动机
ChatGPT 或 Llama 等大型语言模型 (LLM) 近来受到了前所未有的关注。然而,它们的运行成本仍然非常高昂。尽管生成单个响应可能需要约 0.01 美元(AWS 上一个 8xA100 实例的几秒钟成本),但当扩展到数十亿用户时,这些用户每天可能与 LLM 进行多次交互,成本会迅速累积。一些用例的成本更高,例如代码自动补全,因为它在每次输入新字符时都会运行。随着 LLM 应用的激增,即使是生成时间上的微小效率提升,也能产生巨大的影响。
LLM 推理(或“解码”)是一个迭代过程:每次生成一个 token。生成包含 N 个 token 的完整句子需要模型进行 N 次前向传播。幸运的是,可以缓存之前计算的 token:这意味着单个生成步骤不依赖于上下文长度,除了一个操作——注意力。这个操作不会随着上下文长度的增加而很好地扩展。
LLM 有许多重要的新兴用例,它们利用长上下文。通过更长的上下文,LLM 可以对更长的文档进行推理,无论是进行摘要还是回答相关问题,它们可以跟踪更长的对话,甚至在编写代码之前处理整个代码库。例如,大多数 LLM 在 2022 年(GPT-3)的上下文长度最高为 2k,但我们现在有开源 LLM 扩展到 32k(Llama-2-32k),甚至最近达到 100k 以上(CodeLlama)。在这种情况下,注意力在推理过程中占据了相当大的时间比例。
当在批次大小维度上进行扩展时,即使上下文相对较小,注意力也可能成为瓶颈。这是因为读取内存量随批次维度扩展,而模型的其余部分仅取决于模型大小。
我们提出了一种名为 Flash-Decoding 的技术,它显著加速了推理过程中的注意力计算,对于非常长的序列,生成速度提高了 8 倍。主要思想是尽可能快地并行加载键和值,然后单独重新缩放并组合结果以保持正确的注意力输出。
解码过程中的多头注意力
在解码过程中,生成的每个新 token 都需要关注所有先前的 token,以计算
softmax(queries @ keys.transpose) @ values
这个操作在训练场景中已经通过 FlashAttention(v1 和最近的 v2)进行了优化,其中瓶颈在于读写中间结果(例如 Q @ K^T)的内存带宽。然而,这些优化不能直接应用于推理场景,因为瓶颈不同。对于训练,FlashAttention 在批次大小和查询长度维度上进行并行化。在推理过程中,查询长度通常为 1:这意味着如果批次大小小于 GPU 上的流式多处理器 (SM) 数量(A100 为 108),该操作将只使用 GPU 的一小部分!在使用长上下文时尤其如此,因为它需要较小的批次大小才能适应 GPU 内存。当批次大小为 1 时,FlashAttention 将使用不到 GPU 的 1%!

FlashAttention 仅在查询块和批次大小之间进行并行化,在解码过程中无法完全占用整个 GPU
注意力也可以使用矩阵乘法原语完成——不使用 FlashAttention。在这种情况下,操作完全占用 GPU,但会启动许多读写中间结果的内核,这不是最优的。
更快的解码注意力:Flash-Decoding
我们的新方法 Flash-Decoding 基于 FlashAttention,并增加了一个新的并行化维度:键/值序列长度。它结合了上述两种方法的优点。像 FlashAttention 一样,它将极少的额外数据存储到全局内存中,但即使批次大小很小,只要上下文长度足够大,它也能充分利用 GPU。

Flash-Decoding 还在键和值之间进行并行化,代价是一个小的最终归约步骤
Flash-Decoding 分三步工作
- 首先,我们将键/值分割成更小的块。
- 我们使用 FlashAttention 并行计算查询与这些分割块的注意力。我们还为每行和每个分割块写入一个额外的标量:注意力值的对数和指数 (log-sum-exp)。
- 最后,我们通过对所有分割块进行归约,并使用对数和指数来缩放每个分割块的贡献,从而计算出实际输出。
这一切之所以可能,是因为注意力/softmax 可以迭代计算。在 Flash-Decoding 中,它在两个层面使用:在分割块内部(像 FlashAttention 一样),以及在分割块之间执行最终归约。
实际上,步骤 (1) 不涉及任何 GPU 操作,因为键/值块是完整键/值张量的视图。然后我们有两个独立的内核分别执行 (2) 和 (3)。
CodeLlama 34B 基准测试
为了验证这种方法,我们对 CodeLLaMa-34b 的解码吞吐量进行了基准测试。该模型与 Llama 2 具有相同的架构,更广泛地说,结果应该适用于许多 LLM。我们测量了在 512 到 64k 不同序列长度下的解码速度(tok/s),并比较了多种计算注意力的方法:
- Pytorch:使用纯 PyTorch 原语运行注意力(不使用 FlashAttention)
- FlashAttention v2
- FasterTransformer:使用 FasterTransformer 注意力核
- Flash-Decoding
- 以及作为上限计算的读取整个模型和 KV-cache 所需的时间
Flash-Decoding 为超长序列解锁了高达 8 倍的解码速度提升,并且比其他方法具有更好的扩展性。
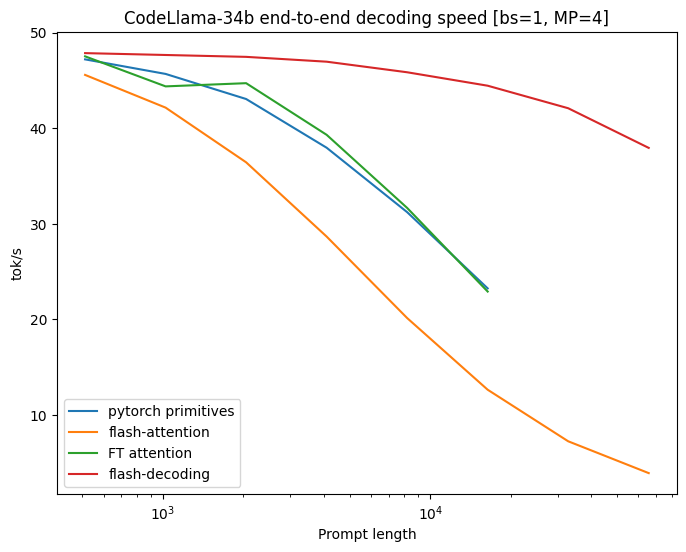
除了 Flash-Decoding,所有方法在小提示下表现相似,但随着序列长度从 512 增加到 64k,扩展性很差。在这种情况下(批次大小为 1),使用 Flash-Decoding 时,序列长度的扩展对生成速度影响很小。
组件级微基准测试
我们还在 A100 上对各种序列长度和批次大小的 f16 输入的缩放多头注意力进行了微基准测试。我们将批次大小设置为 1,并使用 16 个维度为 128 的查询头,以及 2 个键/值头(分组查询注意力),这与在 4 个 GPU 上运行 CodeLLaMa-34b 时使用的维度相匹配。
| 设置 \ 算法 | PyTorch Eager (微秒) | Flash-Attention v2.0.9 (微秒) | Flash-Decoding (微秒) |
| B=256, seqlen=256 | 3058.6 | 390.5 | 63.4 |
| B=128, seqlen=512 | 3151.4 | 366.3 | 67.7 |
| B=64, seqlen=1024 | 3160.4 | 364.8 | 77.7 |
| B=32, seqlen=2048 | 3158.3 | 352 | 58.5 |
| B=16, seqlen=4096 | 3157 | 401.7 | 57 |
| B=8, seqlen=8192 | 3173.1 | 529.2 | 56.4 |
| B=4, seqlen=16384 | 3223 | 582.7 | 58.2 |
| B=2, seqlen=32768 | 3224.1 | 1156.1 | 60.3 |
| B=1, seqlen=65536 | 1335.6 | 2300.6 | 64.4 |
| B=1, seqlen=131072 | 2664 | 4592.2 | 106.6 |
多头注意力的微基准测试,运行时间以微秒计。Flash-Decoding 在序列长度扩展到 64k 时,运行时间几乎保持不变。
之前测量到的端到端高达 8 倍的加速之所以成为可能,是因为注意力本身的计算速度比 FlashAttention 快 50 倍。直到序列长度达到 32k,注意力时间大致保持不变,因为 Flash-Decoding 能够充分利用 GPU。
使用 Flash-Decoding
Flash-decoding 可在以下地方获得:
- 在 FlashAttention 包中,从 2.2 版本开始。
- 通过 xFormers 从 0.0.22 版本开始,通过 `xformers.ops.memory_efficient_attention`。调度器将根据问题规模自动使用 Flash-Decoding 或 FlashAttention 方法。当这些方法不支持时,它可以调度到一个实现 Flash-Decoding 算法的高效 triton 内核。
一个使用 LLaMa v2 / CodeLLaMa 进行解码的完整示例可在 FlashAttention 仓库 这里 和 xFormers 仓库 这里找到。我们还提供了一个 极简示例 用于 LLaMa v1/v2 模型的高效解码代码,旨在快速、易读、具有教育意义且可修改。
致谢
感谢 Erich Elsen、Ashish Vaswani 和 Michaël Benesty 提出分割 KV 缓存加载的这个想法。我们感谢 Jeremy Reizenstein、Patrick Labatut 和 Andrew Tulloch 的宝贵讨论,以及 Quentin Carbonneaux 为 xFormers 贡献了高效解码示例。我们还要感谢 Geeta Chauhan 和 Gregory Chanan 帮助撰写文章,并更广泛地为本文在 PyTorch 博客上发表做出了贡献。