注意力机制作为无处不在的 Transformer 架构的核心层,是大型语言模型和长上下文应用的瓶颈。FlashAttention(和 FlashAttention-2)通过最小化内存读写,开创了一种在 GPU 上加速注意力机制的方法,现在大多数库都使用它来加速 Transformer 的训练和推理。这使得LLM的上下文长度在过去两年中大幅增加,从2-4K(GPT-3、OPT)增加到128K(GPT-4),甚至1M(Llama 3)。然而,尽管取得了成功,FlashAttention 尚未利用现代硬件的新功能,FlashAttention-2 在 H100 GPU 上的理论最大 FLOPs 利用率仅为 35%。在这篇博文中,我们描述了在 Hopper GPU 上加速注意力机制的三种主要技术:利用 Tensor Cores 和 TMA 的异步性来 (1) 通过 warp 专用化重叠整体计算和数据移动,(2) 交错块级矩阵乘法和 softmax 运算,以及 (3) 利用硬件对 FP8 低精度的支持进行不连贯处理。
我们很高兴发布 FlashAttention-3,它融合了这些技术。使用 FP16 时,它比 FlashAttention-2 快 1.5-2.0 倍,吞吐量高达 740 TFLOPS,即 H100 理论最大 FLOPS 的 75% 利用率。使用 FP8 时,FlashAttention-3 达到接近 1.2 PFLOPS,误差比基准 FP8 注意力机制小 2.6 倍。
FlashAttention-3 可在以下地址获取:https://github.com/Dao-AILab/flash-attention
论文
FlashAttention 回顾
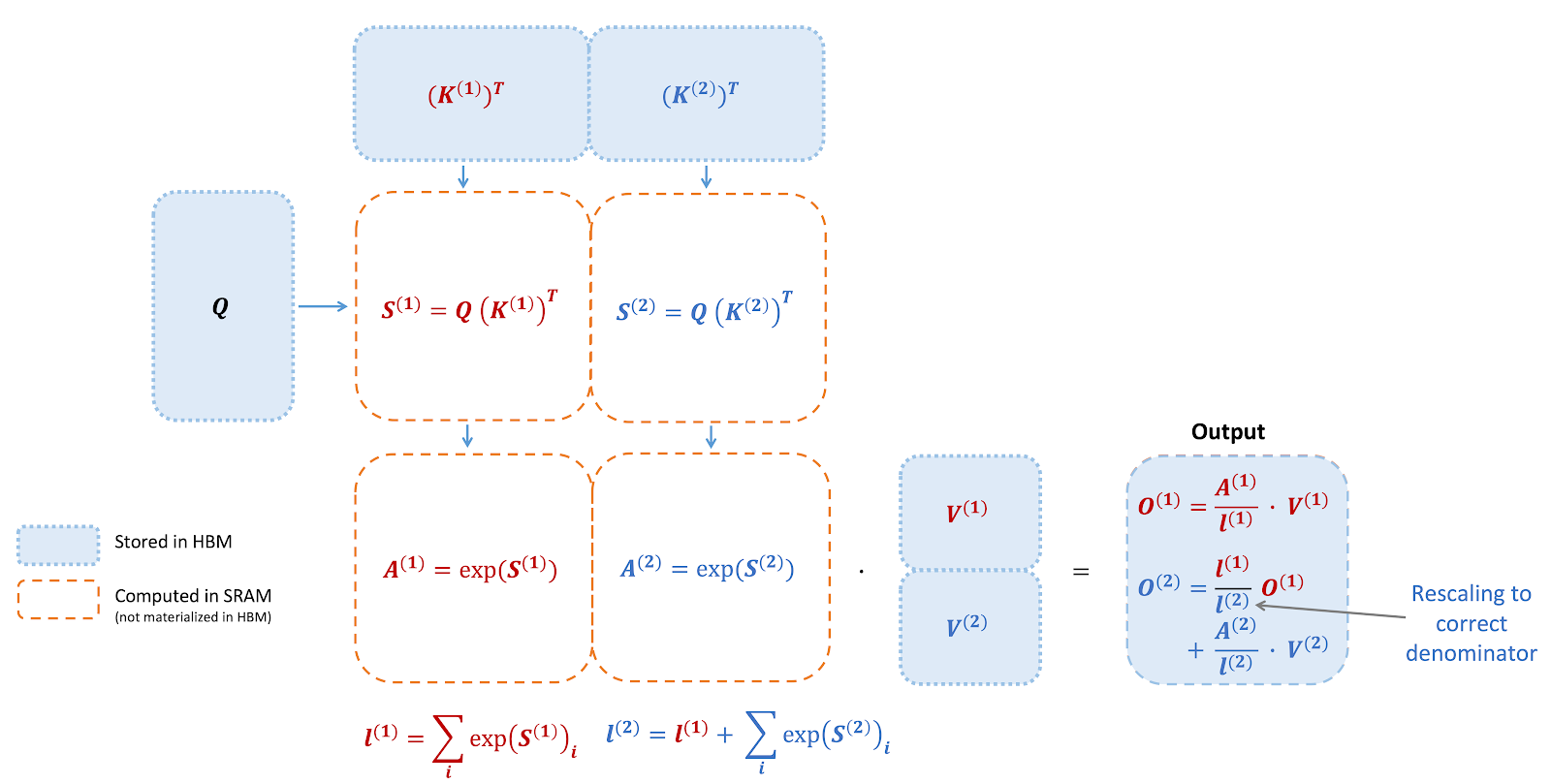
FlashAttention 是一种重新排序注意力计算并利用分块和重新计算来显著加速并减少内存使用(从序列长度的二次方降至线性)的算法。我们使用分块将输入块从 HBM(GPU 内存)加载到 SRAM(快速缓存),对该块执行注意力计算,并更新 HBM 中的输出。通过不将大型中间注意力矩阵写入 HBM,我们减少了内存读写量,从而使实际时间加快 2-4 倍。
此处展示了 FlashAttention 正向传播的示意图:通过分块和 softmax 重缩放,我们以块为单位进行操作,避免从 HBM 读取/写入,同时获得正确的输出而没有近似值。
Hopper GPU 上的新硬件功能 – WGMMA、TMA、FP8
尽管 FlashAttention-2 在 Ampere (A100) GPU 上可以达到理论最大 FLOPS 的 70%,但它尚未利用 Hopper GPU 上的新功能来最大化性能。我们在此描述 Hopper 独有的一些新功能,以及它们为何重要。
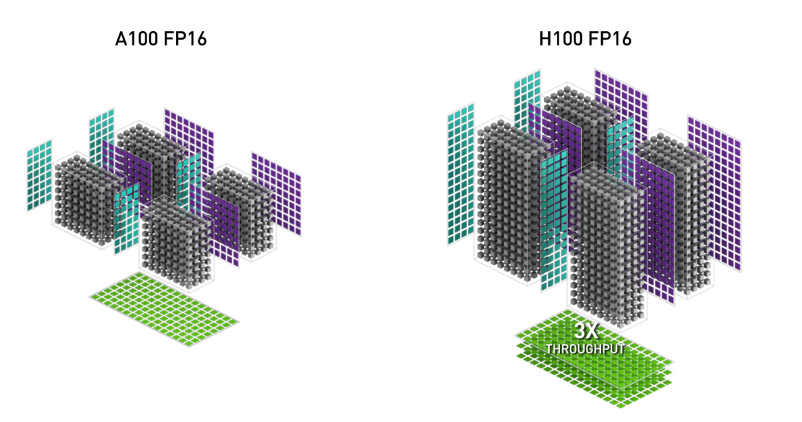
1. WGMMA (Warpgroup Matrix Multiply-Accumulate)。这项新功能利用了 Hopper 上的新 Tensor Cores,其吞吐量1远高于 Ampere 中较旧的 mma.sync 指令(图片来自 H100 白皮书)。
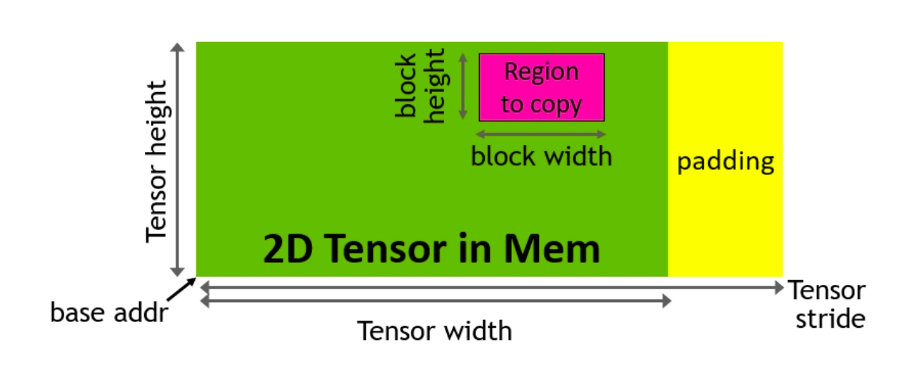
2. TMA (Tensor Memory Accelerator)。这是一个特殊的硬件单元,用于加速全局内存和共享内存之间的数据传输,负责所有索引计算和越界预测。这释放了寄存器,是增加瓦片大小和效率的宝贵资源。
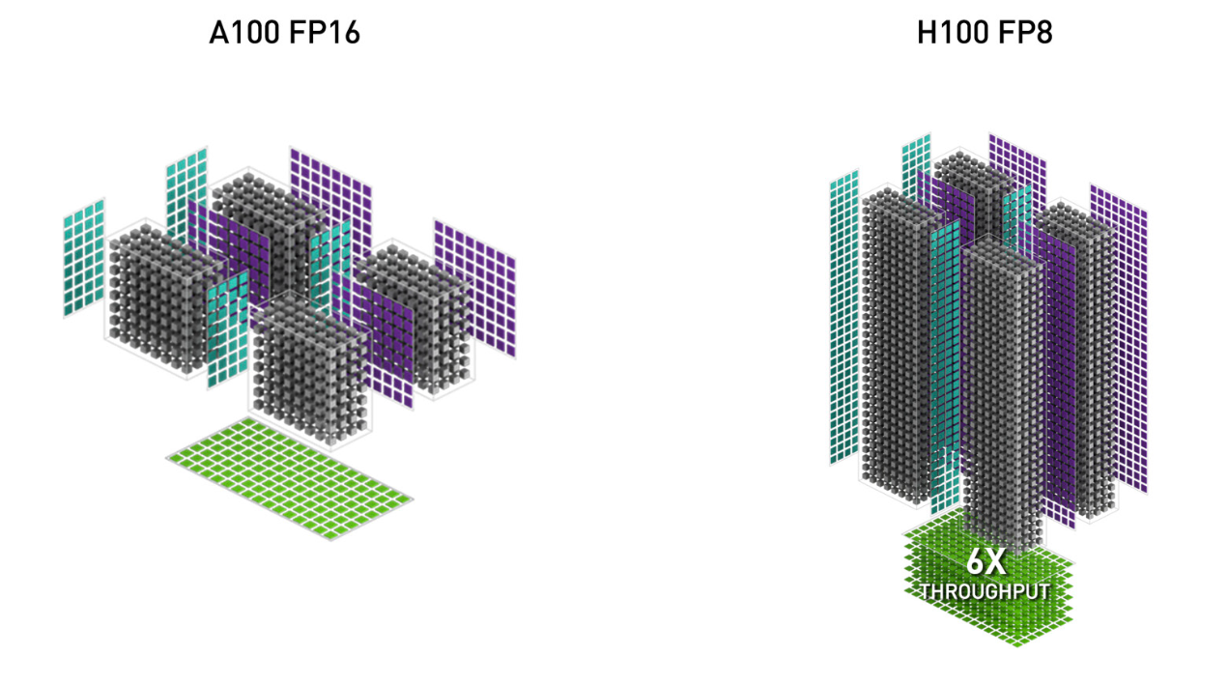
3. FP8 低精度。这使 Tensor Core 的吞吐量翻倍(例如,FP16 为 989 TFLOPS,FP8 为 1978 TFLOPS),但通过使用更少的比特来表示浮点数来牺牲精度。
FlashAttention-3 利用了 Hopper 的所有这些新功能,并使用了来自 NVIDIA 的 CUTLASS 库的强大抽象。
通过重写 FlashAttention 以使用这些新功能,我们已经可以显著加速它(例如,FlashAttention-2 FP16 正向传播从 350 TFLOPS 提高到大约 540-570 TFLOPS)。然而,Hopper 上新指令(WGMMA 和 TMA)的异步特性为重叠操作并因此提取更大性能开辟了额外的算法机会。对于这篇博文,我们将解释两种针对注意力机制的此类技术。warp 专用化的通用技术,即独立的生产者和消费者 warp 执行 TMA 和 WGMMA,在 GEMM 的背景下已在其他地方进行了充分介绍,在这里也同样适用。
异步性:重叠 GEMM 和 Softmax
为什么要重叠?
注意力机制主要包含 GEMM(Q 和 K 之间以及注意力概率 P 和 V 之间的矩阵乘法)和 softmax 两种操作。为什么我们需要重叠它们呢?大部分 FLOPS 不都在 GEMM 中吗?只要 GEMM 运算速度快(例如,使用 WGMMA 指令计算),GPU 不就应该 飞速运转 吗?
问题在于,在现代加速器上,非矩阵乘法操作比矩阵乘法操作慢得多。像指数函数(用于 softmax)这样的特殊函数,其吞吐量甚至低于浮点乘加;它们由多功能单元评估,该单元独立于浮点乘加或矩阵乘加单元。举例来说,H100 GPU SXM5 的 FP16 矩阵乘法吞吐量为 989 TFLOPS,但特殊函数仅为 3.9 TFLOPS(吞吐量低 256 倍)2!对于头维度为 128 的情况,矩阵乘法 FLOPS 比指数函数多 512 倍,这意味着指数函数可能占矩阵乘法时间的 50%。对于 FP8 情况更糟,矩阵乘法 FLOPS 速度快两倍,而指数函数 FLOPS 速度保持不变。理想情况下,我们希望矩阵乘法和 softmax 并行操作。当 Tensor Cores 忙于矩阵乘法时,多功能单元应该计算指数函数!
使用乒乓调度实现 warpgroup 间的重叠
重叠 GEMM 和 softmax 的第一种也是最简单的方法是什么都不做!warp 调度器已经尝试调度 warp,以便当某些 warp 被阻塞(例如,等待 GEMM 结果)时,其他 warp 可以运行。也就是说,warp 调度器为我们免费完成了部分重叠。
然而,我们可以通过手动进行一些调度来改进这一点。例如,如果我们有 2 个 warpgroup(标记为 1 和 2 – 每个 warpgroup 是一个包含 4 个 warp 的组),我们可以使用同步屏障(bar.sync),以便 warpgroup 1 首先执行其 GEMM(例如,一次迭代的 GEMM1 和下一次迭代的 GEMM0),然后 warpgroup 2 执行其 GEMM,同时 warpgroup 1 执行其 softmax,依此类推。这种“乒乓”调度如下图所示,相同的颜色表示相同的迭代。
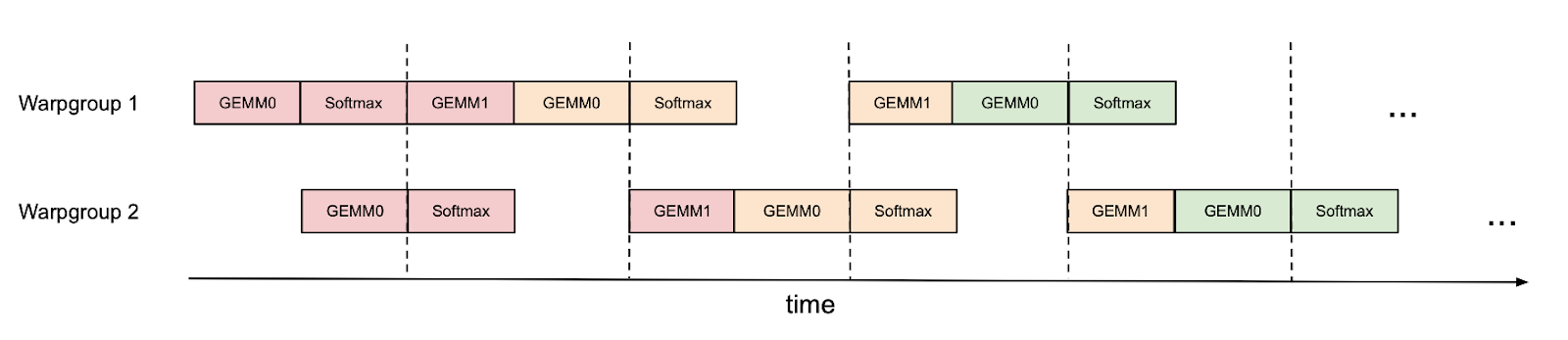
这将使我们能够在另一个 warpgroup 的 GEMM 阴影下执行 softmax。当然,这个图只是一个卡通化的表示;在实践中,调度并非如此干净。尽管如此,乒乓调度可以将 FP16 注意力前向传播从大约 570 TFLOPS 提高到 620 TFLOPS(头维度 128,序列长度 8K)。
GEMM 和 Softmax 的 warpgroup 内重叠
即使在一个 warpgroup 内,我们也可以让 softmax 的一部分在 warpgroup 的 GEMM 运行时同时运行。这在下图中有所说明,其中相同的颜色表示相同的迭代。
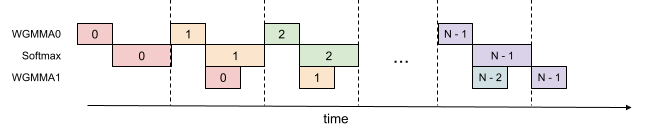
这种流水线操作将 FP16 注意力前向传播的吞吐量从大约 620 TFLOPS 提高到大约 640-660 TFLOPS,代价是更高的寄存器压力。我们需要更多的寄存器来同时保存 GEMM 的累加器以及 softmax 的输入/输出。总的来说,我们发现这种技术提供了一个有利的权衡。
低精度:通过不连贯处理减少量化误差
LLM 激活可能存在异常值,其幅度远大于其余特征。这些异常值使得量化变得困难,从而产生更大的量化误差。我们利用不连贯处理(一种在量化文献中使用的技术,例如来自QuIP)来将查询和键与一个随机正交矩阵相乘,以“分散”异常值并减少量化误差。具体来说,我们使用 Hadamard 变换(带随机符号),它可以在每个注意力头中以 O(d log d) 而不是 O(d^2) 的时间完成,其中 d 是头维度。由于 Hadamard 变换受内存带宽限制,它可以与之前的操作(例如旋转嵌入,也受内存带宽限制)“免费”融合。
在我们的实验中,Q、K、V 从标准正态分布生成,但 0.1% 的条目具有较大幅度(模拟异常值),我们发现不连贯处理可以将量化误差减少 2.6 倍。下表显示了数值误差比较。请参阅论文了解详细信息。

注意力基准测试
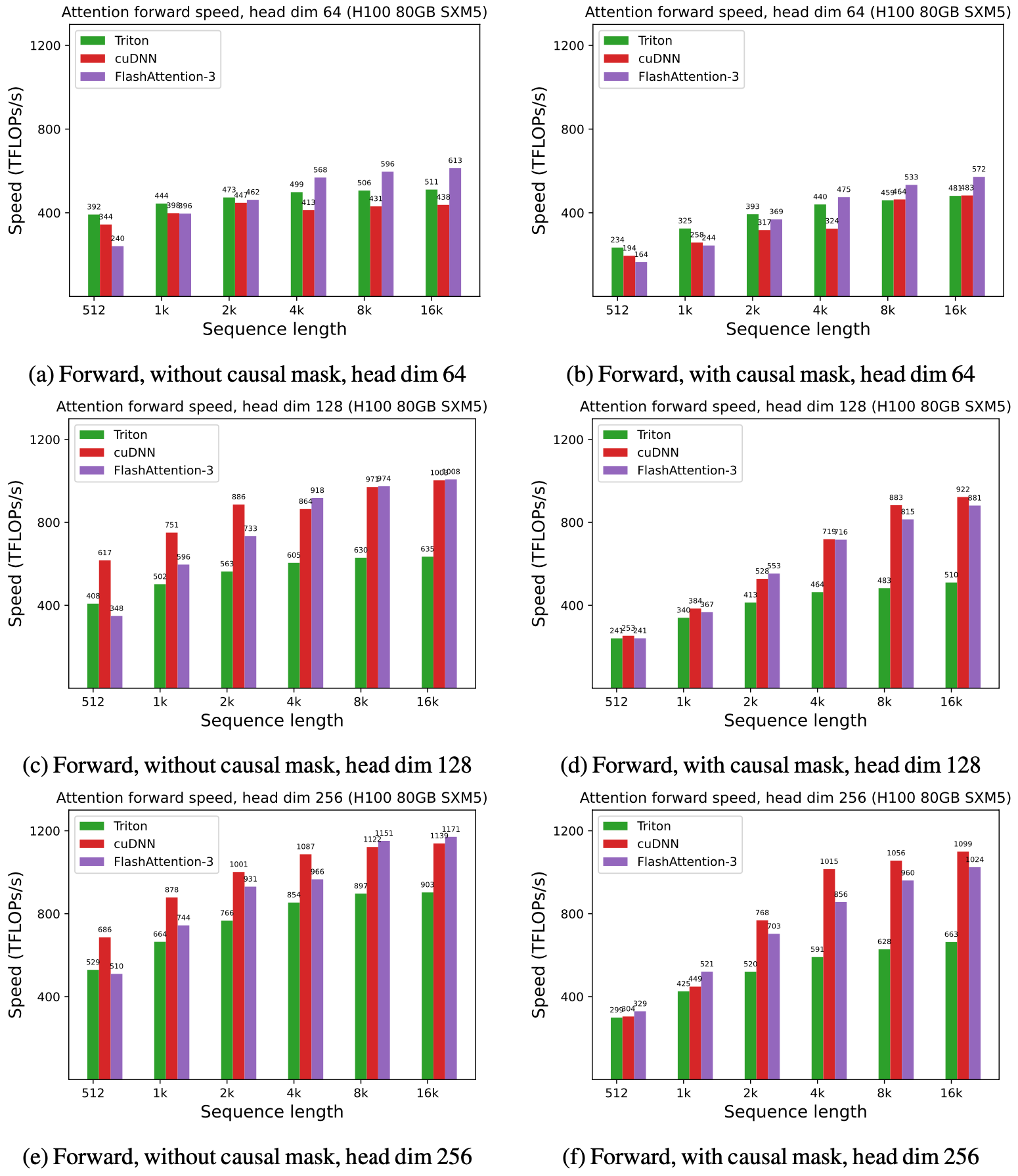
我们展示了 FlashAttention-3 的一些结果,并将其与 FlashAttention-2,以及 Triton 和 cuDNN 中的实现(两者都已经使用了 Hopper GPU 的新硬件特性)进行了比较。
对于 FP16,我们看到比 FlashAttention-2 提速约 1.6x-1.8x。
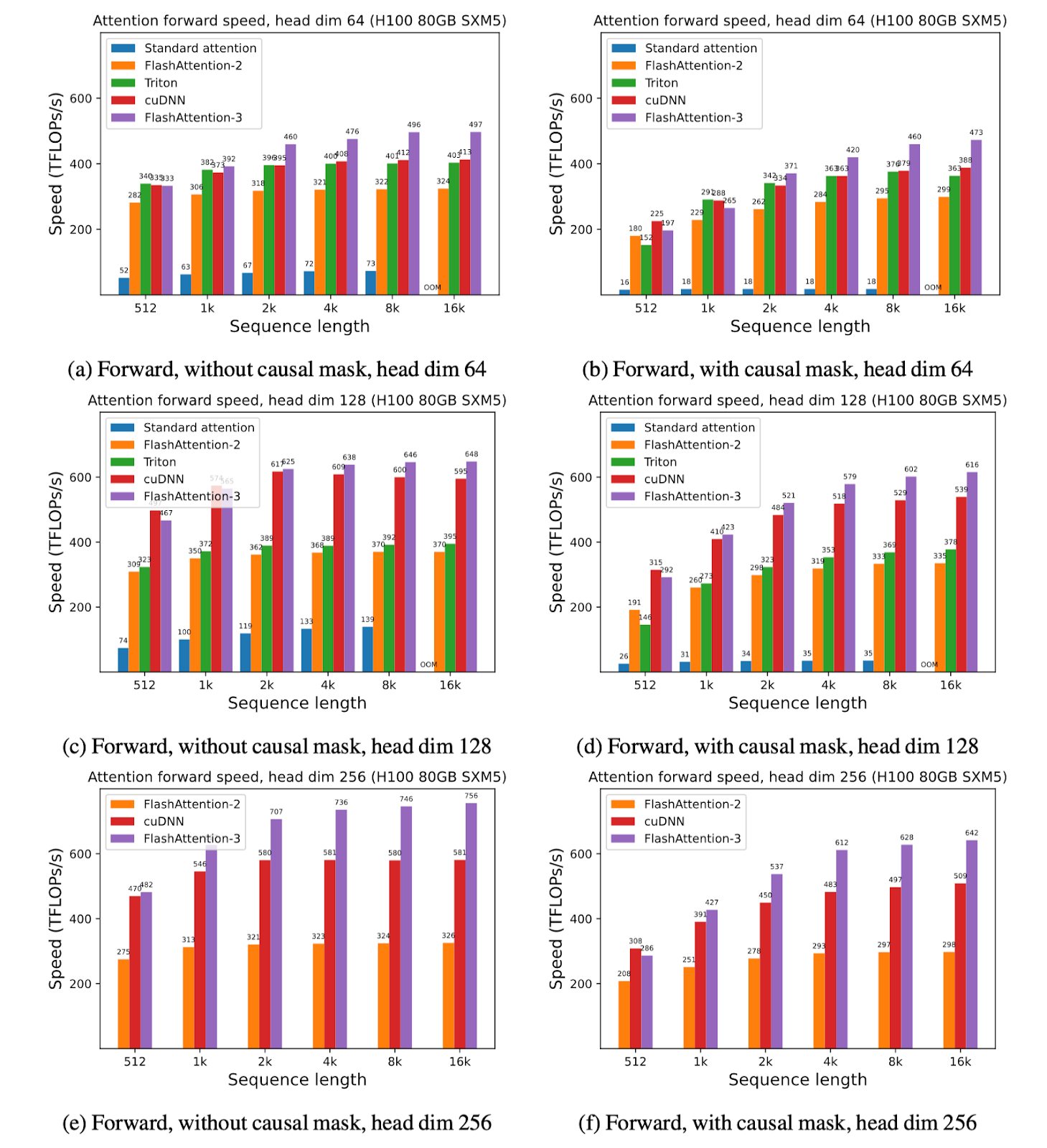
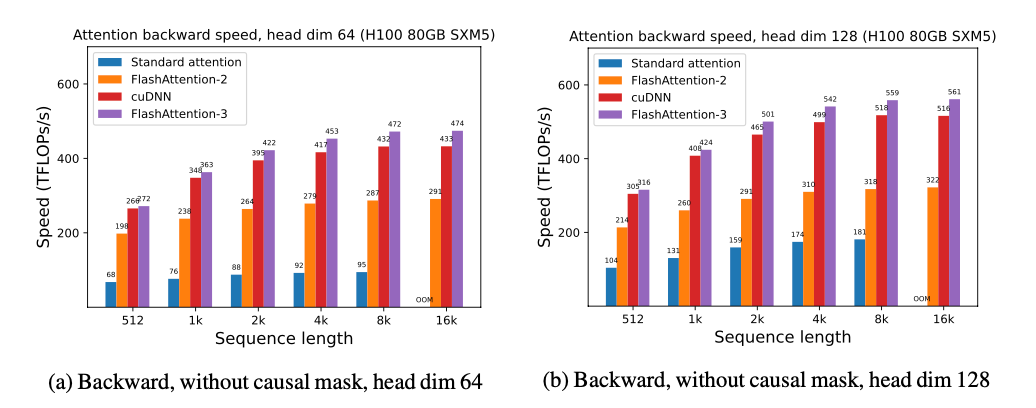
对于 FP8,我们能够达到接近 1.2 PFLOPS!
讨论
这篇博客文章重点介绍了 Hopper GPU 上 FlashAttention 的一些优化。其他优化(例如,可变长度序列、持久化内核和 FP8 的内核内转置)在论文中进行了介绍。
我们已经看到,设计利用其运行硬件的算法可以带来显著的效率提升,并解锁诸如长上下文等新的模型功能。我们期待未来在 LLM 推理优化方面的工作,以及将我们的技术推广到其他硬件架构。
我们也期待 FlashAttention-3 在 PyTorch 的未来版本中集成。