
在加速大型语言模型在各种 AI 硬件上运行的竞赛中,FlagGems 提供了一个高性能、灵活且可扩展的解决方案。FlagGems 基于 Triton 语言构建,是一个插件式的 PyTorch 运算符和内核库,旨在普及 AI 计算。它的使命是:实现一次编写、随处 JIT 的体验,使开发人员能够轻松地将优化的内核部署到各种硬件后端。FlagGems 最近获得 PyTorch 生态系统工作组的接纳,并加入了 PyTorch 生态系统。
FlagGems 已实现 180 多个运算符,涵盖原生的 PyTorch 运算符和大型模型中广泛使用的自定义运算符,正在快速发展以跟上生成式 AI 的前沿。
要查看 PyTorch 生态系统,请参阅PyTorch Landscape,并了解项目如何加入 PyTorch 生态系统。
主要特点
- 广泛的运算符库:180 多个 PyTorch 兼容运算符,且持续增长
- 性能优化:精选运算符经过手动调优以提高速度
- 与 Torch.compile 独立:在即时模式下功能齐全
- 逐点运算符代码生成:自动为任意输入类型和布局生成内核
- 快速内核调度:每个函数运行时调度逻辑
- C++ Triton 调度器:正在开发中,以实现更快的执行
- 多后端就绪:通过与后端无关的运行时 API 跨 10 多个硬件平台工作
架构
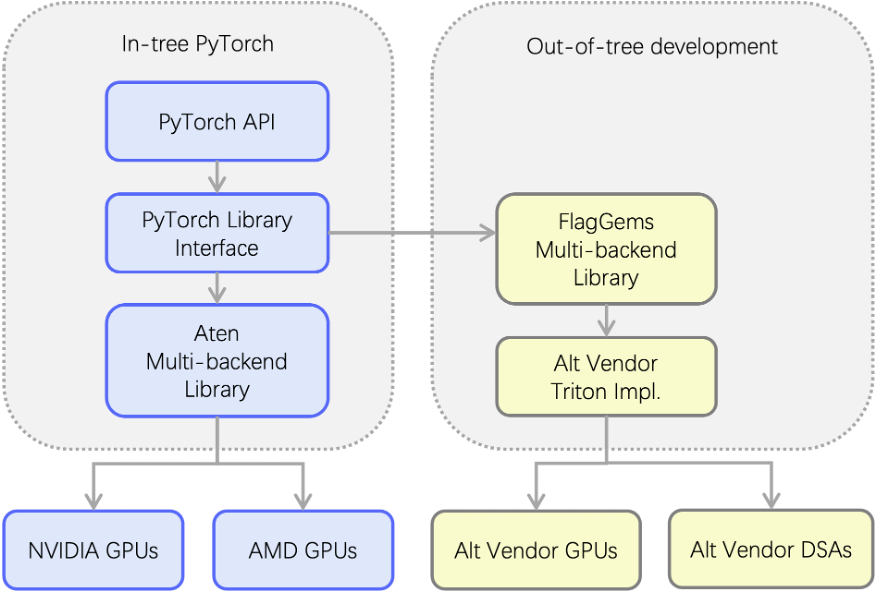
FlagGems 通过一个由 Triton 提供支持的多后端库,将 PyTorch 调度系统扩展到树外。它拦截 ATen 运算符调用并提供特定于后端的 Triton 实现,从而轻松支持替代 GPU 和领域特定加速器 (DSA)。
即插即用
- 注册到 PyTorch 的调度系统
- 拦截 ATen 运算符调用
- 无缝替换 CUDA 运算符实现
一次编写,随处编译
- 统一的运算符库代码
- 可在任何支持 Triton 的后端上编译
- 支持 GPU 和 DSA 等异构芯片
3 步快速入门
1. 安装依赖项
pip install torch>=2.2.0 # 2.6.0 preferred pip install triton>=2.2.0 # 3.2.0 preferred
2. 安装 FlagGems
git clone https://github.com/FlagOpen/FlagGems.git cd FlagGems pip install --no-build-isolation . or editable install: pip install --no-build-isolation -e .
3. 在项目中启用 FlagGems
import flag_gems flag_gems.enable() # Replaces supported PyTorch ops globally
喜欢更精细的控制?使用托管上下文
with flag_gems.use_gems(): output = model.generate(**inputs)
需要显式运算符?
out = flag_gems.ops.slice_scatter(inp, dim=0, src=src, start=0, end=10, step=1)
逐点运算符的自动代码生成
使用 @pointwise_dynamic 装饰器,FlagGems 可以自动生成支持广播、融合和内存布局的高效内核。以下是一个实现融合 GeLU 和逐元素乘法的示例:
@pointwise_dynamic(promotion_methods=[(0, 1, “DEFAULT”)]) @triton.jit
def gelu_tanh_and_mul_kernel(x, y): x_fp32 = x.to(tl.float32) x_gelu = 0.5 * x_fp32 * (1 + tanh(x_fp32 * 0.79788456 * (1 + 0.044715 * pow(x_fp32, 2)))) return x_gelu * y
性能验证
FlagGems 包含内置测试和基准测试
- 准确性测试
cd tests pytest test_<op_name>_ops.py --ref cpu
- 性能基准
cd benchmark pytest test_<op_name>_perf.py -s # CUDA microbenchmarks pytest test_<op_name>_perf.py -s --mode cpu # End-to-end comparison
基准测试结果
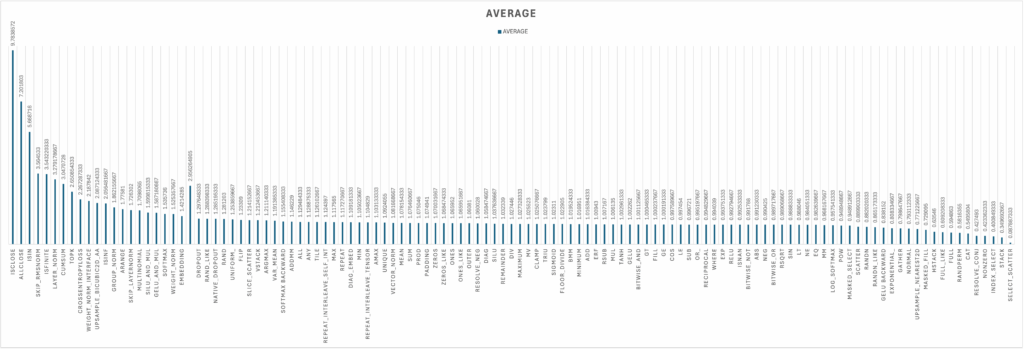
FlagGems 的初始基准测试结果展示了其与 PyTorch 原生运算符实现相比的性能。结果表示平均测得的加速比,大于 1 的值表示 FlagGems 比 PyTorch 原生运算符更快。对于绝大多数运算符,FlagGems 要么与 PyTorch 原生实现的性能持平,要么显著超越。
对于 180 多个运算符中的很大一部分,FlagGems 实现了接近 1.0 的加速比,表明性能与 PyTorch 原生实现相当。
一些核心操作,如 LAYERNORM、CROSS_ENTROPY_、ADDMM 和 SOFTMAX 也显示出令人印象深刻的加速比。
多后端支持
FlagGems 具有供应商灵活性和后端感知能力
使用以下方式设置所需的后端
export GEMS_VENDOR=<vendor>
在 Python 中检查活动后端
import flag_gems print(flag_gems.vendor_name)

总结
FlagGems 为大型模型加速提供了一个统一的内核库,弥合了软件可移植性和硬件性能之间的差距。凭借广泛的后端支持、不断增长的运算符集和先进的代码生成功能,它是您推动 AI 计算极限的首选 Triton 游乐场。