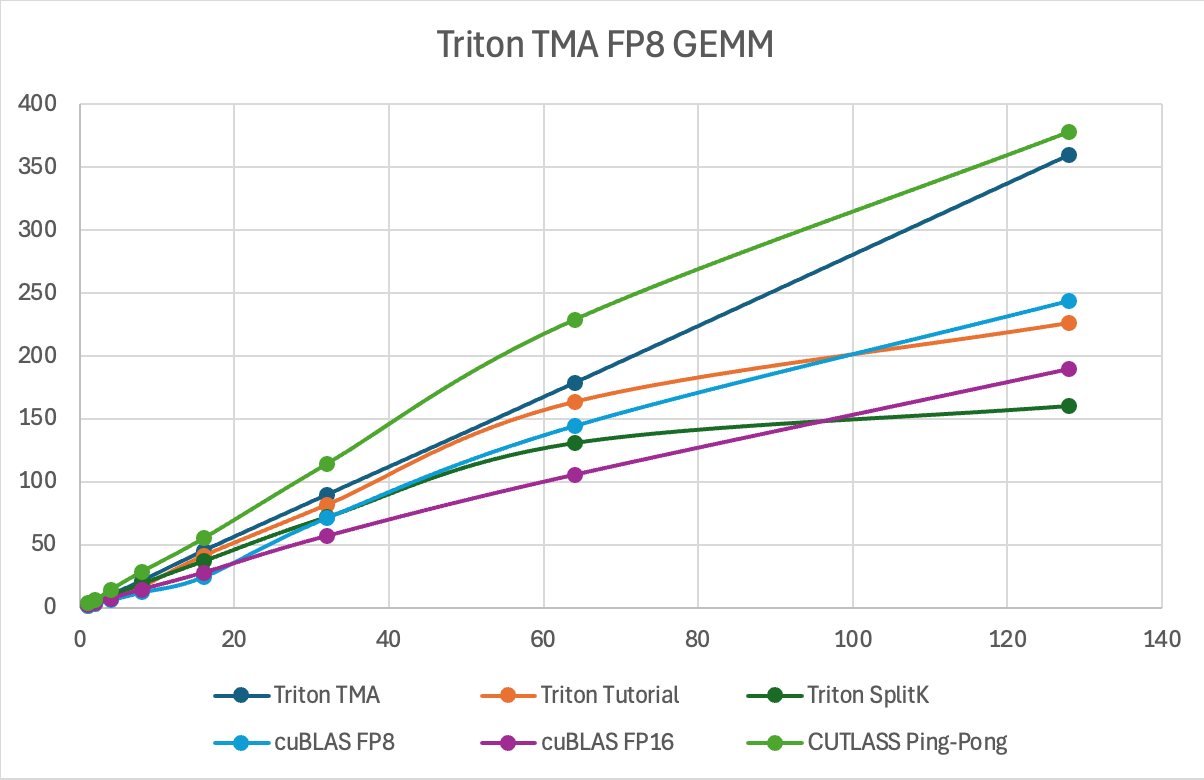
图 10. Triton FP8 TMA GEMM TFLOPs 比较
| M | Triton TMA | Triton 教程 | Triton SplitK | cuBLAS FP8 | cuBLAS FP16 | CUTLASS Ping-Pong FP8 |
| 1 | 2.5 | 1 | 2.4 | 1.5 | 1.8 | 3.57 |
| 2 | 5.1 | 2.5 | 4.8 | 3.1 | 3.6 | 5.9 |
| 4 | 10.3 | 7.21 | 9.6 | 6.1 | 7.2 | 14.3 |
| 8 | 21.0 | 16.5 | 19.2 | 12.3 | 14.4 | 28.6 |
| 16 | 44.5 | 41.0 | 37.2 | 24.5 | 27.7 | 55.1 |
| 32 | 89.7 | 81.2 | 72.2 | 71.6 | 56.8 | 114.4 |
| 64 | 178.5 | 163.7 | 130.8 | 144.6 | 105.3 | 228.7 |
| 128 | 359.7 | 225.9 | 160.1 | 244.0 | 189.2 | 377.7 |
图 11. Triton FP8 TMA GEMM TFLOPs 比较表
上图和表格总结了我们通过利用 TMA 硬件单元在单个 NVIDIA H100 上为 FP8 GEMM 实现的性能提升,超过了非 TMA Triton 内核和高性能 CUDA (cuBLAS) 内核。需要注意的关键点是,该内核在批处理大小方面具有优于竞争对手的卓越扩展特性。我们进行基准测试的问题规模代表了中小批处理大小 LLM 推理中发现的矩阵形状。因此,对于那些有兴趣将此内核用于 FP8 LLM 部署用例的人来说,中 M 区域(M=32 到 M=128)的 TMA GEMM 内核性能将至关重要,因为 FP8 压缩数据类型可以允许更大的矩阵适应 GPU 内存。
总结我们的分析,Triton 和 CUTLASS 中的 TMA 实现存在功能集支持(多播、预取等)以及 TMA 描述符如何传递给 GPU 内核方面的差异。如果以更接近 CUTLASS 内核(按值传递)的方式传递此描述符,则可以避免多余的 H2D 复制,从而大大提高端到端性能。
未来工作
对于未来的研究,我们计划通过与社区合作,将 CUTLASS 的 TMA 加载架构整合到 Triton 中,并研究 FP8 GEMM 的协同内核(Ping-Pong 内核的修改策略)来改进这些结果。
此外,一旦 Triton 中启用了线程块集群和 TMA 原子操作等功能,我们可能会通过在 TMA GEMM 内核中利用 SplitK 策略获得进一步的加速,因为 Hopper 上的原子操作可以在分布式共享内存 (DSMEM) 而不是 L2 缓存中执行。我们还注意到 NVIDIA Hopper GPU 与其他 AI 硬件加速器(如 Google 的 TPU 和 IBM 的 AIU)的相似之处,它们都是数据流架构。在 Hopper 上,由于 TMA(我们在这篇博客中 extensively 讨论过)和 DSMEM(我们计划在未来的帖子中介绍)的加入,数据现在可以从 GMEM “流向”互连的 SM 网络。