我们演示了如何使用 LoRA 以及 PyTorch 和 Hugging Face 生态系统中的工具,在典型的消费级 GPU(NVIDIA T4 16GB)上微调一个 7B 参数的模型,并提供了完整的可复现的 Google Colab 笔记本。
引言
大型语言模型 (LLM) 在工业应用中展现出令人印象深刻的能力。通常,开发者会寻求为特定用例和应用调整这些 LLM,以对其进行微调以获得更好的性能。然而,LLM 在设计上就很大,需要大量的 GPU 才能进行微调。
让我们以一个具体的例子来聚焦:尝试在免费的 Google Colab 实例(1x NVIDIA T4 16GB)上微调 Llama 模型。Llama-2 7B 拥有 70 亿个参数,如果以全精度加载模型,总大小为 28GB。考虑到我们 GPU 的内存限制(16GB),模型甚至无法加载,更不用说在我们的 GPU 上进行训练了。通过可忽略不计的性能下降,内存需求可以减少一半。您可以在此处阅读更多关于以半精度和混合精度运行模型进行训练的信息 此处。
是什么让我们的 Llama 微调成本高昂?
在使用 Adam 优化器进行全量微调,并采用半精度模型和混合精度模式时,每个参数需要分配:
- 2 字节用于权重
- 2 字节用于梯度
- 4 + 8 字节用于 Adam 优化器状态
→ 每个可训练参数总共需要 16 字节,这使得总内存达到 112GB (不包括中间隐藏状态)。考虑到目前最大的 GPU 最多拥有 80GB GPU 显存,这使得微调变得具有挑战性,并且对所有人来说都不太容易实现。为了弥合这一差距,参数高效微调 (PEFT) 方法如今已被社区广泛采用。
参数高效微调 (PEFT) 方法
PEFT 方法旨在大幅减少模型的可训练参数数量,同时保持与完全微调相同的性能。
它们可以根据其概念框架进行区分:该方法是微调现有参数的子集、引入新参数、引入可训练提示等?我们建议读者查阅下面分享的论文,该论文详细比较了现有的 PEFT 方法。
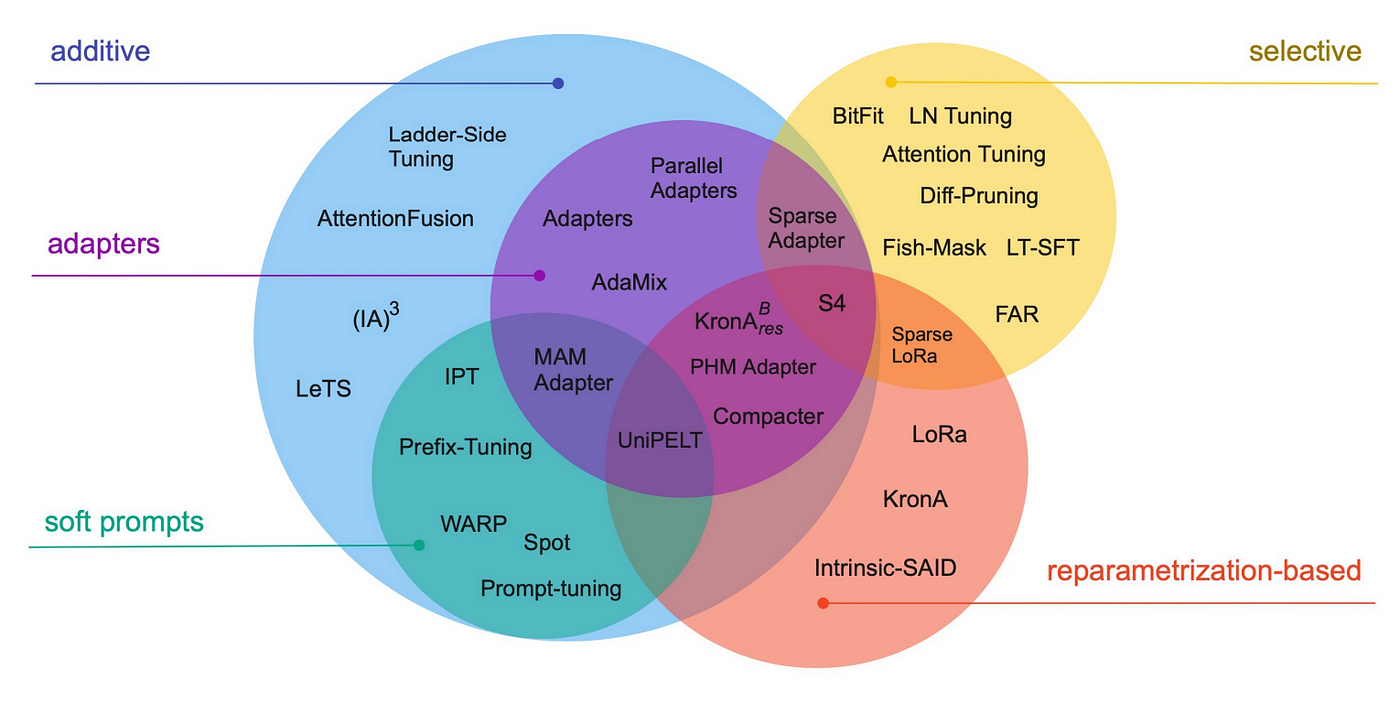
图片取自论文: 从小到大:参数高效微调指南
对于这篇博客文章,我们将重点关注大型语言模型的低秩适应 (LoRA),因为它是社区中最广泛采用的 PEFT 方法之一。
使用 🤗 PEFT 进行大型语言模型的低秩适应 (LoRA)
LoRA 方法由 Microsoft 团队的 Hu 等人于 2021 年提出,其工作原理是在模型(我们将其称为基模型)中附加额外的可训练参数。
为了使微调更高效,LoRA 将一个大型权重矩阵分解为两个较小的、低秩的矩阵(称为更新矩阵)。这些新矩阵可以被训练以适应新数据,同时保持整体变化量较低。原始权重矩阵保持冻结状态,不再进行任何调整。为了产生最终结果,原始权重和适应后的权重会结合在一起。
这种方法有几个优点:
- LoRA 通过大幅减少可训练参数的数量,使微调更高效。
- 原始的预训练权重保持冻结,这意味着您可以拥有多个轻量级且可移植的 LoRA 模型,用于各种下游任务,这些模型都构建在原始权重之上。
- LoRA 与许多其他参数高效方法正交,并且可以与其中许多方法结合使用。
- 使用 LoRA 微调的模型性能与完全微调模型的性能相当。
- 当适配器权重与基础模型合并时,LoRA 不会增加任何推理延迟。
原则上,LoRA 可以应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。然而,为了简化和进一步提高参数效率,在 Transformer 模型中,LoRA 通常仅应用于注意力模块。LoRA 模型中可训练参数的最终数量取决于低秩更新矩阵的大小,这主要由秩 r 和原始权重矩阵的形状决定。
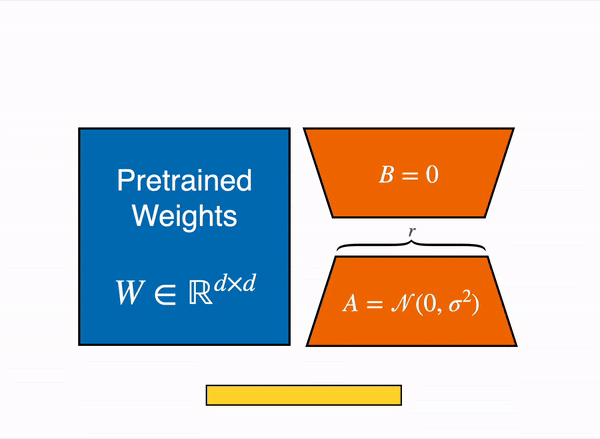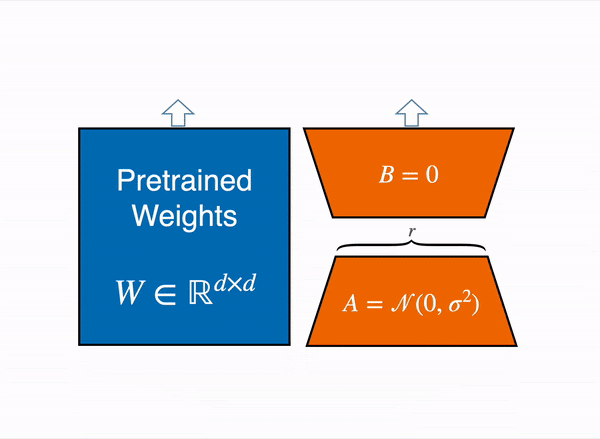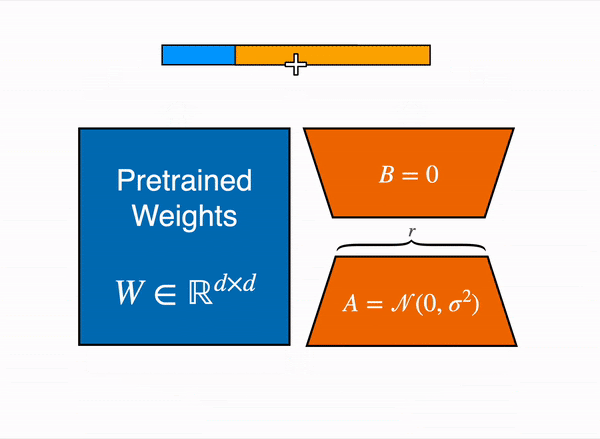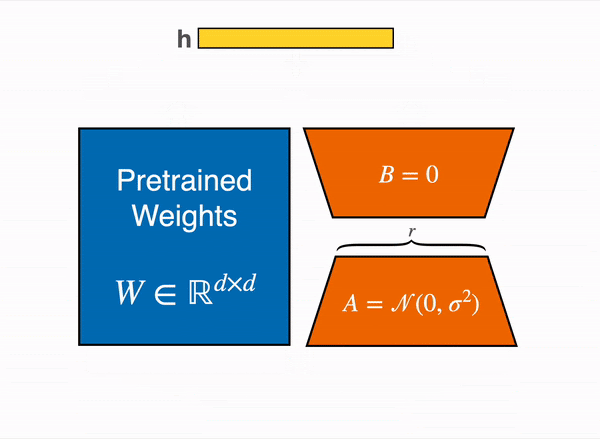
动态图展示 LoRA 在实践中如何工作——原始内容改编自 LoRA 原始论文图 1
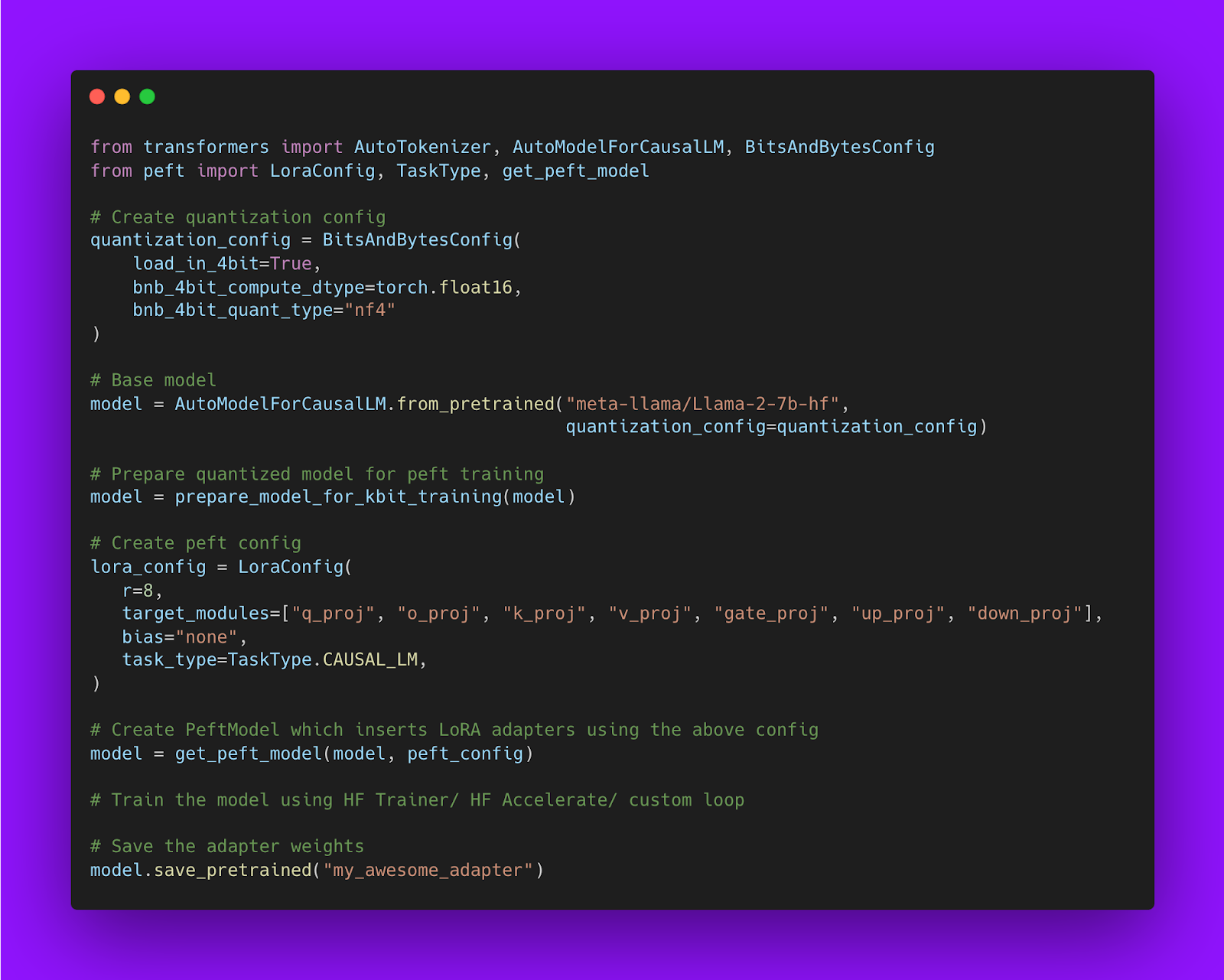
下面是显示如何使用 Hugging Face PEFT 库训练 LoRA 模型的代码片段
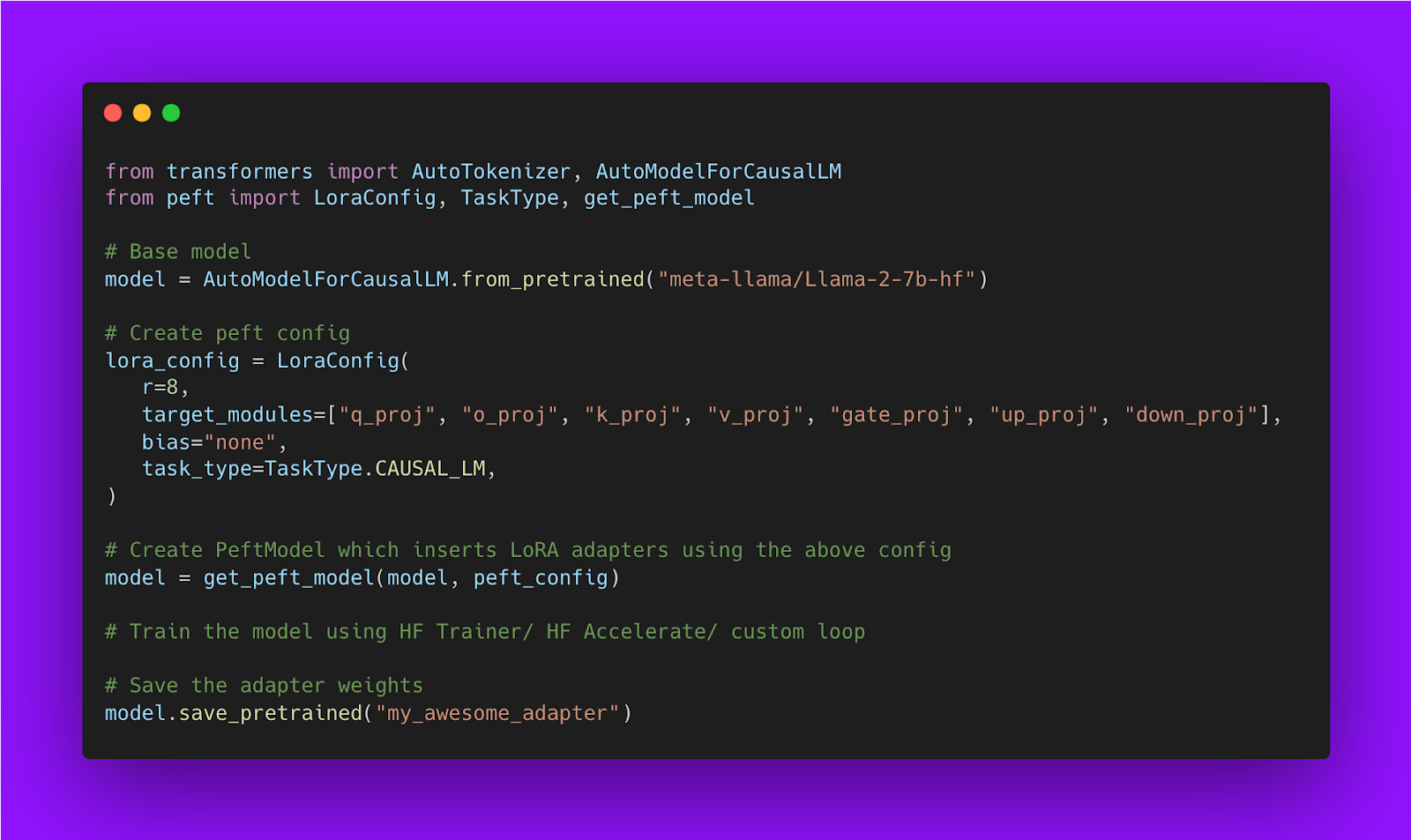
基模型可以是任何 dtype:利用 SOTA LLM 量化并将基模型加载为 4 位精度
根据 LoRA 的公式,只要基础模型中的隐藏状态与 LoRA 矩阵输出的隐藏状态具有相同的 dtype,基础模型就可以以任何数据类型('dtype')进行压缩。
压缩和量化大型语言模型最近成为一个热门话题,因为 SOTA 模型变得越来越大,越来越难以服务和供终端用户使用。社区中的许多人提出了各种方法,可以在性能下降最小的情况下有效压缩 LLM。
这就是 bitsandbytes 库的作用。它的目的是让 Tim Dettmers(一位在量化和深度学习硬件加速器使用方面的领先学术专家)的尖端研究普惠大众。
QLoRA:bitsandbytes 为人工智能民主化做出的核心贡献之一
LLM 的量化主要集中在推理量化上,但 QLoRA (量化模型权重 + 低秩适配器)论文展示了在大规模模型上,通过冻结的量化权重进行反向传播的突破性效用。
通过 QLoRA,我们可以在所有规模和模型上实现 16 位微调性能,同时将微调内存占用减少 90% 以上——从而允许在消费级硬件上微调 SOTA 模型。
在这种方法中,LoRA 对于微调和纠正微小残余量化误差都至关重要。由于量化模型尺寸显著缩小,可以在每个网络层慷慨地放置低秩适配器,这些适配器加起来仍然只占原始模型权重内存足迹的 0.2%。通过这种 LoRA 的使用,我们实现了与 16 位全模型微调相当的性能。
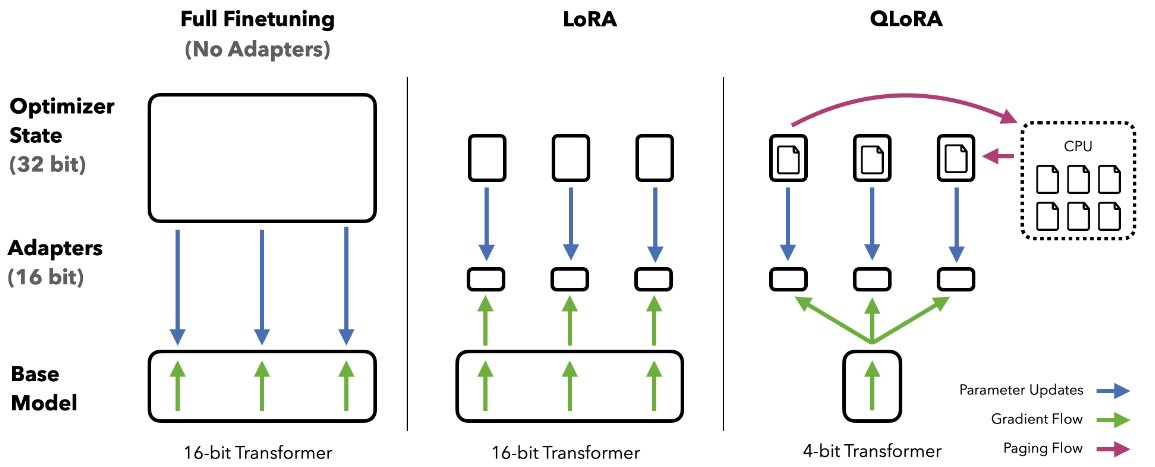
除了慷慨地使用 LoRA 之外,为了实现 4 位模型的高保真微调,QLoRA 还使用了另外 3 种算法技巧:
- 4 位 NormalFloat (NF4) 量化,一种自定义数据类型,利用模型权重正态分布的特性,并将相同数量的权重(每个块)分配到每个量化桶中——从而增强信息密度。
- 双重量化,即对量化常数进行量化(进一步节省)。
- 分页优化器,防止梯度检查点期间的内存峰值导致内存不足错误。
一个有趣的方面是在 GPU 缓存中对 4 位权重进行去量化,矩阵乘法作为 16 位浮点运算执行。换句话说,我们使用一个 低精度存储数据类型 (在我们的例子中是 4 位,但原则上可互换)和一个正常精度 计算数据类型。这很重要,因为后者出于硬件兼容性和数值稳定性原因默认为 32 位, 但对于支持它的新硬件,应设置为最佳 BFloat16 以实现最佳性能。
总而言之,通过结合这些对量化过程的改进和慷慨使用 LoRA,我们将模型压缩了 90% 以上,并在没有通常的量化退化的前提下保持了完整的模型性能,同时还保留了在每一层使用 16 位 LoRA 适配器的完整微调能力。
QLoRA 的实际应用
这些 SOTA 量化方法都打包在 bitsandbytes 库中,并与 HuggingFace 🤗 Transformers 方便地集成。例如,要分别使用 LLM.int8 和 QLoRA 算法,只需将 load_in_8bit 和 load_in_4bit 传递给 from_pretrained 方法。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-125m"
# For LLM.int8()
# model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True)
# For QLoRA
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
您可以在文档的这个特定部分阅读更多关于量化功能的信息: https://hugging-face.cn/docs/transformers/main_classes/quantization
当使用 QLoRA 和 Adam 优化器,以及 4 位基础模型和混合精度模式时,每个参数需要分配:
- 约 0.5 字节用于权重
- 2 字节用于梯度
- 4 + 8 字节用于 Adam 优化器状态
每个可训练参数总共 14 字节,乘以 0.0029,因为使用 QLoRA 最终只有 0.29% 的可训练参数,这使得 QLoRA 训练设置成本约为 4.5GB 来适应,但实际上需要约 7-10GB 来包含始终为半精度的中间隐藏状态(序列长度为 512 时为 7 GB,序列长度为 1024 时为 10GB),这在下一节中分享的 Google Colab 演示中有所体现。
下面是使用 Hugging Face PEFT 训练 QLoRA 模型的代码片段
使用 TRL 进行 LLM 训练
ChatGPT、GPT-4 和 Claude 等模型是强大的语言模型,它们通过一种名为“人类反馈强化学习 (RLHF)”的方法进行了微调,以便更好地与我们期望它们表现和希望使用它们的方式保持一致。微调过程分 3 个步骤进行:
- 监督微调 (SFT)
- 奖励/偏好建模 (RM)
- 人类反馈强化学习 (RLHF)
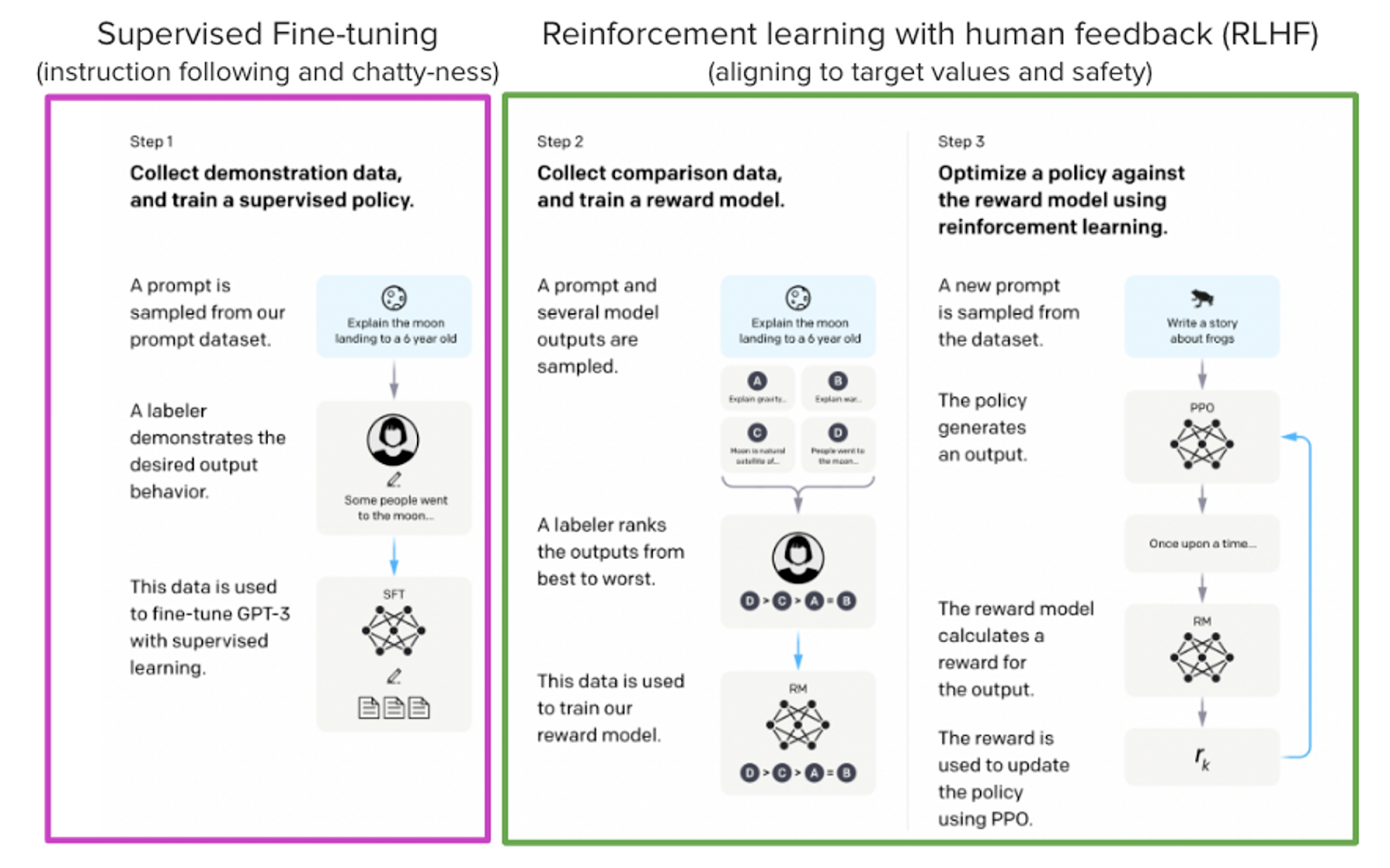
摘自 InstructGPT 论文:Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022)。
这里,我们将只关注监督微调步骤。我们按照类似于预训练的过程在新数据集上训练模型。目标是预测下一个 token(因果语言建模)。可以应用多种技术来提高训练效率:
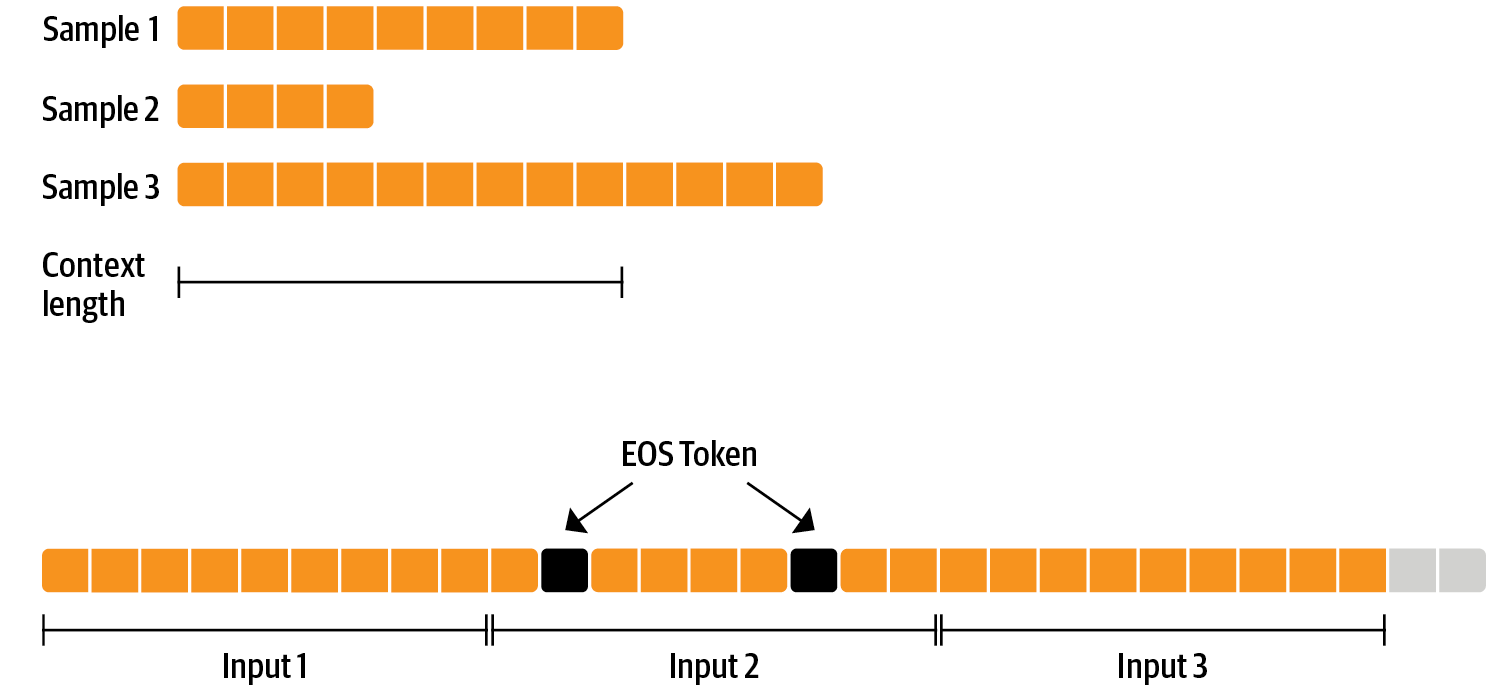
- 打包 (Packing):与批处理中每个样本一个文本,然后填充到最长文本或模型的最大上下文不同,我们将许多文本与句末 (EOS) token 连接起来,并截取上下文大小的块来填充批处理,而无需任何填充。这种方法显著提高了训练效率,因为模型处理的每个 token 都对训练有贡献。
- 仅对完成部分进行训练:我们希望模型能够理解提示并生成答案。与其对整个输入(提示 + 答案)进行训练,如果只对完成部分进行训练,训练效率会更高。
您可以使用 SFTTrainer 结合这些技术进行监督微调。
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
packing=True,
)
由于 SFTTrainer 的后端由 🤗accelerate 提供支持,您可以通过一行代码轻松调整训练以适应您的硬件设置!
例如,如果您有 2 个 GPU,可以使用以下命令执行分布式数据并行训练:
accelerate launch --num_processes=2 training_llama_script.py
将所有部分整合在一起
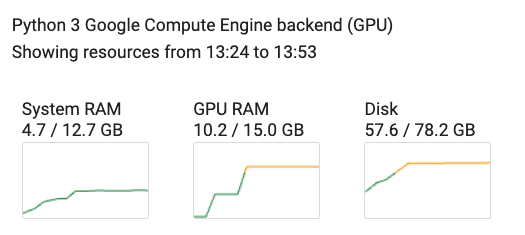
我们制作了一个完整的可复现的 Google Colab 笔记本,您可以通过 此链接查看。我们使用了上面各节中分享的所有组件,并使用 QLoRA 在 UltraChat 数据集上微调了一个 llama-7b 模型。从下面的截图可以看出,当使用序列长度为 1024 且批处理大小为 4 时,内存使用量仍然非常低(约 10GB)。