投机解码是一种用于推理的优化技术,它在生成当前 token 的同时,在一个前向传播中对未来的 token 进行有根据的猜测。它包含一个验证机制,以确保这些猜测的 token 的正确性,从而保证投机解码的整体输出与传统解码的输出相同。优化大型语言模型(LLM)的推理成本,可以说是降低生成式 AI 成本和提高其采用率的最关键因素之一。为此,有多种推理优化技术可用,包括自定义内核、输入请求的动态批处理和大型模型的量化。
在这篇博客文章中,我们提供了投机解码的指南,并展示了它如何与其他优化共存。我们很自豪能开源以下内容,其中包括第一个 Llama3 模型投机器:
- 适用于 Meta Llama3 8B、IBM Granite 7B lab、Meta Llama2 13B 和 Meta Code Llama2 13B 的投机器模型。
- 通过 IBM 的 HF TGI 分支进行推理的代码。
- 训练您自己的投机器和相应配方的代码。
我们已将这些投机器部署到拥有数千日常用户的内部生产级环境中,并观察到语言模型(Llama3 8B、Llama2 13B 和 IBM Granite 7B)的速度提升了 2 倍,IBM Granite 20B 代码模型的速度提升了 3 倍。我们在这份 技术报告 中提供了我们方法的详细解释,并计划在即将发布的 ArXiv 论文中进行深入分析。
投机解码:推理
我们在内部生产环境中运行 IBM TGIS,该环境具有连续批处理、融合内核和量化内核等优化。为了在 TGIS 中启用投机解码,我们修改了 vLLM 的分页注意力内核。接下来,我们将描述推理引擎为启用投机解码而进行的关键更改。
投机解码的前提是模型足够强大,可以在单个前向传播中预测多个 token。然而,当前的推理服务器经过优化,每次只能预测一个 token。在我们的方法中,我们为 LLM 附加了多个投机头(除了通常的一个),以预测第 _N+1_、_N+2_、_N+3_ 个… token。例如,3 个头将预测 3 个额外的 token。投机器架构的详细信息将在本博客的后面部分解释。在推理过程中实现_效率_和_正确性_面临两个挑战:一是无需复制 KV 缓存即可进行预测,二是验证预测是否与原始模型的输出匹配。
在典型的生成循环中,在单个前向步骤处理完提示后,将序列长度为 1(预测的下一个 token)的输入与 KV 缓存一起输入到模型的前向传播中。在朴素的投机解码实现中,每个投机头都将拥有自己的 KV 缓存,但我们修改了 vLLM 项目中开发的分页注意力内核,以实现高效的 KV 缓存维护。这确保了在较大的批次大小时吞吐量不会降低。此外,我们修改了注意力掩码,以启用对 _N+1_ 个 token 的验证,从而在不偏离原始模型输出的情况下启用投机解码。此实现的详细信息记录在 此处。
结果
我们使用一个简单的提示,说明了使用 Meta 的 Llama2 13B 聊天版本所获得的加速。
图 2:非投机生成(左)与投机生成(右)的视觉说明
我们将上述解决方案部署到内部生产环境中。下图报告了两个指标——首次生成 token 的时间 (TTFT) 和 token 间延迟 (ITL),在不同并发用户数(在图线上的数字中表示)下。我们观察到,对于所有批次大小,投机解码版本的 Llama2 13B 聊天模型速度几乎是非投机版本的两倍,而 Granite 20B 代码模型速度几乎是其三倍。我们观察到较小模型(IBM 的 Granite 7B 和 Meta Llama3 8B 模型)也有类似的行为。
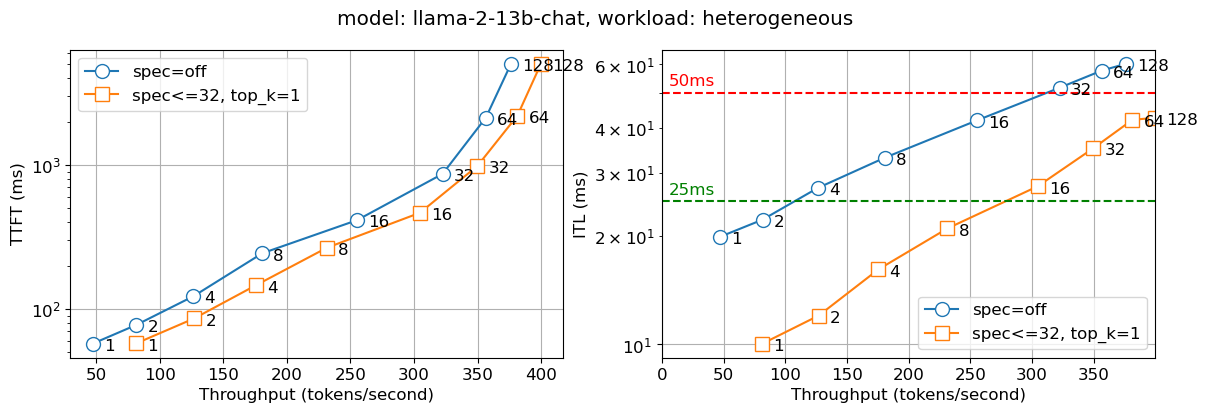
图 3:Llama 13B 的首次生成 token 时间(TTFT – 左)和 token 间延迟(ITL – 右),图上标示了并发用户数
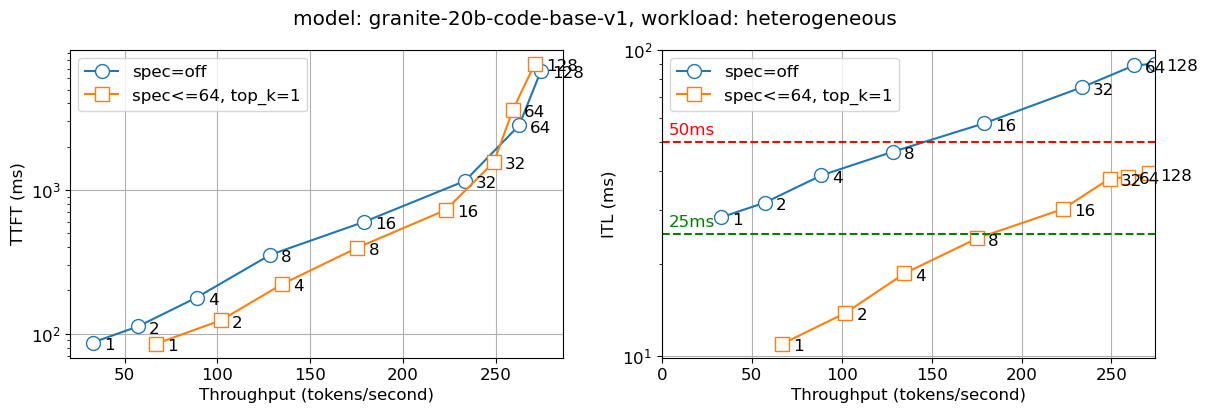
图 4:Granite 20B Code 的首次生成 token 时间(TTFT – 左)和 token 间延迟(ITL – 右),图上标示了并发用户数
效率说明
我们进行了大量实验,以确定投机器训练的正确配置。这些配置是:
- 投机器架构:当前方法允许修改头的数量,这对应于我们可以向前看的 token 数量。增加头的数量也会增加所需的额外计算量和训练复杂性。在实践中,对于语言模型,我们发现 3-4 个头效果很好,而对于代码模型,我们发现 6-8 个头可以带来好处。
- 计算:增加头的数量会导致两个方面的计算量增加,一是单次前向传播的延迟增加,二是多个 token 所需的计算量。如果投机器在拥有更多头时不够准确,将导致计算浪费,从而增加延迟并降低吞吐量。
- 内存:增加的计算量通过每次前向传播所需的 HBM 往返次数来抵消。请注意,如果我们能够正确预测 3 个 token,我们就节省了 HBM 上的三次往返时间。
我们为语言模型选择了 3-4 个头,为代码模型选择了 6-8 个头,并且在 7B 到 20B 的不同模型尺寸上,我们观察到与非投机解码相比,显著的延迟改进而没有吞吐量损失。我们开始在批次大小超过 64 时观察到吞吐量下降,这在实践中很少发生。
投机解码:训练
投机解码有两种主要方法,一种是利用较小的模型(例如,Llama 7B 作为 Llama 70B 的投机器),另一种是附加投机头(并训练它们)。在我们的实验中,我们发现附加投机头的方法在模型质量和延迟增益方面都更有效。
投机器架构
Medusa 使投机解码广受欢迎;他们的方法是在现有模型中添加一个头,然后训练它进行投机。我们通过将“头”分层来修改 Medusa 架构,每个头阶段预测一个 token,然后将其馈送到下一个头阶段。这些多阶段头如下图所示。我们正在探索通过在多个阶段和基础模型之间共享嵌入表来最小化嵌入表的方法。
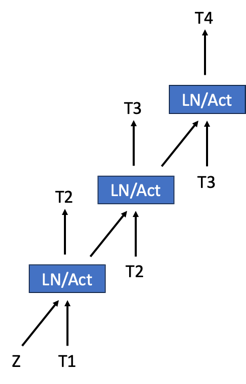
图 4:一个 3 头多阶段投机器的简单架构图。Z 是来自基础模型的状态。
投机器训练
出于效率原因,我们采用两阶段方法训练投机器。在第一阶段,我们使用小批量和长序列长度(4k token)进行训练,并采用标准的因果 LM 方法进行训练。在第二阶段,我们使用来自基础模型生成的大批量和短序列长度(256 token)。在这个训练阶段,我们调整头以匹配基础模型的输出。通过大量实验,我们发现第一阶段与第二阶段的步数比为 5:2 效果很好。我们下图中展示了这些阶段的进展。我们使用 PyTorch FSDP 和 IBM FMS 来训练投机器。
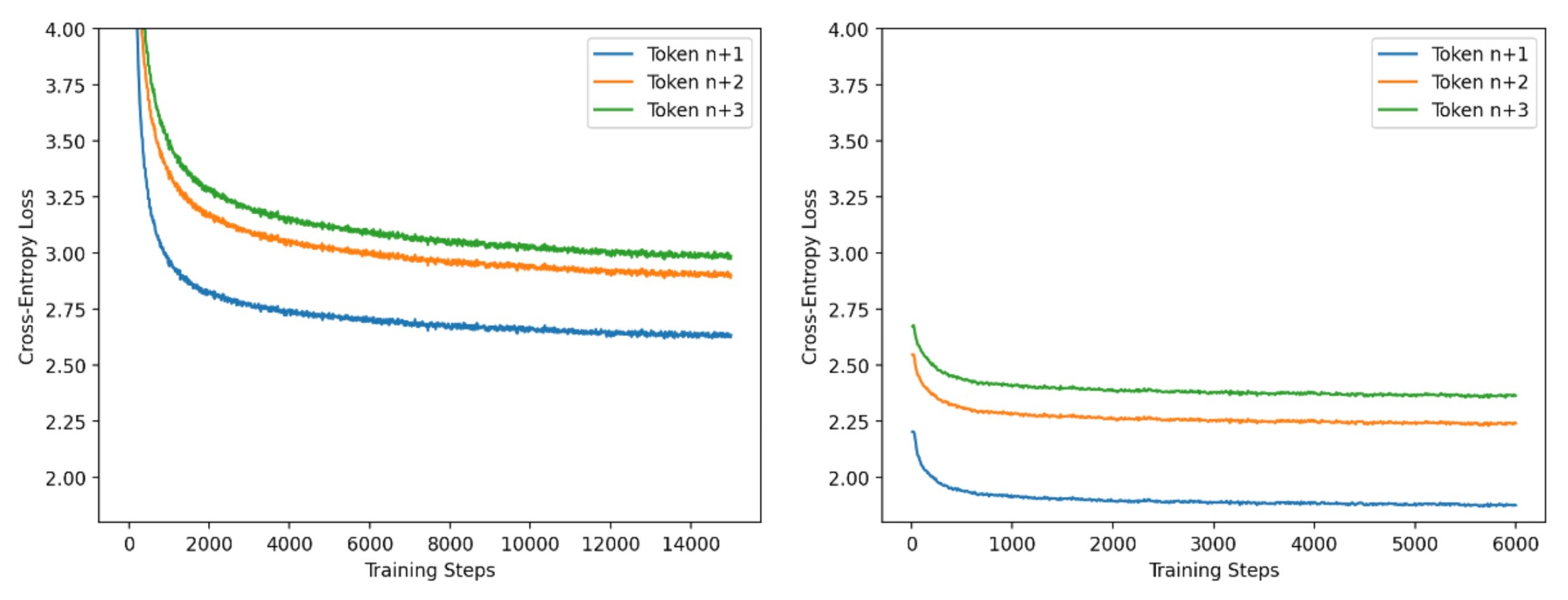
图 5:Llama2-13B 投机器训练的每头训练损失曲线,阶段 1 和 2
结论和未来工作
通过这篇博客,我们发布了一种新的投机解码方法和以下资产:
- 用于改进 Llama3 8B、Llama2 13B、Granite 7B 和 CodeLlama 13B 等一系列模型的 token 间延迟的模型。
- 用于推理的生产级代码。
- 训练投机器的配方。
我们正在努力训练 Llama3 70B 和 Mistral 模型的投机器,并邀请社区贡献和帮助改进我们的框架。我们也很乐意与主要开源服务框架合作,如 vLLM 和 TGI,以回馈我们的投机解码方法,造福社区。
致谢
有几个团队帮助我们实现了推理的这些延迟改进。我们衷心感谢 vLLM 团队以清晰可重用的方式创建了分页注意力内核。我们向 Meta 的 PyTorch 团队表示感谢,他们为这篇博客提供了反馈,并持续努力优化 PyTorch 的使用。特别感谢 IBM Research 的内部生产团队,他们将这个原型投入生产并使其变得更加健壮。感谢 Stas Bekman 对博客提供了富有洞察力的评论,从而改进了对计算、内存和投机器有效性之间权衡的解释。
分页注意力内核由 Josh Rosenkranz 和 Antoni Viros i Martin 集成到 IBM FMS 中。投机器架构和训练由 Davis Wertheimer、Pavithra Ranganathan 和 Sahil Suneja 完成。建模代码与推理服务器的集成由 Thomas Parnell、Nick Hill 和 Prashant Gupta 完成。