本博客是关于使用纯原生 PyTorch 加速生成式 AI 模型系列文章中的第五篇。我们将演示在英特尔®至强®处理器上,GPTFast、Segment Anything Fast 和 Diffusion Fast 的 GenAI 加速效果。
首先,我们回顾一下 GPTFast,这是一项了不起的工作,它在不到 1000 行原生 PyTorch 代码中加快了文本生成速度。最初,GPTFast 仅支持 CUDA 后端。我们将向您展示如何在 CPU 上运行 GPTFast,并通过仅权重量化 (WOQ) 实现额外的性能加速。
在 Segment Anything Fast 中,我们加入了对 CPU 后端的支持,并将通过利用 BFloat16、torch.compile 和带有块级注意力掩码的 scaled_dot_product_attention (SDPA) 提升 CPU 性能来展示加速效果。与 FP32 相比,vit_b 中的加速比可达 2.91 倍,vit_h 中可达 3.95 倍。
最后,Diffusion Fast 现在支持 CPU 后端,并通过利用 BFloat16、torch.compile 和 SDPA 提升 CPU 性能。我们还优化了 Inductor CPU 中卷积、拼接和置换的布局传播规则,以提高性能。与 FP32 相比,在 Stable Diffusion XL (SDXL) 中,加速比可达 3.91 倍。
在 PyTorch CPU 上提升性能的优化策略
GPTFast
在过去一年中,生成式 AI 在各种语言任务中取得了巨大成功,并变得越来越受欢迎。然而,由于自回归解码过程中的内存带宽瓶颈,生成模型面临高昂的推理成本。为了解决这些问题,PyTorch 团队发布了 GPTFast,旨在仅使用纯原生 PyTorch 加速文本生成。该项目从头开始开发了一个 LLM,其速度几乎比基线快 10 倍,并且代码行数不到 1000 行。最初,GPTFast 仅支持 CUDA 后端,并在大约四个月内获得了大约 5000 颗星。受 Llama.cpp 的启发,英特尔团队从 PyTorch 2.4 版本开始提供了 CPU 后端支持,进一步增强了该项目在无 GPU 环境中的可用性。以下是用于提升 PyTorch CPU 性能的优化策略
- Torch.compiletorch.compile 是 PyTorch 2.0 以来引入的 PyTorch 函数,旨在解决 PyTorch 中准确图形捕获的问题,并最终使软件工程师能够更快地运行他们的 PyTorch 程序。
- 仅权重量子化仅权重量子化 (WOQ) 是性能和精度之间的一种权衡,因为文本生成中自回归解码阶段的瓶颈是加载权重的内存带宽,并且通常与传统的量化方法(如 W8A8)相比,WOQ 可以带来更好的精度。GPTFast 支持两种类型的 WOQ:W8A16 和 W4A16。具体来说,激活以 BFloat16 存储,模型权重可以量化为 int8 和 int4,如图 1 所示。
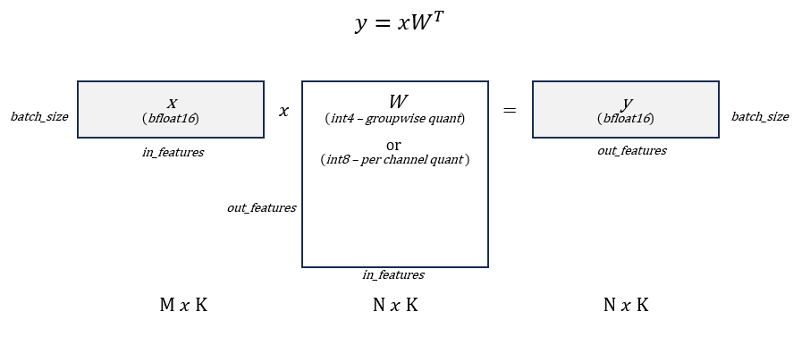
图 1. 仅权重量子化模式。来源:英特尔 马明飞
- 权重预打包与微内核设计。为了最大化吞吐量,GPTFast 允许使用内部 PyTorch ATen API 将模型权重预打包成 int4 上的硬件特定布局。受 Llama.cpp 启发,我们将模型权重从 [N, K] 预打包到 [N/kNTileSize, K, kNTileSize/2],其中 kNTileSize 在 avx512 上设置为 64。首先,模型权重沿 N 维度分块,然后转置两个最内层维度。为了最小化内核计算中的反量化开销,我们以交错模式打乱同一行中的 64 个数据元素,将 Lane2 和 Lane0 打包在一起,Lane3 和 Lane1 打包在一起,如图 2 所示。
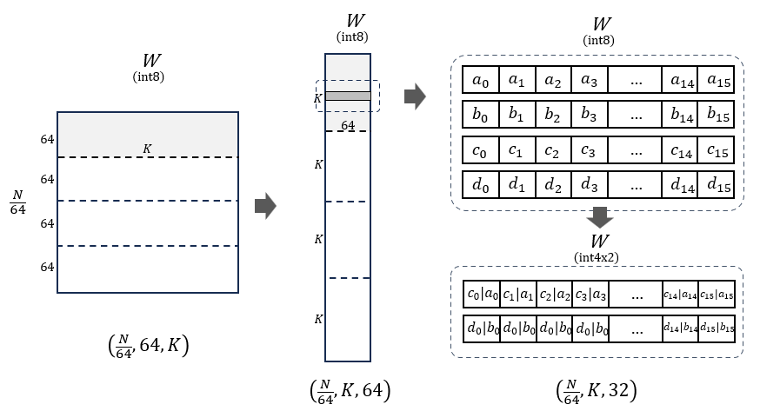
图 2. Int4 上的权重预打包。来源:英特尔 马明飞
在生成阶段,torch.nn.Linear 模块将被降级为使用 PyTorch ATen 内部的高性能内核进行计算,其中量化权重将首先被反量化,然后与寄存器级的融合乘加 (FMA) 累加,如图 3 所示。
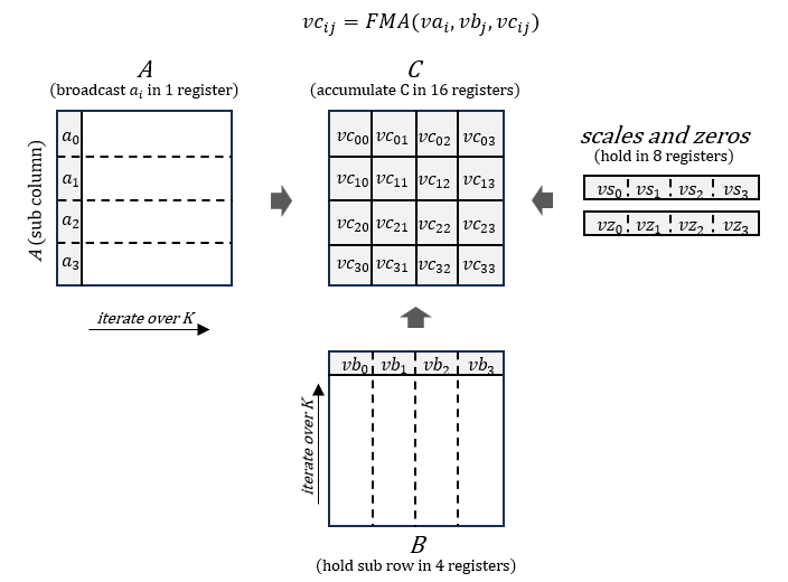
图 3. 微内核设计。来源:英特尔 马明飞
Segment Anything Fast
Segment Anything Fast 为 Segment Anything Model (SAM) 提供了一种简单高效的 PyTorch 原生加速,SAM 是一种用于生成可提示图像掩码的零样本视觉模型。以下是用于提升 PyTorch CPU 性能的优化策略
- BFloat16Bfloat16 是一种常用的半精度类型。通过降低每个参数和激活的精度,我们可以显着节省计算时间和内存。
- Torch.compiletorch.compile 是 PyTorch 2.0 以来引入的 PyTorch 函数,旨在解决 PyTorch 中准确图形捕获的问题,并最终使开发人员能够更快地运行他们的 PyTorch 程序。
- Scaled Dot Product Attention (SDPA)Scaled Dot-Product Attention (SDPA) 是 Transformer 模型中的关键机制。PyTorch 提供了一种融合实现,其性能显著优于朴素方法。对于 Segment Anything Fast,我们以块级方式将注意力掩码从 bfloat16 转换为 float32。这种方法不仅降低了峰值内存使用量,使其成为内存资源有限的系统的理想选择,而且还提高了性能。
Diffusion Fast
Diffusion Fast 为文本到图像扩散模型提供了简单高效的 PyTorch 原生加速。以下是用于提升 PyTorch CPU 性能的优化策略
- BFloat16Bfloat16 是一种常用的半精度类型。通过降低每个参数和激活的精度,我们可以显着节省计算时间和内存。
- Torch.compiletorch.compile 是 PyTorch 2.0 以来引入的 PyTorch 函数,旨在解决 PyTorch 中准确图形捕获的问题,并最终使软件工程师能够更快地运行他们的 PyTorch 程序。
- Scaled Dot Product Attention (SDPA)SDPA 是 Transformer 模型中使用的关键机制,PyTorch 提供了一种融合实现,与朴素实现相比,显示出巨大的性能优势。
在原生 PyTorch CPU 上使用模型
GPTFast
要在 GPTFast 中启动 WOQ,首先量化模型权重。例如,使用 int4 和组大小为 32 进行量化
python quantize.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --mode int4 –group size 32
然后通过将 int4 检查点传递给 generate.py 来运行生成。
python generate.py --checkpoint_path checkpoints/$MODEL_REPO/model_int4.g32.pth --compile --device $DEVICE
要在 GPTFast 中使用 CPU 后端,只需将 DEVICE 变量从 cuda 切换到 CPU。
Segment Anything Fast
cd experiments
export SEGMENT_ANYTHING_FAST_USE_FLASH_4=0
python run_experiments.py 16 vit_b <pytorch_github> <segment-anything_github> <path_to_experiments_data> --run-experiments --num-workers 32 --device cpu
python run_experiments.py 16 vit_h <pytorch_github> <segment-anything_github> <path_to_experiments_data> --run-experiments --num-workers 32 --device cpu
Diffusion Fast
python run_benchmark.py --compile_unet --compile_vae --device=cpu
性能评估
GPTFast
我们基于 测试分支 和上述硬件配置在 PyTorch 上运行了 llama-2-7b-chat 模型。在应用以下步骤后,我们看到与急切模式下的基线相比,性能提升了 3.8 倍。
- 使用
torch.compile自动融合逐元素运算符。 - 通过 WOQ-int8 减少内存占用。
- 通过 WOQ-int4 进一步减少内存占用。
- 使用 AVX512,可在微内核中实现更快的反量化。
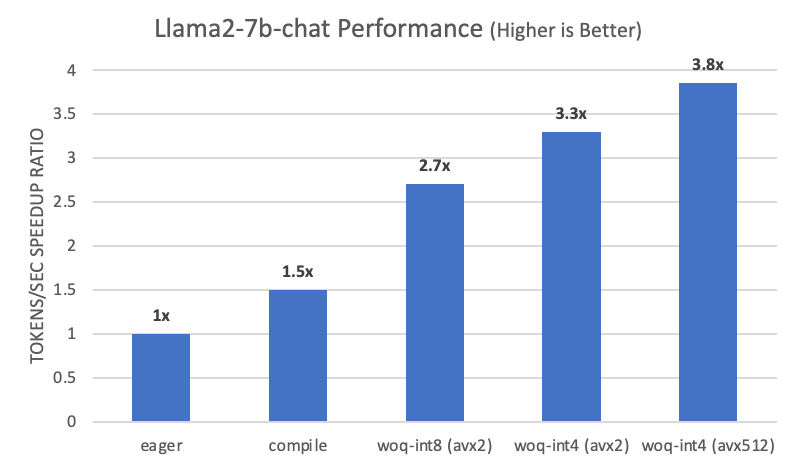
图 4. Llama2-7b-chat 中 GPTFast 的性能加速
Segment Anything Fast
我们在上述硬件配置下,在 PyTorch 上运行了 Segment Anything Fast,并实现了 BFloat16 与 torch.compile 和 SDPA 相比 FP32 的性能加速,如图 5 所示。与 FP32 相比,vit_b 中的加速比可达 2.91 倍,vit_h 中的加速比可达 3.95 倍。
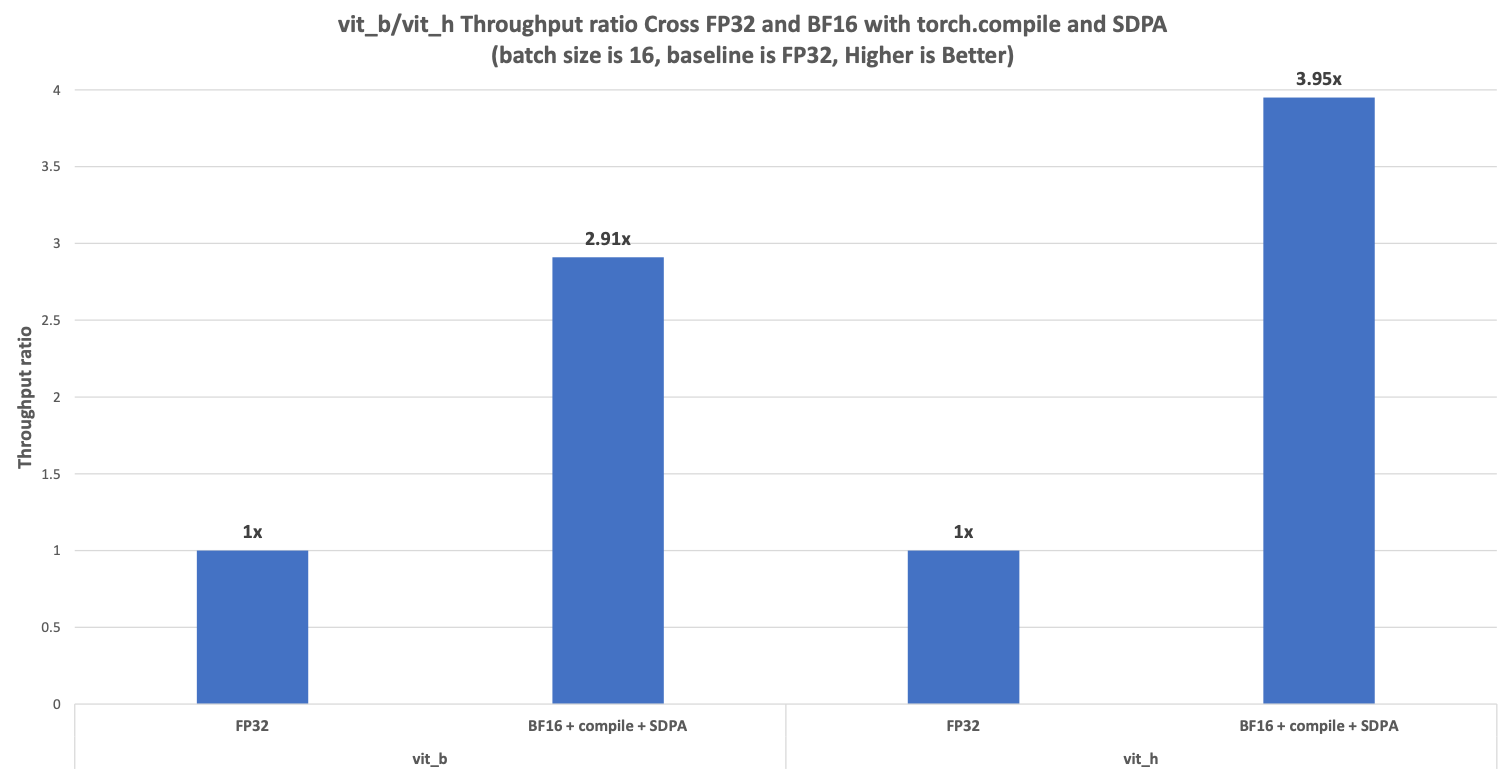
图 5. vit_b/vit_h 中 Segment Anything Fast 的性能加速
Diffusion Fast
我们在上述硬件配置下,在 PyTorch 上运行了 Diffusion Fast,并实现了 BFloat16 与 torch.compile 和 SDPA 相比 FP32 的性能加速,如图 6 所示。与 FP32 相比,在 Stable Diffusion XL (SDXL) 中,加速比可达 3.91 倍。
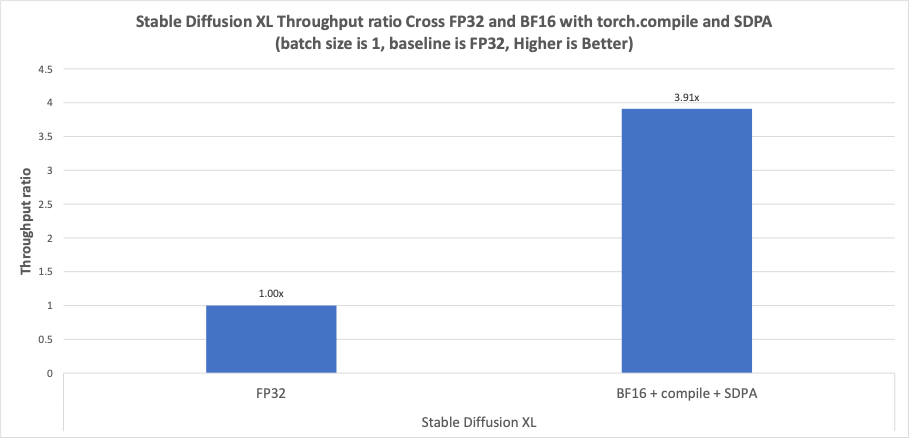
图 6. Stable Diffusion XL 中 Diffusion Fast 的性能加速
结论与未来工作
在本博客中,我们介绍了仅权重量子化、torch.compile 和 SDPA 的软件优化,展示了如何在 CPU 上使用原生 PyTorch 加速文本生成。随着对 AMX-BF16 指令集的支持以及使用 torchao 在 CPU 上优化动态 int8 量化,预计将有进一步的改进。我们将继续扩大软件优化工作的范围。
鸣谢
本博客中呈现的结果是 Meta 和英特尔 PyTorch 团队共同努力的成果。特别感谢 Meta 的 Michael Gschwind,他投入了宝贵的时间提供了大量帮助。我们共同在改进 PyTorch CPU 生态系统的道路上又迈出了一步。
相关博客
第一部分:如何使用 Segment Anything Fast 将 Segment Anything 加速 8 倍以上。
第二部分:如何借助 GPTFast 将 Llama-7B 加速近 10 倍。
第三部分:如何使用 Diffusion Fast 将 文本到图像扩散模型加速高达 3 倍。
第四部分:如何将 FAIR 的 Seamless M4T-v2 模型加速 2.7 倍。
产品和性能信息
图 4:英特尔至强可扩展处理器:使用第四代英特尔至强可扩展处理器进行测量:2x 英特尔(R) 至强(R) 白金 8480+,56 核,超线程开启,睿频开启,NUMA 2,集成加速器可用 [已使用]:DLB 2 [0],DSA 2 [0],IAA 2 [0],QAT 2 [0],总内存 512GB (16x32GB DDR5 4800 MT/s [4800 MT/s]),BIOS 3B07.TEL2P1,微代码 0x2b000590,三星 SSD 970 EVO Plus 2TB,CentOS Stream 9,5.14.0-437.el9.x86_64,运行单插槽(总共 1 个实例,每个实例 56 核,每个实例批处理大小 1),模型使用 PyTorch 2.5 wheel 运行。英特尔于 2024 年 10 月 15 日测试。
图 5:英特尔至强可扩展处理器:使用第四代英特尔至强可扩展处理器进行测量:2x 英特尔(R) 至强(R) 白金 8480+,56 核,超线程开启,睿频开启,NUMA 2,集成加速器可用 [已使用]:DLB 2 [0],DSA 2 [0],IAA 2 [0],QAT 2 [0],总内存 512GB (16x32GB DDR5 4800 MT/s [4800 MT/s]),BIOS 3B07.TEL2P1,微代码 0x2b000590,三星 SSD 970 EVO Plus 2TB,CentOS Stream 9,5.14.0-437.el9.x86_64,运行单插槽(总共 1 个实例,每个实例 56 核,每个实例批处理大小 16),模型使用 PyTorch 2.5 wheel 运行。英特尔于 2024 年 10 月 15 日测试。
图 6:英特尔至强可扩展处理器:使用第四代英特尔至强可扩展处理器进行测量:2x 英特尔(R) 至强(R) 白金 8480+,56 核,超线程开启,睿频开启,NUMA 2,集成加速器可用 [已使用]:DLB 2 [0],DSA 2 [0],IAA 2 [0],QAT 2 [0],总内存 512GB (16x32GB DDR5 4800 MT/s [4800 MT/s]),BIOS 3B07.TEL2P1,微代码 0x2b000590,三星 SSD 970 EVO Plus 2TB,CentOS Stream 9,5.14.0-437.el9.x86_64,运行单插槽(总共 1 个实例,每个实例 56 核,每个实例批处理大小 1),模型使用 PyTorch 2.5 wheel 运行。英特尔于 2024 年 10 月 15 日测试。
注意事项和免责声明
性能因使用、配置和其他因素而异。请访问性能指数网站了解更多信息。性能结果基于所示配置下的测试日期,可能无法反映所有公开发布的更新。 请参阅备份以获取配置详情。 没有任何产品或组件是绝对安全的。您的成本和结果可能有所不同。英特尔技术可能需要启用硬件、软件或服务激活。
英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能属于他人所有。
AI 免责声明
AI 功能可能需要购买软件、订阅或由软件或平台提供商启用,或者可能具有特定的配置或兼容性要求。详情请访问 www.intel.com/AIPC。结果可能有所不同。