最近,Llama 2 发布并引起了机器学习社区的广泛关注。Amazon EC2 Inf2 实例,由 AWS Inferentia2 提供支持,现已支持 Llama 2 模型的训练和推理。在这篇文章中,我们将展示如何使用最新的 AWS Neuron SDK 版本在 Amazon EC2 Inf2 实例上实现 Llama-2 模型的低延迟和高成本效益推理。我们首先介绍如何创建、编译和部署 Llama-2 模型,并解释 AWS Neuron SDK 引入的优化技术,以实现低成本下的高性能。然后,我们将展示我们的基准测试结果。最后,我们将展示如何通过 Amazon SageMaker 使用 TorchServe 在 Inf2 实例上部署 Llama-2 模型。

什么是 Llama 2
Llama 2 是一种自回归语言模型,它使用优化的 Transformer 架构。Llama 2 旨在用于英语的商业和研究用途。它有多种大小——70 亿、130 亿和 700 亿参数——以及预训练和微调版本。据 Meta 称,微调版本使用监督微调 (SFT) 和带有人类反馈的强化学习 (RLHF) 来与人类对有用性和安全性的偏好保持一致。Llama 2 在来自公开来源的 2 万亿个 token 数据上进行了预训练。微调模型旨在用于助手式聊天,而预训练模型可以适应各种自然语言生成任务。无论开发人员使用哪个版本的模型,Meta 的负责任使用指南都可以协助指导可能需要进行的额外微调,以通过适当的安全缓解措施来定制和优化模型。
Amazon EC2 Inf2 实例概览
Amazon EC2 Inf2 实例,采用 Inferentia2,提供 3 倍更高的计算能力,4 倍更多的加速器内存,从而实现高达 4 倍的吞吐量,以及高达 10 倍的低延迟,与第一代 Inf1 实例相比。
大型语言模型 (LLM) 推理是一种内存密集型工作负载,性能随加速器内存带宽的增加而提高。Inf2 实例是 Amazon EC2 中唯一针对推理优化的实例,可提供高速加速器互连 (NeuronLink),从而实现高性能大型 LLM 模型部署和高成本效益的分布式推理。您现在可以在 Inf2 实例上跨多个加速器高效且经济地部署数十亿参数的 LLM。
Inferentia2 支持 FP32、TF32、BF16、FP16、UINT8 和新的可配置 FP8 (cFP8) 数据类型。AWS Neuron 可以接受高精度 FP32 和 FP16 模型,并将其自动转换为低精度数据类型,同时优化准确性和性能。自动转换通过消除对低精度再训练的需求,并使用更小的数据类型实现更高性能的推理,从而缩短了上市时间。
为了灵活且可扩展地部署不断发展的深度学习模型,Inf2 实例具有硬件优化和软件支持,可用于动态输入形状以及通过标准 PyTorch 自定义运算符编程接口用 C++ 编写的自定义运算符。
Transformers Neuron (transformers-neuronx)
Transformers Neuron 是一个软件包,使 PyTorch 用户能够部署性能优化的 LLM 推理。它具有使用 XLA 高级运算符 (HLO) 实现的 Transformer 模型优化版本,这使得张量可以在多个 NeuronCore 之间进行分片(即张量并行),并实现了性能优化,例如用于 Neuron 硬件的并行上下文编码和 KV 缓存。Llama 2 的 XLA HLO 源代码可以在这里找到。
Llama 2 通过 LlamaForSampling 类在 Transformers Neuron 中得到支持。Transformers Neuron 为 Hugging Face 模型提供了无缝的用户体验,可在 Inf2 实例上提供优化的推理。更多详细信息可在 Transforms Neuron Developer Guide 中找到。在下一节中,我们将解释如何使用 Transformers Neuron 部署 Llama-2 13B 模型。此示例也适用于其他基于 Llama 的模型。
使用 Transformers Neuron 进行 Llama 2 模型推理
创建模型、编译和部署
我们在这里有三个简单的步骤来在 Inf2 实例上创建、编译和部署模型。
- 创建一个 CPU 模型,使用此脚本或以下代码片段序列化并将检查点保存在本地目录中。
from transformers import AutoModelForCausalLM
from transformers_neuronx.module import save_pretrained_split
model_cpu = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-hf", low_cpu_mem_usage=True)
model_dir = "./llama-2-13b-split"
save_pretrained_split(model_cpu, model_dir)
- 使用以下方法从保存序列化检查点的本地目录加载和编译模型。要加载 Llama 2 模型,我们使用 Transformers Neuron 中的
LlamaForSampling。请注意,环境变量NEURON_RT_NUM_CORES指定了运行时要使用的 NeuronCore 数量,它应该与为模型指定的张量并行 (TP) 度匹配。此外,NEURON_CC_FLAGS可在仅解码器 LLM 模型上启用编译器优化。
from transformers_neuronx.llama.model import LlamaForSampling
os.environ['NEURON_RT_NUM_CORES'] = '24'
os.environ['NEURON_CC_FLAGS'] = '--model-type=transformer'
model = LlamaForSampling.from_pretrained(
model_dir,
batch_size=1,
tp_degree=24,
amp='bf16',
n_positions=16,
context_length_estimate=[8]
)
现在,让我们编译模型并使用一行 API 将模型权重加载到设备内存中。
model.to_neuron()
- 最后,让我们在编译后的模型上运行推理。请注意,
sample函数的输入和输出都是 token 序列。
inputs = torch.tensor([[1, 16644, 31844, 312, 31876, 31836, 260, 3067, 2228, 31844]])
seq_len = 16
outputs = model.sample(inputs, seq_len, top_k=1)
Transformers Neuron 中的推理优化
张量并行
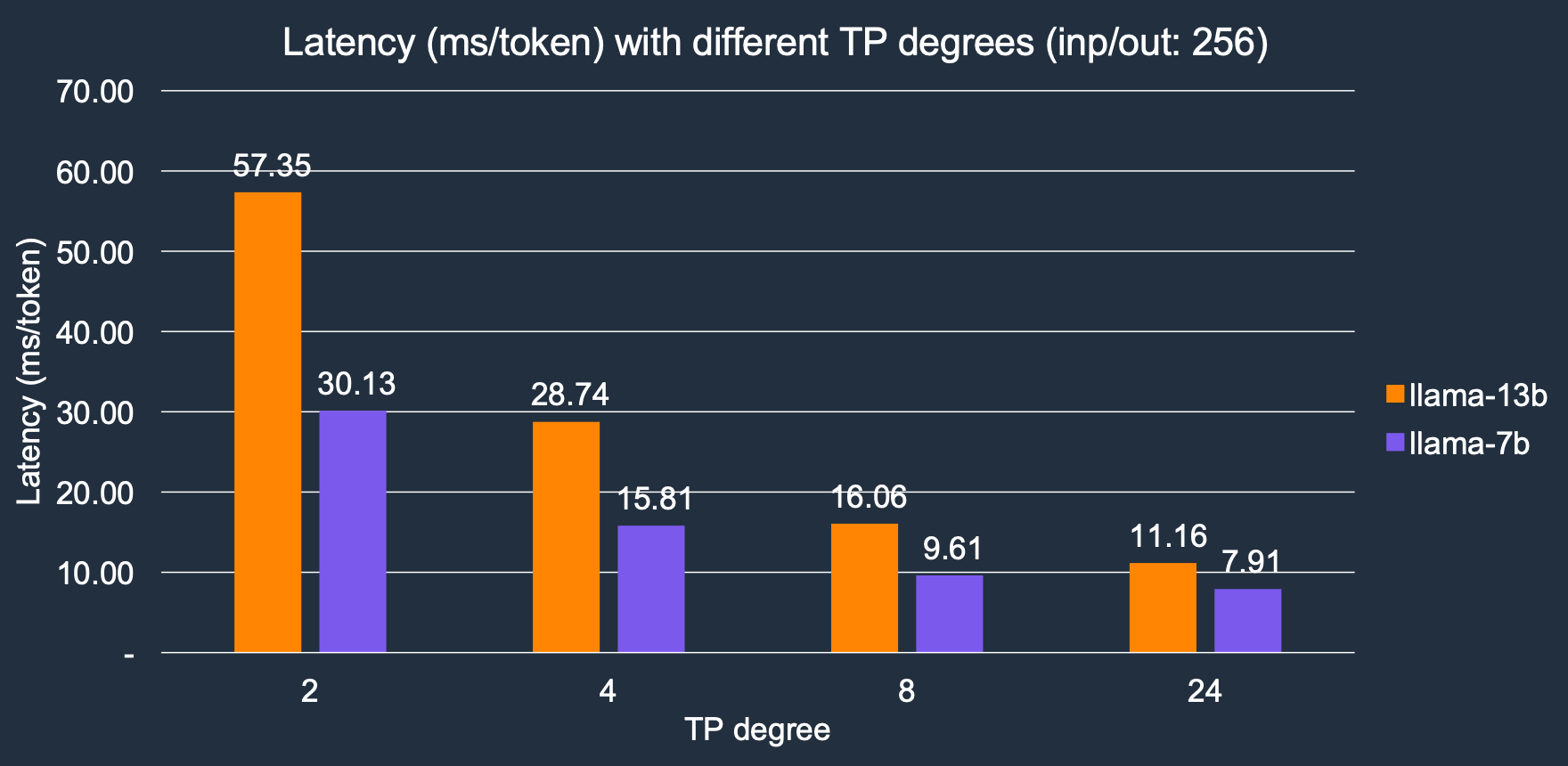
Transformer Neuron 在多个 NeuronCore 之间实现并行张量操作。我们将用于推理的核心数量表示为 TP 度。TP 度越大,内存带宽越高,从而导致延迟越低,因为 LLM token 生成是一个内存 I/O 密集型工作负载。随着 TP 度的增加,推理延迟显著降低,我们的结果显示,TP 度从 2 增加到 24,整体速度提高了约 4 倍。对于 Llama-2 7B 模型,延迟从 2 个核心的 30.1 毫秒/token 降低到 24 个核心的 7.9 毫秒/token;类似地,对于 Llama-2 13B 模型,它从 57.3 毫秒/token 降低到 11.1 毫秒/token。
并行上下文编码
在 Transformer 架构中,token 以称为自回归采样(autoregressive sampling)的顺序过程生成,而输入提示 token 可以通过并行上下文编码并行处理。这可以显著减少在通过自回归采样生成 token 之前输入提示上下文编码的延迟。默认情况下,参数 context_length_estimate 将设置为一系列 2 的幂次方数字,旨在涵盖各种上下文长度。根据用例,它可以设置为自定义数字。这可以在使用 LlamaForSampling.from_pretrained 创建 Llama 2 模型时完成。我们描述了输入 token 长度对端到端 (E2E) 延迟的影响。如图所示,得益于并行上下文编码,Llama-2 7B 模型的文本生成延迟仅随更大输入提示而略有增加。

KV 缓存
自注意力块使用 KV 向量执行自注意力操作。KV 向量是使用 token 嵌入和 KV 权重计算的,因此与 token 相关联。在朴素实现中,对于每个生成的 token,都会重新计算整个 KV 缓存,但这会降低性能。因此,Transformers Neuron 库会重复使用先前计算的 KV 向量,以避免不必要的计算,这被称为 KV 缓存,以减少自回归采样阶段的延迟。
基准测试结果
我们对 Llama-2 7B 和 13B 模型在不同条件下(即输出 token 数量、实例类型)的延迟和成本进行了基准测试。除非另有说明,我们使用数据类型 'bf16' 和批处理大小 1,因为这是实时应用(如聊天机器人和代码助手)的常见配置。
延迟
以下图表显示了在 inf2.48xlarge 实例上使用 TP 度为 24 的每个 token 延迟。这里,每个输出 token 的延迟计算为端到端延迟除以输出 token 的数量。我们的实验表明,Llama-2 7B 生成 256 个 token 的端到端延迟比其他可比较的推理优化型 EC2 实例快 2 倍。

吞吐量
现在我们展示 inf2.48xlarge 实例可以为 Llama-2 7B 和 13B 模型每秒生成的 token 数量。在 TP 度为 24 的情况下,充分利用所有 24 个 NeuronCore,Llama-2 7B 和 13B 模型分别可以达到 130 token/秒和 90 token/秒。

成本
对于延迟优先的应用程序,我们展示了在 inf2.48xlarge 实例上托管 Llama-2 模型的成本,7B 和 13B 模型每 1000 个 token 的成本分别为 $0.011 和 $0.016,比其他可比较的推理优化型 EC2 实例节省了 3 倍的成本。请注意,我们报告的成本基于 3 年预留实例价格,这是客户用于大型生产部署的价格。
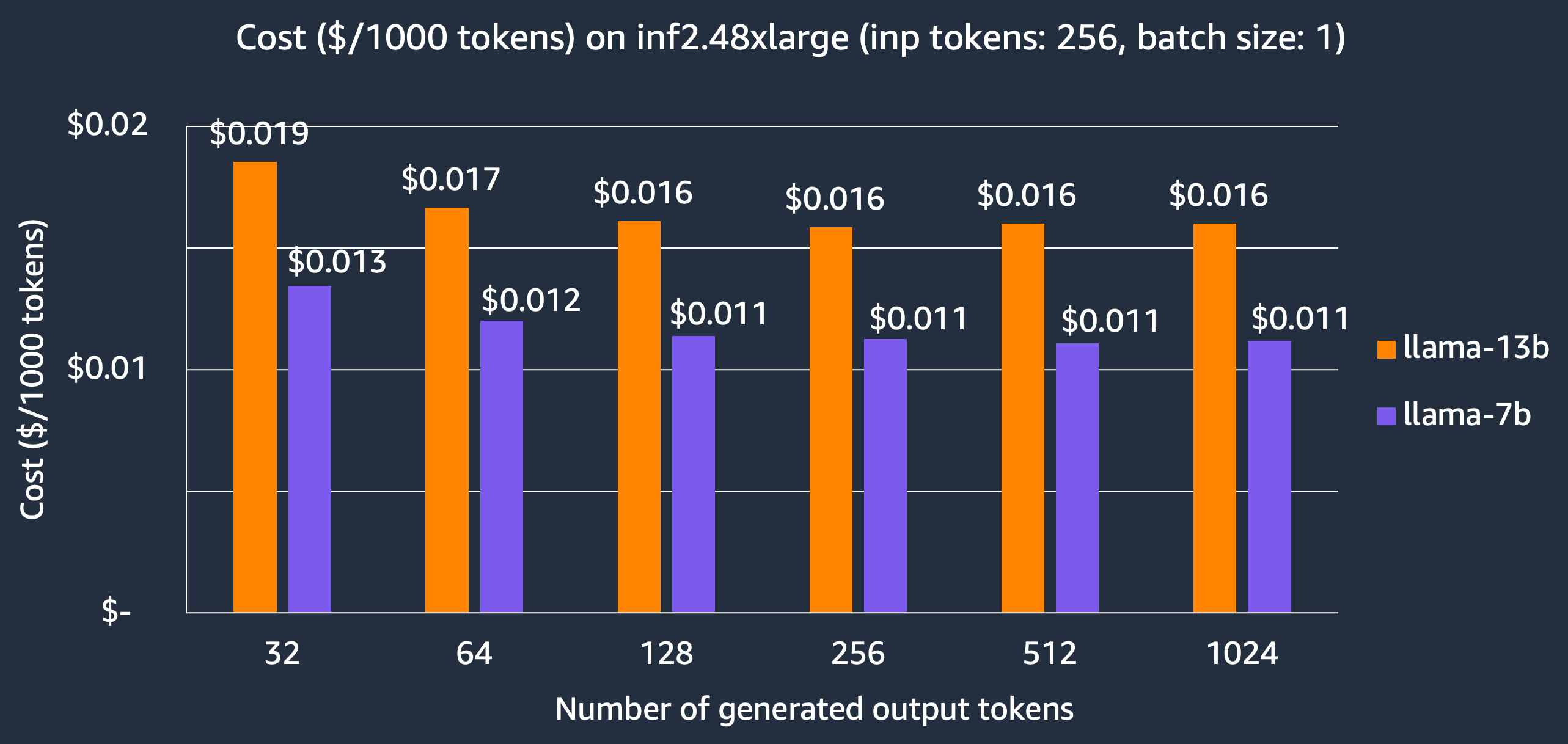
我们还比较了在 inf2.xlarge 和 inf2.48xlarge 实例上托管 Llama-2 7B 模型的成本。我们可以看到 inf2.xlarge 比 inf2.48xlarge 便宜 4 倍以上,但代价是由于 TP 度较小而导致延迟更长。例如,在 inf2.48xlarge 上模型生成 256 个输出 token(输入 256 个 token)需要 7.9 毫秒,而在 Inf2.xlarge 上需要 30.1 毫秒。

使用 TorchServe 在 EC2 Inf2 实例上提供 Llama2
现在,我们转向模型部署。在本节中,我们将向您展示如何通过 SageMaker 使用 TorchServe 部署 Llama-2 13B 模型。TorchServe 是 PyTorch 推荐的模型服务器,预装在 AWS PyTorch 深度学习容器 (DLC) 中。
本节描述了使用 TorchServe 所需的准备工作,特别是如何配置 model_config.yaml 和 inf2_handler.py,以及如何生成模型工件和预编译模型以用于后续模型部署。提前准备模型工件可以避免模型部署期间的模型编译,从而缩短模型加载时间。
模型配置 model-config.yaml
handler 和 micro_batching 部分中定义的参数用于自定义处理程序 inf2_handler.py。有关 model_config.yaml 的更多详细信息,请参见 此处。TorchServe 微批处理是一种并行预处理和后处理批量推理请求的机制。当后端稳定接收传入数据时,通过更好地利用可用加速器,它可以实现更高的吞吐量,更多详细信息请参见 此处。对于 Inf2 上的模型推理,micro_batch_size、amp、tp_degree 和 max_length 分别指定批处理大小、数据类型、张量并行度以及最大序列长度。
# TorchServe Frontend Parameters
minWorkers: 1
maxWorkers: 1
maxBatchDelay: 100
responseTimeout: 10800
batchSize: 16
# TorchServe Backend Custom Handler Parameters
handler:
model_checkpoint_dir: "llama-2-13b-split"
amp: "bf16"
tp_degree: 12
max_length: 100
micro_batching:
# Used by batch_size in function LlamaForSampling.from_pretrained
micro_batch_size: 1
parallelism:
preprocess: 2
inference: 1
postprocess: 2
自定义处理程序 inf2_handler.py
Torchserve 中的自定义处理程序是一个简单的 Python 脚本,可让您将模型初始化、预处理、推理和后处理逻辑定义为函数。在这里,我们创建了 Inf2 自定义处理程序。
- initialize 函数用于加载模型。在这里,Neuron SDK 将首次编译模型,并将预编译的模型保存在由
NEURONX_CACHE启用并在NEURONX_DUMP_TO中指定的目录中。第一次之后,后续运行将检查是否已经有预编译的模型工件。如果是,它将跳过模型编译。一旦模型加载完成,我们便会启动预热推理请求,以便缓存编译版本。当使用 neuron 持久缓存时,它可以显著减少模型加载延迟,确保后续推理运行迅速。
os.environ["NEURONX_CACHE"] = "on"
os.environ["NEURONX_DUMP_TO"] = f"{model_dir}/neuron_cache"
TorchServe `TextIteratorStreamerBatch` 扩展了 Hugging Face transformers `BaseStreamer`,以支持当 `batchSize` 大于 1 时的响应流。
self.output_streamer = TextIteratorStreamerBatch(
self.tokenizer,
batch_size=self.handle.micro_batch_size,
skip_special_tokens=True,
)
- 推理函数调用
send_intermediate_predict_response以发送流式响应。
for new_text in self.output_streamer:
logger.debug("send response stream")
send_intermediate_predict_response(
new_text[: len(micro_batch_req_id_map)],
micro_batch_req_id_map,
"Intermediate Prediction success",
200,
self.context,
)
打包模型工件
使用 torch-model-archiver 将所有模型工件打包到一个名为 llama-2-13b-neuronx-b1 的文件夹中。
torch-model-archiver --model-name llama-2-13b-neuronx-b1 --version 1.0 --handler inf2_handler.py -r requirements.txt --config-file model-config.yaml --archive-format no-archive
服务模型
export TS_INSTALL_PY_DEP_PER_MODEL="true"
torchserve --ncs --start --model-store model_store --models llama-2-13b-neuronx-b1
一旦日志显示“WORKER_MODEL_LOADED”,预编译模型应保存在 llama-2-13b-neuronx-b1/neuron_cache 文件夹中,该文件夹与 Neuron SDK 版本紧密相关。然后,将 llama-2-13b-neuronx-b1 文件夹上传到您的 S3 存储桶,以供产品部署中使用。本博客中 Llama-2 13B 模型的工件可在 此处 找到,该工件与 TorchServe 模型库中的 Neuron SDK 2.13.2 相关联。
使用 TorchServe 在 SageMaker Inf2 实例上部署 Llama-2 13B 模型
在本节中,我们使用 PyTorch Neuronx 容器在 SageMaker 端点上部署 Llama-2 13B 模型,该端点使用 ml.inf2.24xlarge 托管实例,该实例具有 6 个 Inferentia2 加速器,与我们的模型配置 model_config.yaml 处理程序设置 tp_degree: 12 对应。鉴于我们已使用 torch-model-archiver 将所有模型工件打包到一个文件夹中并上传到 S3 存储桶,我们现在将使用 SageMaker Python SDK 创建一个 SageMaker 模型,并使用 部署未压缩模型方法将其部署到 SageMaker 实时端点。以这种方式使用 SageMaker 部署的关键优势是速度,您可以获得一个功能齐全的生产就绪端点,其中包含安全的 RESTful 端点,而无需在基础设施上花费任何精力。在 SageMaker 上部署模型和运行推理有 3 个步骤。笔记本示例可以在 这里 找到。
- 创建一个 SageMaker 模型
from datetime import datetime
instance_type = "ml.inf2.24xlarge"
endpoint_name = sagemaker.utils.name_from_base("ts-inf2-llama2-13b-b1")
model = Model(
name="torchserve-inf2-llama2-13b" + datetime.now().strftime("%Y-%m-%d-%H-%M-%S"),
# Enable SageMaker uncompressed model artifacts
model_data={
"S3DataSource": {
"S3Uri": s3_uri,
"S3DataType": "S3Prefix",
"CompressionType": "None",
}
},
image_uri=container,
role=role,
sagemaker_session=sess,
env={"TS_INSTALL_PY_DEP_PER_MODEL": "true"},
)
- 部署 SageMaker 模型
model.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
volume_size=512, # increase the size to store large model
model_data_download_timeout=3600, # increase the timeout to download large model
container_startup_health_check_timeout=600, # increase the timeout to load large model
)
- 在 SageMaker 上运行流式响应推理 当端点处于服务中时,您可以使用
invoke_endpoint_with_response_streamAPI 调用来调用模型。此功能可以将每个生成的 token 返回给用户,从而增强用户体验。当生成整个序列非常耗时时,此功能尤其有用。
import json
body = "Today the weather is really nice and I am planning on".encode('utf-8')
resp = smr.invoke_endpoint_with_response_stream(EndpointName=endpoint_name, Body=body, ContentType="application/json")
event_stream = resp['Body']
parser = Parser()
for event in event_stream:
parser.write(event['PayloadPart']['Bytes'])
for line in parser.scan_lines():
print(line.decode("utf-8"), end=' ')
推理示例:
输入
“今天天气真好,我正计划”
输出
“今天天气真好,我正计划去海滩。我打算带上我的相机,拍一些海滩的照片。我将拍摄沙滩、海水和人群的照片。我还将拍摄日落的照片。我真的很高兴能去海滩拍照。
海滩是一个拍照的好地方。沙滩、海水和人群都是很棒的拍摄对象。日落也是一个很棒的拍摄对象。”
结论
在这篇文章中,我们展示了如何使用 Transformers Neuron 运行 Llama 2 模型推理,以及如何通过 Amazon SageMaker 在 EC2 Inf2 实例上使用 TorchServe 部署 Llama 2 模型服务。我们展示了使用 Inferentia2 的优势——低延迟和低成本——这得益于 AWS Neuron SDK 中的优化,包括张量并行、并行上下文编码和 KV 缓存,尤其适用于 LLM 推理。要了解最新信息,请关注 AWS Neuron 的最新版本以获取新功能。
立即开始使用 EC2 和 SageMaker 上的 Llama 2 示例,并敬请期待如何在 Inf2 上优化 Llama 70B!