合作者:Less Wright、Howard Huang、Chien-Chin Huang,Crusoe:Martin Cala, Ethan Petersen
摘要:我们使用torchft和torchtitan在真实世界环境中以极高的合成故障率训练模型,以证明容错训练的可靠性和正确性。
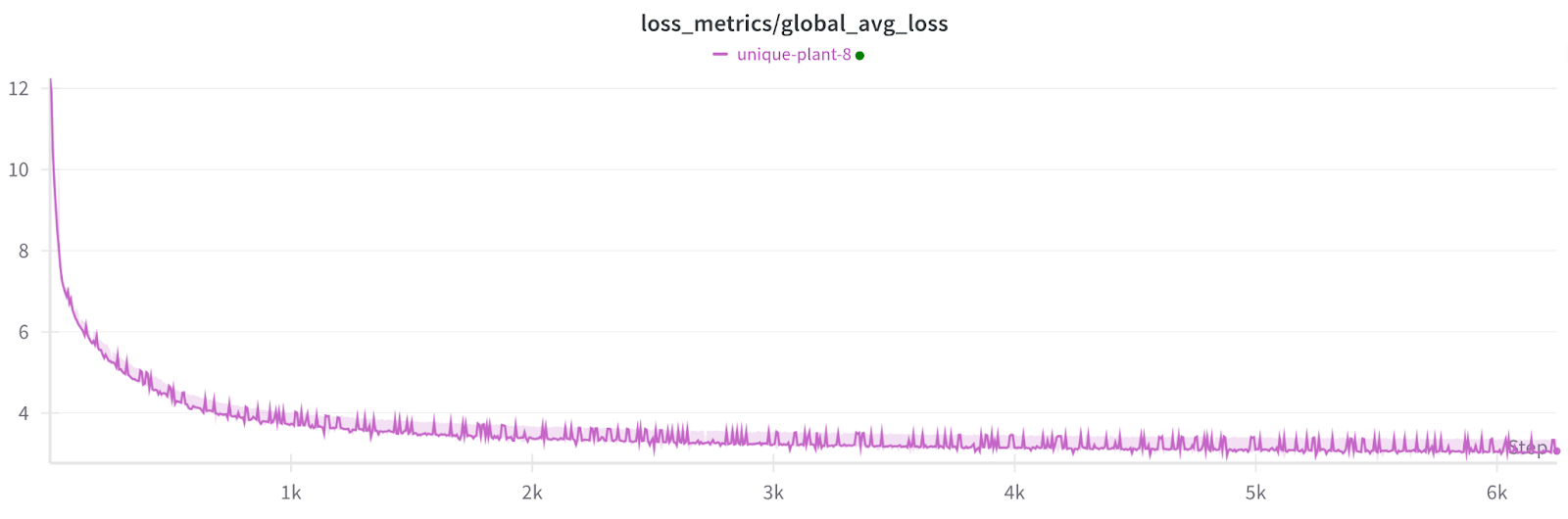
在1200次故障且无检查点情况下的训练损失。
注意:每个小尖峰都是一个非参与工作器恢复,这会影响指标但不会影响模型。
引言
我们希望通过运行具有尽可能极端故障率的训练作业,在最坏情况下演示torchft。
大多数LLM预训练使用分片模型,采用FSDP。torchft通过HSDP2支持分片模型,HSDP2将分片模型与来自torchft的容错DDP all reduce结合起来。我们已将torchft集成到torchtitan中,因此您可以开箱即用地使用容错功能。torchft+titan还支持每个副本组内的其他分片/并行化,例如张量并行化(TP)、流水线并行化(PP)等。
这是使用torchft的训练作业结构
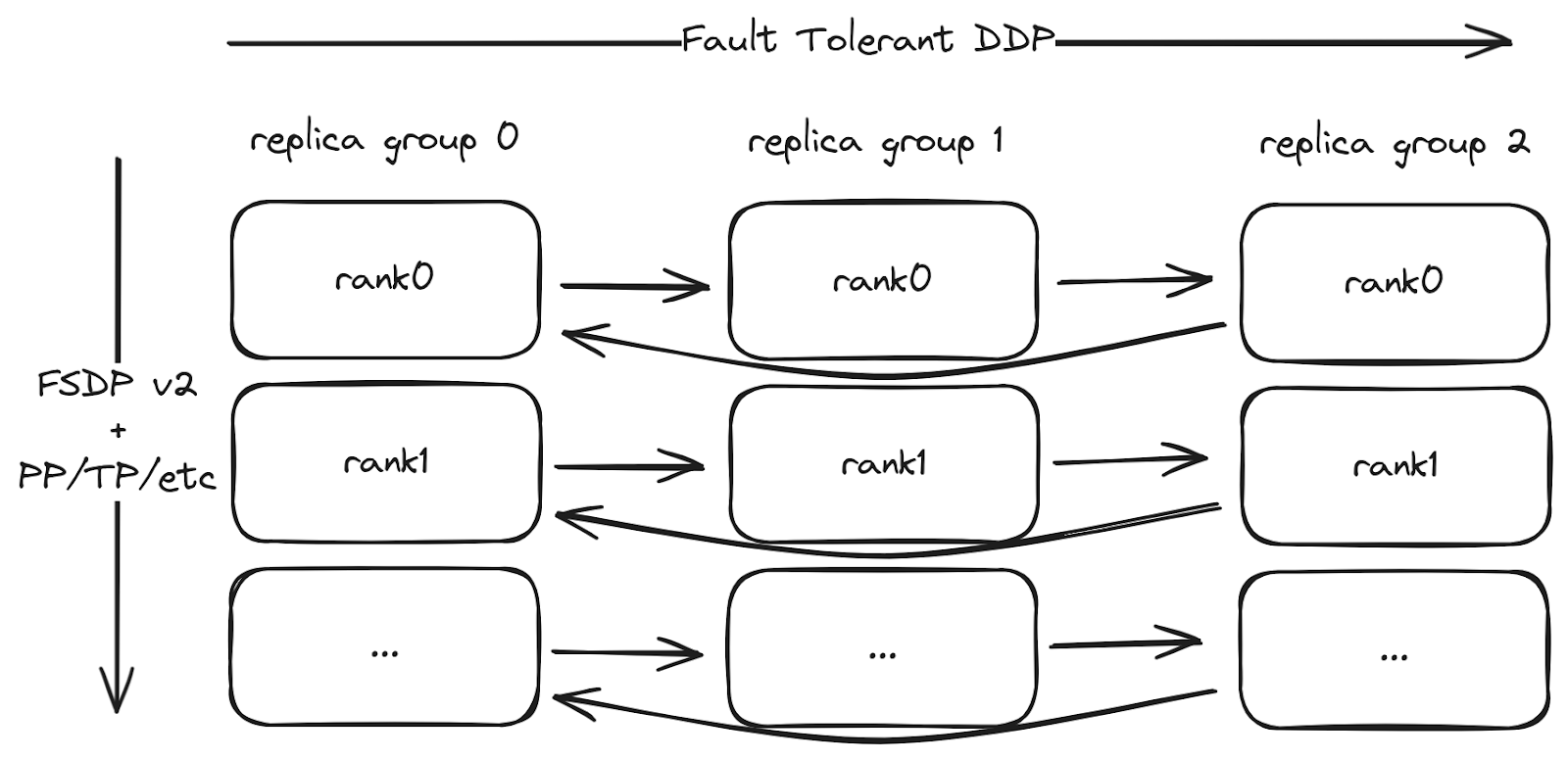
训练作业的结构。torchft的容错DDP实现在副本组之间用于同步梯度。每个副本组内使用标准的FSDP2和其他并行化。
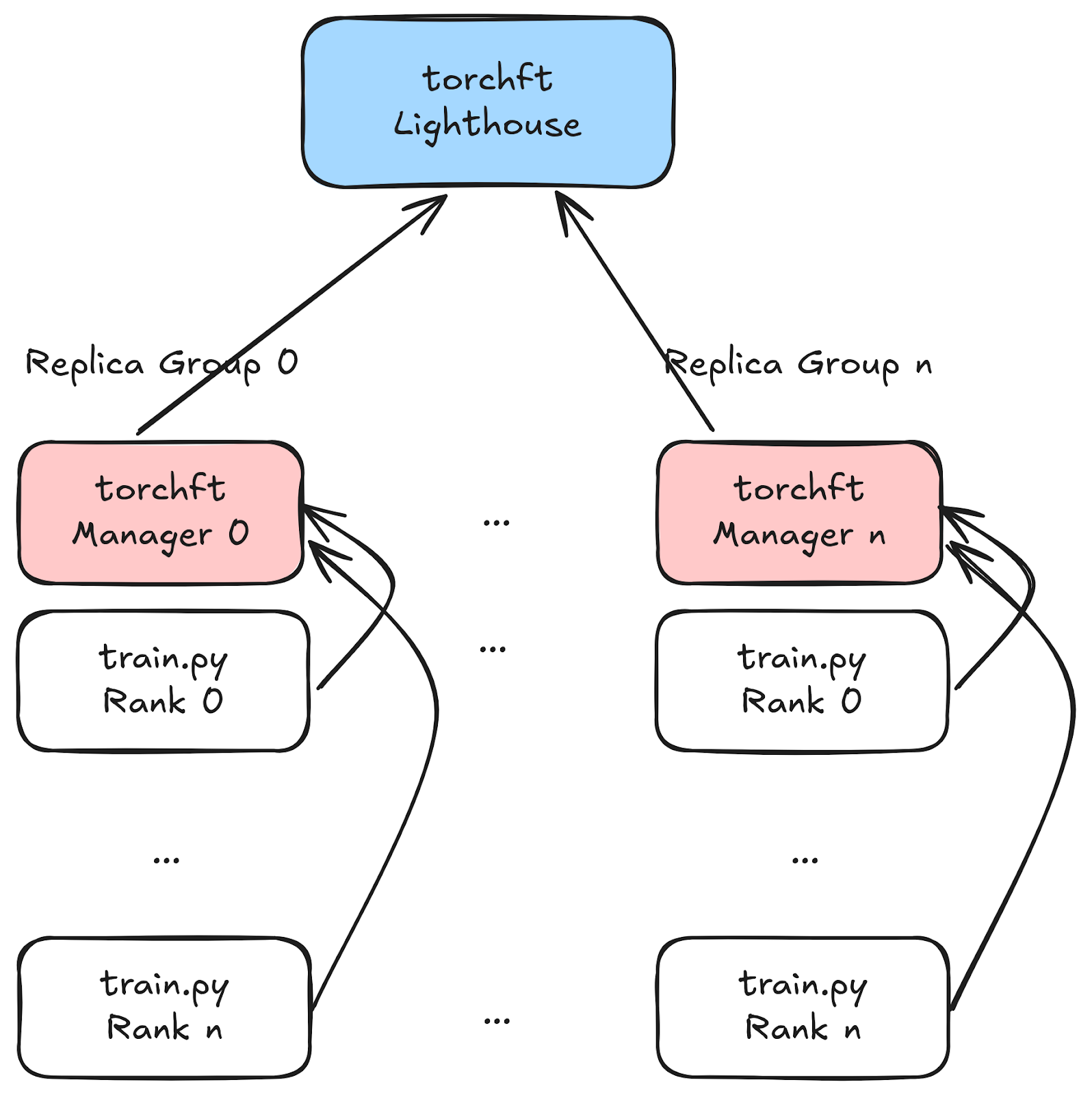
torchft使用一个全局Lighthouse服务器和每个副本组的管理器来进行工作器的实时协调。Lighthouse通过心跳了解所有工作器的状态以及哪些工作器是健康的。
torchft实现了几种不同的容错算法。其中两个最主要的是
- 容错HSDP:FSDPv2的扩展,使用容错all-reduce。这完全模拟了标准的HSDP训练,每步进行梯度all_reduce和每步容错。这最适用于具有快速后端网络(如infiniband)的大规模训练。
- LocalSGD/DiLoCo:半同步训练的容错实现。这些算法通过在指定间隔而不是像HSDP那样每步同步来最小化通信开销。这通常用于通信受限的训练场景,例如通过以太网/TCP或在地理上分离的位置(联邦学习或多数据中心训练)。
我们一直在关注新算法,例如我们即将支持流式DiLoCo。如果您有新的用例希望合作,请联系我们!
集群设置
Crusoe慷慨地借给我们一个包含300个L40S GPU的集群。GPU分布在30台主机上,每台主机配备10个NVIDIA L40S GPU。
对于模型,我们使用torchtitan和具有1B参数的Llama 3模型以匹配可用硬件。
NVIDIA L40S GPU通常用于推理,因此为我们提供了一个在非传统环境中测试torchft的机会,在这种环境中,由于较低的纯TCP(无infiniband/nvlink)网络瓶颈,DiLoCo等功能真正发挥作用。L40S具有48GB的VRAM(更接近消费级GPU),因此我们使用了较小的模型和批次大小。训练的平均步长约为9秒。
为了最大限度地提高有限网络的性能,我们以30x1x10的配置训练模型。我们有30个副本组(容错域),每个组有1台主机和10个GPU/工作器。torchft可以在每个副本组中拥有许多主机,但对于这个集群,由于网络带宽有限,每个副本组的单个主机/10个GPU性能最佳。我们运行了30个副本组,因为更多的组会给协调和重新配置算法带来更大的压力。
对于网络通信,我们在每个副本组内使用NCCL进行所有通信(即FSDP),并使用Gloo进行跨副本组通信。Gloo虽然性能通常不如NCCL,但初始化速度快得多,并且失败检测速度也快得多,这对于快速检测故障很重要。torchft确实支持在NCCL下实现IB集群的容错功能,但有一些注意事项,在此次演示中未使用。由于我们希望最大化故障和恢复的总次数,因此我们使用Gloo,因为在我们的用例中,它可以在小于1秒的时间内重新初始化,并且我们能够将所有操作的超时时间设置为5秒。
对于容错算法,我们主要使用容错HSDP进行测试,因为它对通信和仲裁层施加的压力最大。对于最终测试,我们使用了DiLoCo,它更适合基于以太网的集群。
无需检查点即可恢复
传统的机器学习通过在发生错误时从检查点重新加载来实现“容错”。这涉及一个完整的“停止一切”操作,所有工作器重新启动并从最近持久化的检查点加载。
有了torchft,我们转而专注于将故障隔离到独立的GPU组。当该组内发生错误时,我们可以异步重启该组,所有其他组可以重新配置并继续训练而无需该组。
当该组通过重启恢复或调度程序替换机器时,这些工作器将不再拥有有效的权重和优化器状态副本。如果尝试从检查点恢复,其他组已经继续前进。相反,我们依赖于运行时异步权重传输。这会从健康的副本进行点对点权重传输。
由于我们总是从另一个工作器恢复——事实证明,只要我们能保证至少有一个组是健康的,我们实际上就不需要任何检查点。为了这次演示,我们完全关闭了检查点,因为持久的检查点保存和加载比我们的P2P恢复时间长得多。
这里显示了一个图表,展示了正在恢复的副本(副本1)如何加入仲裁并从健康的对等体(副本0)恢复,而不会造成任何停机或影响健康的工人训练。
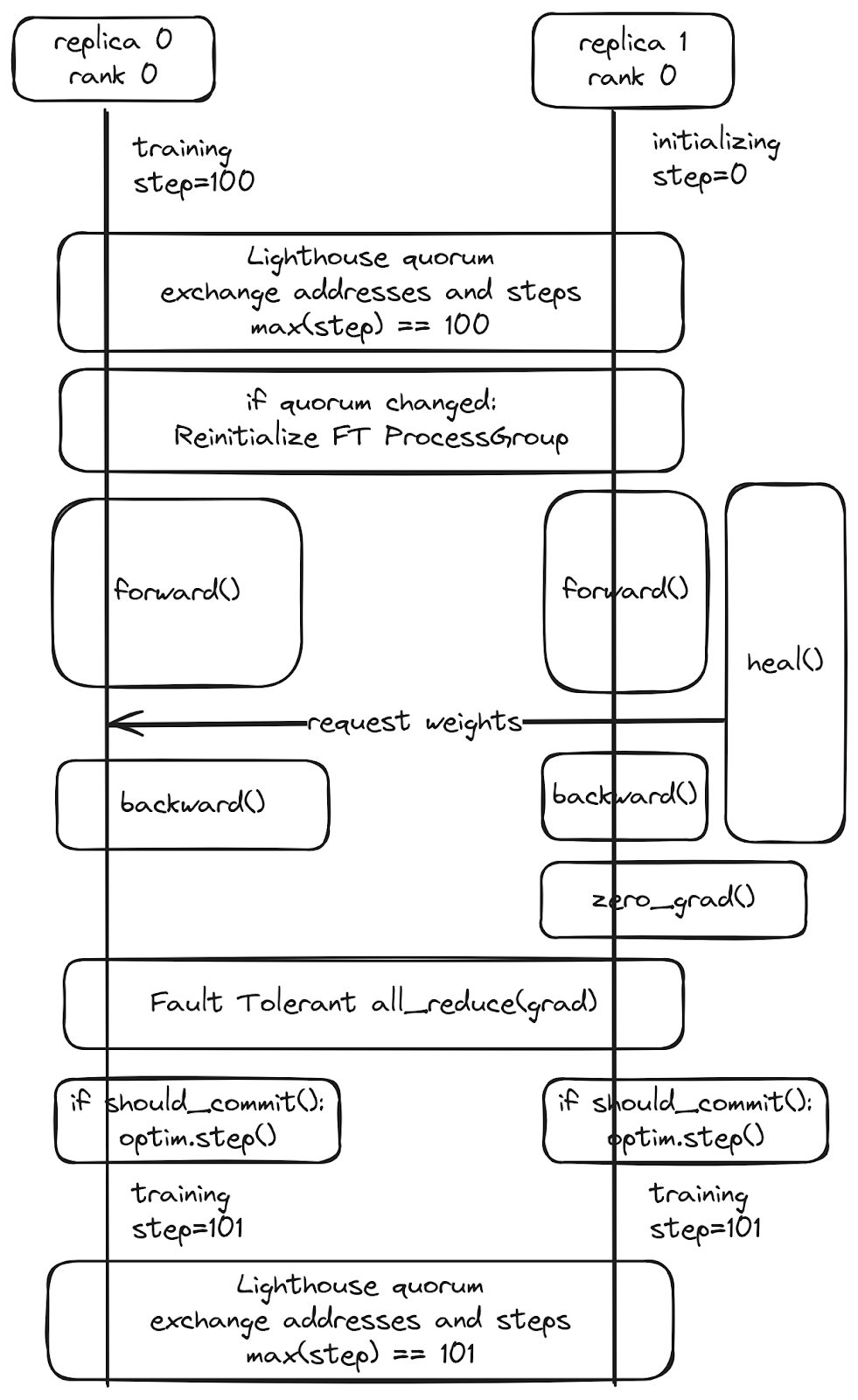
torchft借鉴了分布式数据库的许多概念。
- 仲裁操作通过频繁的心跳确定哪些工作器是健康的,并确保我们能够快速确定哪些工作器处于活动状态,以容错方式交换元数据,并强制执行无脑裂条件。
- 为了确保一致性并确定何时需要恢复工作器,我们有效地使用传统数据库语义处理训练。传统数据库使用“事务”,其中每个操作要么提交(完全应用),要么回滚(丢弃)。torchft以同样的方式处理每个训练步骤。副本组中的每个训练步骤都被视为一个分布式事务,我们通过执行优化器来确保所有工作器提交该步骤,或者如果发生错误,它们都通过丢弃梯度来回滚。
欲了解更多详情,请参阅torchft README,其中包含文档、设计文档和演示的链接。
训练循环集成
TorchFT已经与TorchTitan集成,因此,启用它只需设置一个配置标志。对于典型的模型,torchft提供了包装器,这些包装器自动调用torchft管理器中的钩子以提供容错功能。
from torchft import Manager, DistributedDataParallel, Optimizer, ProcessGroupGloo # Instantiate your model and optimizer as normal m = nn.Linear(2, 3) optimizer = optim.AdamW(m.parameters()) # Setup torchft Manager and wrap the model and optimizer. manager = Manager( pg=ProcessGroupGloo(), load_state_dict=lambda state_dict: m.load_state_dict(state_dict), state_dict=lambda: m.state_dict(), ) m = DistributedDataParallel(manager, m) optimizer = Optimizer(manager, optimizer) for batch in dataloader: # When you call zero_grad, we start the asynchronous quorum operation # and perform the async weights recovery if necessary. optimizer.zero_grad() out = m(batch) loss = out.sum() # The gradient allreduces will be done via torchft's fault tolerant # ProcessGroupGloo wrapper. loss.backward() # The optimizer will conditionally step depending on if any errors occured. # The batch will be discarded if the gradient sync was interrupted. optimizer.step()
容错调度
我们可以使用标准的ML作业调度程序(如Slurm),因为副本组内工作器的语义与普通作业相同。如果组内任何工作器发生错误,我们预计整个组会同时重启。在每个副本组内,应用程序是一个完全标准的训练作业,使用标准的非容错操作。
为了在传统调度程序上实现容错,我们运行多个这样的作业。每个副本组都在Slurm上作为一个独立的训练作业运行,Lighthouse和监控脚本在主节点上运行。所有跨组通信都通过torchft管理的ProcessGroup和仲裁API完成。为了在故障时重新启动组并注入故障,我们使用了torchx Python API的一个小脚本。
监控脚本看起来像这样:
from torchx.runner import get_runner NUM_REPLICA_GROUPS = 30 with get_runner() as runner: while True: jobs = runner.list(scheduler) active_replicas = { parse_replica_id(job.name) for job in jobs if not job.is_terminal() } missing_replicas = set(range(NUM_REPLICA_GROUPS)) - active_replicas for replica_id in missing_replicas: app_def = make_app_def(replica_id=replica_id) app_handle = runner.run( app_def, scheduler="slurm", cfg={"partition": "batch"}, ) print("launched:", replica_id, app_handle) time.sleep(5.0)
通过使用`scancel`取消特定副本组的Slurm作业来注入故障。在实际场景中,我们期望故障是由训练过程中的错误触发,这将导致该副本组独立崩溃,而不是外部故障。
指标和日志
为了确保我们对作业有统一的视图,我们避免向单个副本组注入故障,以简化对作业指标和仲裁事件的跟踪。该组能够持续记录参与者数量、步骤成功/失败和损失。
由于我们正在进行每步容错,因此参与者数量和批处理大小会根据哪些工作器健康而每步发生变化。
损失通过副本组之间的allreduce操作,对作业中所有工作器/副本组进行平均。
注意:下面损失图中小的尖峰是由于我们对所有主机(包括恢复中的工作器,它们具有过时的权重)的损失进行平均,这导致在这些步骤中损失错误地更高。
运行
我们运行了三个不同的测试,展示了torchft的各种故障场景和功能。
运行1:每60秒注入一次故障,共1100次故障
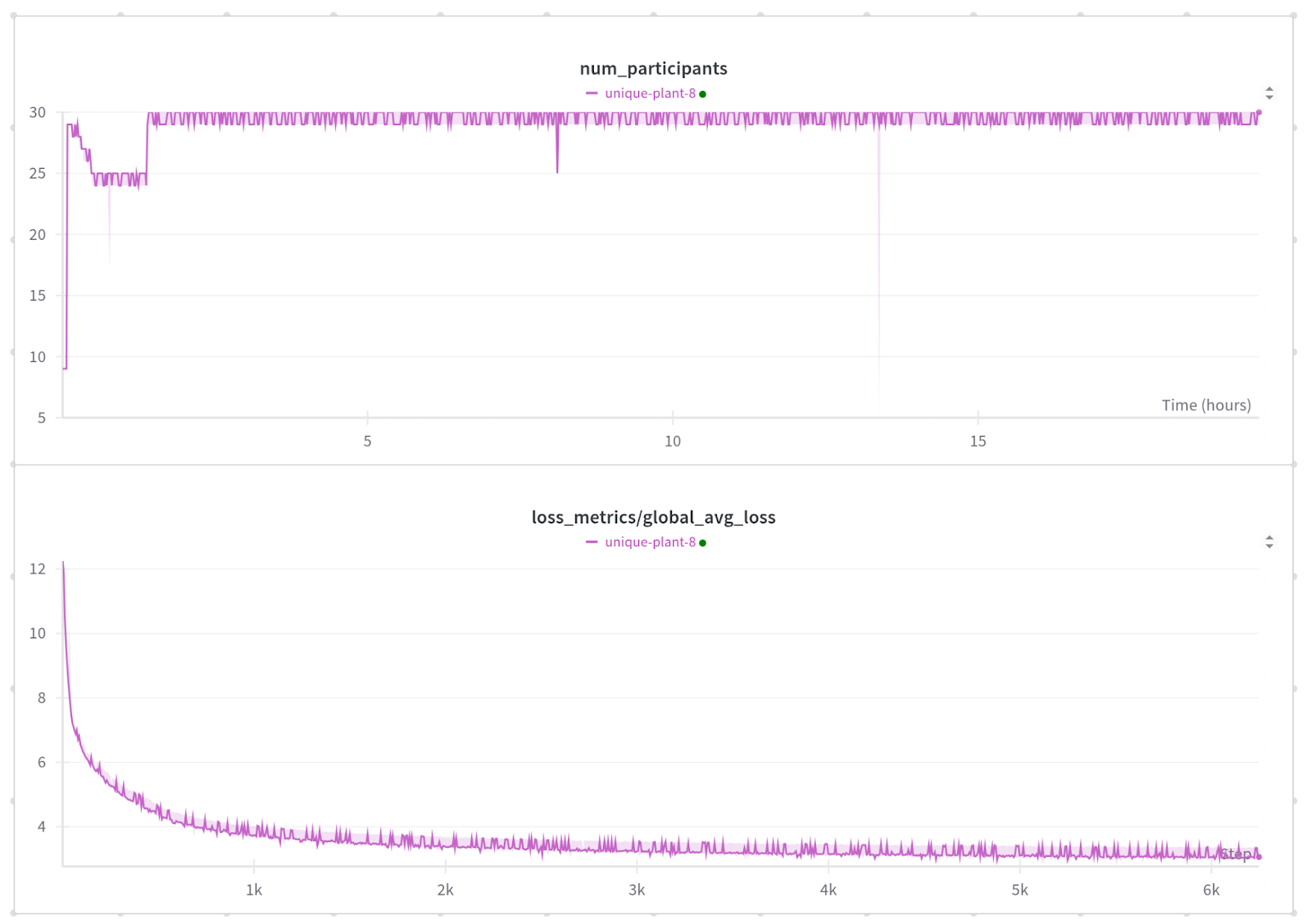
这次运行持续了超过19小时,共6249步。平均而言,每一步耗时10.9秒。
对于最初的运行,我们每60秒以非常可重复的模式注入一次故障。我们最初集群中有一台坏机器,因此我们短暂地将世界规模缩小到25台主机,直到机器被替换,然后我们以零停机时间将作业扩展回来。
每60秒发生一次故障,我们预计在每次故障之间能够完成约5个步骤而不会出现任何问题。从结果来看,我们看到有6249个步骤和5145次成功提交。torchft旨在尽可能安全,如果发生任何错误,它将在运行优化器之前通过“should_commit”丢弃该步骤。
对于整体步骤效率,我们有:
5145次成功步骤 / 6249次总步骤 = 82.3%
在步长约为11秒,每60秒发生一次故障的情况下,我们应该能够完成每6步中的5步(83.3%),这与测量性能几乎完全匹配。
我们平均每步有29.6个参与的副本组,因此总训练效率为81.2%。对于超过1000次故障来说,这个结果还不错。
运行2:每15秒注入一次故障,共1015次故障
我们想看看我们还能推进到什么程度,并使其更具挑战性。对于第二次运行,我们以0-30秒的间隔注入故障,平均每15秒一次故障。
与通常平均故障间隔在10分钟到数小时的训练作业相比,这种故障率是极端的,但这让我们能够验证无论何时发生错误,我们都能恢复,并让我们进行大量测试循环,以增强对我们实现的信心。
通过随机化故障间隔,我们使得故障发生在工作器仍在初始化而不是处于稳定状态时,并且更有可能触及边缘情况。我们很高兴地报告,torchft表现如预期,没有发生不可恢复的错误。
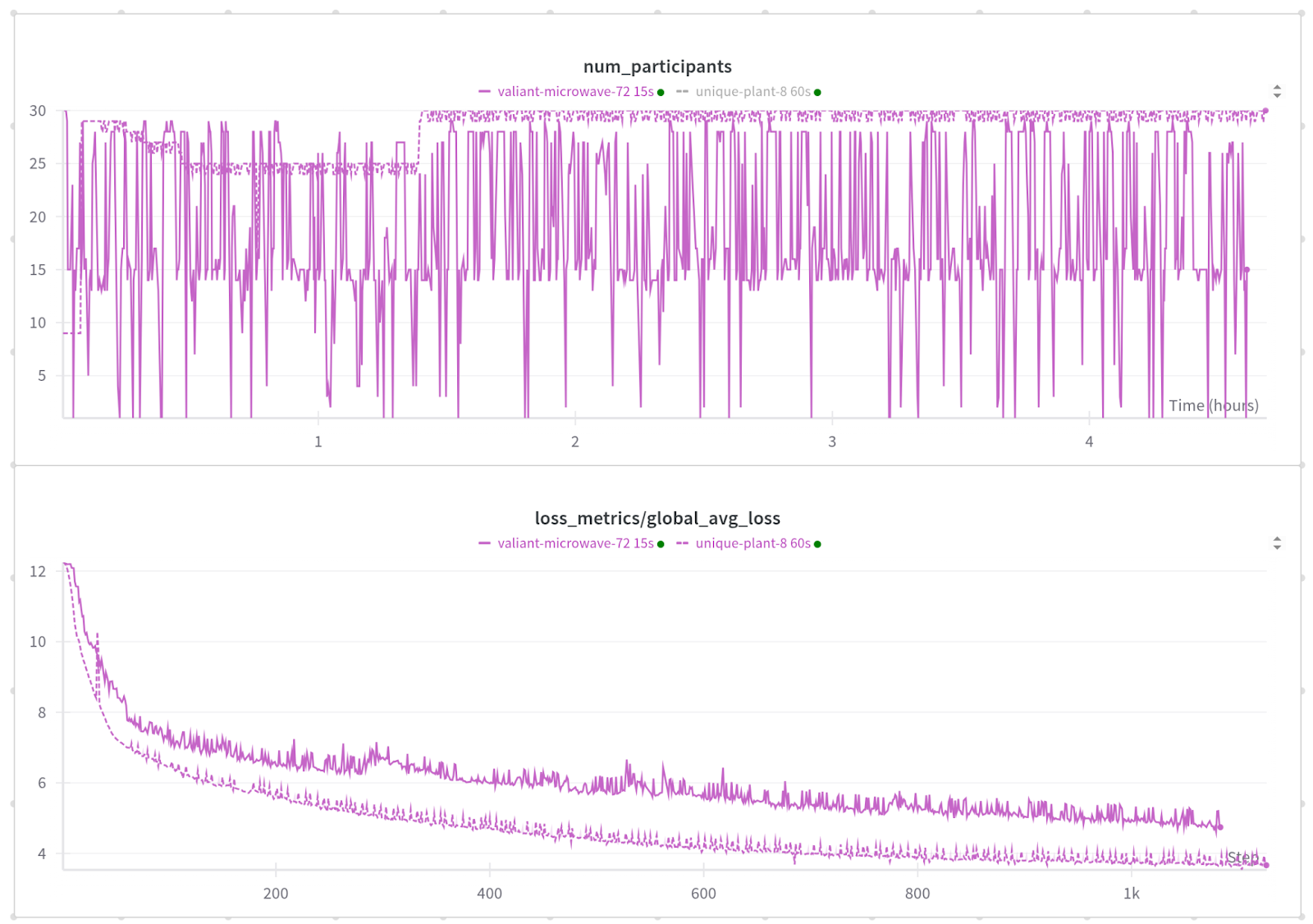
如您所见,这项工作表现得更加不稳定。与60秒故障率时我们拥有的接近30台机器不同,每15秒发生一次故障,我们每一步可用的机器从1台到30台不等。
平均而言,在任何给定步骤中,我们有18.9个(18.9/30 = 63%)工作器处于健康状态并参与,平均步长为15.46秒。
在前888个步骤中,有268个步骤成功提交,这使我们获得了30.2%的步骤效率。
这使得训练效率仅为13.4%,这在任何正常的训练作业中都会很糟糕,但值得注意的是,尽管每15秒就崩溃一次,模型仍在收敛!仅仅从检查点加载模型通常就需要超过1分钟。
损失收敛速度比我们60秒MTBF运行慢,但这是预期的,因为有更多批次因错误而被丢弃。
我们确实看到损失出现一些较大的尖峰,这与只有1个参与者健康且因此批处理大小仅为1/30的情况相关。这可以通过调整最小副本数量轻松避免。我们在此测试中将其设置为1。
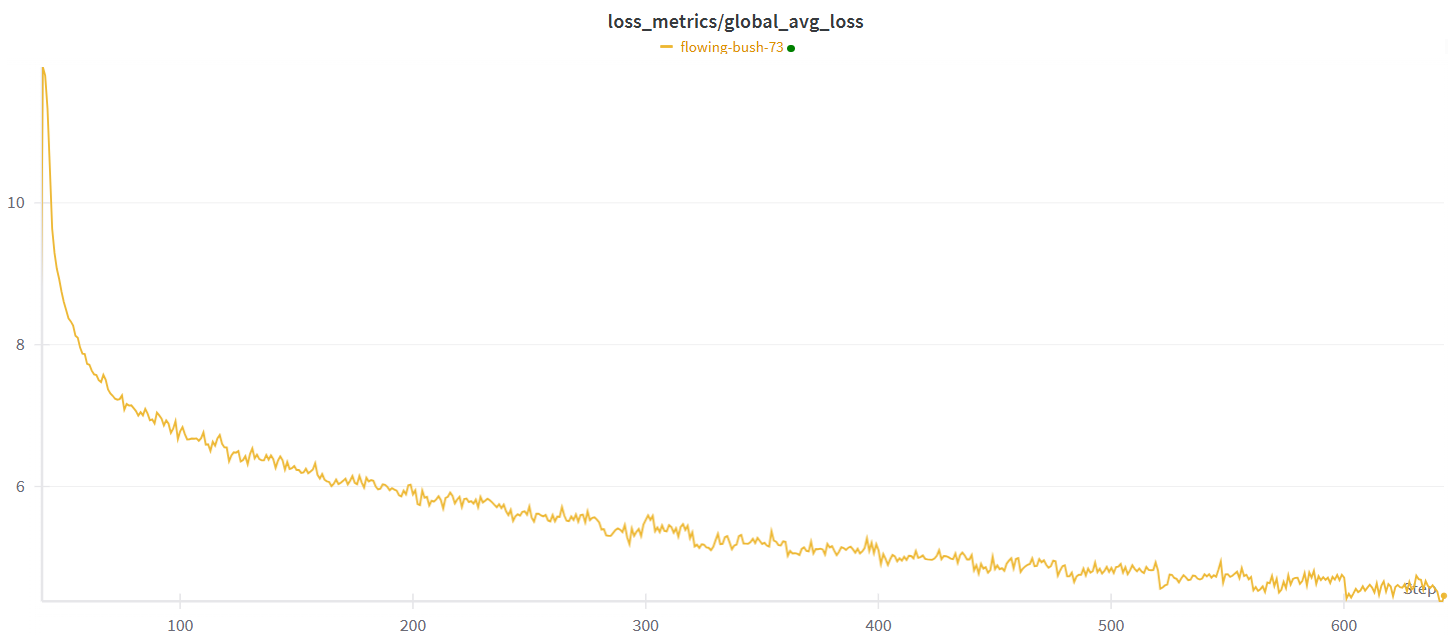
运行3:半同步训练
TorchFT还支持半同步训练算法,包括LocalSGD和DiLoCo,并计划未来添加更多。与HSDP2不同,这些算法不是每步都同步。相反,它们会进行多个步骤的局部训练,然后通过平均参数或梯度来同步权重。这种方法通过将通信成本降低到每N步一次(一个可配置的超参数)而不是每步一次来提高性能。我们对集群的测试表明吞吐量有显著改善。当每40步同步一次时,我们最小化了通信开销,从而实现了更高的整体吞吐量。下面是DiLoCo(黄色)和常规HSDP2(紫色)的吞吐量比较,DiLoCo平均约为4000 tps,而HSDP2平均约为1200 tps。
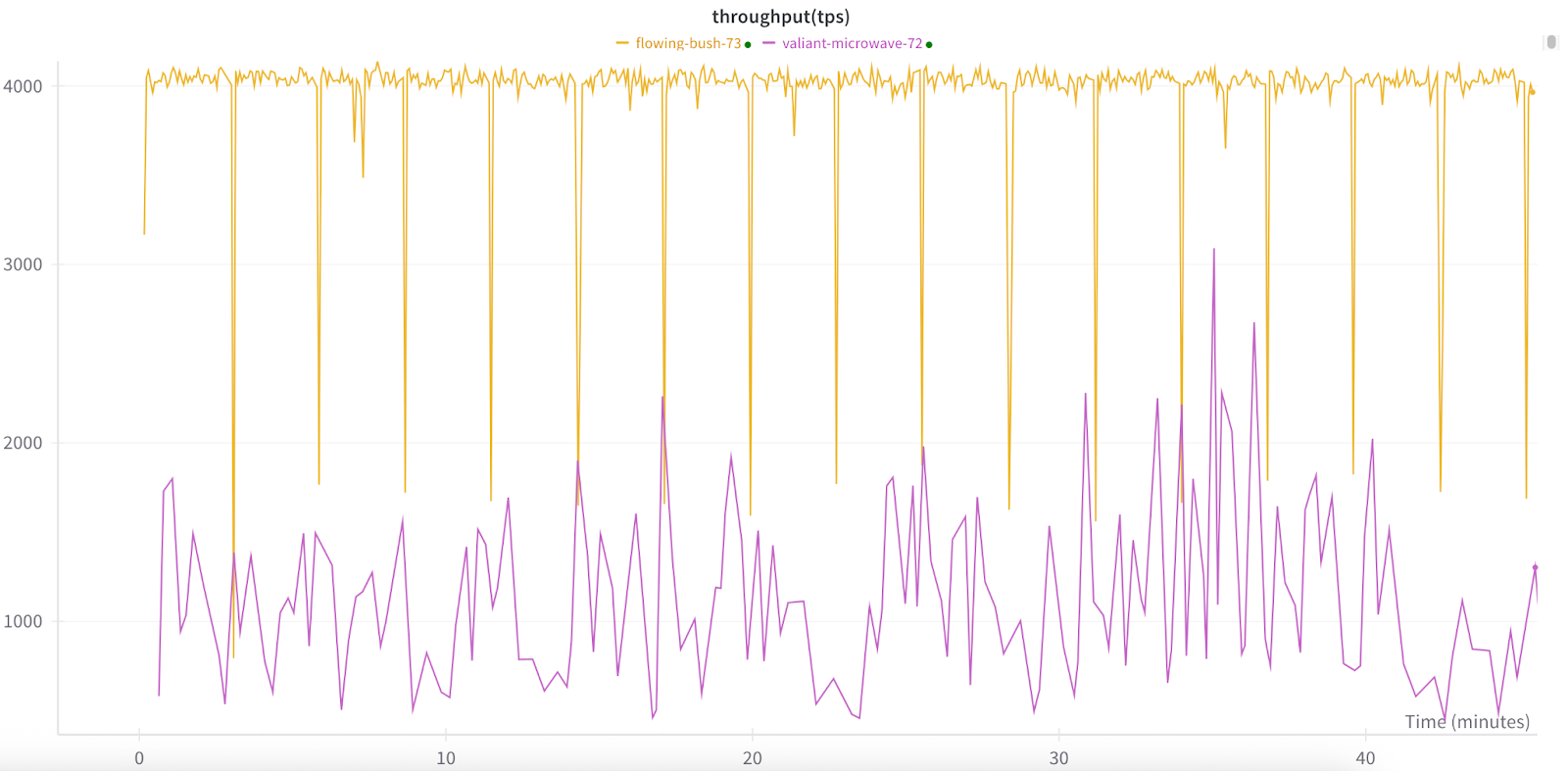
自然,同步间隔越长,副本组内的模型差异越大。这种差异可能会影响模型的收敛。然而,在我们的测试中,我们观察到即使同步间隔较长,模型仍然能够有效地训练并达到收敛。这种韧性在副本可能意外离开组的动态环境中是有益的。即使在这种情况下,模型也表现出在没有显著中断的情况下继续训练的能力。
下一步
torchft正在积极开发中,我们计划在新型算法(如流式DiLoCo)、使PyTorch Distributed更能抵御故障(即使在infiniband/nvlink上!)以及更高效等方面进行大量改进。
如果您对使用torchft感兴趣,请查看torchft README和torchft文档。我们也乐意与您交流,因此请随时通过GitHub、LinkedIn或Slack直接联系我们。