引言
FX 基于特征提取是新的 TorchVision 实用工具,它允许我们在 PyTorch Module 的正向传播过程中访问输入的中间转换。它通过符号化跟踪正向方法来生成一个图,其中每个节点代表一个操作。节点的命名方式是人类可读的,这样用户就可以轻松指定他们想要访问的节点。
听起来有点复杂吗?不用担心,这篇文章适合所有人。无论你是初学者还是资深深度视觉从业者,你都可能想了解 FX 特征提取。如果你想了解更多关于特征提取的背景知识,请继续阅读。如果你已经熟悉这些并想知道如何在 PyTorch 中实现,请跳到 PyTorch 中的现有方法:优缺点。如果你已经了解在 PyTorch 中进行特征提取的挑战,请随意跳到 FX 救星。
特征提取回顾
我们都习惯了深度神经网络(DNN)接收输入并产生输出,我们不一定会考虑中间发生了什么。让我们以 ResNet-50 分类模型为例

图 1:ResNet-50 接收一张鸟的图像,并将其转换为抽象概念“鸟”。来源:来自 ImageNet 的鸟图像。
然而,我们知道 ResNet-50 架构中有许多顺序的“层”,它们一步步转换输入。在下面的图 2 中,我们深入探讨了 ResNet-50 中的层,并展示了输入通过这些层时的中间转换。

图 2:ResNet-50 分多步转换输入图像。从概念上讲,我们可以在这些步骤中的每一步之后访问图像的中间转换。来源:来自 ImageNet 的鸟图像。
PyTorch 中的现有方法:优缺点
在引入基于 FX 的特征提取之前,PyTorch 中已经存在一些进行特征提取的方法。
为了说明这些方法,让我们考虑一个执行以下操作的简单卷积神经网络
- 应用几个“块”,每个块中包含几个卷积层。
- 在几个块之后,它使用全局平均池化和展平操作。
- 最后,它使用一个输出分类层。
import torch
from torch import nn
class ConvBlock(nn.Module):
"""
Applies `num_layers` 3x3 convolutions each followed by ReLU then downsamples
via 2x2 max pool.
"""
def __init__(self, num_layers, in_channels, out_channels):
super().__init__()
self.convs = nn.ModuleList(
[nn.Sequential(
nn.Conv2d(in_channels if i==0 else out_channels, out_channels, 3, padding=1),
nn.ReLU()
)
for i in range(num_layers)]
)
self.downsample = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
for conv in self.convs:
x = conv(x)
x = self.downsample(x)
return x
class CNN(nn.Module):
"""
Applies several ConvBlocks each doubling the number of channels, and
halving the feature map size, before taking a global average and classifying.
"""
def __init__(self, in_channels, num_blocks, num_classes):
super().__init__()
first_channels = 64
self.blocks = nn.ModuleList(
[ConvBlock(
2 if i==0 else 3,
in_channels=(in_channels if i == 0 else first_channels*(2**(i-1))),
out_channels=first_channels*(2**i))
for i in range(num_blocks)]
)
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.cls = nn.Linear(first_channels*(2**(num_blocks-1)), num_classes)
def forward(self, x):
for block in self.blocks:
x = block(x)
x = self.global_pool(x)
x = x.flatten(1)
x = self.cls(x)
return x
model = CNN(3, 4, 10)
out = model(torch.zeros(1, 3, 32, 32)) # This will be the final logits over classes
假设我们想在全局平均池化之前获取最终的特征图。我们可以这样做
修改正向方法
def forward(self, x):
for block in self.blocks:
x = block(x)
self.final_feature_map = x
x = self.global_pool(x)
x = x.flatten(1)
x = self.cls(x)
return x
或者直接返回它
def forward(self, x):
for block in self.blocks:
x = block(x)
final_feature_map = x
x = self.global_pool(x)
x = x.flatten(1)
x = self.cls(x)
return x, final_feature_map
这看起来很容易。但这里有一些缺点,都源于同一个根本问题:修改源代码并不理想
- 考虑到项目的实际情况,访问和更改并不总是那么容易。
- 如果我们需要灵活性(开启或关闭特征提取,或有变体),我们需要进一步调整源代码来支持这一点。
- 这不总是仅仅插入一行代码的问题。考虑一下,如果我按照这种方式编写模块,你将如何从其中一个中间块中获取特征图。
- 总的来说,当实际上不需要改变模型的工作方式时,我们宁愿避免维护模型源代码的开销。
可以预见,当处理更大、更复杂的模型,并试图从嵌套子模块中获取特征时,这个缺点会变得更加棘手。
使用原始模块的参数编写新模块
接着上面的例子,假设我们想从每个块中获取一个特征图。我们可以这样编写一个新模块
class CNNFeatures(nn.Module):
def __init__(self, backbone):
super().__init__()
self.blocks = backbone.blocks
def forward(self, x):
feature_maps = []
for block in self.blocks:
x = block(x)
feature_maps.append(x)
return feature_maps
backbone = CNN(3, 4, 10)
model = CNNFeatures(backbone)
out = model(torch.zeros(1, 3, 32, 32)) # This is now a list of Tensors, each representing a feature map
事实上,这与 TorchVision 内部用于构建其许多检测模型的方法非常相似。
尽管这种方法解决了一些直接修改源代码的问题,但仍然存在一些主要缺点
- 真正直接访问顶层子模块的输出。处理嵌套子模块会迅速变得复杂。
- 我们必须小心,不要遗漏输入和输出之间的任何重要操作。我们将原始模块的精确功能转录到新模块时,可能会引入错误。
总的来说,这种方法和上一种方法都存在将特征提取与模型源代码本身联系起来的复杂性。事实上,如果我们检查 TorchVision 模型的源代码,我们可能会怀疑一些设计选择受到了希望以这种方式将其用于下游任务的影响。
使用钩子
钩子将我们从编写源代码的范式转向指定输出的范式。考虑到上面我们的玩具 CNN 示例,以及获取每个层特征图的目标,我们可以这样使用钩子
model = CNN(3, 4, 10)
feature_maps = [] # This will be a list of Tensors, each representing a feature map
def hook_feat_map(mod, inp, out):
feature_maps.append(out)
for block in model.blocks:
block.register_forward_hook(hook_feat_map)
out = model(torch.zeros(1, 3, 32, 32)) # This will be the final logits over classes
现在我们在访问嵌套子模块方面拥有完全的灵活性,并且摆脱了修改源代码的责任。但这种方法也有其缺点
- 我们只能将钩子应用于模块。如果我们需要输出的函数式操作(reshape、view、函数式非线性等),钩子将无法直接对其起作用。
- 我们没有修改源代码的任何内容,因此无论钩子如何,整个正向传播都会执行。如果只需要访问早期特征而不需要最终输出,这可能会导致大量无用的计算。
- 钩子不兼容 TorchScript。
以下是不同方法的优缺点总结
| 可以直接使用源代码,无需任何修改或重写 | 访问特征的完全灵活性 | 删除不必要的计算步骤 | TorchScript 兼容 | |
|---|---|---|---|---|
| 修改前向方法 | 否 | 理论上是。取决于你愿意编写多少代码。所以实际上,否。 | 是 | 是 |
| 重用原始模块的子模块/参数的新模块 | 否 | 理论上是。取决于你愿意编写多少代码。所以实际上,否。 | 是 | 是 |
| 钩子 | 是 | 大部分是。仅限于子模块的输出 | 否 | 否 |
表 1:PyTorch 现有特征提取方法的一些优点(或缺点)
在本文的下一节中,让我们看看如何实现全面“是”。
FX 救星
此时,对于一些 Python 和编程新手来说,自然会问:“我们不能直接指向一行代码,然后告诉 Python 或 PyTorch 我们想要那一行代码的结果吗?” 对于那些花更多时间编程的人来说,为什么不能这样做是清楚的:一行代码中可以发生多个操作,无论是显式编写在那里,还是作为子操作隐式存在。就以这个简单的模块为例
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.submodule = MySubModule()
def forward(self, x):
return self.submodule(x + self.param).clamp(min=0.0, max=1.0)
正向方法只有一行代码,我们可以将其展开为
- 将
self.param添加到x - 通过 self.submodule 传递 x。在这里,我们需要考虑在该子模块中发生的步骤。我将仅使用虚拟操作名称进行说明:I. submodule.op_1 II. submodule.op_2
- 应用 clamp 操作
因此,即使我们指向这一行,问题仍然是:“我们想提取哪一步的输出?”。
FX 是 PyTorch 的一个核心工具包,它(过于简化地说)执行我刚刚提到的展开操作。它执行一种称为“符号跟踪”的操作,这意味着 Python 代码被解释并一步一步地执行,使用一些虚拟代理作为真实输入。引入一些术语,上面描述的每个步骤都被视为一个“节点”,连续的节点相互连接形成一个“图”(与图的常见数学概念非常相似)。以下是将上述“步骤”转换为图的概念。
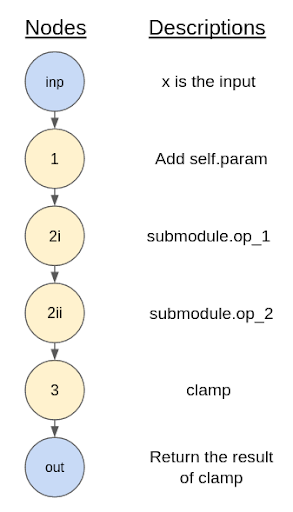
图 3:对我们简单正向方法示例进行符号跟踪结果的图形表示。
请注意,我们称之为图,而不仅仅是一组步骤,因为图可能会分支并重新组合。想想残差块中的跳跃连接。它看起来像这样
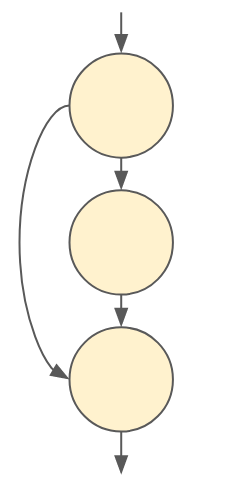
图 4:残差跳跃连接的图形表示。中间节点类似于残差块的主分支,最终节点表示主分支的输入和输出之和。
现在,TorchVision 的 get_graph_node_names 函数按照上述描述应用 FX,在此过程中,为每个节点标记一个人类可读的名称。让我们用上一节中的玩具 CNN 模型试试这个
model = CNN(3, 4, 10)
from torchvision.models.feature_extraction import get_graph_node_names
nodes, _ = get_graph_node_names(model)
print(nodes)
结果将是
['x', 'blocks.0.convs.0.0', 'blocks.0.convs.0.1', 'blocks.0.convs.1.0', 'blocks.0.convs.1.1', 'blocks.0.downsample', 'blocks.1.convs.0.0', 'blocks.1.convs.0.1', 'blocks.1.convs.1.0', 'blocks.1.convs.1.1', 'blocks.1.convs.2.0', 'blocks.1.convs.2.1', 'blocks.1.downsample', 'blocks.2.convs.0.0', 'blocks.2.convs.0.1', 'blocks.2.convs.1.0', 'blocks.2.convs.1.1', 'blocks.2.convs.2.0', 'blocks.2.convs.2.1', 'blocks.2.downsample', 'blocks.3.convs.0.0', 'blocks.3.convs.0.1', 'blocks.3.convs.1.0', 'blocks.3.convs.1.1', 'blocks.3.convs.2.0', 'blocks.3.convs.2.1', 'blocks.3.downsample', 'global_pool', 'flatten', 'cls']
我们可以将这些节点名称理解为感兴趣操作的分层组织“地址”。例如,“blocks.1.downsample”指的是第二个 ConvBlock 中的 MaxPool2d 层。
create_feature_extractor,所有神奇之处都发生在这里,它比 get_graph_node_names 走得更远。它将所需的节点名称作为输入参数之一,然后使用更多的 FX 核心功能来
- 将所需的节点指定为输出。
- 裁剪不必要的下游节点及其关联参数。
- 将生成的图转换回 Python 代码。
- 向用户返回另一个 PyTorch Module。该模块将步骤 3 中的 Python 代码作为正向方法。
作为演示,以下是如何应用 create_feature_extractor 从我们的玩具 CNN 模型中获取 4 个特征图
from torchvision.models.feature_extraction import create_feature_extractor
# Confused about the node specification here?
# We are allowed to provide truncated node names, and `create_feature_extractor`
# will choose the last node with that prefix.
feature_extractor = create_feature_extractor(
model, return_nodes=['blocks.0', 'blocks.1', 'blocks.2', 'blocks.3'])
# `out` will be a dict of Tensors, each representing a feature map
out = feature_extractor(torch.zeros(1, 3, 32, 32))
就是这么简单。归根结底,FX 特征提取只是一种方法,可以让我们实现我们中一些人刚开始编程时天真地希望做到的事情:“给我这段代码的输出(指着屏幕)”。
- … 不需要我们修改源代码。
- … 提供了完全的灵活性,可以访问输入的任何中间转换,无论是模块的结果还是函数式操作的结果
- … 一旦提取了特征,确实会删除不必要的计算步骤
- … 我之前没有提到,但它也兼容 TorchScript!
这是再次添加了 FX 特征提取行的表格
| 可以直接使用源代码,无需任何修改或重写 | 访问特征的完全灵活性 | 删除不必要的计算步骤 | TorchScript 兼容 | |
|---|---|---|---|---|
| 修改前向方法 | 否 | 理论上是。取决于你愿意编写多少代码。所以实际上,否。 | 是 | 是 |
| 重用原始模块的子模块/参数的新模块 | 否 | 理论上是。取决于你愿意编写多少代码。所以实际上,否。 | 是 | 是 |
| 钩子 | 是 | 大部分是。仅限于子模块的输出 | 否 | 否 |
| FX | 是 | 是 | 是 | 是 |
表 2:表 1 的副本,其中添加了一行 FX 特征提取。FX 特征提取全面获得了“是”!
当前 FX 限制
虽然我很想就此结束这篇文章,但 FX 确实有一些自身的限制,归结为
- 当涉及到解释和转换为图的步骤时,可能有一些 Python 代码尚未被 FX 处理。
- 动态控制流无法用静态图表示。
当这些问题出现时,最简单的做法是将底层代码打包成一个“叶子节点”。回想图 3 中的示例图?从概念上讲,我们可能认为 submodule 本身应该被视为一个节点,而不是一组代表底层操作的节点。如果我们这样做,我们可以将图重新绘制为
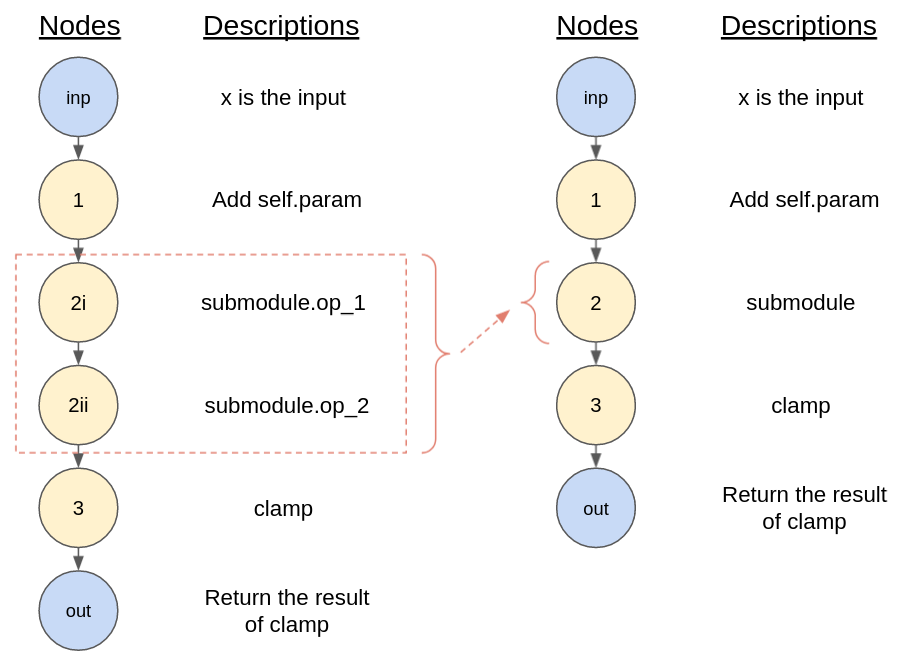
图 5:`submodule` 中的单个操作可能(左 - 红色框内)合并为一个节点(右 - 节点 #2),如果我们考虑将 `submodule` 作为“叶子”节点。
如果子模块中存在一些有问题代码,但我们不需要从中提取任何中间转换,我们就会这样做。实际上,通过向 create_feature_extractor 或 get_graph_node_names 提供关键字参数,这很容易实现。
model = CNN(3, 4, 10)
nodes, _ = get_graph_node_names(model, tracer_kwargs={'leaf_modules': [ConvBlock]})
print(nodes)
其输出将是
['x', 'blocks.0', 'blocks.1', 'blocks.2', 'blocks.3', 'global_pool', 'flatten', 'cls']
请注意,与之前相比,任何给定的 ConvBlock 的所有节点都被合并为一个节点。
我们可以对函数做类似的事情。例如,Python 的内置 len 需要被封装,并且结果应该被视为叶子节点。以下是使用核心 FX 功能实现的方法
torch.fx.wrap('len')
class MyModule(nn.Module):
def forward(self, x):
x += 1
len(x)
model = MyModule()
feature_extractor = create_feature_extractor(model, return_nodes=['add'])
对于您定义的函数,您可以改用 `create_feature_extractor` 的另一个关键字参数(小细节:为什么您可能想这样做)
def myfunc(x):
return len(x)
class MyModule(nn.Module):
def forward(self, x):
x += 1
myfunc(x)
model = MyModule()
feature_extractor = create_feature_extractor(
model, return_nodes=['add'], tracer_kwargs={'autowrap_functions': [myfunc]})
请注意,上述所有修复都不涉及修改源代码。
当然,有时您试图访问的中间转换位于导致问题的同一个正向方法或函数中。在这种情况下,我们不能仅仅将该模块或函数视为叶节点,因为那样我们就无法访问内部的中间转换。在这些情况下,需要对源代码进行一些重写。以下是一些示例(不详尽)
- FX 在尝试跟踪带有
assert语句的代码时会引发错误。在这种情况下,您可能需要删除该断言或将其替换为torch._assert(这不是公共函数 – 因此将其视为权宜之计,请谨慎使用)。 - 不支持对张量切片进行原地更改的符号跟踪。您需要为切片创建一个新变量,应用操作,然后使用连接或堆叠重建原始张量。
- 在静态图中表示动态控制流在逻辑上是不可能的。看看你是否能将编码逻辑提炼成非动态的东西——请参阅 FX 文档以获取提示。
通常,您可以查阅 FX 文档以获取有关符号跟踪限制和可能解决方案的更多详细信息。
结论
我们快速回顾了特征提取以及为什么可能需要进行特征提取。尽管 PyTorch 中存在用于特征提取的现有方法,但它们都存在相当大的缺点。我们学习了 TorchVision 的 FX 特征提取实用工具如何工作,以及与现有方法相比,它为何如此多功能。虽然后者仍有一些小问题需要解决,但我们了解其局限性,并可以根据我们的用例权衡与其他方法的局限性。希望通过将这个新实用工具添加到您的 PyTorch 工具包中,您现在能够处理绝大多数可能遇到的特征提取需求。
编程愉快!