概述
在 PyTorch 2.5.0 版本中,我们引入了 FlexAttention torch.nn.attention.flex_attention,供希望自定义注意力内核而无需编写内核代码的机器学习研究人员使用。本博客介绍了我们针对推理优化的解码后端,支持 GQA 和 PagedAttention,以及包括性能调优指南和可训练偏置支持在内的功能更新。
如果您正在寻找一种在训练后/推理管道中轻松试用 FlexAttention 的方法,PyTorch 原生训练后库 torchtune 和推理代码库 gpt-fast 已经集成了 FlexAttention。快来试试吧!
我们很高兴地宣布,我们关于 FlexAttention 的论文已被 MLSys2025 会议接受,该会议将于 5 月 12 日至 15 日在加利福尼亚州圣克拉拉举行。
标题: FlexAttention:一种用于生成优化注意力内核的编程模型。 海报
用于推理的 FlexAttention
TL;DR:torch.compile 在查询序列很短时会将 flex_attention 降级为融合的 FlashDecoding 内核。
一个融合的注意力内核并不适用于所有情况——尤其是在长上下文 LLM 推理中。
LLM 推理的解码阶段是一个迭代过程:逐个生成 token,需要 N 次前向传递才能生成一个 N-token 的句子。幸运的是,每次迭代都不需要重新计算整个句子的自注意力——之前计算的 token 会被缓存,因此我们只需要将新生成的 token 与缓存的上下文进行注意力计算。
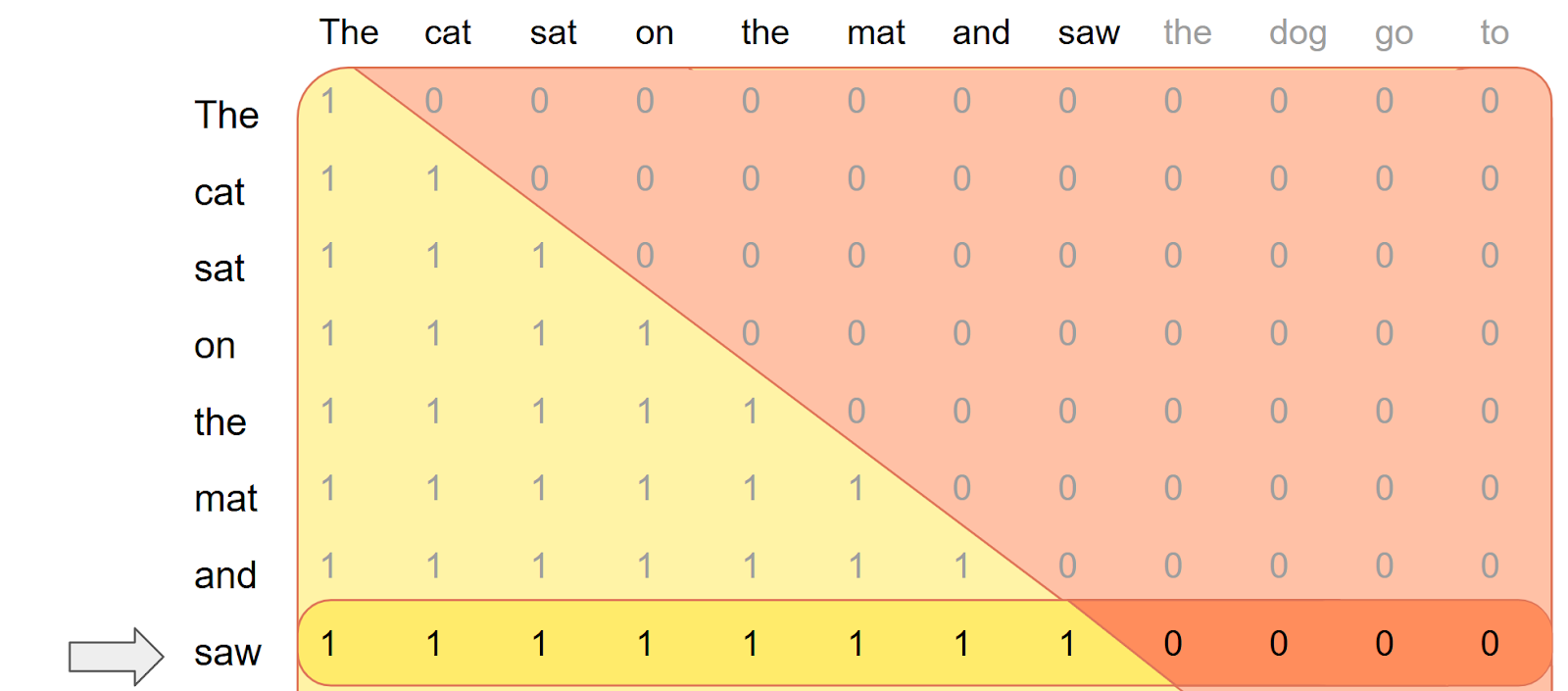
这导致了一种独特的注意力模式,即短查询序列(1 个 token)关注长键值缓存(上下文长度可达 128k)。传统的方形注意力内核优化(q_len ≈ kv_len)在这里并不直接适用。这种模式对 GPU 内存利用率和占用率提出了新的挑战。我们构建了一个专用的 FlexDecoding 后端,针对长上下文 LLM 推理进行了优化,并结合了 FlashDecoding 中的解码专用技术。
FlexDecoding 作为 torch.nn.attention.flex_attention 操作符的替代后端实现。flex_attention 在给定短查询和长 KV 缓存时,会自动切换到 FlexDecoding 后端进行 JIT 编译。如果输入形状发生显著变化,例如从预填充阶段过渡到解码阶段,JIT 重新编译会为每种情况生成一个单独的内核。
flex_attention = torch.compile(flex_attention)
k_cache = torch.random(B, H, 16384, D)
v_cache = torch.random(B, H, 16384, D)
...
# Prefill Phase: query shape = [B, H, 8000, D]
flex_attention(q_prefill, k_cache, v_cache, ...) # Uses FlexAttention backend optimized for prefill & training
# Decoding Phase: q_last_token shape = [B, H, 1, D]
flex_attention(q_last_token , k_cache, v_cache, ...) # Recompiles with the FlexDecoding backend
# decode 2 tokens at the same time: q_last_2_tokens shape = [B, H, 2, D]
flex_attention(q_last_2_tokens, k_cache, v_cache, ...) # No recompilation needed! Runs the decoding kernel again.
使用 KV 缓存
实现高效推理的关键优化之一是维护一个预分配的 KV 缓存,该缓存会随着新 token 的生成而**原地**更新。FlexDecoding 不会通过专用 API 强制执行特定的 KV 缓存策略,而是允许用户自行定义和管理 KV 缓存。
与 FlexAttention 类似,FlexDecoding 接受用户定义的 mask_mod 和 score_mod 函数。这些函数在 softmax 操作之前修改注意力分数。
 score_mod(score, b, h, q_idx, kv_idx) -> tensor # return updated score
score_mod(score, b, h, q_idx, kv_idx) -> tensor # return updated score
分数是一个表示查询 token 和键 token 点积的标量 pytorch 张量。其余参数指定正在计算哪个分数
b批次索引h注意力头索引q_idx查询张量中的 token 位置kv_idx键/值张量中的 token 位置
在解码阶段,先前计算的 token 会被缓存,并且只有最新生成的 token(第 i 个)用作查询。此单 token 查询上的简单因果掩码如下所示
def causal(score, b, h, q_idx, kv_idx):
return torch.where(q_idx >= kv_idx, score, -float("inf"))
 这有问题:新 token “saw” 应该关注所有先前生成的 token,即 “The cat sat on the mat and saw”,而不仅仅是 kv 缓存中的第一个条目。为了纠正这一点,
这有问题:新 token “saw” 应该关注所有先前生成的 token,即 “The cat sat on the mat and saw”,而不仅仅是 kv 缓存中的第一个条目。为了纠正这一点,score_mod 需要**将 q_idx 偏移** i 以实现准确解码。
 为每个 token 创建一个新的
为每个 token 创建一个新的 score_mod 以适应偏移量是很慢的,因为它意味着 FlexAttention 需要为不同的 score_mod 每次迭代都重新编译。相反,
我们将此 offset 定义为一个张量,并在每次迭代时递增其值
offset = torch.tensor(i, "cuda")
def causal_w_offset(score, b, h, q_idx, kv_idx):
return torch.where(q_idx + offset >= kv_idx, score, -float("inf"))
# Attend the i-th token
flex_attention(..., score_mod=causal_w_offset ) # Compiles the kernel here
...
# Attend the i+1-th token
offset = offset + 1 # Increment offset
flex_attention(..., score_mod=causal_w_offset ) # Doesn't need to recompile!
值得注意的是,这里的 offset 变成了一个捕获的张量,如果 offset 值改变,它不需要重新编译。
手动重写 score_mod 和 mask_mod 以处理偏移量是不必要的。我们可以使用通用重写器自动完成此过程
offset = torch.tensor(i, "cuda")
def get_score_mod_w_offset(score_mod: _score_mod_signature, _offset: tensor):
def _score_mod(score, b, h, q, kv):
return score_mod(score, b, h, q + _offset, kv)
return _score_mod
def get_mask_mod_w_offset(mask_mod: _mask_mod_signature, _offset: tensor):
def _mask_mod(b, h, q, kv):
return mask_mod(b, h, q + _offset, kv)
return _mask_mod
causal_w_offset = get_score_mod_w_offset(causal, offset)
用于推理的 BlockMask
我们还可以将 BlockMask 用于推理,以利用掩码稀疏性。这个想法是在模型设置期间一次性预计算 BlockMask,并在解码期间使用它的切片
预计算 BlockMask
在设置期间,我们为 MAX_SEQ_LEN x MAX_SEQ_LEN 创建一个方形 BlockMask
from torch.nn.attention.flex_attention import create_block_mask
def causal_mask(b, h, q_idx, kv_idx):
return q_idx >= kv_idx
block_mask = create_block_mask(causal_mask, B=None, H=None, Q_LEN=MAX_SEQ_LEN,KV_LEN=MAX_SEQ_LEN)
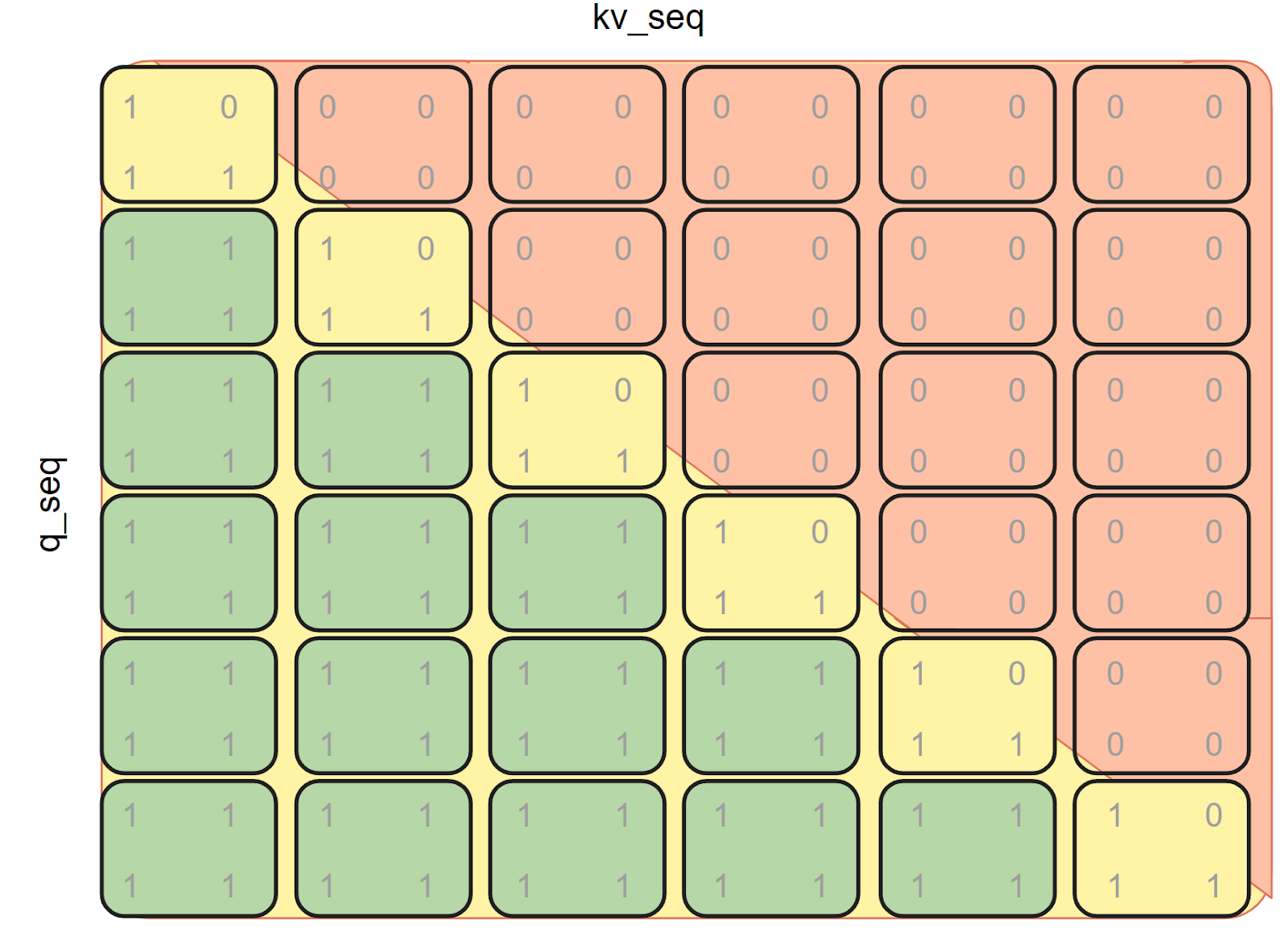 在解码期间使用 BlockMask
在解码期间使用 BlockMask
对于第 i 个 token,我们使用掩码的一个切片
block_offset = i // block_mask.BLOCK_SIZE[0]
block_mask_slice = block_mask[:, :, block_offset]
# don't forget to use the mask_mod with offset!
block_mask_slice.mask_mod = get_mask_mod_w_offset(causal_mask)
 性能
性能
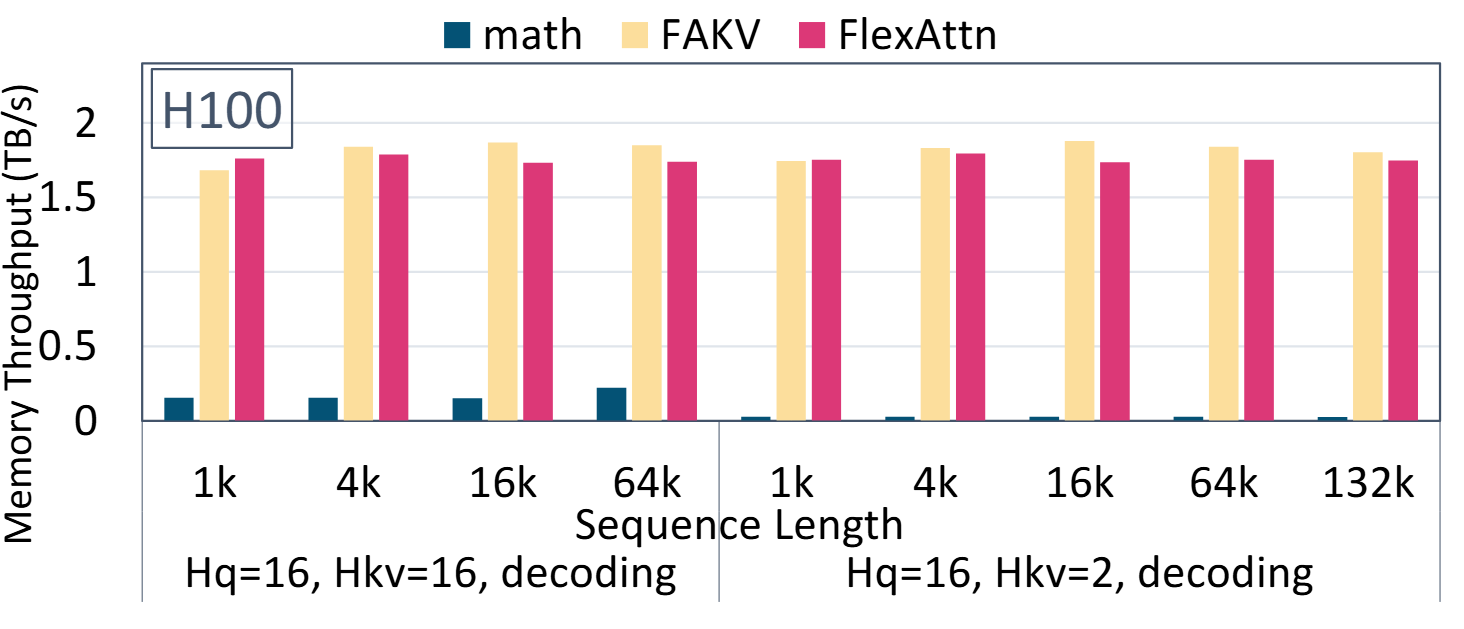 FlexDecoding 内核的性能与 FlashDecoding (FAKV) 相当,并且显著优于 pytorch 的 scaled_dot_product_attention (代码)。
FlexDecoding 内核的性能与 FlashDecoding (FAKV) 相当,并且显著优于 pytorch 的 scaled_dot_product_attention (代码)。
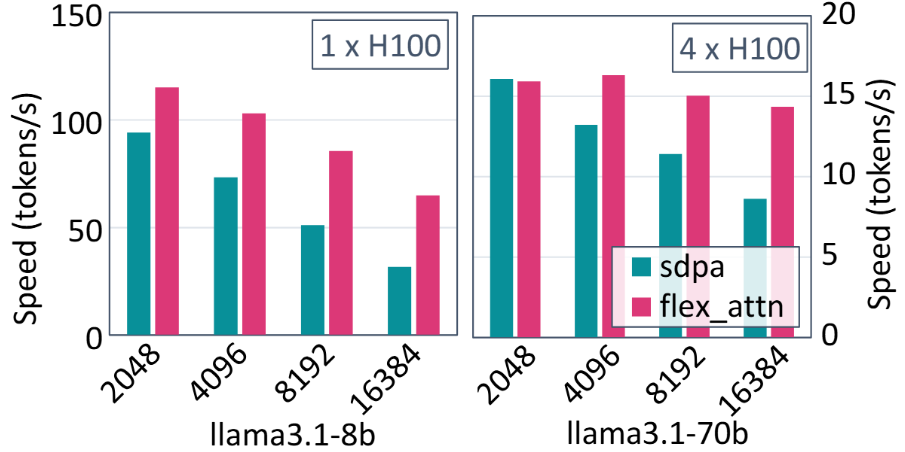
与 gpt-fast 中的 SDPA 相比,FlexDecoding 将 LLaMa3.1-8B 服务性能提升了 1.22x-2.04x,将 LLaMa3.1-70B 性能提升了 0.99x – 1.66x。( 代码)
分页注意力
vLLM 是流行的 LLM 服务引擎之一,其高效的内存管理得益于 PagedAttention。现有的 PagedAttention 实现需要专用的 CUDA 内核,并且在支持新兴的注意力变体方面显示出有限的灵活性。在本节中,我们介绍了一种由 FlexAttention 和 torch.compile 支持的 PT2 原生 PagedAttention 实现。
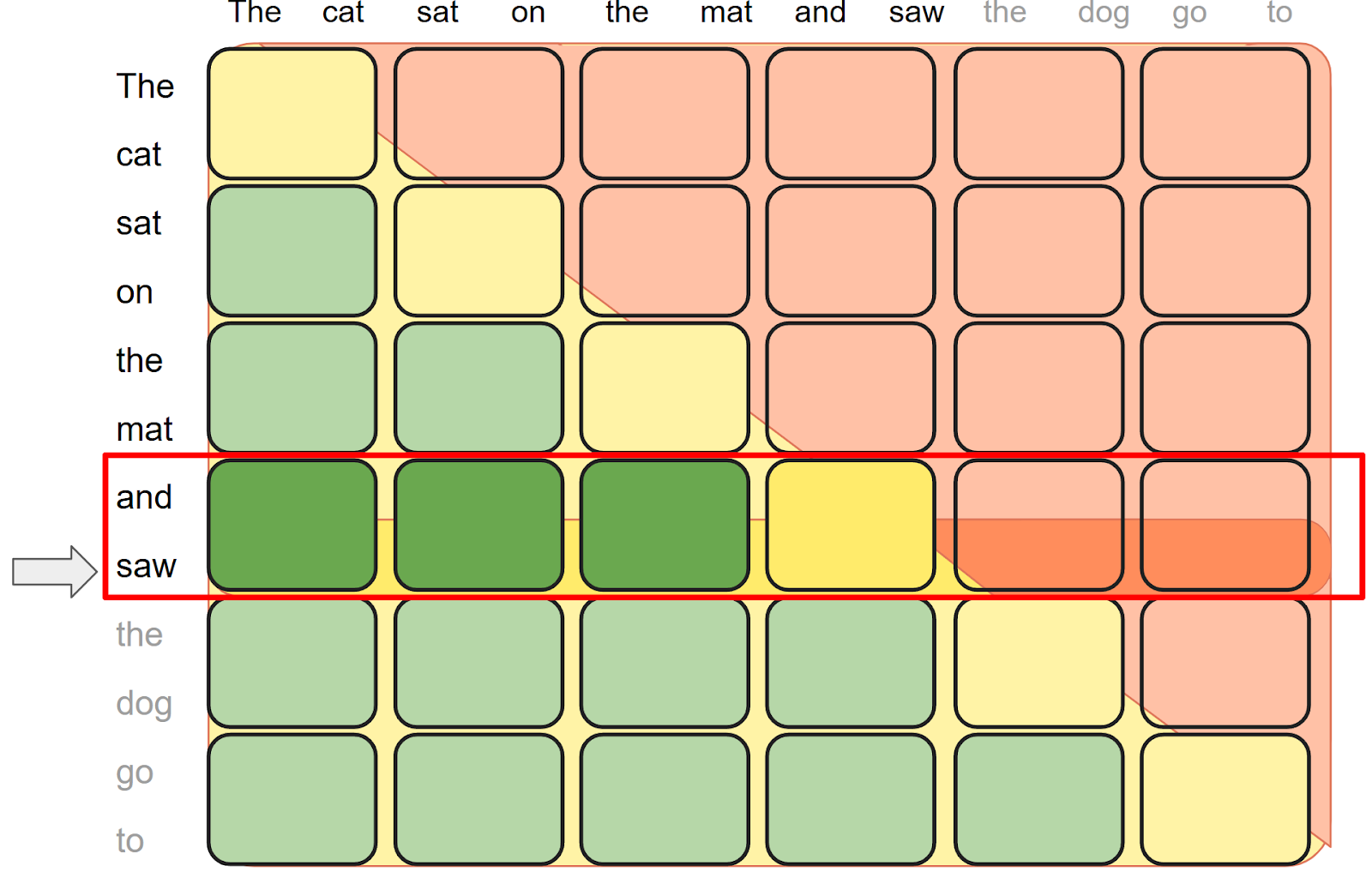
PagedAttention 分散 KV 缓存以减少内存碎片并支持更高的批次大小。如果没有 PagedAttention,来自同一请求的 KV 缓存将存储在连续内存中,需要形状为 *B x H x KV LEN x D* 的 2 个张量。我们称之为逻辑 KV 缓存。在这里,KV_LEN 是批次中所有请求的最大序列长度。考虑到图 1(a),KV_LEN 为 9,因此所有请求都必须填充到 9 个 token,导致大量内存浪费。使用 PagedAttention,我们可以将每个请求分块成大小相同的多页 page_size,并将这些页分散到形状为 *1 x H x max seq len x D* 的物理 KV 缓存中,其中 max_seq_len=n_pages x page_size。这避免了将请求填充到相同长度并节省了内存。具体来说,我们提供了一个 assign API,通过索引计算更新 KV 缓存
def assign(
batch_idx: torch.Tensor,
input_pos: torch.Tensor,
k_val: torch.Tensor,
v_val: torch.Tensor,
k_cache: torch.Tensor,
v_cache: torch.Tensor,
) -> None
此 assign API 背后是一个页表,一个将逻辑 KV 缓存映射到物理 KV 缓存的张量
assign 接受 k_val 和 v_val,并根据页表中的映射将其分散到物理 KV 缓存中。
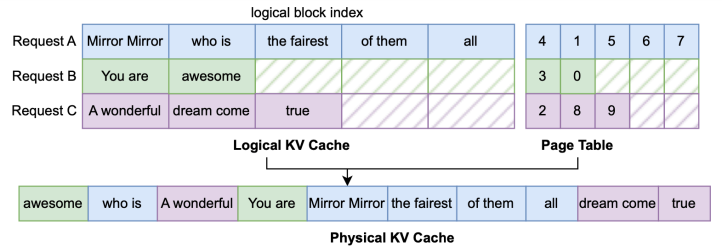
带有页表的分页注意力
一个自然的问题是,如何将 PagedAttention 与 FlexAttention 集成以支持不同的注意力变体?一个朴素的想法是在使用 FlexAttention 计算之前将逻辑 KV 缓存具体化。但这会导致冗余的内存复制和糟糕的性能。另一个想法是为分页注意力构建一个专用的 CUDA 或 Triton 内核,类似于 现有 PagedAttention 实现。然而,这会增加大量手动工作和代码复杂性。
相反,我们通过根据页表转换逻辑块掩码来设计融合的间接内存访问。在 FlexAttention 中,我们利用 BlockMask 来识别逻辑块并跳过冗余计算。虽然 Paged Attention 添加了一层额外的间接内存访问,但我们可以进一步将逻辑块掩码转换为与页表对应的物理块掩码,如图 2 所示。我们的 PagedAttention 实现通过 torch.gather 调用提供了 convert_logical_block_mask
def convert_logical_block_mask(
block_mask: BlockMask,
batch_idx: Optional[torch.Tensor] = None,
) -> BlockMask
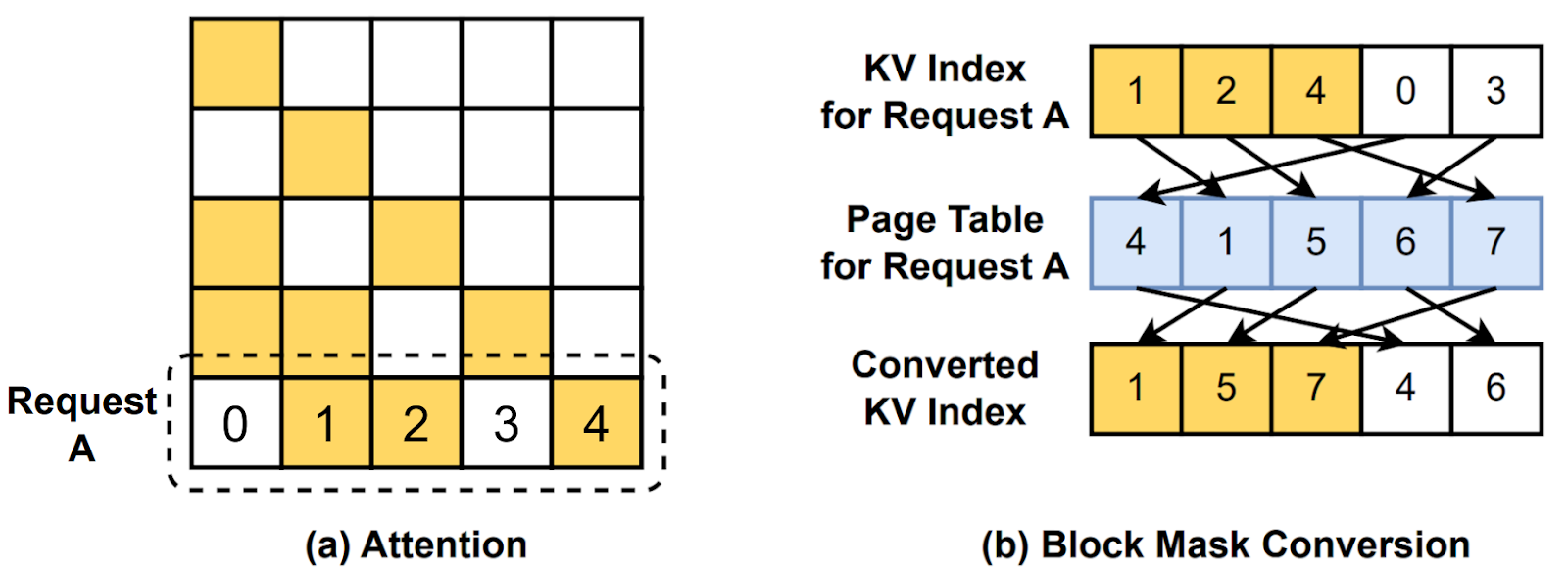 通过块掩码转换的分页注意力
通过块掩码转换的分页注意力
剩下一个问题是如何为 PagedAttention 重写用户指定的 mask_mod 和 score_mod。当用户指定这些修改时,他们是在没有运行时维护的页表知识的情况下使用逻辑索引编写的。以下代码显示了运行时必要的自动转换,以便使用物理 KV 索引重写用户指定的修改。new_mask_mod 将接受 physical_kv_idx 并将其转换回 logical_kv_idx,然后将用户指定的 mask_mod 应用于 logical_kv_idx 以获得正确的掩码。为了效率,我们将 physical_to_logical 维护为从 physical_kv_block 到 logical_kv_block 的映射,以方便转换。为了正确性,我们使用 torch.where 调用将超出边界的块掩码为 False。在将来自多个请求的逻辑 KV 缓存批处理到相同的物理 KV 缓存中之后,物理块的数量远多于每个请求的逻辑块数量。因此,在块掩码转换期间,物理块可能没有与特定请求对应的逻辑块。通过使用 torch.where 将其掩码为 False,我们可以确保来自不同请求的数据不会相互干扰的正确性。同样,我们可以自动转换 score_mod。
def get_mask_mod(mask_mod: Optional[_mask_mod_signature]) -> _mask_mod_signature:
if mask_mod is None:
mask_mod = noop_mask
def new_mask_mod(
b: torch.Tensor,
h: torch.Tensor,
q_idx: torch.Tensor,
physical_kv_idx: torch.Tensor,
):
physical_kv_block = physical_kv_idx // page_size
physical_kv_offset = physical_kv_idx % page_size
logical_block_idx = physical_to_logical[b, physical_kv_block]
logical_kv_idx = logical_block_idx * page_size + physical_kv_offset
return torch.where(
logical_block_idx >= 0, mask_mod(b, h, q_idx, logical_kv_idx), False
)
return new_mask_mod
图 3 展示了 Paged Attention 的延迟 (代码)。总的来说,与仅使用 Flex Attention 相比,Flex Attention 与 Paged Attention 的开销不到 5%。我们还观察到与 Flash Attention v2 相当的性能。一个最小的服务示例 进一步表明,在评估 OpenOrca 数据集 时,PagedAttention 可以支持 76 倍更高的批次大小,该数据集包括 1M GPT-4 完成和 3.2M GPT-3.5 完成。
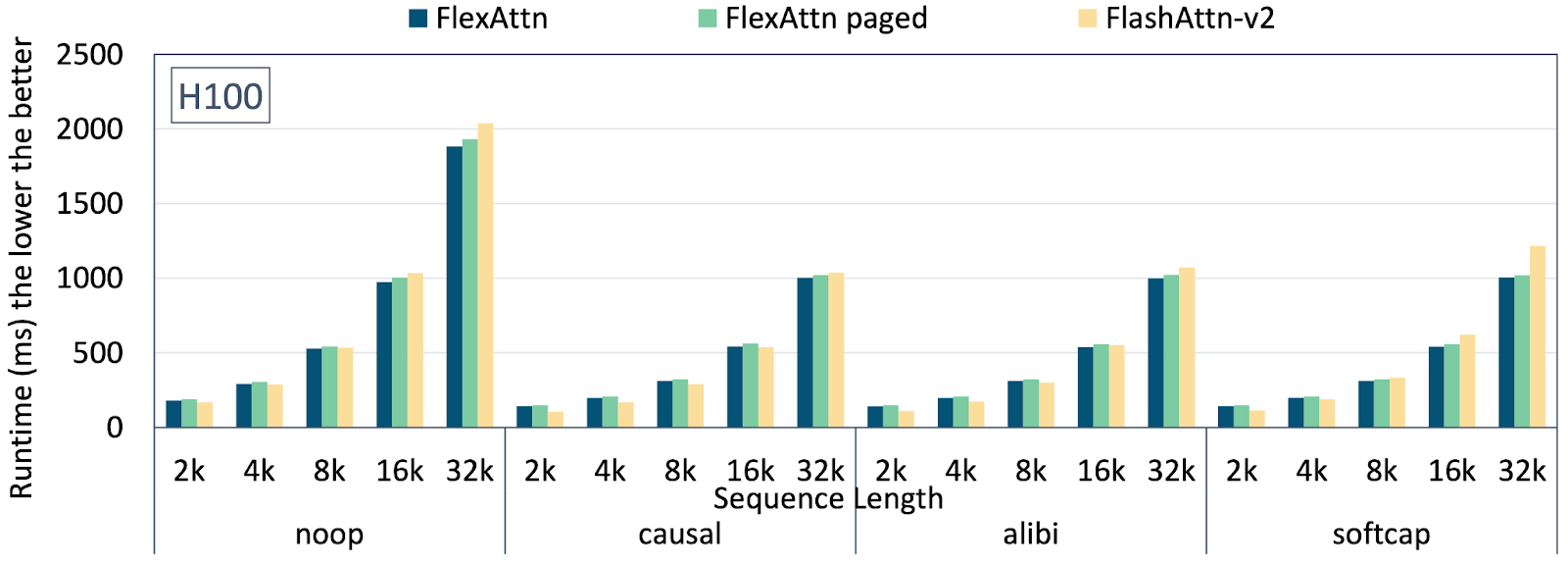 分页注意力:不同序列长度下的延迟
分页注意力:不同序列长度下的延迟
可训练偏置
FlexAttention 现在支持 score_mod 函数中的可训练参数。此功能允许用户在其 score_mod 实现中引用需要梯度的张量,并且在训练期间梯度会自动通过这些参数反向传播。
内存高效的梯度累积
FlexAttention 不会具体化完整的注意力分数矩阵,而是使用原子加法 (tl.atomic_add) 来累积梯度。这种方法显著降低了内存使用量,但代价是在梯度计算中引入了一些非确定性。
处理广播操作
前向传播中的广播操作(例如,score + bias[h])在反向传播中需要特殊考虑。当将张量广播到头内或其他维度中的多个注意力分数时,我们需要将这些梯度还原为原始张量形状。我们不具体化完整的注意力分数矩阵来执行此还原,而是使用原子操作。虽然这会带来一些运行时开销,但它允许我们通过避免具体化大型中间张量来保持内存效率。
当前限制
当前的实现只允许从 score_mod 函数中的每个输入张量进行一次读取。例如,bias[q_idx] + bias[kv_idx] 不受支持,因为它两次从同一个张量读取。我们希望将来能取消此限制。
简单示例
bias = torch.randn(num_heads, requires_grad=True)
def score_mod(score, b, h, q_idx, kv_idx):
return score + bias[h]
FlexAttention 的性能调优
要点速览
为了获得最佳性能,请使用 max-autotune 编译 FlexAttention,尤其是在处理复杂的 score_mods 和 mask_mods 时
flex_attention = torch.compile(flex_attention, dynamic=True, mode=’max-autotune’)
什么是 max-autotune?
max-autotune 是 torch.compile 的一种模式,在该模式下,TorchInductor 会扫描许多内核参数(例如,tile size、num_stages)并选择性能最佳的配置。这个过程允许内核测试成功和失败的配置而不会出现问题,并找到最佳可行的配置。
虽然使用 max-autotune 编译时间会更长,但最佳配置会缓存以供将来内核执行。
这是使用 max-autotune 编译的 FlexAttention 示例
triton_flex_attention_backward_7 0.2528 ms 100.0% BLOCKS_ARE_CONTIGUOUS=False, BLOCK_M1=32, BLOCK_M2=32, BLOCK_N1=32, BLOCK_N2=32, FLOAT32_PRECISION="'ieee'", GQA_SHARED_HEADS=7, HAS_FULL_BLOCKS=False, IS_DIVISIBLE=False, OUTPUT_LOGSUMEXP=True, PRESCALE_QK=False, QK_HEAD_DIM=128, ROWS_GUARANTEED_SAFE=False, SM_SCALE=0.08838834764831843, SPARSE_KV_BLOCK_SIZE=1073741824, SPARSE_Q_BLOCK_SIZE=1073741824, V_HEAD_DIM=128, num_stages=4, num_warps=4
为什么将 max-autotune 用于 FlexAttention?
FlexAttention 中共享内存的利用量取决于 score_mod 和 mask_mod 方法。这种可变性意味着预配置的默认内核参数可能会导致性能下降,甚至在某些硬件上对于某些掩码/模块出现共享内存不足的错误。
例如,对于文档掩码,默认配置可以将 GPU 占用率减半,从而将某些 GPU 上的性能降低到其潜力的约 75%。为避免此类问题,我们强烈建议启用 max-autotune。
更新和增强
- 现在作为 PyTorch 2.5.0 中的原型功能提供
- 修复了关键的正确性问题,包括影响在同一次 torch.compile 调用中多次调用 FlexAttention 的错误
扩展架构支持
- 任意序列长度支持——不再需要 128 的倍数
- 通过
is_gqa=True添加了原生分组查询注意力 (GQA) 支持 - 增强维度灵活性
- 不同的 QK 和 V 头维度
- 非 2 的幂的头维度
- 可训练注意力偏置(原型)
幕后
- 新的融合 CPU 后端
- 改进了 float32 输入的 TF32 处理
- 解决了各种动态形状问题
- 输出布局与查询步幅匹配
这些更新使 FlexAttention 更加健壮和灵活,同时保持其核心承诺:将 PyTorch 的易用性与 FlashAttention 的性能优势相结合。