在人工智能创新以前所未有的速度加速发展的背景下,Meta 的 Llama 开源大型语言模型 (LLM) 家族脱颖而出,成为一项显著的突破。Llama 标志着 LLM 的一个重大进步,展示了预训练架构在各种应用中的强大能力。Llama 2 进一步拓展了规模和能力的边界,激发了语言理解、生成及其他领域的进步。
在 Llama 发布后不久,我们发布了一篇博客文章,展示了使用 PyTorch/XLA 在 Cloud TPU v4 上为 Llama 实现超低推理延迟。在此成果的基础上,今天,我们很荣幸能分享使用 PyTorch/XLA 在 Cloud TPU v4 和我们最新的 AI 超级计算机 Cloud TPU v5e 上实现的 Llama 2 训练和推理性能。
在这篇博客文章中,我们以 Llama 2 为例,展示了 PyTorch/XLA 在 Cloud TPU 上进行 LLM 训练和推理的强大能力。我们讨论了用于提高推理吞吐量和训练模型 FLOPS 利用率 (MFU) 的计算技术和优化。对于 Llama 2 70B 参数,我们实现了 53% 的训练 MFU、17 毫秒/token 推理延迟、42 token/秒/芯片的吞吐量,所有这些都由 Google Cloud TPU 上的 PyTorch/XLA 提供支持。我们提供了训练用户指南和推理用户指南,以重现本文中的结果。此外,您可以在此处找到我们的 Google Next 2023 演示文稿。
模型概述
Llama 2 提供多种尺寸,从 7B 到 70B 参数不等,可满足不同的需求、计算资源以及训练/推理预算。无论是小型项目还是大规模部署,Llama 模型都提供多功能性和可扩展性,以适应广泛的应用。
Llama 2 是一个自回归语言模型,它使用优化的 Transformer 架构。最大的 70B 模型使用分组查询注意力,这在不牺牲质量的情况下加快了推理速度。Llama 2 在 2 万亿个 token 上进行了训练(比 Llama 多 40% 的数据),并且推理上下文长度为 4,096 个 token(是 Llama 上下文长度的两倍),这使得模型具有更高的准确性、流畅性和创造力。
Llama 2 是一个最先进的 LLM,在推理、编码、熟练度知识测试等多个基准测试中优于许多其他开源语言模型。模型的规模和复杂性对 AI 加速器提出了许多要求,使其成为 PyTorch/XLA 在 Cloud TPU 上进行 LLM 训练和推理性能的理想基准。
LLM 的性能挑战
Llama 2 等 LLM 的大规模分布式训练带来了技术挑战,需要实用的解决方案才能最有效地利用 TPU。Llama 的大小可能会使 TPU 的内存和处理资源紧张。为了解决这个问题,我们使用模型分片,它涉及将模型分解成更小的片段,每个片段都符合单个 TPU 核心的容量。这使得跨多个 TPU 的并行化成为可能,从而提高了训练速度,同时减少了通信开销。
另一个挑战是有效地管理训练 Llama 2 所需的大型数据集,这需要有效的数据分布和同步方法。此外,优化学习率调度、梯度聚合和分布式 TPU 之间的权重同步等因素对于实现收敛至关重要。
在预训练或微调 Llama 2 之后,对模型检查点运行推理会带来额外的技术挑战。我们之前的博客文章中讨论的所有挑战,例如自回归解码、可变输入提示长度以及模型分片和量化的需求,仍然适用于 Llama 2。此外,Llama 2 引入了两个新功能:分组查询注意力 (grouped-query attention) 和当所有提示都达到 eos 时提前停止。我们将讨论 PyTorch/XLA 如何应对这些挑战,以在 Cloud TPU v4 和 v5e 上实现 Llama 2 的高性能、高成本效益的训练和推理。
大规模分布式训练
PyTorch/XLA 提供了两种主要的大规模分布式训练方式:SPMD,它利用 XLA 编译器将单设备程序转换为多设备分布式程序;以及 FSDP,它实现了广泛采用的 Fully Sharded Data Parallel 算法。
在这篇博客文章中,我们展示了如何使用 SPMD API 来注释 HuggingFace (HF) Llama 2 的实现,以最大限度地提高性能。作为比较,我们还展示了相同配置下的 FSDP 结果;请在此处阅读有关 PyTorch/XLA FSDP API 的信息。
SPMD 概述
让我们简要回顾一下 SPMD 的基本原理。有关详细信息,请参阅我们的博客文章和用户指南。
Mesh
一个多维数组,描述了 TPU 设备的逻辑拓扑。
# Assuming you are running on a TPU host that has 8 devices attached
num_devices = xr.global_runtime_device_count()
# mesh shape will be (4,2) in this example
mesh_shape = (num_devices // 2, 2)
device_ids = np.array(range(num_devices))
# axis_names 'x' and 'y' are optional
mesh = Mesh(device_ids, mesh_shape, ('x', 'y'))
Partition Spec (分区规范)
一个元组,描述了相应张量维度在 mesh 上如何分片。
partition_spec = ('x', 'y')
Mark Sharding (标记分片)
一个 API,它接受一个 mesh 和一个 partition_spec,然后为 XLA 编译器生成一个分片注释。
tensor = torch.randn(4, 4).to('xla')
# Let's resue the above mesh and partition_spec.
# It means the tensor's 0th dim is sharded 4 way and 1th dim is sharded 2 way.
xs.mark_sharding(tensor, mesh, partition_spec)
使用 SPMD 进行 2D 分片
在我们的 SPMD 博客文章中,我们展示了使用 1D FSDP 风格的分片。在这里,我们引入了一种更强大的分片策略,称为 2D 分片,其中参数和激活都被分片。这种新的分片策略不仅允许拟合更大的模型,还将 MFU 提高到 **54.3%**。有关更多详细信息,请阅读基准测试部分。
本节介绍了一组适用于大多数 LLM 的通用规则,为方便起见,我们直接引用了 HF Llama 中的变量名和配置名。
首先,让我们创建一个带有相应轴名称(数据和模型)的 2D 网格。数据轴通常是我们分发输入数据的地方,模型轴是我们进一步分发模型的地方。
mesh = Mesh(device_ids, mesh_shape, ('data', 'model'))
mesh_shape 可以是一个超参数,针对不同的模型大小和硬件配置进行调整。相同的网格将在所有以下分片注释中重复使用。在接下来的几节中,我们将介绍如何使用网格来分片参数、激活和输入数据。
参数分片
下表总结了 HF Llama 2 的所有参数及相应的分区规范。HF 示例代码可在此处找到。
| 参数名称 | 解释 | 参数形状 | 分区规范 |
embed_tokens | 嵌入层 | (vocab_size,hidden_size) | (模型,数据) |
q_proj | 注意力权重 | (num_heads x head_dim,hidden_size) | (数据,模型) |
k_proj / v_proj | 注意力权重 | (num_key_value_heads x head_dim,hidden_size) | (数据,模型) |
o_proj | 注意力权重 | (hidden_size,num_heads x head_dim) | (模型,数据) |
gate_proj / up_proj | MLP 权重 | (intermediate_size,hidden_size) | (模型,数据) |
down_proj | MLP 权重 | (hidden_size,intermediate_size) | (数据,模型) |
lm_head | HF 输出嵌入 | (vocab_size,hidden_size) | (模型,数据) |
表 1:SPMD 2D 分片参数分区规范
规则是,除了 QKVO 投影之外,任何权重的 hidden_size 维度都根据网格的 data 轴进行分片,然后其他维度与剩余的 model 轴进行分片。对于 QKVO,则相反。这种模型-数据轴旋转方法与 Megatron-LM 类似,旨在减少通信开销。对于 layernorm 权重,鉴于它们是 1D 张量,我们隐式地将它们标记为在不同设备之间复制。
激活分片
为了更好地利用设备内存,我们通常需要注释一些内存绑定操作的输出。这样,编译器被迫只在设备上保留部分输出而不是完整的输出。在 Llama 2 中,我们明确注释所有 torch.matmul 和 nn.Linear 的输出。表 2 总结了相应的注释;HF 示例代码可在此处找到。
| 输出名称 | 解释 | 输出形状 | 分区规范 |
inputs_embeds | 嵌入层输出 | (batch_size,sequence_length,hidden_size) | (数据,无,模型) |
query_states | 注意力 nn.Linear 输出 | (batch_size,sequence_length,num_heads x head_dim) | (数据,无,模型) |
key_states / value_states | 注意力 nn.Linear 输出 | (batch_size,sequence_length,num_key_value_heads x head_dim) | (数据,无,模型) |
attn_weights | 注意力权重 | (batch_size,num_attention_heads,sequence_length,sequence_length) | (数据,模型,无,无) |
attn_output | 注意力层输出 | (batch_size,sequence_length,hidden_size) | (数据,无,模型) |
up_proj / gate_proj / down_proj | MLP nn.Linear 输出 | (batch_size,sequence_length,intermediate_size) | (数据,无,模型) |
logits | HF 输出嵌入输出 | (batch_size,sequence_length,hidden_size) | (数据,无,模型) |
表 2:SPMD 2D 分片激活分区规范
规则是,任何输出的 batch_size 维度都根据网格的 data 轴进行分片,然后任何输出的长度维度都被复制,最后维度沿 model 轴进行分片。
输入分片
对于输入分片,规则是沿网格的 data 轴分片批量维度,并复制 sequence_length 维度。下面是示例代码,相应的 HF 更改可以在此处找到。
partition_spec = ('data', None)
sharding_spec = xs.ShardingSpec(mesh, partition_spec)
# MpDeviceLoader will shard the input data before sending to the device.
pl.MpDeviceLoader(dataloader, self.args.device, input_sharding=sharding_spec, ...)
现在,所有需要分片的数据和模型张量都已覆盖!
优化器状态和梯度
您可能想知道是否也需要对优化器状态和梯度进行分片。好消息是:XLA 编译器的分片传播功能在这两种情况下都会自动完成分片注释,无需更多提示即可提高性能。
需要注意的是,优化器状态通常在训练循环的第一次迭代中初始化。从 XLA 编译器的角度来看,优化器状态是第一个图的输出,因此具有分片注释的传播。对于后续迭代,优化器状态成为第二个图的输入,分片注释从第一个图传播而来。这也是 PyTorch/XLA 通常为训练循环生成两个图的原因。如果优化器状态在第一次迭代之前以某种方式初始化,则用户必须手动注释它们,就像模型权重一样。
同样,上述分片注释的所有具体示例都可以在我们的 HF Transformers 的分支中找到:此处。该存储库还包含我们实验性功能 MultiSlice 的代码,包括 HybridMesh 和 dcn 轴,这些都遵循上述原则。
注意事项
在使用 SPMD 进行训练时,有几点需要注意:
- 使用
torch.einsum而不是torch.matmul;torch.matmul通常会展平张量并在最后执行torch.mm,这对于轴已分片的 SPMD 来说是不利的。XLA 编译器将难以确定如何传播分片。 - PyTorch/XLA 提供了修补的
[nn.Linear](https://github.com/pytorch/xla/blob/master/torch_xla/experimental/xla_sharding.py#L570)来克服上述限制。
import torch_xla.experimental.xla_sharding as xs
from torch_xla.distributed.fsdp.utils import apply_xla_patch_to_nn_linear
model = apply_xla_patch_to_nn_linear(model, xs.xla_patched_nn_linear_forward)
- 始终在所有分片中重复使用相同的网格。
- 始终指定
--dataloader_drop_last yes。最后一个较小的数据难以注释。 - 在主机上初始化的大型模型可能会导致主机端 OOM。避免此问题的一种方法是在 元设备 上初始化参数,然后逐层创建和分片实际张量。
基础设施改进
除了上述建模技术外,我们还开发了其他功能和改进以最大限度地提高性能,包括:
- 我们启用了异步集体通信。这需要增强 XLA 编译器的延迟隐藏调度器,以更好地优化 Llama 2 PyTorch 代码。
- 我们现在允许在 IR 图的中间进行分片注释,就像 JAX 的 jax.lax.with_sharding_constraint 一样。以前,只对图输入进行注释。
- 我们还将复制的分片规范从编译器传播到图输出。这允许我们自动分片优化器状态。
推理优化
所有针对 Llama 推理实现的 PyTorch/XLA 优化 也都应用于 Llama 2。这包括 使用 torch-xla collective ops 的张量并行 + Dynamo (torch.compile)、避免重新编译的自回归解码逻辑改进、分桶提示长度、具有编译友好索引操作的 KV-cache。Llama 2 引入了两个新变化:分组查询注意力,以及当所有提示都达到 eos 时提前停止。我们应用了相应的更改,以通过 PyTorch/XLA 促进更好的性能和灵活性。
分组查询注意力
Llama 2 为 70B 模型启用了分组查询注意力。它允许 Key 和 Value 头的数量小于 Query 头的数量,同时仍支持 KV 缓存分片,最多可达 KV 头的数量。对于 70B 模型,n_kv_heads 为 8,这限制了张量并行度小于或等于 8。为了将模型检查点分片以在更多设备上运行,K、V 投影权重需要先复制,然后分成多个部分。例如,要将 70B 模型检查点从 8 份分片到 16 份,K、V 投影权重将被复制并分成每片 2 份。我们提供了一个 reshard_checkpoints.py 脚本来处理这个问题,并确保分片的检查点在数学上与原始检查点相同。
EOS 提前停止
Llama 2 的生成代码添加了提前停止逻辑。一个 eos_reached 张量用于跟踪所有提示生成的完成情况,如果批次中所有提示都达到了 eos 标记,则生成将提前停止。类似的更改也已整合到 PyTorch/XLA 优化版本中,并进行了一些微调。
在 PyTorch/XLA 中,将 eos_reached 等张量的值作为控制流条件的一部分进行检查将调用阻塞的设备到主机传输。张量将从设备内存传输到 CPU 内存以评估其值,而所有其他逻辑都在等待。这在每次生成新 token 后都会引入毫秒级的延迟。作为一种权衡,我们将检查 eos_reached 值的频率降低到每 10 次新 token 生成一次。通过这一更改,阻塞的设备到主机传输的影响将减少 10 倍,而提前停止仍然有效,并且在每个序列达到 eos token 后最多会生成 9 个不必要的 token。
模型服务
PyTorch/XLA 正在研究一种服务策略,以使 PyTorch 社区能够通过 Torch.Export、StableHLO 和 SavedModel 服务他们的深度学习应用程序。PyTorch/XLA Serving 是 PyTorch/XLA 2.1 版本中的一个实验性功能;有关详细信息,请访问我们的服务用户指南。用户可以利用 TorchServe 来运行他们的单主机工作负载。
基准测试
指标
为了衡量训练性能,我们使用行业标准指标:模型 FLOPS 利用率 (MFU)。模型 FLOPS 是执行一次正向和反向传播所需的浮点运算。模型 FLOPS 与硬件和实现无关,仅取决于底层模型。MFU 衡量模型在训练期间利用实际硬件的效率。实现 100% MFU 意味着模型完美地使用了硬件。
为了衡量推理性能,我们使用行业标准指标:吞吐量。首先,我们测量模型编译和加载后的每 token 延迟。然后,我们通过将批量大小 (BS) 除以每芯片延迟来计算吞吐量。因此,吞吐量衡量模型在生产环境中的表现,而无论使用了多少芯片。
结果
训练评估
图 1 显示了 Llama 2 SPMD 2D 分片在各种 Google TPU v4 硬件上的训练结果,其中 PyTorch/XLA FSDP 作为基线。与在相同硬件配置下运行的 FSDP 相比,我们针对所有尺寸的 Llama 2 将 MFU 提高了 28%。这一性能提升主要归因于:1) 2D 分片比 FSDP 具有更低的通信开销,2) SPMD 中启用了异步集体通信,从而允许通信和计算重叠。另请注意,随着模型规模的扩大,我们保持了高 MFU。表 3 显示了所有硬件配置以及训练基准中使用的一些超参数。
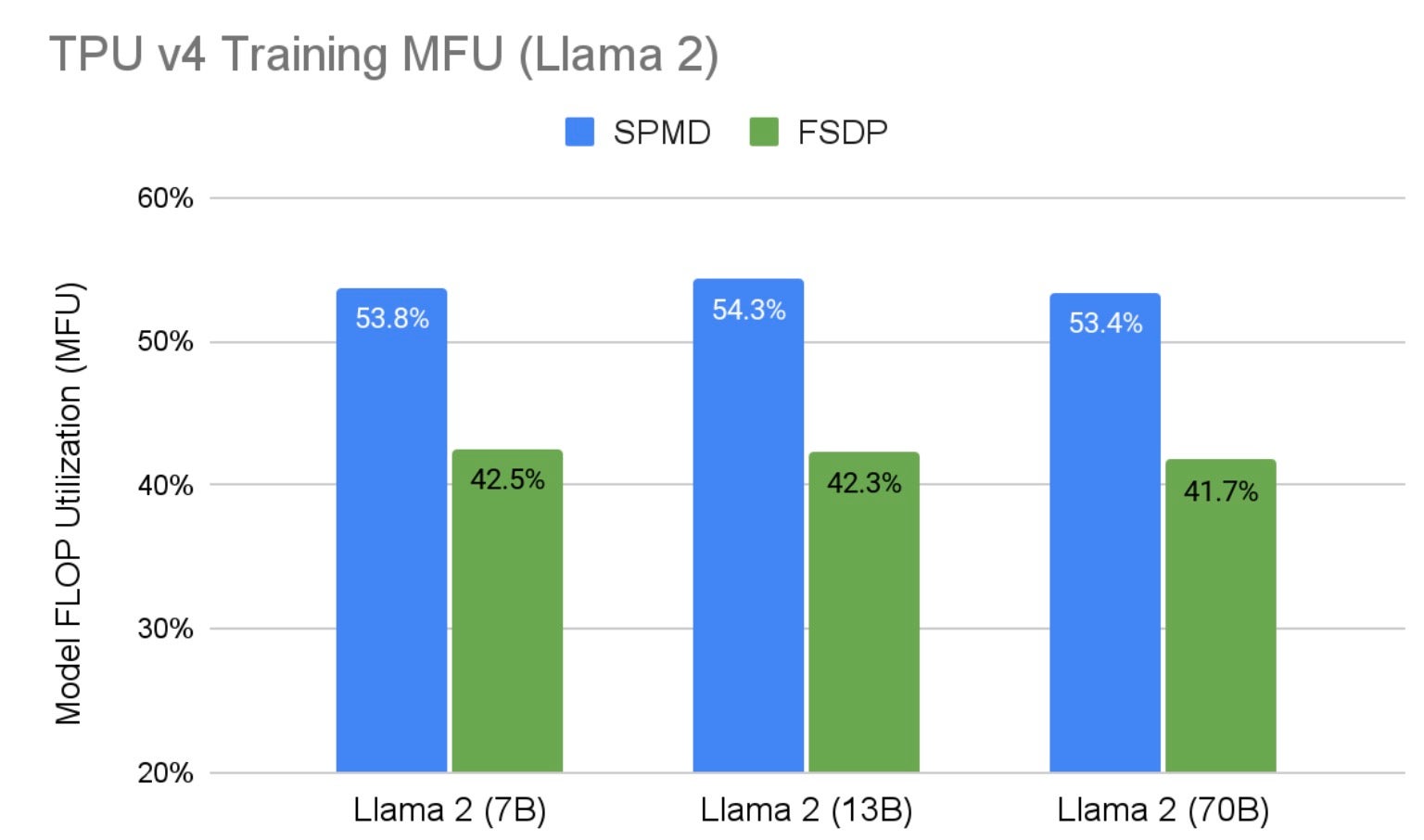
图 1:TPU v4 硬件上的 Llama 2 训练 MFU
图 1 中的结果是在序列长度为 1,024 时产生的。图 2 显示了在较大序列长度下的性能表现。它表明我们的性能也与序列长度呈线性关系。由于 2D 分片中未对序列长度轴进行分片,并且 TPU 对批处理大小非常敏感,因此需要较小的每设备批处理大小来适应较大序列长度带来的额外内存压力,因此 MFU 预计会略有下降。对于 Llama 2 70B 参数,性能下降低至 4%。在准备这些结果时,Hugging Face Llama 2 分词器将最大模型输入限制为 2,048,这使得我们无法评估更大的序列长度。
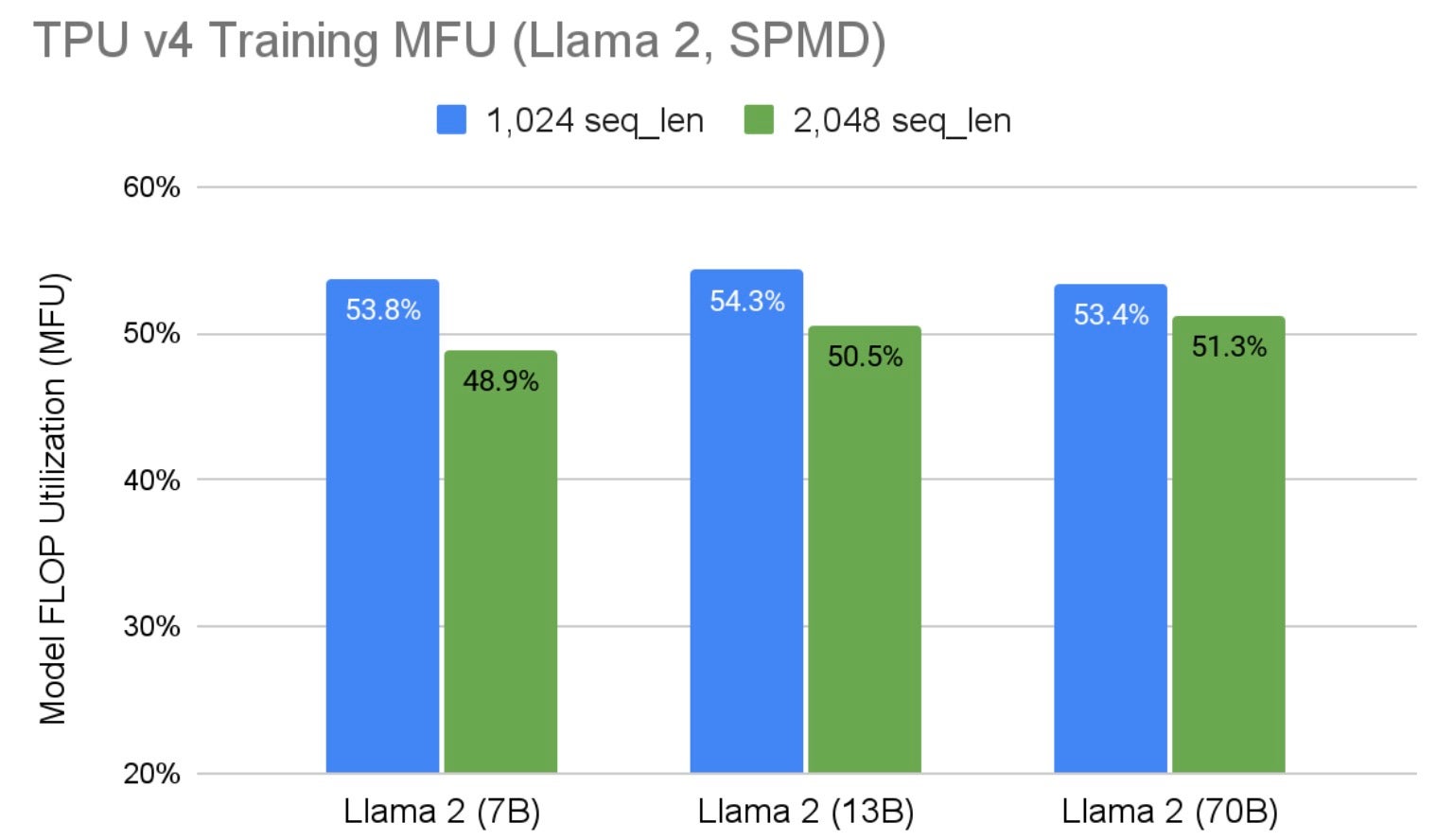
图 2:不同序列长度下 TPU v4 上的 Llama 2 SPMD 训练 MFU
| 模型尺寸 | 7B | 13B | 70B | |||
| TPU 核心数 | V4-32 | V4-64 | V4-256 | |||
| 网格形状 | (16, 1) | (32, 1) | (32, 4) | |||
| 序列长度 | 1,024 | 2,048 | 1,024 | 2,048 | 1,024 | 2,048 |
| 全局批次 | 256 | 128 | 256 | 128 | 512 | 256 |
| 每设备批次 | 16 | 8 | 8 | 4 | 16 | 8 |
表 3:Llama 2 SPMD 训练基准 TPU 配置和超参数
最后要提的是,我们使用 adafactor 作为优化器以更好地利用内存。再次,这里是 用户指南,可用于重现上述基准测试结果。
推理评估
在本节中,我们扩展了我们之前在 Cloud v4 TPU 上对 Llama 的评估。在这里,我们展示了 TPU v5e 在推理应用中的性能特性。
我们将推理吞吐量定义为模型每秒每个 TPU 芯片产生的 token 数量。图 3 显示了 Llama 2 70B 在 v5e-16 TPU 节点上的吞吐量。鉴于 Llama 是一个内存密集型应用程序,我们发现应用仅权重量子化可解锁将模型批次大小扩展到 32。在更大的 TPU v5e 硬件上,可能会实现更高的吞吐量结果,直到芯片之间的 ICI 网络带宽限制 TPU 切片提供更高的吞吐量。探索 TPU v5e 在 Llama 2 上的上限超出了本工作的范围。请注意,为了使 Llama 2 70B 模型在 v5e-16 上运行,我们复制了注意力头,使其每个芯片一个头,如上面推理部分所讨论的。如之前所讨论的,随着模型批次大小的增加,每 token 延迟成比例增长;量化通过减少内存 I/O 需求来改善整体延迟。
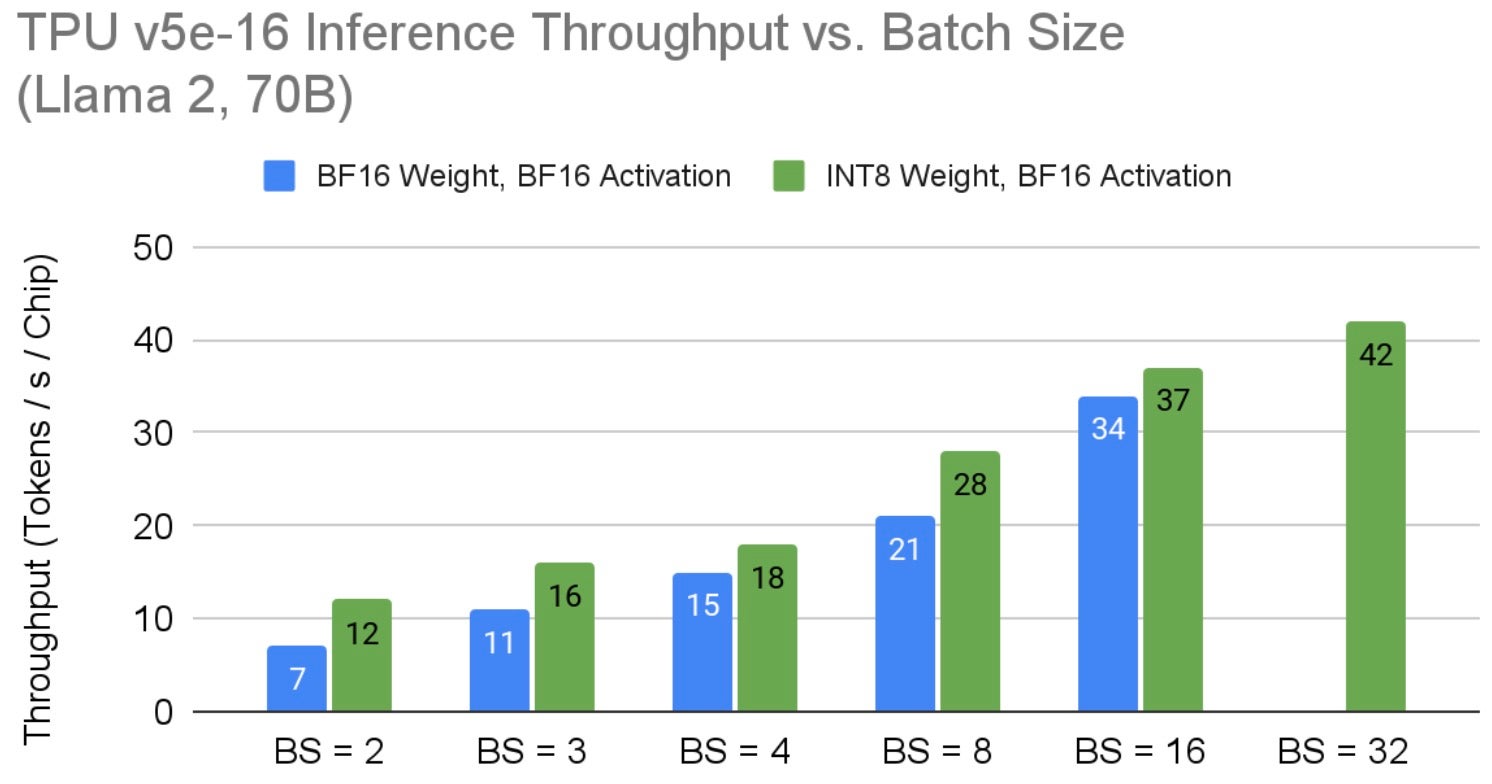
图 3:TPU v5e 上 Llama 2 70B 推理每芯片吞吐量与批处理大小的关系
图 4 显示了不同模型尺寸的推理吞吐量结果。这些结果突出了在给定硬件配置下使用 bf16 精度时的最大吞吐量。仅使用权重量化,70B 模型上的吞吐量达到 42。如前所述,增加硬件资源可能会带来性能提升。
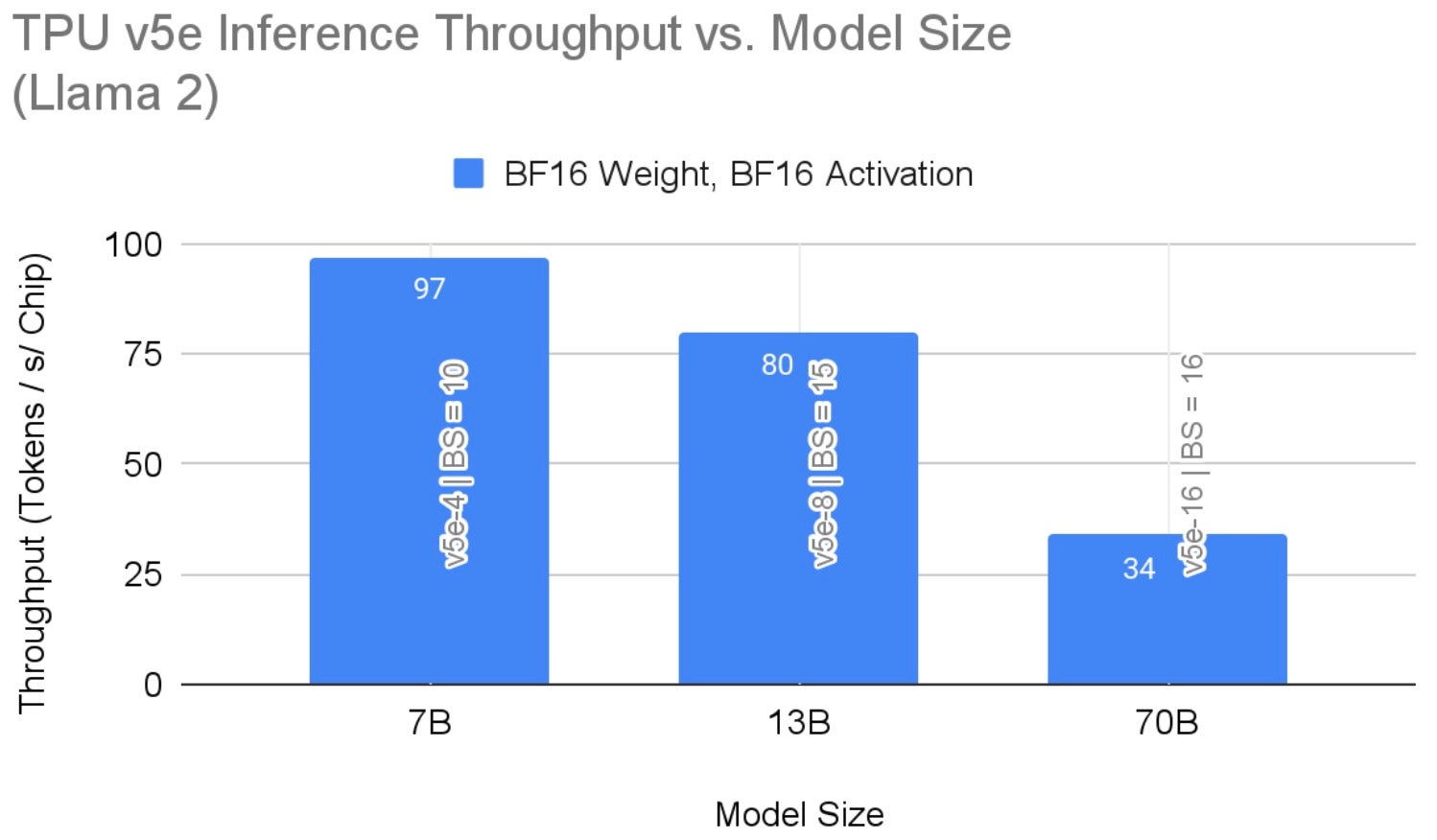
图 4:TPU v5e 上 Llama 2 推理每芯片吞吐量
图 5 显示了在 Cloud TPU v5e 上服务 Llama 2 模型(来自图 4)的成本。我们报告了基于 us-west4 区域 3 年承诺(预留)价格的 TPU v5e 每芯片成本。所有模型大小都使用最大序列长度 2,048 和最大生成长度 1,000 个 token。请注意,经过量化后,70B 模型的成本降至 **每 1,000 个 token 0.0036 美元**。
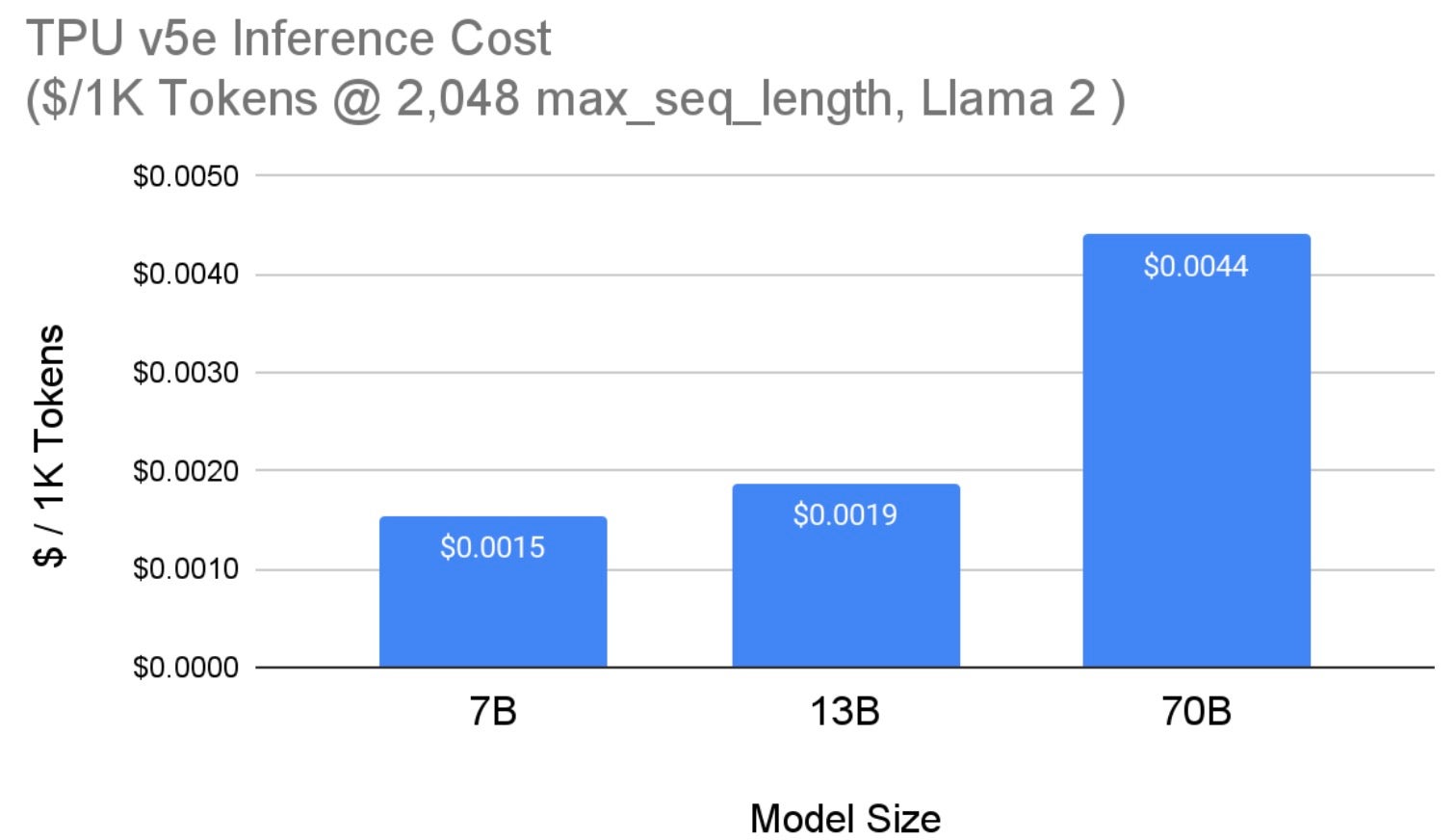
图 5:TPU v5e 上 Llama 2 推理每芯片成本
图 6 总结了我们在 TPU v5e 上最好的 Llama 2 推理延迟结果。Llama 2 7B 结果来自我们的非量化配置(BF16 权重,BF16 激活),而 13B 和 70B 结果来自量化配置(INT8 权重,BF16 激活)。我们将此观察归因于量化固有的内存节省与计算开销的权衡;因此,对于较小的模型,量化可能不会导致较低的推理延迟。
此外,提示长度对 LLM 的内存需求有很大影响。例如,当 max_seq_len=256 且批处理大小为 1,在 v5e-4 上运行 Llama2 7B 且未量化时,我们观察到 1.2ms/token 的延迟(即 201 tokens/秒/芯片)。
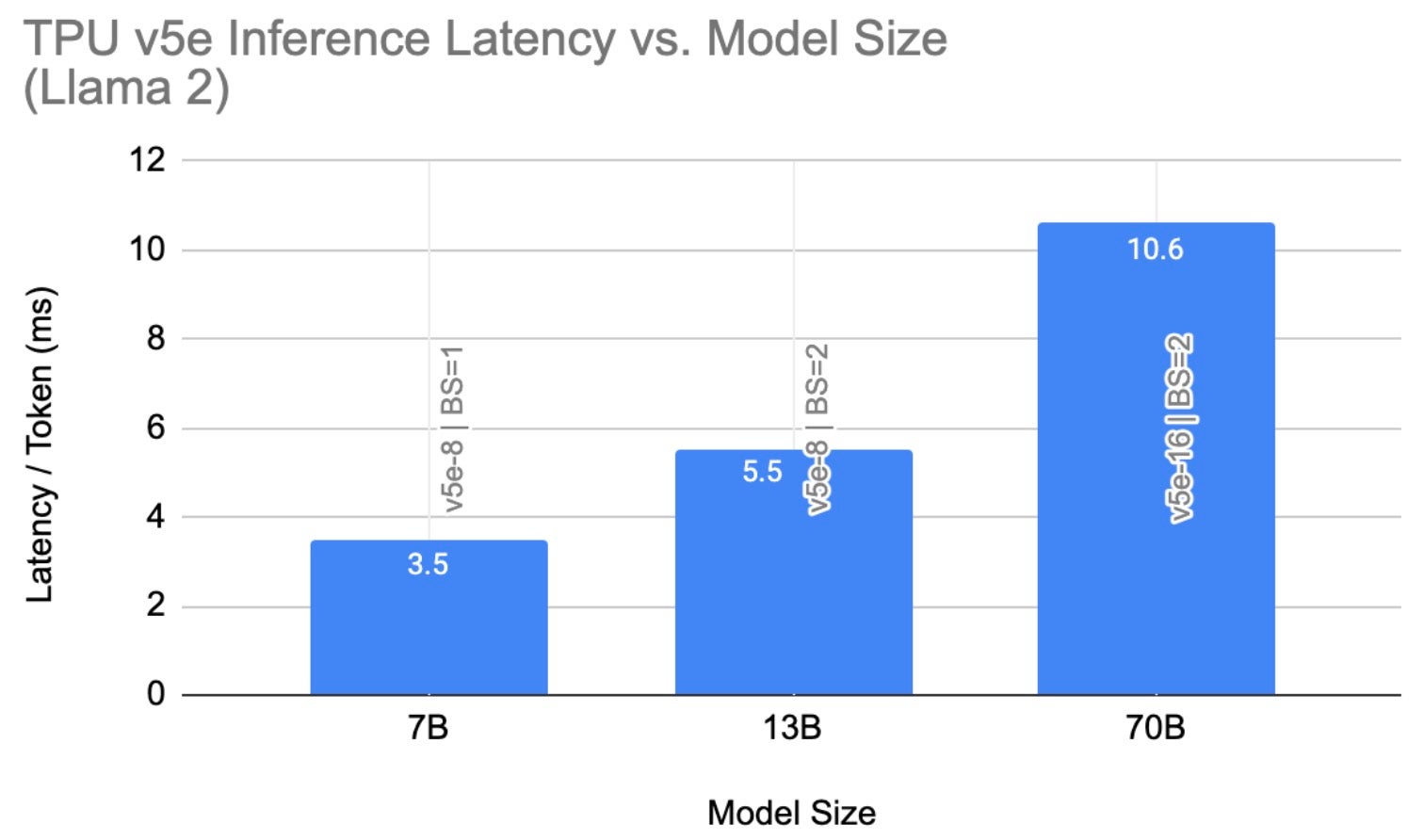
图 6:TPU v5e 上的 Llama 2 推理延迟
最终思考
最近的人工智能创新浪潮可谓是变革性的,其中 LLM 的突破首当其冲。Meta 的 Llama 和 Llama 2 模型是这一进步浪潮中的重要里程碑。PyTorch/XLA 独特地实现了 Llama 2 和其他 LLM 以及生成式 AI 模型在 Cloud TPU(包括新的 Cloud TPU v5e)上的高性能、高成本效益的训练和推理。展望未来,PyTorch/XLA 将继续在 Cloud TPU 上突破吞吐量和可扩展性的性能极限,同时保持相同的 PyTorch 用户体验。
我们对 PyTorch/XLA 的未来发展充满期待,并邀请社区加入我们。PyTorch/XLA 完全开源开发。因此,请在 GitHub 上提交问题、拉取请求和 RFC,以便我们公开协作。您还可以亲自尝试在包括 TPU 和 GPU 在内的各种 XLA 设备上使用 PyTorch/XLA。
我们要特别感谢 Marcello Maggioni、Tongfei Guo、Andy Davis、Berkin Ilbeyi 在这项工作中的支持和协作。
祝好,
Google 的 PyTorch/XLA 团队