我们很高兴地宣布,在 PyTorch 的原生低精度库 TorchAO 中,我们为 Arm CPU 添加了带低位权重(1-8 位)的嵌入运算符,以及带 8 位动态量化激活和低位权重(1-8 位)的线性运算符。这些运算符可以在所有 PyTorch 界面(包括 eager、torch.compile、AOTI 和 ExecuTorch)上无缝运行,并且可以在 torchchat 中使用。
在开发这些线性运算符时,我们关注的是 PyTorch 和 ExecuTorch 之间的代码共享,并建立了高级运算符和低级内核之间的清晰界限。这种设计 允许第三方供应商轻松替换自己的内核。我们还着手 创建一个实验新 CPU 量化想法并将其在 PyTorch 生态系统中进行测试的场所和基础设施。
通用低位内核
硬件不支持低位算术。在我们称为通用内核的方法中,我们以模块化的方式明确地将低位值解包为 int8 值的逻辑与 int8 GEMV 内核逻辑分离开来。我们从 8 位内核开始,例如,这个 1x8 8 位 GEMV 内核 使用 Arm neondot 指令。在 8 位内核中,我们调用一个 内联解包例程 将低位值转换为 int8 值。此解包例程是强制内联的,并基于某些低位值进行模板化。我们的实验表明,使用单独的强制内联解包例程与直接嵌入内联解包代码之间没有性能差异。
这种模块化设计的优势在于提高了开发速度和代码可维护性。在编写了一个 8 位内核之后,我们通过编写 简单的位打包例程 快速实现了完整的低位覆盖。事实上,从事位打包例程开发的开发人员不需要成为 GEMV/GEMM 内核编写专家。我们还重用了线性内核中的相同位打包例程 在嵌入内核中。将来,我们可以将相同的位打包例程重用于通用 GEMM 内核或基于 fma 或 i8mm 指令的内核。
PyTorch 和 ExecuTorch 之间的共享代码
为了实现 PyTorch 和 ExecuTorch 之间的代码共享,我们 使用原始指针而不是 PyTorch 张量 编写了内核。此外,我们 在一个头文件中实现了线性运算符,该头文件包含在单独的 PyTorch 和 ExecuTorch 运算符注册代码中。通过仅使用 ATen 和 ExecuTorch 张量共有的特性,我们确保了两个框架之间的兼容性。对于多线程计算,我们引入了 torchao::parallel_1d,它根据编译时标志编译为 at::parallel_for 或 ExecuTorch 的线程池。
可替换内核
我们针对高级多线程线性运算符的设计与低级单线程内核无关,允许第三方供应商替换自己的实现。运算符和内核之间的接口由 ukernel 配置 定义,该配置指定了用于准备激活数据、准备权重数据和运行内核的内核函数指针。负责平铺和调度的运算符仅通过此配置与内核交互。
性能
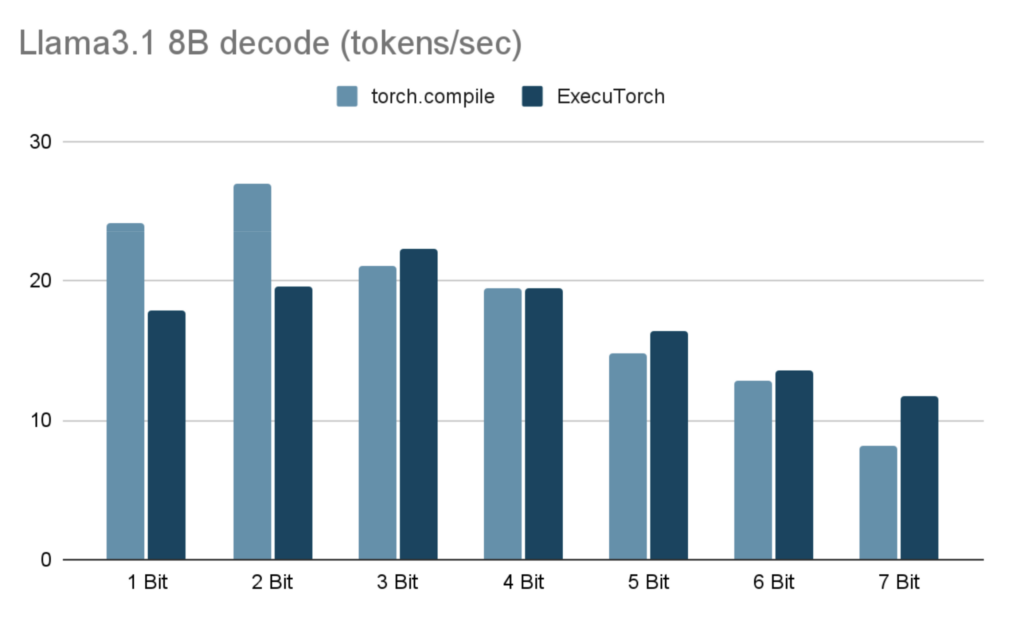
下表显示了在 M1 Macbook Pro(32GB 内存)上使用 6 个 CPU 线程时,Llama3.1 8B 令牌生成性能。
| 位宽 x | torch.compile (解码令牌/秒) | ExecuTorch (解码令牌/秒) | ExecuTorch PTE 大小 (GiB) |
| 1 | 24.18 | 17.86 | 1.46 |
| 2 | 27.02 | 19.65 | 2.46 |
| 3 | 21.01 | 22.25 | 3.46 |
| 4 | 19.51 | 19.47 | 4.47 |
| 5 | 14.78 | 16.34 | 5.47 |
| 6 | 12.80 | 13.61 | 6.47 |
| 7 | 8.16 | 11.73 | 7.48 |
结果在 M1 Macbook Pro(8 个性能核心和 2 个效率核心)上使用 32GB 内存和 6 个线程 通过 torchchat 运行。在每个测试中,生成了最大序列长度为 128 个令牌。对于每个位宽 x,嵌入层以组大小为 32 进行 x 位组量化。在线性层中,激活按令牌动态量化为 8 位,权重以组大小为 256 进行 x 位组量化。我们此处关注性能,不报告准确度或困惑度数字。根据模型,较低的位宽可能需要量化感知训练、使用混合位宽量化模型或调整组大小以获得可接受的准确度。
尝试并贡献!
如果您想看到新的低位内核实际运行,请通过 设置 torchchat 并 使用内核在本地量化和运行 LLM 来尝试它们。
如果您想提供帮助,请考虑添加对以下领域之一的支持
- 为 Arm CPU 添加通用低位 GEMM 内核,重用通用 GEMV 内核中的相同位打包例程。
- 根据 ISA、打包格式和激活形状改进 ukernel 配置的运行时选择。
- 为其他 CPU ISA(如 x86)添加低位内核。
- 将 KleidiAI 等第三方库与运算符框架集成。